How Uncertainty Estimation Scales with Sampling in Reasoning Models
Abstract: Uncertainty estimation is critical for deploying reasoning LLMs, yet remains poorly understood under extended chain-of-thought reasoning. We study parallel sampling as a fully black-box approach using verbalized confidence and self-consistency. Across three reasoning models and 17 tasks spanning mathematics, STEM, and humanities, we characterize how these signals scale. Both self-consistency and verbalized confidence scale in reasoning models, but self-consistency exhibits lower initial discrimination and lags behind verbalized confidence under moderate sampling. Most uncertainty gains, however, arise from signal combination: with just two samples, a hybrid estimator improves AUROC by up to $+12$ on average and already outperforms either signal alone even when scaled to much larger budgets, after which returns diminish. These effects are domain-dependent: in mathematics, the native domain of RLVR-style post-training, reasoning models achieve higher uncertainty quality and exhibit both stronger complementarity and faster scaling than in STEM or humanities.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview of the Paper
This paper looks at a simple but important question: when an AI that “thinks step by step” answers a question, how well can it tell whether it’s right or wrong? The authors test two easy, black-box ways to measure the AI’s uncertainty (how unsure it is), see how these improve when you let the AI try multiple times, and check whether combining the two gives even better results—especially when extra tries are expensive.
Key Objectives and Questions
The study focuses on four plain questions:
- If we let the AI answer the same question multiple times, do its uncertainty signals get better?
- Which signal works better when we only have a few tries?
- Is combining the two signals more helpful than just taking more tries of one signal?
- Do results change across different subjects, like math, science, and humanities?
How They Did the Study (Methods)
The researchers tested three “reasoning” LLMs—AIs that show long chains of thoughts before giving an answer—on 17 tasks across math, STEM (science and related subjects), and humanities.
They used a black-box setup, which means they only looked at inputs and outputs, not the inside of the model. For each question, they asked the model to answer the same prompt K times, independently. Think of it like asking the same student to solve a problem multiple times, from scratch, to see if the final answers agree.
Here are the two uncertainty signals they measured:
- Verbalized Confidence (VC): The model says how sure it is (a number between 0 and 100) along with its final answer. If multiple tries give different answers, they first take the majority-vote answer, then average the confidence of the tries that picked that majority answer. Analogy: ask the student to rate their confidence, but only listen to the students who chose the final team answer.
- Self-Consistency (SC): This checks agreement across tries. It’s simply the fraction of tries that agree with the majority answer. Analogy: if 6 out of 8 tries say “B,” then SC is 6/8 = 0.75. More agreement usually means more confidence.
They also tested a combined signal (SCVC): a simple average of VC and SC. Analogy: consider both how sure the students feel and how much they agree.
To judge how good these signals are, they used AUROC, a scale-invariant score of “ranking quality.” In simple terms, AUROC asks: if you randomly pick one question the model got right and one it got wrong, how often does the uncertainty signal give a higher “confidence” to the right one? A score of 0.5 means random guessing; higher is better.
Because the model’s answers can vary from try to try, the authors generated a pool of answers per question and then repeatedly “sampled” different sets of K tries from this pool. This is like forming many small teams from a big class to see the average behavior and reduce the effect of luck.
Main Findings
- Both signals improve with more tries, but verbalized confidence starts stronger:
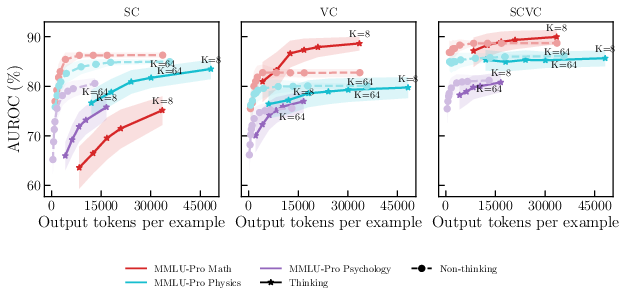
- When you only allow a few tries (like K=2), the model’s self-reported confidence (VC) already does a good job of telling right from wrong. Self-consistency (SC) also improves as you add tries, but it lags behind VC at the same budget and doesn’t catch up within the tested range.
- Combining the signals gives the biggest win, fast:
- The simple combo (SCVC) of “how sure the model says it is” plus “how much the tries agree” delivers the largest jump in quality with just two tries. In math tasks, this combo improved the score by about 13 AUROC points over using a single confidence report. Even if you give many more tries to either VC or SC alone, the two-try combo already beats them.
- After this early jump, more tries still help, but with diminishing returns.
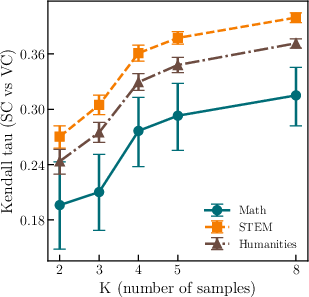
- Subject matters: math benefits most
- In math tasks, uncertainty estimates improve faster and combining signals works best. STEM and humanities also improve, but gains are smaller and plateau earlier.
- This likely happens because these reasoning models are especially well-tuned for math during training.
- Extra note on prompting styles
- Fancy ways of asking the model for confidence (special “judge” passes or complicated prompts) didn’t help much compared to simple, direct confidence reports.
- Since each extra try is costly for reasoning models (their chains of thought are long), the low-cost, two-try combo is usually the best deal.
Why It Matters (Implications)
- Practical recipe: If you can afford only a little extra compute, take two tries and combine signals. Don’t rely only on agreement (SC) or only on self-reported confidence (VC). The two together give a big, early boost and often beat deeper, more expensive sampling of either one alone.
- Safer and smarter use of AI: Good uncertainty estimates help decide when to trust the model, when to double-check, or when to ask a human. That’s especially important in sensitive areas like education support, scientific reasoning, health advice, or law, where being confidently wrong can be risky.
- Domain-aware expectations: Expect the strongest uncertainty quality and scaling in math. In other areas, the combo still helps, but improvements saturate sooner.
In short, the paper shows a simple, cost-effective way to get better “I might be wrong” signals from step-by-step reasoning AIs: take two tries, combine “how sure I feel” with “how much I agree with myself,” and you’ll usually get most of the benefit without paying for many more tries.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unexplored in the paper, organized to help future researchers design concrete follow‑ups.
Scope and generalizability
- Evaluate whether findings hold for larger/closed-source frontier reasoning models and different architectures (e.g., o-series, GPT‑4 class, larger R1 variants), not just mid-sized open-source models (8B–30B).
- Assess cross-lingual generalizability beyond English and across culturally diverse datasets.
- Test on additional task types beyond multiple-choice and short-form math (e.g., long-form generation, program synthesis, multi-hop planning, tool-augmented reasoning, real-world QA).
- Examine out-of-distribution and distribution-shift settings (e.g., adversarial, domain-shifted, or temporally shifted data) to evaluate robustness of uncertainty signals.
Metrics and evaluation design
- Go beyond AUROC to quantify calibration (ECE, Brier), risk–coverage/accuracy–coverage curves, decision-theoretic utility, and abstention performance; determine how to map SC, VC, and SCVC scores to calibrated probabilities usable for deployment.
- Characterize asymptotic scaling beyond K=8 and with larger independent pools (R≫10) to establish scaling laws and saturation points for SC, VC, and SCVC.
- Quantify compute-normalized efficiency: tokens or wall-clock per AUROC gain, and cost–benefit curves comparing “more samples” vs “deeper per-sample reasoning.”
- Validate bootstrap protocol sensitivity (e.g., vary R and the number of bootstrap draws) and compare to independent re-decoding to rule out artifacts from sampling within a small pre-generated pool.
Signal definitions and aggregation
- Investigate alternative aggregations:
- Averaging VC across all samples (not only those matching the majority) vs weighted averaging by VC; soft-vote or Bayesian aggregation of answers and confidences.
- Alternatives to uniform random tie-breaking for majority vote; assess tie-sensitive estimators.
- Develop and test non-linear or learned combinations of SC and VC (e.g., logistic/meta-models, isotonic/Platt calibration), and per-domain/per-task adaptive weighting rather than a fixed λ.
- Explore additional black-box signals and their complementarity (e.g., token-level entropy, final-answer log-prob, rationale agreement, diversity of solution paths, step-level self-evaluations, debate/critique signals, external verifier scores).
Sampling, decoding, and prompting
- Systematically study how decoding hyperparameters (temperature, top‑p), sampling strategies (beam/diverse beam), and prompt variants affect SC, VC, their correlation, and SCVC gains.
- Design and evaluate adaptive sampling policies (dynamic K) that stop early when uncertainty is low or when SC and VC converge/diverge, optimizing AUROC per token.
- Compare benefits of prompt diversity (different CoT styles, self-verify vs silent reasoning, different seeds) versus repeated sampling of a single prompt for uncertainty quality.
- Analyze trade-offs between increased chain-of-thought depth per sample and number of samples for fixed compute budgets; identify optimal allocation regimes by domain/task.
Domain- and training-related questions
- Causally test the hypothesis that RLVR post-training on math drives stronger scaling and complementarity by comparing models with/without RLVR, varying RLVR intensity, and extending RLVR to non-math domains.
- Conduct fine-grained, per-task and per-item difficulty analyses to understand where SC vs VC helps most (e.g., “easy” vs “hard” items; items requiring backtracking vs straightforward computation).
- Investigate why epistemic/verification-style elicitation underperforms in RLMs: which trace properties (length, structure, backtracking frequency) predict success/failure of VC variants?
Robustness, failure modes, and safety
- Test robustness of VC to prompt manipulation and adversarial attacks that inflate verbalized confidence without improving correctness; develop adversarially robust elicitation protocols.
- Characterize failure modes where SC misleads (spurious agreement, majority wrong) and where VC misleads (systematic over/underconfidence); build detectors/guards that route to additional sampling or external verification.
- Evaluate stability of SC and VC under small input perturbations, paraphrases, or formatting changes, and measure variance across random seeds.
Practical deployment considerations
- Provide calibrated, probability-valued SCVC suitable for thresholding in abstention systems and integrate with downstream decision policies (e.g., triage to human, tool use triggers).
- Compare judge-based approaches with elicitation under a unified cost model (extra pass vs extra sample) and explore “lightweight judges” that read summaries instead of full traces.
- Study privacy/compliance settings where CoT is suppressed from outputs or hidden from the uncertainty module, and quantify the impact on VC/SCVC quality.
Methodological transparency and reproducibility
- Specify and test answer normalization for free-form math (e.g., numeric equivalence rules) and assess its impact on AUROC; report sensitivity to grading heuristics.
- Release code, prompts, and per-question predictions to enable replication and fine-grained meta-analyses (e.g., disagreement cases between SC and VC).
- Report per-model/per-task token budgets and wall-clock costs to facilitate fair cost-adjusted comparisons across methods.
Practical Applications
Overview
This paper studies black-box uncertainty estimation for reasoning LLMs (RLMs) using:
- Verbalized confidence (VC): the model’s self-reported confidence.
- Self-consistency (SC): agreement across multiple sampled chains of thought.
- A simple hybrid (SCVC): the average of VC and SC.
Key empirical findings with practical consequences:
- VC is strong even at one sample; SC lags at comparable budgets.
- Most gains come from combining VC and SC: with just two samples (K=2), SCVC outperforms scaling either signal alone to K=8.
- Effects are domain-dependent: mathematics shows the fastest scaling and strongest complementarity; STEM/humanities improve less with additional samples.
Below are actionable applications and workflows informed by these results.
Immediate Applications
The following can be deployed now with today’s RLMs and standard inference stacks.
- Uncertainty-aware RLM API wrapper (Software, Platforms)
- Use case: Wrap any reasoning model with a two-sample uncertainty layer that:
- Samples K=2 chains, computes majority answer, VC (from answers matching the majority), SC, and SCVC.
- Returns the answer plus SC, VC, SCVC and a recommended action (answer, ask clarifying question, escalate, or sample more).
- Workflow: If SCVC ≥ τ_high → answer; if SCVC ≤ τ_low → abstain/escalate; else sample up to K=5 only when needed.
- Assumptions/dependencies:
- Model supports chain-of-thought and numeric confidence elicitation.
- Latency budgets allow one extra sample.
- Simple equal-weight SCVC (λ≈0.5) is robust; domain-specific thresholds may be needed.
- Cost-aware inference policy for production LLM/RLM systems (MLOps, Cloud)
- Use case: Maximize uncertainty quality per unit cost by preferring K=2 hybrid (SCVC) rather than deep sampling of a single signal.
- Tools/products:
- “Compute-aware sampler” that escalates from K=2→K=5 only when SCVC is mid-range.
- Early-stop when majority is decisive and VC is high.
- Assumptions: Token and latency budgets; streaming or parallel inference support.
- Human-in-the-loop escalation in customer support and enterprise assistants (Customer Support, Productivity)
- Use case: For responses with low SCVC, route to a human agent; show a confidence badge to the end user.
- Workflow: Two-sample hybrid gating; attach confidence and rationale summary to tickets.
- Assumptions: SLA-compatible latency; explainability needs satisfied by chain-of-thought storage policies.
- Safer content generation with selective abstention (Marketing, Legal, Policy Comms)
- Use case: Abstain or add disclaimers on low-SCVC outputs; request user confirmation on medium SCVC.
- Tools/products: “Selective generation toggle” in editors; compliance-aware templates triggered by low SCVC.
- Assumptions: Clear UX for deferral; storage rules for reasoning traces.
- Data labeling and active learning with uncertainty filtering (Data Ops, ML Ops)
- Use case: Use SCVC to filter auto-labeled data; send low-SCVC examples to human annotators; prioritize them for review.
- Products: “SCVC-driven labeler” for LLM-generated datasets; dashboards ranking items by SCVC.
- Assumptions: Consistent answer formats for majority voting; budget for K=2 per item.
- Evaluation, red teaming, and test selection (Security, QA, Safety)
- Use case: Use SCVC to identify high-risk queries and allocate human audit time; estimate residual risk via discrimination metrics (e.g., AUROC).
- Workflow: Bootstrap-based AUROC reporting at fixed K; set acceptance thresholds per domain.
- Assumptions: Access to evaluation datasets; acceptance criteria defined by governance.
- Education: adaptive tutoring and grading (Education Technology)
- Use case:
- Tutors show solutions when SCVC is high; ask for student input or hints when SCVC is mid; escalate to human instructor when low.
- Automated grading abstains on low SCVC, reducing false confident grading.
- Tools: “Two-attempt tutor mode” that runs K=2 by default; lightweight confidence UI for learners.
- Assumptions: Non-math subjects may see smaller gains; threshold tuning per subject.
- High-level planning and task execution gates (Robotics, Ops, RPA)
- Use case: Gate plan execution behind SCVC; request human confirmation when low; trigger tool use or alternative planners at mid SCVC.
- Workflow: Plan→SCVC gate→(execute | confirm | refine).
- Assumptions: Real-time constraints; mapping SCVC thresholds to action risk; logging for post-hoc analysis.
- Healthcare information and triage assistants (Healthcare, Patient Support)
- Use case: For non-diagnostic informational tasks, provide outputs only at high SCVC; otherwise defer with safety messaging or route to a clinician.
- Tools: Patient-facing assistant with confidence badges; automated triage flags based on SCVC.
- Assumptions: Not for autonomous diagnosis; regulatory compliance; human oversight.
- Finance assistants for compliance-aware drafting (Finance, Legal)
- Use case: Generate drafts when SCVC is high; add mandatory disclaimers and route to human review when low.
- Workflow: SCVC-conditioned compliance lane (auto-approve vs. review).
- Assumptions: Domain thresholds and audit logs; legal review for policy alignment.
- Research reproducibility and benchmarking (Academia)
- Use case: Adopt the paper’s bootstrap AUROC protocol at fixed K for reporting uncertainty discrimination; include SC, VC, SCVC breakdowns.
- Tools: Open-source evaluation harness mirroring the paper’s procedure.
- Assumptions: Access to multiple samples per item; standardized prompts (minimally guided elicitation is recommended).
- Prompting practice: prefer minimal elicitation over judge passes (All sectors)
- Use case: Reduce cost/latency by eliciting VC inline (VaEl) instead of a separate judge pass; combine with SC at K=2.
- Assumptions: Judge passes cost more and showed limited benefit; ensure models follow numeric confidence formatting.
Long-Term Applications
These require further research, scaling, regulatory approval, or ecosystem development.
- Domain-general RLVR and data for non-math tasks (Model Training, Foundation Models)
- Opportunity: The strongest scaling/complementarity occurs in math; extend RLVR-style post-training to STEM/humanities to improve SCVC quality elsewhere.
- Dependencies: High-quality verifiable reward signals beyond math; compute budgets; evaluation suites by domain.
- Calibrated probability from hybrid signals (ML Systems, Risk Management)
- Opportunity: Convert SCVC (discriminative but mis-scaled) into calibrated probabilities via post-hoc calibration (e.g., isotonic regression) or training-time objectives.
- Dependencies: Held-out data; stability across distribution shifts; governance for threshold setting.
- Stepwise uncertainty tracking for chain-of-thought (Agent Systems, Tool Use)
- Opportunity: Estimate uncertainty at intermediate steps to decide when to branch, call tools, or backtrack; use SCVC at step-level to drive agent behaviors.
- Dependencies: Instrumented CoT; step alignment and formatting standards; efficient partial resampling.
- Multi-agent debate and stopping criteria (Agentic AI)
- Opportunity: Use SCVC to decide when to terminate debates or solicit more agents; tie stopping rules to hybrid confidence thresholds.
- Dependencies: Debate frameworks; latency/compute constraints; robust consensus mechanisms.
- Distillation of hybrid uncertainty to single-pass models (Model Compression, Edge)
- Opportunity: Train student models to emulate SCVC with one pass, preserving uncertainty quality while cutting latency/cost.
- Dependencies: Teacher-student pipelines; suitable losses (discrimination + calibration); coverage across domains.
- Dynamic compute and hardware scheduling (Cloud, Inference Infra)
- Opportunity: Asynchronous, parallel sampling pipelines with early-exit on decisive SCVC; autoscaling policies conditioned on SCVC distributions.
- Dependencies: Orchestrators that batch K=2 efficiently; streaming majority vote; token-level preemption.
- Regulated decision support with documented uncertainty (Healthcare, Finance, Public Sector)
- Opportunity: Clinical decision support and financial advisory tools that report hybrid uncertainty, with thresholds defining human oversight triggers.
- Dependencies: Prospective validation, audits, and RCTs; regulator guidance on uncertainty reporting; trace retention policies.
- Standardized audits and procurement requirements (Policy, Governance)
- Opportunity: Require vendors to report uncertainty discrimination (e.g., AUROC) at declared sampling budgets and to log SC/VC/SCVC for high-stakes uses.
- Dependencies: Standards bodies and industry consortia; sector-specific benchmarks; privacy and retention frameworks for CoT.
- Curriculum-aware adaptive education at scale (Education)
- Opportunity: Use SCVC-driven gating to personalize instruction, decide when to provide hints vs. solutions, and measure student-model interactions.
- Dependencies: Longitudinal studies on learning outcomes; fairness and bias assessments across demographics and subjects.
- Tool-augmented problem solving triggered by low SCVC (Software Engineering, Scientific Computing)
- Opportunity: When SCVC is low, automatically invoke retrieval, formal solvers, test generation, or external calculators; when high, skip costlier tools.
- Dependencies: Tool integration; reliable detection of answer formats; latency budgets.
- Safety cases and red-team ops driven by uncertainty analytics (Trust & Safety, Security)
- Opportunity: Build safety cases that quantify uncertainty performance under defined K; drive red-team sampling policies based on SCVC strata.
- Dependencies: Incident taxonomies; cross-org data-sharing norms; standardized reporting templates.
Key Assumptions and Dependencies (cross-cutting)
- Model capabilities and prompts:
- RLMs must support chain-of-thought generation and numeric confidence elicitation with reliable formatting.
- Minimal elicitation prompts (e.g., VaEl) tend to work best; judge-based second passes are costlier with limited benefits.
- Compute, latency, and cost:
- K=2 adds noticeable latency; pipelines should support parallel sampling and early stops. Benefits are largest per unit cost at K=2.
- Domain dependence:
- Math benefits most from hybrid signals; non-math domains may need domain-specific thresholds or further training (e.g., RLVR) to realize similar gains.
- Metrics and thresholds:
- SCVC improves discrimination (AUROC), but not necessarily calibration; calibrated thresholds may require post-hoc calibration and per-domain tuning.
- Answer formatting and majority voting:
- Self-consistency relies on consistent answer extraction; enforce strict formatting and parsing rules to avoid spurious disagreements.
- Privacy and compliance:
- Chain-of-thought traces can include sensitive content; adopt retention and redaction policies aligned with sector regulations.
- Human oversight:
- For high-stakes applications (healthcare, finance, legal), low- or mid-SCVC outputs should route to human review; fully automated use requires further validation and regulatory approval.
Glossary
- Agreement-based signal: An uncertainty indicator derived from how often multiple independent generations agree on an answer. "combining introspection- and agreement-based uncertainty signals provides substantially larger gains"
- Area Under the Receiver Operating Characteristic (AUROC): A discrimination metric measuring how well confidence scores separate correct from incorrect answers. "Formally, AUROC measures the probability that a randomly chosen correct example receives a higher confidence score than a randomly chosen incorrect example."
- Brier score: A calibration metric that computes the mean squared error between predicted probabilities and outcomes. "Calibration metrics such as ECE \citep{guo2017calibration} or the Brier score \citep{brier1950verification} require meaningful probabilistic interpretation of the numeric scale."
- Chain-of-thought reasoning: A prompting/decoding approach where the model generates intermediate reasoning steps before the final answer. "under extended chain-of-thought reasoning."
- Context window: The maximum token length the model can attend to in a single sequence. "All models support context windows of at least 131K tokens, enabling extended chain-of-thought reasoning."
- Dense model: A neural network where all parameters are active for every input, as opposed to sparsely activated experts. "DeepSeek-R1-8B is a dense model obtained by fine-tuning an 8B Qwen base on reasoning traces from DeepSeek-R1 \citep{deepseekr1}."
- Epistemic Elicitation (EpEL): A prompting style that asks the model to explicitly reflect on and report its certainty. "Specifically, we adopt an Epistemic Elicitation (EpEL; \citealp{tian_just_2023}) instruction that encourages the model to reflect on its subjective certainty in the provided answer without revisiting the solution."
- Epistemic-markers judge (EpJu): A judge variant that assesses confidence using linguistic cues of certainty or hedging in the reasoning trace. "Epistemic-markers judge (EpJu). The judge attends to hedging language and certainty cues."
- Expected Calibration Error (ECE): A summary metric of how well predicted probabilities match empirical accuracies across bins. "Calibration metrics such as ECE \citep{guo2017calibration} or the Brier score \citep{brier1950verification} require meaningful probabilistic interpretation of the numeric scale."
- Hybrid estimator (SCVC): A combined uncertainty signal formed by linearly blending self-consistency and verbalized confidence. "With just two samples, the hybrid estimator (SCVC) improves AUROC by points in mathematics"
- Introspection-based signal: An uncertainty indicator derived from the model’s own stated confidence about its answer. "We study how introspection-based and agreement-based uncertainty signals scale with the number of test-time samples"
- Judge (approach): A two-pass method where a separate model invocation reviews the full reasoning trace to output a confidence score. "We study two families of verbalized confidence (VC) methods: elicitation \citep{xiong_can_2024}, where the model reports confidence alongside its answer, and judge approaches \citep{gu2025surveyllmasajudge}, where a separate pass reads the full reasoning trace and outputs a confidence score."
- Kendall’s tau: A rank correlation coefficient measuring ordinal association between two variables. "Figure~\ref{fig:kendall_sc_vc} reports Kendallâs between VC and SC."
- Macro-averaging: Averaging metric values equally across tasks or classes, regardless of their size. "Task-level AUROC is macro-averaged within domain, and model-level averages are computed within the same draw."
- Majority vote: Aggregation rule that selects the answer occurring most frequently across samples. "Let denote the majority-vote answer among ; ties are broken uniformly at random."
- Mixture-of-experts (MoE) model: An architecture that routes inputs to a subset of specialized expert sub-networks. "gpt-oss-20b and Qwen3-30B-A3B are mixture-of-experts models trained with Reinforcement Learning with Verifiable Rewards (RLVR)."
- Monte Carlo approximation: Using random sampling to approximate a distribution or expectation when exact computation is infeasible. "The per-question pool serves as a Monte Carlo approximation to the model's decoding distribution"
- Parallel sampling: Querying the same prompt multiple times independently to obtain diverse outputs for uncertainty estimation. "uncertainty estimation can also exploit parallel sampling, which queries the same prompt multiple times to obtain multiple samples."
- Reinforcement Learning with Verifiable Rewards (RLVR): A post-training method that optimizes models using rewards derived from verifiable correctness signals. "reasoning models undergo a key post-training procedure via reinforcement learning with verifiable rewards (RLVR), but this is primarily limited to mathematical domains."
- Reasoning LLM (RLM): A LLM tailored for extended deliberation that produces longer reasoning traces before answers. "Reasoning LLMs (RLMs) extend standard LLMs by extending test-time computation through extended chain-of-thought deliberation."
- Self-consistency (SC): An agreement-based confidence estimate computed as the fraction of samples that match the majority answer. "Self-consistency \citep{wang2022self} estimates confidence from agreement across sampled samples:"
- Stochastic decoding: Non-deterministic generation (e.g., via sampling) that introduces randomness into outputs. "under stochastic decoding where the variance from temperature sampling can be large."
- Temperature sampling: A randomness control in probabilistic decoding where higher temperature increases output diversity. "under stochastic decoding where the variance from temperature sampling can be large."
- Top-p sampling: Nucleus sampling strategy that draws from the smallest set of tokens whose cumulative probability exceeds p. "We use generation hyperparameters recommended by the model authors: temperature = 1.0 and top- = 1.0 for gpt-oss-20b, and temperature = 0.6 and top- = 0.95 for Qwen3-30B-A3B and DeepSeek-R1-8B."
- Verbalized confidence (VC): A model-reported numeric estimate of its own certainty about an answer. "Verbalized confidence uses the model's explicit confidence outputs as a black-box uncertainty signal"
- Verification elicitation (VeEl): An elicitation variant prompting the model to check its reasoning before stating confidence. "Verification elicitation (VeEl). The model is prompted to check its reasoning before assigning confidence."
- Verification judge (VeJu): A judge variant that assesses the validity and consistency of the reasoning steps to assign confidence. "Verification judge (VeJu). The judge evaluates the validity and consistency of reasoning steps."
- Vanilla elicitation (VaEl): A basic elicitation setup where the model outputs an answer and a confidence score in one pass. "Vanilla elicitation (VaEl). The model provides an answer and a confidence score."
- Vanilla judge (VaJu): A basic judge setup where a second pass reads the reasoning trace and outputs a confidence score. "Vanilla judge (VaJu). A second pass reads the full reasoning trace and outputs a confidence score."
Collections
Sign up for free to add this paper to one or more collections.