How do LLMs Compute Verbal Confidence
Abstract: Verbal confidence -- prompting LLMs to state their confidence as a number or category -- is widely used to extract uncertainty estimates from black-box models. However, how LLMs internally generate such scores remains unknown. We address two questions: first, when confidence is computed - just-in-time when requested, or automatically during answer generation and cached for later retrieval; and second, what verbal confidence represents - token log-probabilities, or a richer evaluation of answer quality? Focusing on Gemma 3 27B and Qwen 2.5 7B, we provide convergent evidence for cached retrieval. Activation steering, patching, noising, and swap experiments reveal that confidence representations emerge at answer-adjacent positions before appearing at the verbalization site. Attention blocking pinpoints the information flow: confidence is gathered from answer tokens, cached at the first post-answer position, then retrieved for output. Critically, linear probing and variance partitioning reveal that these cached representations explain substantial variance in verbal confidence beyond token log-probabilities, suggesting a richer answer-quality evaluation rather than a simple fluency readout. These findings demonstrate that verbal confidence reflects automatic, sophisticated self-evaluation -- not post-hoc reconstruction -- with implications for understanding metacognition in LLMs and improving calibration.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “How do LLMs Compute Verbal Confidence?”
What is this paper about?
This paper studies how LLMs—AI systems that generate text—decide how confident they are in their own answers when you ask them to say it out loud as a number or a label (like “low,” “medium,” or “high”). This is called verbal confidence.
The big questions
The researchers focused on two simple questions:
- When does the model decide its confidence?
- Just-in-time: Does it only figure out confidence at the last moment when you ask for it?
- Cached: Or does it quietly figure out its confidence while it’s writing the answer, save it somewhere inside, and then simply “look it up” later when asked?
- What does the confidence actually measure?
- Is it just how “fluent” or easy the answer was to type out (like how sure it felt while choosing each next word)?
- Or is it a smarter self-check that judges whether the answer actually fits the question well?
How they studied it (in everyday terms)
The team tested two different AI models (Gemma 3 and Qwen) on trivia questions. They had the models give answers, and then asked for a confidence rating. Importantly, they told the models not to show their reasoning—only to give a confidence score—so they could look at the hidden signals inside the models, not written explanations.
They used several clever “peek and poke” techniques on the model’s inner workings. Think of an LLM’s writing process like a step-by-step assembly line, where each step is a “layer,” and each piece of text is processed position by position (token by token). Two special positions mattered most:
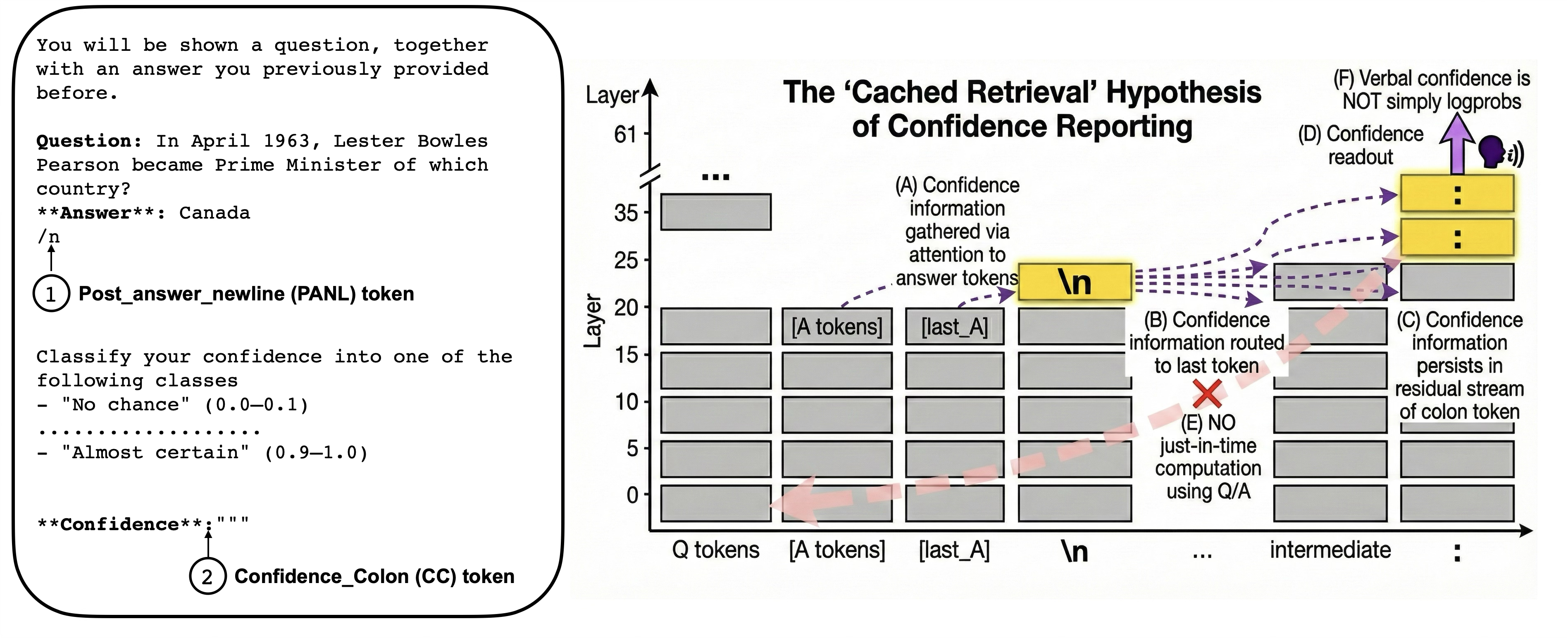
- PANL: the “post-answer newline,” right after the answer ends. Think of it as the first pause after finishing the answer.
- CC: the “confidence cue,” the point where the model is asked to say its confidence.
Here’s what they did, using simple analogies:
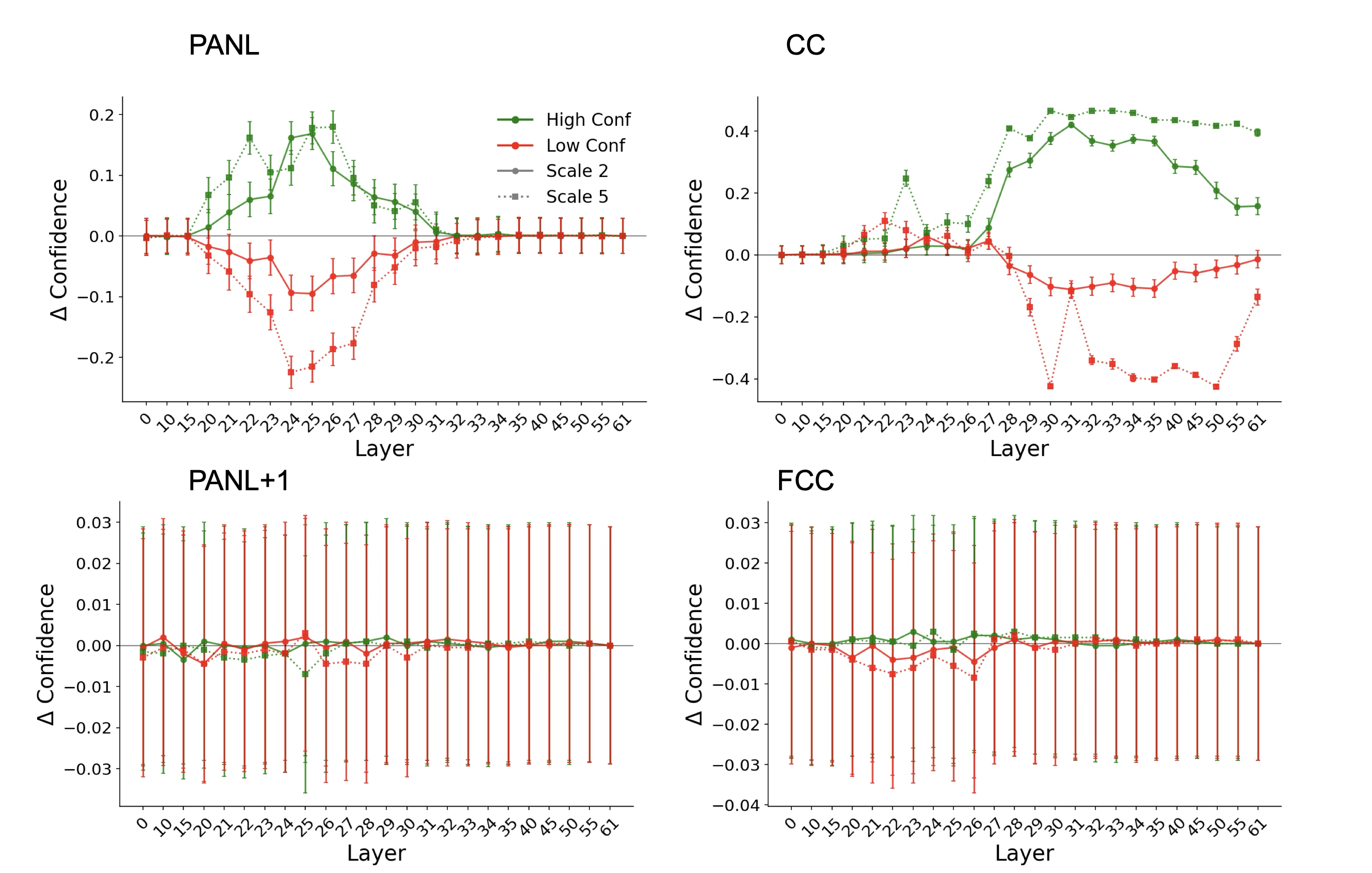
- Activation steering: Nudge the model’s “confidence dial” at a certain step or position to see if it makes the model report higher or lower confidence. This tests whether confidence is already present there.
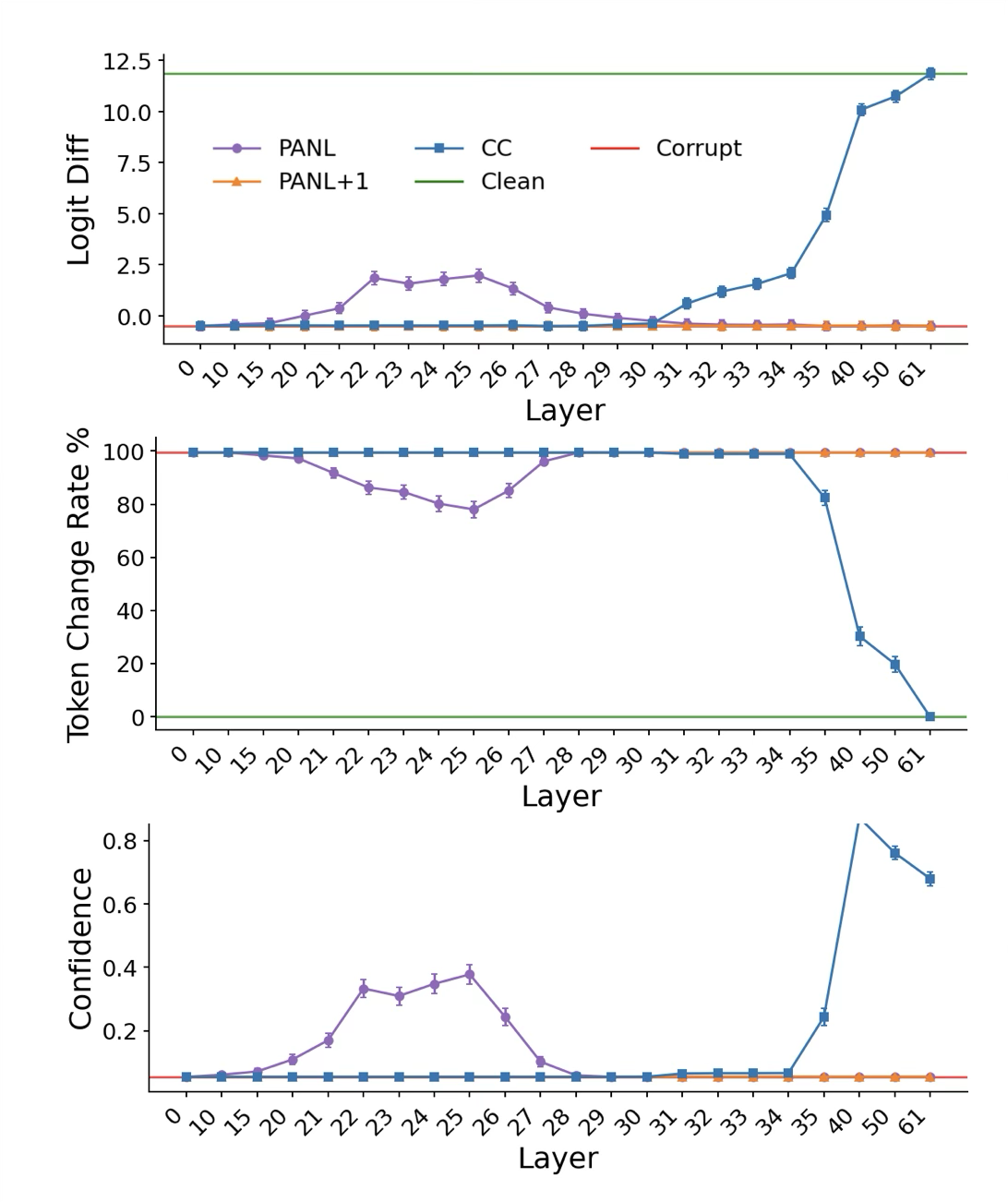
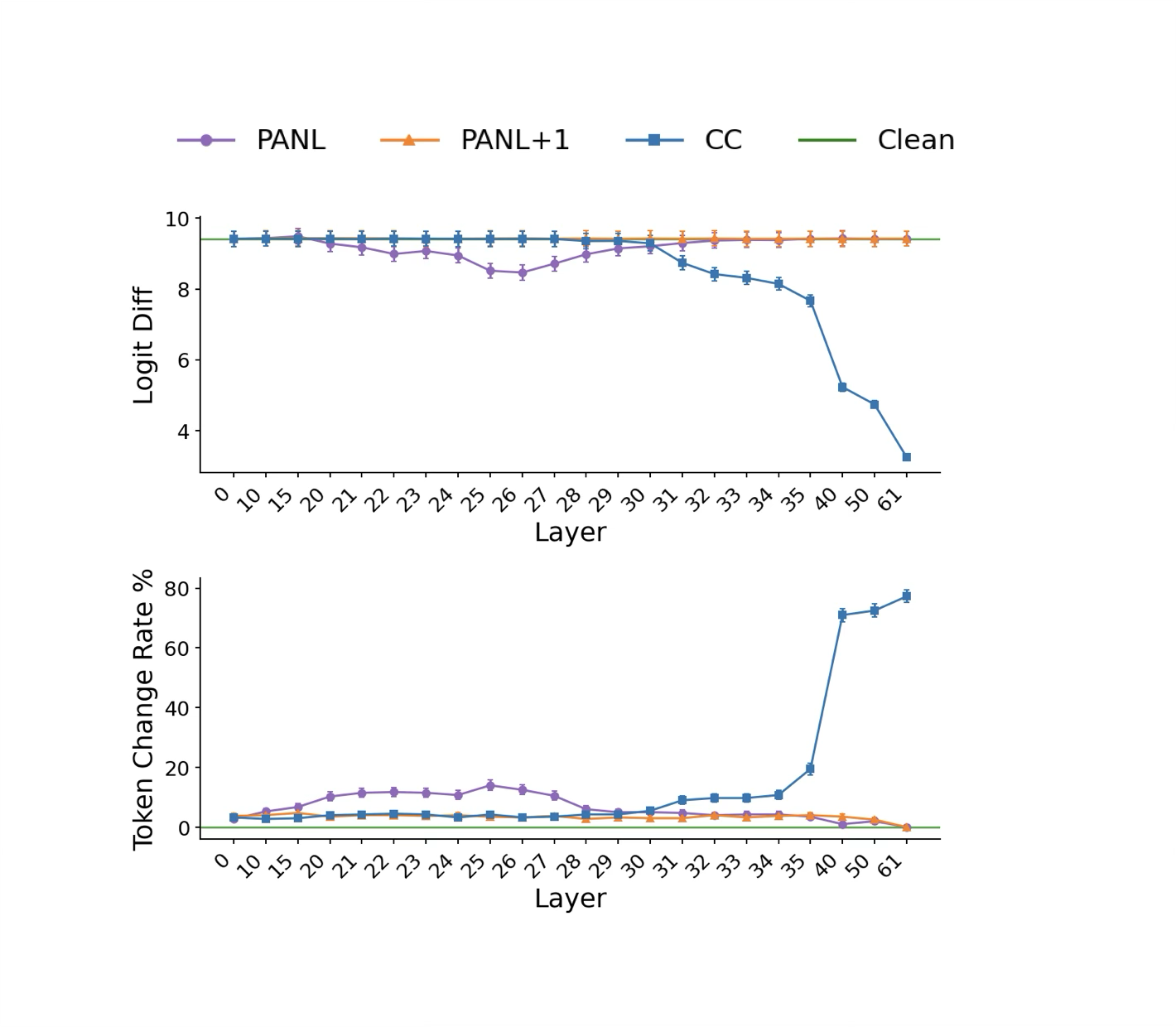
- Activation patching: First, “scramble” the answer’s internal info so the model can’t judge it well. Then “restore” clean signals at a single place (like PANL or CC) to see if that spot is enough to bring back correct confidence behavior.
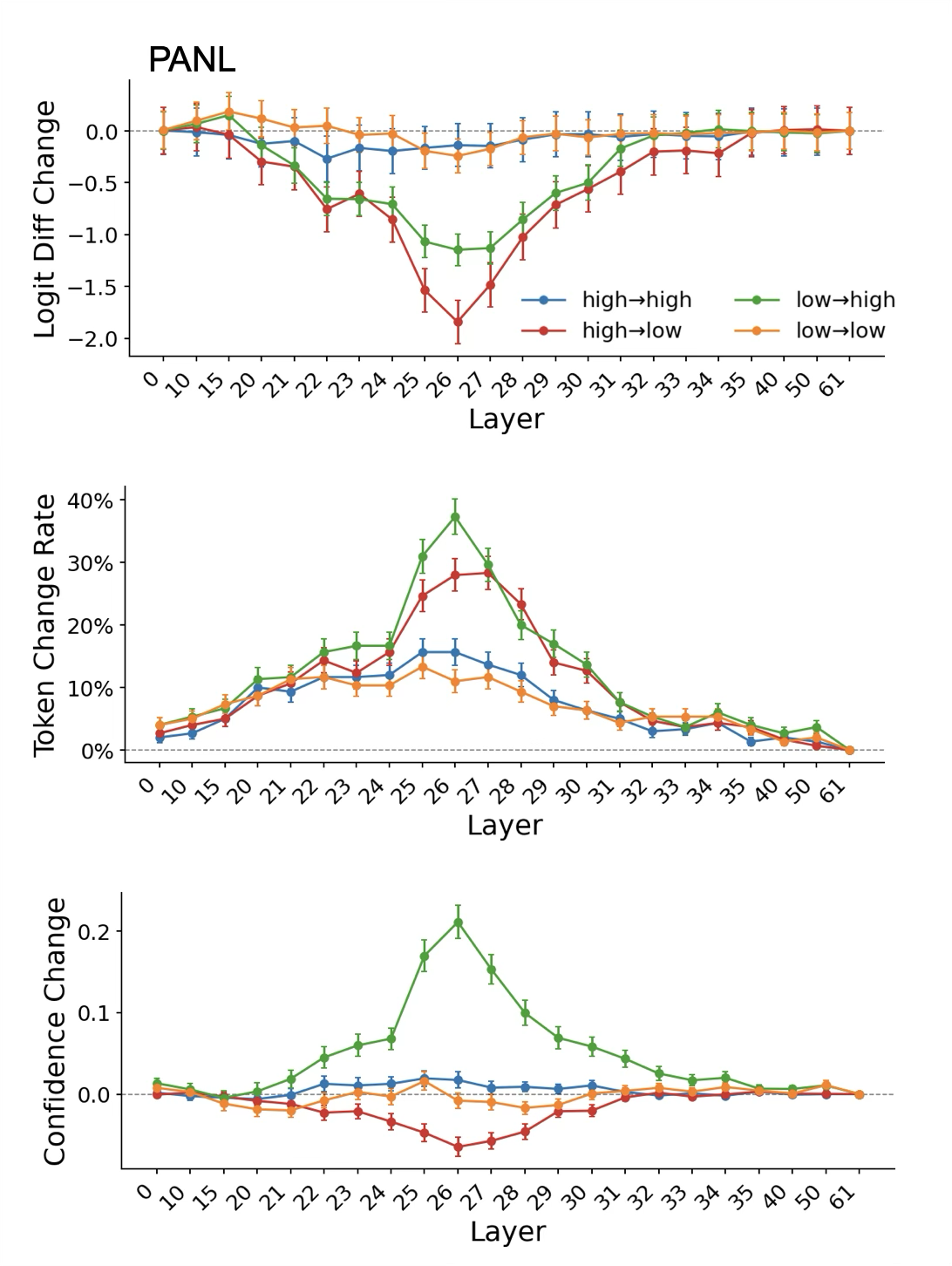
- Activation noising: “Blur” a spot (replace it with an average, boring signal) to see if the confidence output gets worse. If it does, that spot matters.
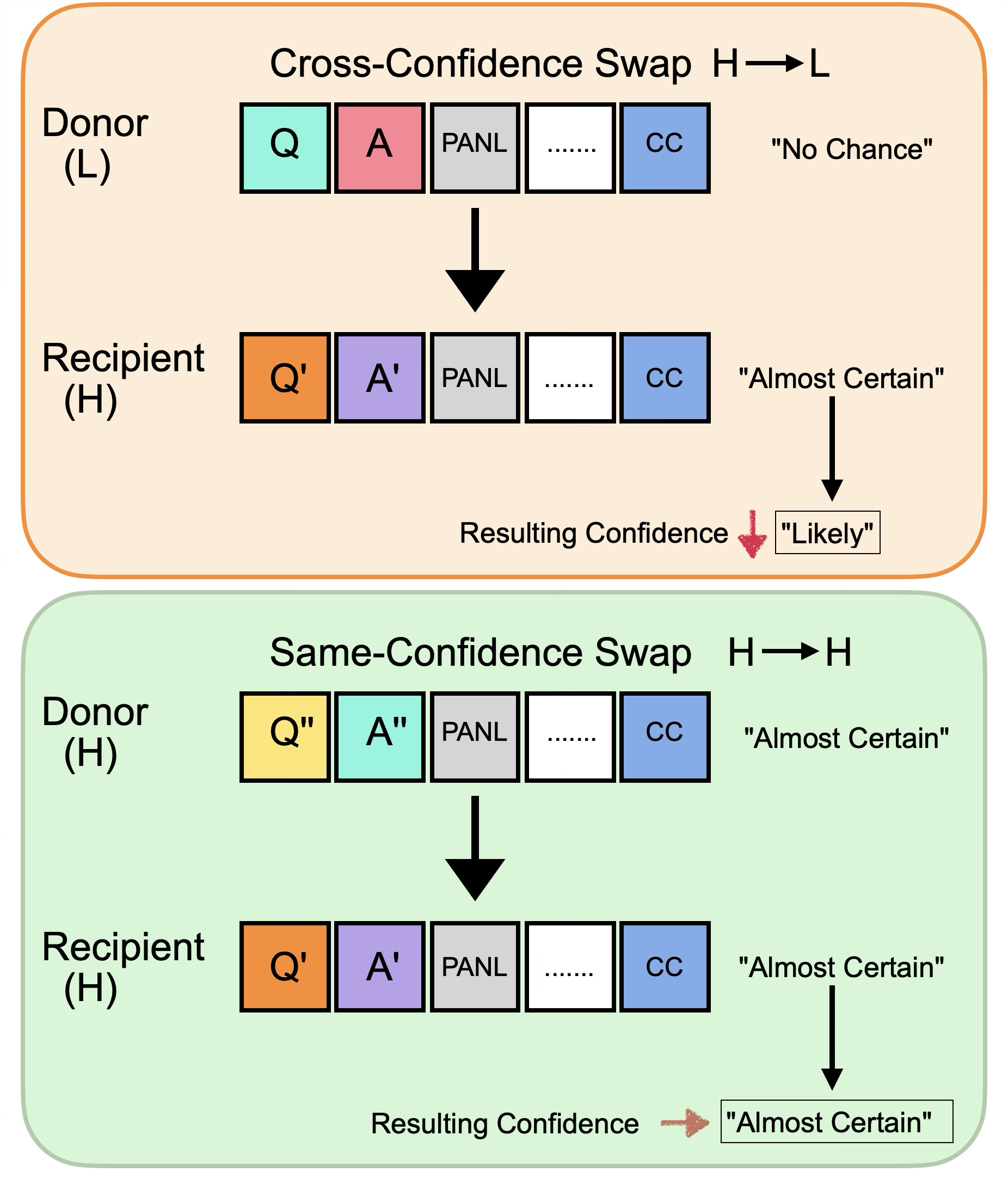
- Activation swap: “Transplant” the internal state from a clearly high-confidence example into a low-confidence one (and vice versa) at PANL or CC, to see if confidence shifts along with the transplant. If it does, that spot really stores confidence.
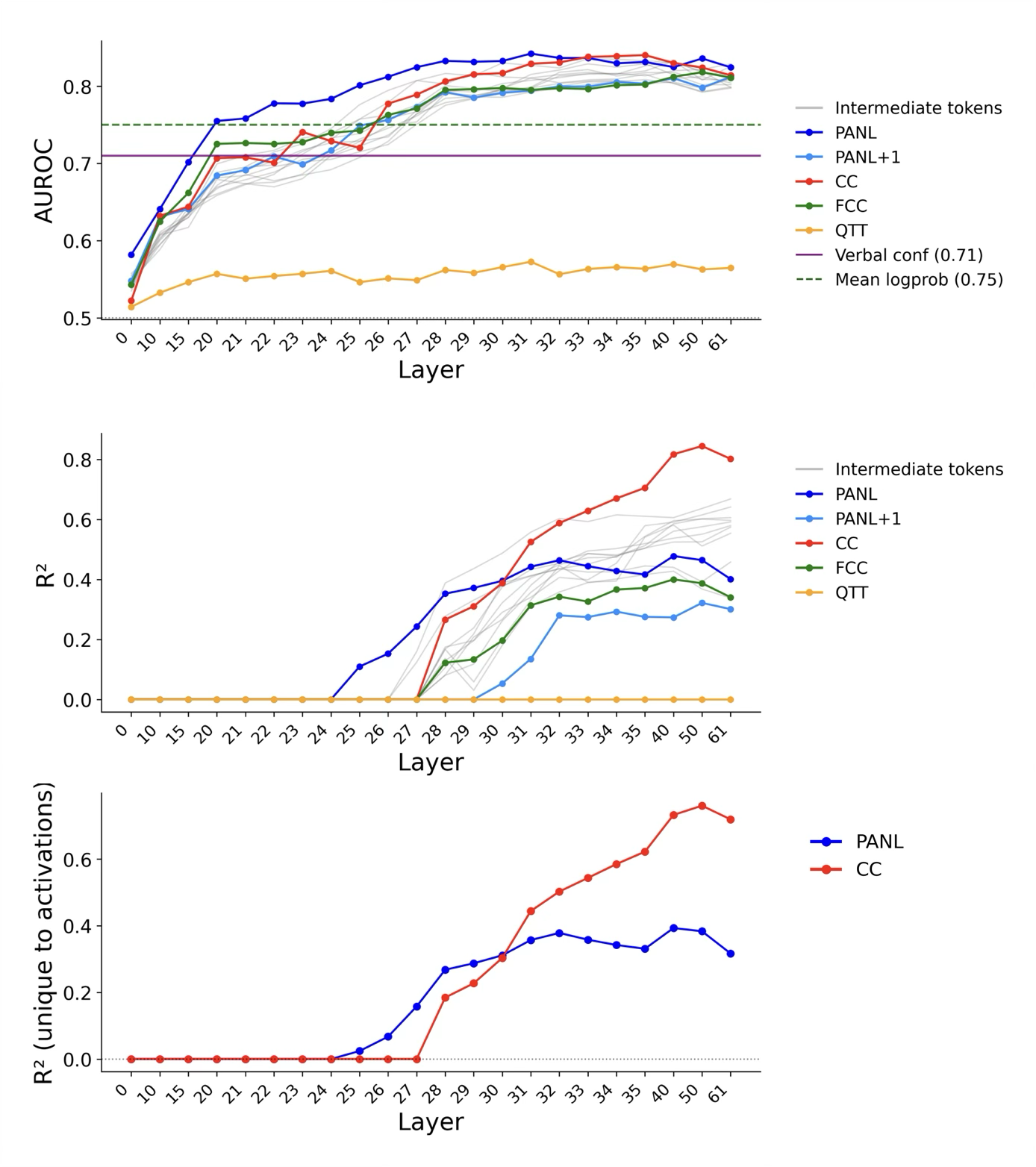
- Linear probing and variance tests: Train a very simple “detector” on the model’s internal signals to see how well those signals predict correctness and confidence. Then check how much these signals explain beyond basic fluency measures (like how likely each token was).
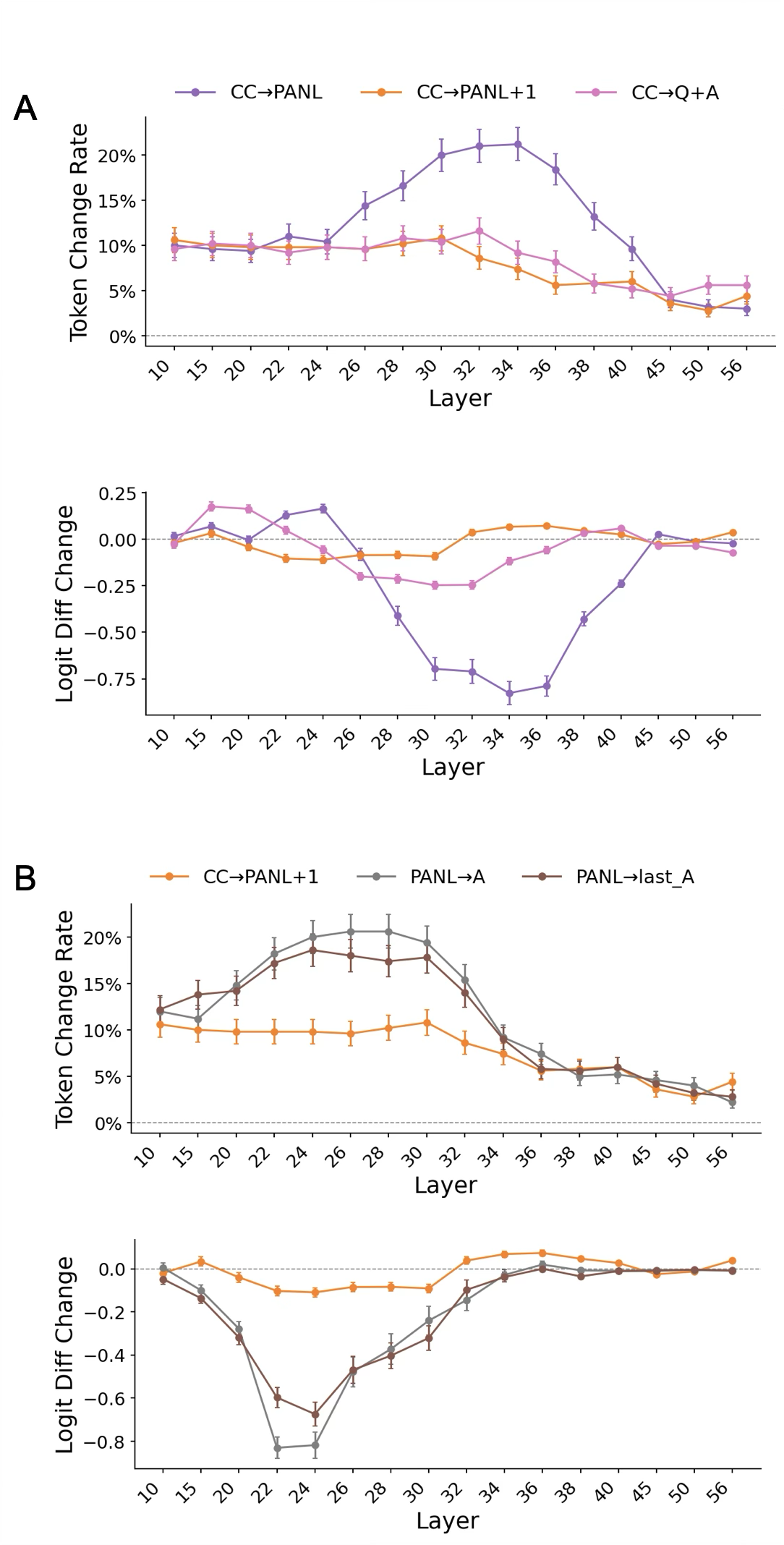
- Attention blocking: Block the model’s “look back” connections to trace where confidence information flows—from the answer, to PANL, to CC. This is like temporarily covering the model’s eyes for certain parts to see what breaks.
What they found and why it matters
The results strongly support the cached idea:
- Confidence is computed during answer generation and saved before the model is asked to report it.
- The first place this confidence appears is right after the answer finishes (PANL), at earlier steps in the model.
- Later, when asked for confidence, the model retrieves that stored signal at the CC position and verbalizes it.
- PANL comes first, CC comes later.
- “Pushes” at PANL change confidence earlier in the process than pushes at CC.
- “Restoring” PANL helps bring back normal confidence even when the answer information was scrambled.
- Swapping PANL between low and high confidence examples moves the reported confidence in the expected direction.
- Blocking how CC “looks back” to PANL disrupts confidence reporting, showing CC is reading confidence from PANL, not building it from scratch.
- Also, blocking how PANL “looks back” to the answer disrupts confidence, showing the signal comes from the answer content.
- Verbal confidence is not just fluency or token probabilities.
- The confidence signal at PANL and CC explains a lot beyond how easily the model generated each word.
- This suggests the model is doing a richer self-check: “Does this answer actually fit the question?” not only “Was I fluent while typing?”
- The pattern appears in more than one model and with different ways of asking for confidence (categories and numbers).
- That means it’s likely a general strategy that LLMs use.
Why this matters:
- If confidence is a stored self-evaluation, we can build better tools to access and improve it.
- It shows LLMs have a kind of metacognition: they can form internal judgments about their own answers before being asked.
- Since it’s more than fluency, we can potentially detect mistakes even when the model writes smoothly.
What this could change
- Safer AI: Systems can better judge when to warn users, ask for help, or double-check answers.
- Better calibration: We can adjust how models report confidence so it matches reality more closely.
- Smarter training and debugging: Understanding where and how confidence is formed helps engineers improve models, reduce overconfidence, and design better prompts.
- Research on AI “self-awareness”: These results show that LLMs automatically run internal checks, moving us closer to understanding and improving AI self-monitoring.
In short: LLMs don’t make up confidence at the last second. They quietly figure it out while answering, store it, and then retrieve it when asked. And that inner confidence is more than just how easy the words were to write—it’s a meaningful self-check of answer quality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to suggest actionable next steps.
- Limited model coverage: results are demonstrated on Gemma 3 27B and Qwen 2.5 7B only; it is unknown whether cached retrieval holds across larger/smaller models, different training paradigms (e.g., base vs RLHF-instruction-tuned), and other architectures (e.g., MoE, encoder–decoder, multilingual pretraining).
- Task/domain narrowness: experiments center on English factual QA (TriviaQA). It remains unclear whether the same confidence-computation mechanism applies to math/code reasoning, long-form synthesis, multi-hop or multi-step tasks, tool-use, or dialogue settings.
- Chain-of-thought (CoT) suppression: the study deliberately disables CoT. How confidence is computed when CoT is enabled (and how it interacts with chain length, scratchpad content, or backtracking) is not tested.
- Prompt dependence and routing: confidence routing differed between a “categorical” prompt (possible multi-hop routing) and a “minimal numeric” prompt (direct CC→PANL dependency). A systematic map of how prompt templates, instruction phrasing, and tokenization (e.g., presence/absence of newline/EOS) change the cache location and retrieval path is missing.
- Language and modality generalization: behavior in non-English prompts, multilingual settings, and multimodal inputs (e.g., VLMs) is untested.
- Answer length and structure: how the cache behaves with long, multi-sentence answers or multi-turn interactions (multiple PANL-like positions) is not evaluated; whether the “first post-answer position” generalizes with variable answer boundaries is unknown.
- Inference-time settings: effects of decoding strategy (greedy vs sampling), temperature, top-k/p, and nucleus sampling on the internal confidence computation and its readout are not examined.
- OOD robustness: the stability of cached confidence under domain shift (e.g., biomedical, legal), adversarially constructed questions/answers, or noisy/ambiguous prompts remains unassessed.
- Causal circuit resolution: while attention blocking identifies edge-level dependencies (answer tokens → PANL → CC), the specific attention heads and MLP units that compute, store, and route confidence are not localized, and their nonlinear interactions are unmapped.
- Partial intervention effects: activation patching/noising yield partial recovery/disruption, implying distributed and redundant circuitry. The full set of positions/layers necessary and sufficient for confidence computation is not identified.
- Mechanism of cache formation: the paper shows that PANL reads from answer tokens, but the precise computation that aggregates evidence (e.g., which features of question–answer fit are used) is not characterized.
- Second-order signal content: variance partitioning shows verbal confidence is not reducible to token log-probabilities, but what additional features drive the “richer evaluation” (e.g., semantic consistency, retrieval conflicts, entailment/contradiction, novelty) is unspecified.
- Temporal dynamics during answering: confidence appears at PANL and later transfers to CC, but when and how confidence evolves during the generation of the answer itself (e.g., before the last answer token) is not probed.
- Forced-error settings: if the model is constrained to produce an incorrect answer (e.g., via prefixes or logits bias), does the cached confidence reflect error awareness and decrease accordingly? This behavioral dissociation is not shown.
- Multi-choice vs open-ended: how cached confidence operates when token log-probabilities are strong signals (e.g., multiple choice) versus open-ended generation is not systematically compared.
- Training provenance: the role of pretraining vs instruction tuning/RLHF in producing cached confidence representations, and whether fine-tuning can relocate or sharpen the cache, is not investigated.
- Calibration interventions: while mechanisms are characterized, the paper does not test whether targeted edits (e.g., steering/patching at PANL/CC or fine-tuning heads) measurably improve calibration metrics (ECE, Brier, AUROC) across datasets.
- Black-box applicability: the study relies on internal activations, which are unavailable in most deployed LMs. Practical proxies that reveal or enhance cached confidence in black-box settings are not provided.
- Adversarial manipulability: whether prompts can decouple answer content from confidence (e.g., inflation/deflation via style cues) and how robust the PANL cache is to such manipulations is unknown.
- Stability across prompt perturbations: small changes in formatting (whitespace, punctuation, token boundaries) may alter PANL and CC effects; a sensitivity analysis is absent.
- Numeric vs categorical readout: the mapping from internal confidence to different verbalizations (digits vs classes) and whether the same latent is read out by distinct decoding heads is not established.
- Interaction with known “confidence neurons”: links between PANL/CC pathways and previously reported LayerNorm-scale “confidence regulation neurons” are not explored; do these modules gate or amplify the cached signal?
- Long-context effects: for long prompts or retrieval-augmented inputs, do multiple caches form, and how does the model select which cache to retrieve at CC?
- Generalization beyond newline-based PANL: if answers do not end with newline (e.g., streaming APIs or different templates), does the cache relocate (e.g., to EOS) and does the same temporal precedence persist?
- Comprehensive evaluation metrics: reliance on AUROC, R², and logit margins is informative but limited; proper scoring rules (e.g., Brier, NLL), finer-grained calibration curves, and per-difficulty analyses (e.g., item response theory) are not reported.
- Dataset balance and selection: several analyses focus on high-confidence trials, potentially biasing conclusions; how results change across confidence strata or with better-balanced datasets is not shown.
- Cross-dataset replication: decoding and intervention results are not replicated on multiple QA datasets (e.g., Natural Questions, HotpotQA), leaving external validity uncertain.
- Theoretical alignment: while second-order interpretations are suggested, the work does not formalize or test a computational model (e.g., Bayesian error-detection) that quantitatively predicts observed internal signals and behavior.
- Safety and deployment implications: whether accessing/manipulating the cache could support abstention, uncertainty-aware routing, or hallucination mitigation in real applications is not experimentally demonstrated.
Practical Applications
Immediate Applications
The findings show that LLMs compute a cached, internal confidence signal during answer generation and retrieve it for verbalization, and that this signal reflects more than token log-probabilities. The following applications can be deployed now using prompt design, workflow changes, and, where applicable, open-model internals.
- Confidence-aware routing and triage in AI products (software, customer support, finance ops, legal drafting)
- What: Prompt LLMs to output a numeric/categorical confidence immediately after the answer and use thresholds to decide “auto-accept,” “auto-retrieve/check,” or “escalate to human.”
- Tools/workflows:
- Confidence Router: middleware that parses the answer + confidence, applies thresholds, and triggers retrieval, testing, or human review.
- Policy: log confidence per decision for auditability.
- Sectors: customer support ticket replies, contract clause extraction, KYC/AML triage, claims summarization.
- Assumptions/dependencies: verbal confidence must be validated on the target task; prompt should minimize intermediate template tokens between the answer and the confidence request to preserve reliable retrieval (per minimal-prompt results).
- Tool-use policies driven by confidence (software engineering, RAG/search, analytics)
- What: If verbal confidence is low, invoke retrieval (RAG), run code tests, call a calculator/simulator, or ask for additional context; if high, skip extra steps.
- Tools/workflows:
- Confidence-Triggered Tooling: simple if/else policies in orchestration layers (e.g., LangChain, Semantic Kernel).
- Sectors: software (unit tests before accepting code), data analytics (cross-check with SQL), content generation (auto-citation when low confidence).
- Assumptions/dependencies: thresholds require calibration per task; added latency/cost for extra tool calls.
- Prompt and UI design for more reliable confidence reporting (all sectors, consumer assistants)
- What: Use minimal, numeric prompts and place the confidence request immediately after the answer (answer + newline + brief instruction + colon), minimizing intermediate tokens that can diffuse routing from PANL to the confidence site.
- Tools/workflows:
- Prompt Linter for Confidence: ensure short post-answer templates and unique first tokens for confidence classes (for clear decoding and logging).
- UI: display the model’s confidence with explanations (e.g., “~70% confident”) and links to verify.
- Sectors: search assistants, enterprise copilots, educational chatbots.
- Assumptions/dependencies: user research needed for how best to present confidence; multilingual behavior may differ.
- Confidence-based active learning and QA prioritization (industry/academia)
- What: Use low verbal confidence to prioritize human labeling/review and to select examples for additional training or evaluation.
- Tools/workflows:
- Data Curator: rank items by confidence for annotation queues; measure calibration (ECE/AUROC) on held-out sets.
- Sectors: document understanding, OCR post-processing, taxonomy tagging, NER.
- Assumptions/dependencies: generalization from TriviaQA to target data must be tested; monitor drift as models update.
- Assurance and audit logging in regulated workflows (finance, healthcare, public sector)
- What: Record the model’s confidence per decision for audit trails, risk scoring, and post-hoc reviews.
- Tools/workflows:
- Calibration Dashboard: track ECE/AUROC over time and per use case; alert on degradation.
- Sectors: financial advice disclaimers, clinical-note summarization assistants, public-sector information portals.
- Assumptions/dependencies: verbal confidence should be validated in-domain; do not use as the sole safety control in high-stakes settings.
- Teaching metacognition in educational tools (education)
- What: Tutors that reveal their confidence alongside answers and prompt students to reflect and compare with their own confidence judgments.
- Tools/workflows:
- Confidence-Aware Tutor: activities that encourage students to weigh evidence based on model’s confidence.
- Assumptions/dependencies: content and age-appropriate presentation; calibrate per subject domain.
- Model selection and monitoring when token log-probabilities are unavailable (industry/academia)
- What: Use verbal confidence as an uncertainty proxy for black-box models to compare providers and monitor releases.
- Tools/workflows:
- “Confidence-Only” Benchmarking: standardized prompts, calibration metrics (ECE/AUROC), and acceptance-rate curves.
- Assumptions/dependencies: performance varies by model; re-validate after model updates.
- Simple calibration improvements via confidence placement (software/UX)
- What: Place confidence immediately adjacent to the answer to reduce template-induced routing noise (given PANL→CC pathway).
- Tools/workflows:
- Response Templates: ensure a newline right after the answer and a concise “Confidence:” prompt.
- Assumptions/dependencies: helps retrieval; does not replace rigorous calibration.
Long-Term Applications
These opportunities require further research, access to model internals, scaling, or validation beyond current demonstrations.
- Provider-level “confidence channel” or endpoint (AI platforms)
- What: Expose a stable confidence API derived from internal cached representations rather than (or in addition to) token log-probabilities.
- Potential products:
- Confidence API: per-output scalar with confidence intervals and calibration metadata.
- Dependencies: model-provider implementation; stability guarantees across updates; privacy safeguards.
- Mechanistic calibration modules via activation steering/patching (model dev, safety)
- What: Use activation steering to nudge confidence output toward better calibration (e.g., down-regulate overconfidence) and activation patching to stabilize confidence pathways.
- Potential products:
- Calibration Steering Layer: optional runtime module for open models; fine-tuning targets for proprietary models.
- Dependencies: access to activations or fine-tuning hooks; cross-task generalization studies; guardrails to prevent adverse effects.
- Confidence-aware autonomous agents and backtracking (robotics, software agents)
- What: Agents use internal confidence to decide when to act, seek help, or backtrack/repair; low confidence at PANL triggers re-plan or tool-use before committing.
- Potential products:
- Self-Correcting Planners; Safety-Aware Robotics Controllers.
- Dependencies: real-time confidence extraction; rigorous evaluation in safety-critical contexts; human-in-the-loop protocols.
- Domain-validated confidence thresholds for high-stakes decisions (healthcare, finance, legal)
- What: Empirically derived thresholds tied to outcomes and risk profiles; dual-signal gating (verbal confidence + external checks) before action.
- Potential products:
- Clinical Decision Support with Confidence Gating; Compliance Copilots that auto-cite when below threshold.
- Dependencies: prospective studies/clinical trials; regulatory approval; robust fail-safe designs.
- Cross-model confidence distillation and small “confidence readers” (platforms, research)
- What: Train lightweight models to predict an LLM’s correctness from surface text + minimal context, approximating the richer, internal confidence.
- Potential products:
- Sidecar Confidence Estimators to gate expensive models or tools.
- Dependencies: labeled datasets linking answers, correctness, and verbal confidence; generalization across tasks/models.
- Standards and policy for confidence reporting and calibration (policy, industry consortia)
- What: Establish norms for presenting model confidence, calibration tests, and audit requirements; certification for “confidence-competent” systems.
- Potential products:
- Confidence Reporting Standard; Calibration Badges; Regulatory guidance.
- Dependencies: multi-stakeholder alignment; reproducible evaluation suites; consumer-testing evidence.
- Interpretability tools that visualize PANL→CC confidence flow (ML ops, research)
- What: IDE-like diagnostics that trace attention/activation pathways for confidence, flagging failure points across model updates.
- Potential products:
- Confidence Circuit Explorer integrated into ML observability stacks.
- Dependencies: access to internals (open models or provider partnerships); scalable instrumentation.
- Error detection and lie/hallucination mitigation by cross-checking signals (safety)
- What: Combine verbal confidence with other signals (e.g., token log-probs, consistency sampling) to detect likely errors or strategic misstatements.
- Potential products:
- Multi-Signal Risk Scorers; Hallucination Gates that trigger retrieval/citation.
- Dependencies: fusion models and thresholds; adversarial robustness; domain validation.
- Multimodal and multilingual confidence mechanisms (vision-language, speech)
- What: Extend cached-confidence analysis and tooling to VLMs and non-English settings for broader applicability.
- Potential products:
- Confidence-Aware Multimodal Assistants (e.g., medical imaging triage support with model confidence).
- Dependencies: new experiments across modalities/languages; dataset availability; UI adaptations.
- Training-time objectives that enhance second-order (metacognitive) signals (model training)
- What: Regularize or fine-tune models to strengthen the internal confidence representation and its alignment with correctness, improving calibration and error detection.
- Potential products:
- Metacognition-Enhanced LLMs with better self-evaluation and safer deployment characteristics.
- Dependencies: scalable training recipes, benchmarks beyond TriviaQA, prevention of confidence gaming.
- Fairness and bias audits on confidence (policy, compliance)
- What: Evaluate whether confidence varies systematically by topic or demographic content and mitigate disparities.
- Potential products:
- Confidence Fairness Audits; Compliance reports for regulated deployments.
- Dependencies: sensitive attribute detection frameworks; governance processes; representative datasets.
- Consumer-facing assistants that teach and use confidence (daily life, education)
- What: Assistants that routinely display and reason with their confidence, encouraging user verification for low-confidence answers and reinforcing critical thinking.
- Potential products:
- Confidence-Aware Home Assistants; Study Aids with calibration coaching.
- Dependencies: UX research on trust and comprehension; localization; privacy considerations.
Notes on feasibility and dependencies across applications:
- Generalization: Results were shown on Gemma 3 27B and Qwen 2.5 7B with TriviaQA and no chain-of-thought; behavior may differ for long-form reasoning, other domains, or languages—revalidation is needed.
- Prompt sensitivity: Reliability improves when the confidence request follows immediately after the answer with minimal intervening tokens; template-heavy prompts may diffuse the cached signal.
- Access constraints: Activation-level methods (steering/patching/attention blocking) require open models or provider collaboration; black-box settings should rely on prompt and workflow design.
- Calibration risk: Verbal confidence is informative and reflects more than log-probabilities, but it is not perfectly calibrated; use it as one signal among several, especially in high-stakes contexts.
- Monitoring: Model updates can change confidence behavior; maintain dashboards (ECE, AUROC) and regression tests for confidence workflows.
Glossary
- Activation noising: An intervention that replaces hidden activations with a mean representation to disrupt or test the necessity of information. "we performed activation noising (mean ablation) experiments"
- Activation patching: A causal technique that restores clean activations at specific positions/layers to test whether they are sufficient to recover behavior. "we employed activation patching with a corrupt-then-restore paradigm"
- Activation steering: Adding direction vectors to internal activations to causally increase or decrease a target behavior. "Activation steering, therefore, allows us to distinguish between competing accounts of confidence generation."
- Activation swap experiment: Swapping residual activations between trials to test whether specific positions encode transferable information (e.g., confidence). "We designed an activation swap experiment"
- Attention blocking: Disabling specific attention connections to trace information flow and rule out alternative computations. "Attention blocking experiments rule out just-in-time (JIT) computation"
- Attention edges: Directed connections representing which prior tokens a position is allowed to attend to in a transformer. "by selectively blocking attention edges between positions."
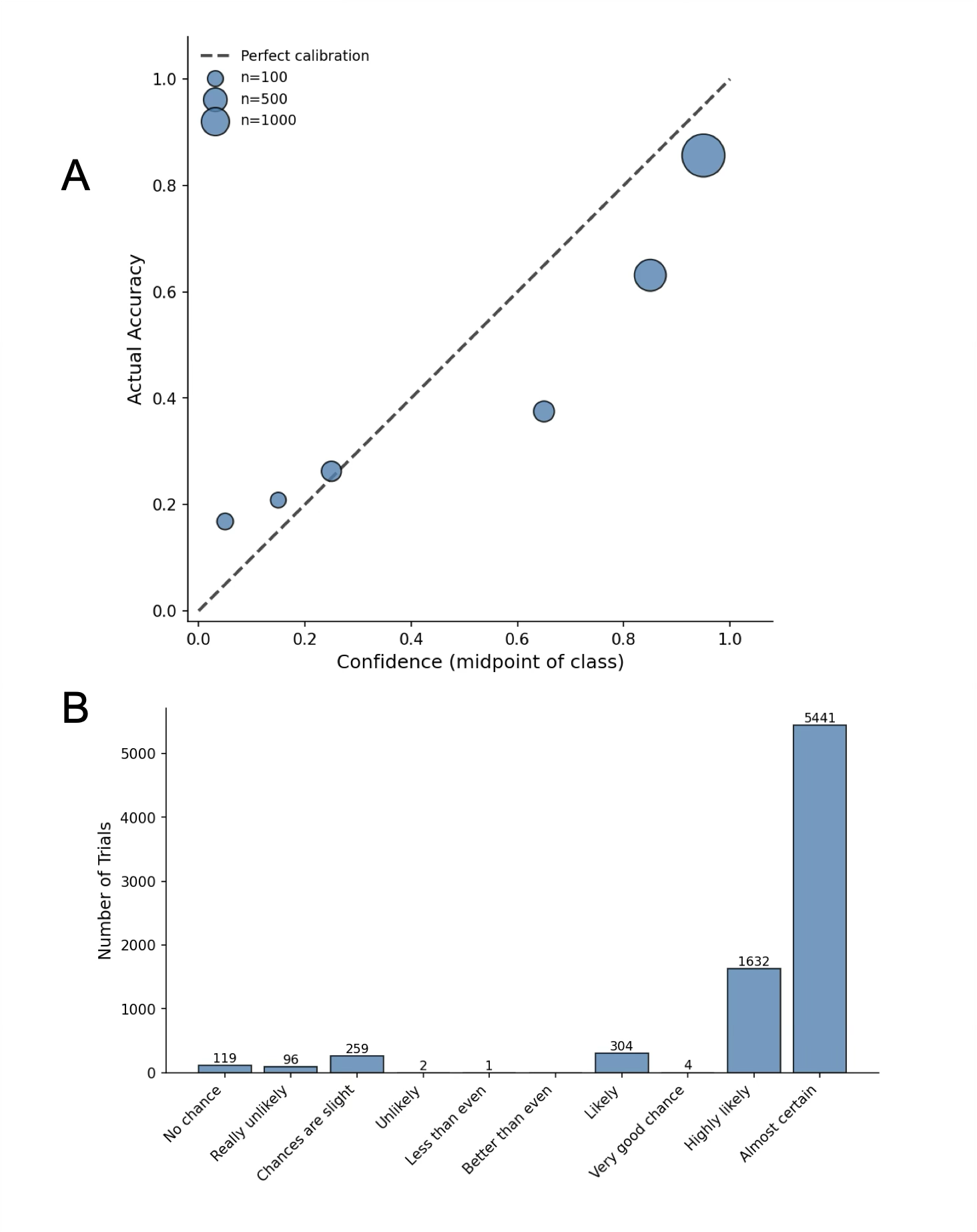
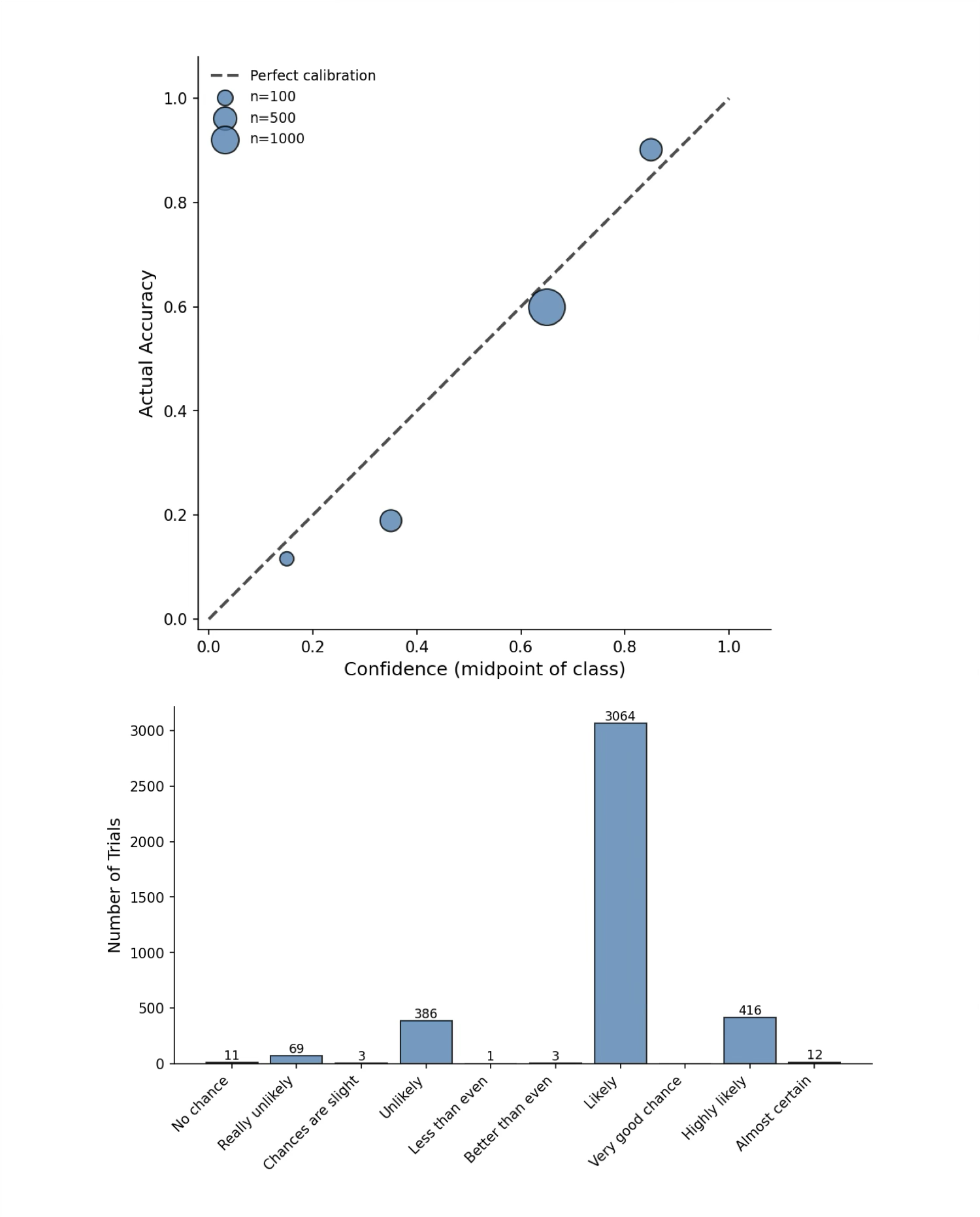
- AUROC: Area Under the Receiver Operating Characteristic curve; a threshold-independent metric for binary discrimination performance. "Gemma was reasonably well calibrated (ECE = 0.12, AUROC = 0.71)"
- Cached retrieval: The hypothesis/mechanism where a model computes a representation (e.g., confidence) during generation and stores it for later output. "We provide convergent evidence for cached retrieval."
- Causal attention: The autoregressive attention mask that prevents a token from attending to future positions. "This follows because causal attention prevents PANL from attending to tokens that appear later in the prompt"
- CC (confidence-colon) token: The token position (a colon) at which the model is prompted to verbalize its confidence. "Key positions: PANL (post-answer-newline) token, CC (confidence-colon) token."
- Chain-of-thought (CoT): Explicit intermediate reasoning steps output by a model before its final answer. "we deliberately suppress chain-of-thought reasoning"
- ECE: Expected Calibration Error; a scalar metric quantifying the mismatch between predicted confidence and empirical accuracy. "Gemma was reasonably well calibrated (ECE = 0.12, AUROC = 0.71)"
- First-order accounts: Theoretical view that confidence is a direct readout of the same internal signal used to make the decision. "Under first-order accounts, confidence arises from the same internal signals that drive the decision itself"
- First token change rate: The fraction of trials where the top (argmax) first confidence token changes relative to a baseline. "first token change rate, the proportion of trials where the argmax confidence token differed from baseline."
- Interchange intervention: A causal analysis method that swaps internal states between runs to test what information they carry. "This approach draws on the logic of interchange intervention"
- JIT (just-in-time) hypothesis: The idea that the model computes confidence only when explicitly asked, not during answer generation. "Under the just-in-time (JIT) hypothesis, no dedicated confidence computation occurs during answer generation"
- LayerNorm: A normalization operation applied within transformer blocks; its parameters can modulate expression of signals. "by modulating LayerNorm scale"
- Linear probes: Simple linear models trained on hidden activations to decode specific variables (e.g., correctness, confidence). "we trained linear probes to decode two measures from residual stream activations"
- Logit difference: The margin between the logit for a target token and the mean (or competing) logits, used to assess confidence strength. "logit difference change, the change in the margin between the clean trial's confidence class logit and the mean logit of alternatives"
- Mean ablation: Replacing activations with their mean across examples to remove information while preserving scale. "activation noising (mean ablation) experiments"
- Mechanistic interpretability: The study of how specific internal components and circuits in models implement behaviors. "This is expected and consistent with broader findings in mechanistic interpretability."
- Metacognition: The capacity for self-evaluation of one’s own outputs or knowledge, here in LLMs. "with implications for understanding metacognition in LLMs"
- PANL (post-answer-newline) token: The newline token immediately following the model’s answer, proposed as a cache site for confidence. "post-answer-newline token (n, PANL)"
- Residual stream: The per-token vector space in transformers that accumulates and carries information across layers. "Confidence information persists in the residual stream at the confidence-colon through later layers (30--35)."
- Second-order accounts: Theoretical view that confidence is computed by a distinct evaluative process that can go beyond generation fluency. "Under second-order accounts, confidence involves a distinct computation that evaluates the decision"
- Token log-probabilities: The logarithms of the model’s predicted token probabilities, often used as a proxy for confidence. "what verbal confidence represents -- token log-probabilities, or a richer evaluation of answer quality?"
- Unembedding matrix: The final linear map from hidden representations to vocabulary logits used for token prediction. "Confidence is verbalized when CC's representation is transformed by the unembedding matrix at the final layer (layer 61)."
- Variance partitioning: Statistical method to quantify how much unique variance in a target is explained beyond other predictors. "variance partitioning revealed that these cached representations explain substantial variance in verbal confidence beyond token log-probabilities"
- Verbal confidence: Explicit confidence expressed by the model as text or a number when prompted. "Verbal confidenceâprompting LLMs to state their confidence as a number or categoryâis widely used to extract uncertainty estimates from black-box models."
Collections
Sign up for free to add this paper to one or more collections.