ELT: Elastic Looped Transformers for Visual Generation
Abstract: We introduce Elastic Looped Transformers (ELT), a highly parameter-efficient class of visual generative models based on a recurrent transformer architecture. While conventional generative models rely on deep stacks of unique transformer layers, our approach employs iterative, weight-shared transformer blocks to drastically reduce parameter counts while maintaining high synthesis quality. To effectively train these models for image and video generation, we propose the idea of Intra-Loop Self Distillation (ILSD), where student configurations (intermediate loops) are distilled from the teacher configuration (maximum training loops) to ensure consistency across the model's depth in a single training step. Our framework yields a family of elastic models from a single training run, enabling Any-Time inference capability with dynamic trade-offs between computational cost and generation quality, with the same parameter count. ELT significantly shifts the efficiency frontier for visual synthesis. With $4\times$ reduction in parameter count under iso-inference-compute settings, ELT achieves a competitive FID of $2.0$ on class-conditional ImageNet $256 \times 256$ and FVD of $72.8$ on class-conditional UCF-101.


















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ELT, short for Elastic Looped Transformers, a new way to build AI models that create images and videos. Instead of stacking lots of different layers (which makes models huge), ELT reuses the same small set of layers over and over in a loop. With a special training trick, the model learns to produce good results even if you stop the loop early. This makes ELT smaller, faster, and more flexible than many current models—while keeping the picture quality high.
What questions is the paper trying to answer?
- Can we make high-quality image and video generators that are much smaller (fewer “parameters”)?
- Can one model work well at different speed/quality settings, so it’s useful both on phones (fast, fewer loops) and in the cloud (slower, more loops)?
- How can we train such a looping model so that it produces good images not only at the final loop, but also in the middle?
How does ELT work? (Explained simply)
Think of making art by refining a sketch:
- Traditional big models are like hiring a huge team of different artists, each doing one pass and handing it off to the next.
- ELT is like hiring a small, very skilled team that revises the same drawing multiple times. The team is the same each pass (weight sharing), but each pass makes the picture better.
Two key ideas:
- Reusing a small block many times
- A “transformer” is a common AI building block used for language and vision.
- ELT uses a small block of transformer layers and repeats that block L times during each step of image generation.
- “Parameters” are the settings the model has learned (the knobs). Reusing the same block means far fewer knobs to store.
- Teaching the model to be good at every loop, not just the last
- Normally, if you loop a block, only the final pass gives a good image. If you stop early, the image looks bad.
- ELT fixes this with a training method called Intra-Loop Self Distillation (ILSD):
- Imagine a “teacher” and a “student” inside the same model: the teacher is the result after doing all the loops; the student is what you get after fewer loops.
- During training, the student learns from the teacher’s output, and also from the real target image. Over time, the student gets better, so if you stop early at fewer loops, you still get a good image.
- This makes the model “elastic”—you can choose how many loops to run at test time based on how much time or power you have.
Two common ways the model generates pictures (ELT works with both):
- Masked generation (like MaskGIT): Start with lots of blanks and repeatedly fill them in.
- Diffusion (like DiT): Start from noisy static and repeatedly remove noise to reveal a picture.
In both cases, ELT puts the looping block inside each step of the process, so each step can be refined more than once, using the same small set of layers.
Simple definitions:
- Parameters: the learned memory of the model. Fewer parameters = smaller model.
- Loops: how many times the same small block is applied to refine the image.
- Any-Time inference: you can stop early and still get a decent result—like a graphics “quality slider.”
What did they do to test ELT?
- They trained ELT for class-conditional image generation on ImageNet at 256×256 resolution (the model is told what class to draw, like “shih tzu” or “bird”).
- They also trained it for class-conditional video generation on UCF-101 (short action clips).
- They compared ELT to strong baselines in both masked generation and diffusion setups.
- They measured:
- Quality: FID for images (lower is better) and FVD for videos (lower is better).
- Size: number of parameters (how big the model is).
- Speed/compute: how much work (GFLOPs) and how many images per second (throughput).
Main findings and why they matter
- High quality with far fewer parameters:
- On ImageNet 256×256, ELT reached FID ≈ 2.0—on par with strong baselines—while using about 4× fewer parameters in some settings. That means much smaller models without losing image quality.
- Works well across different compute budgets (Any-Time inference):
- With standard looping (without ELT’s training), images look good only when you use the exact number of loops seen in training. If you change the loop count, quality drops a lot.
- With ELT’s ILSD training, images remain high quality across many loop counts. You can choose fewer loops for speed or more loops for the best possible quality, all with the same model.
- Faster and more efficient on hardware:
- Because the same small block is reused, most of the model’s weights can stay close to the chip’s fast memory. This reduces slow memory transfers and speeds up generation.
- On a TPU, ELT showed up to about 3.5× higher throughput than the baseline at larger model sizes.
- Good results in diffusion models too:
- In a diffusion setup, ELT matched or beat a deeper baseline while using fewer parameters, as long as there’s a reasonable minimum number of unique layers (you can’t shrink to just one unique layer and expect top quality; a small base is still needed).
- Predictable scaling:
- As you increase either model width (how “wide” the layers are) or the number of loops, quality tends to improve—but with diminishing returns. ELT lets you trade off loops and width to hit the best quality for your compute budget.
In short: ELT shifts the efficiency curve. You can get similar (or better) picture quality with smaller models and flexible compute.
Why this matters
- Runs well on different devices:
- Phones and edge devices can use fewer loops to save time and battery.
- Servers can use more loops for higher fidelity.
- Saves memory and cost:
- Smaller models are cheaper to store and easier to deploy.
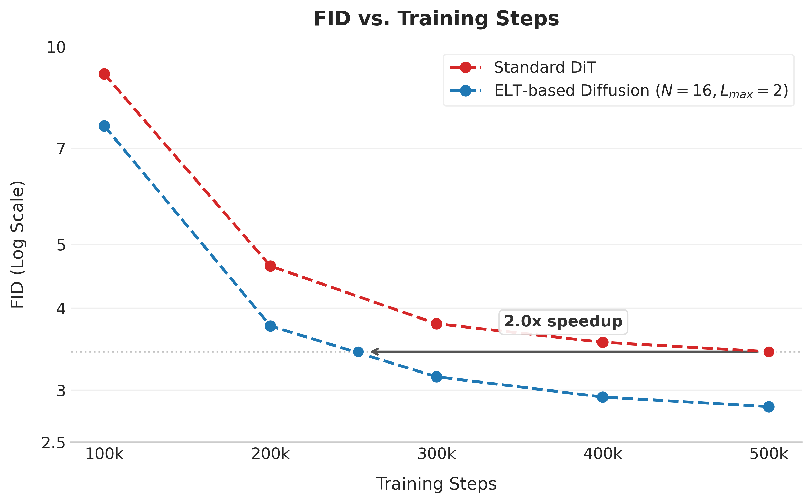
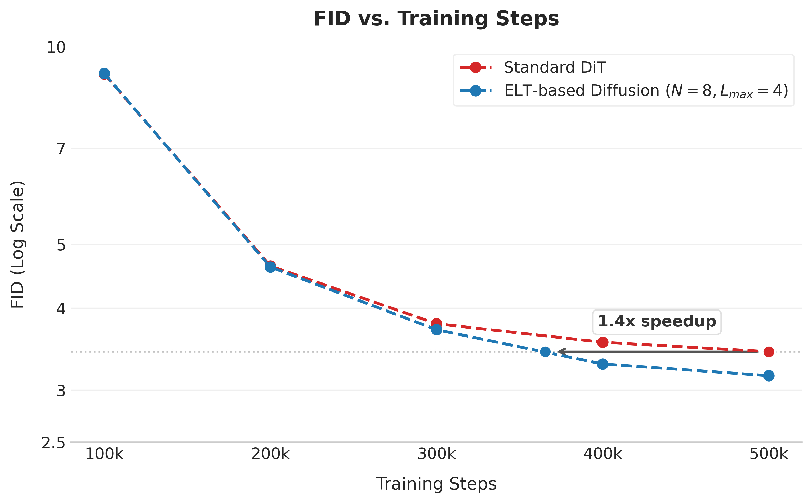
- Faster training and testing:
- The model converges quickly in some settings and can generate images faster due to fewer memory bottlenecks.
- A general idea that can travel:
- The “loop and distill” approach could help other tasks where you want strong results from small models that can adapt to different speed/quality needs.
Summary
ELT is a clever way to make image and video generators smaller and more flexible by reusing a small transformer block many times and training it so intermediate steps are already good. This enables “Any-Time” generation: one model that can run fast for okay results or take more time for great results—without retraining or changing the model size. It achieves competitive quality with far fewer parameters and can run faster on modern hardware.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
Methodology and theory
- Lack of theoretical analysis of looped dynamics: no convergence guarantees, fixed-point behavior, or stability analysis of repeatedly composing the shared block ; unclear when/why intermediate states approximate the “solution space.”
- No guidance on choosing the minimal number of unique layers () and loops () for a given width/depth to avoid failure modes (e.g., the observed collapse at ); no principled design rules or scaling laws for selection.
- Unclear role of loop-aware conditioning: whether explicit “loop index” embeddings or per-loop parameter modulation would improve stability/quality is untested.
- Potential accumulation of bias/periodicity from weight tying across many loops is not analyzed (e.g., recurring artifacts from repeated application of the same block).
ILSD training and ablations
- No ablation on the ILSD loss components: the relative impact of ground-truth vs. distillation terms, or sensitivity to the decay schedule of , is not studied.
- The choice of uniform Stochastic Student Sampling () is not justified; alternative sampling distributions or curricula (e.g., bias toward small early) are unexplored.
- No comparison to alternative distillation strategies (e.g., temperature scaling for discrete tokens, soft vs. hard targets, or offline/teacher-frozen variants).
- The claim of “minimal overhead” is not quantified: missing wall-clock training time, memory usage, and step-time breakdowns versus baselines and versus a no-ILSD looped model.
- No study of whether ILSD constrains or compromises final-loop () performance compared to optimizing only for final outputs.
Inference behavior and control
- Early-exit policies are not learned or adaptive: no halting/utility estimates (e.g., ACT-style) or stopping criteria to decide per input/sample at inference time.
- No analysis of output consistency across loops for the same seed (e.g., whether semantics remain stable as increases or whether changes are mostly refinement vs. drift).
- Interplay between loops per sampling step and total sampling steps () in diffusion is unexplored (e.g., trading loops within-step vs. fewer total steps).
- Compatibility with modern samplers (DDIM, DPM-Solver, EDM, flow matching, v-prediction) is not evaluated; only DDPM 512-step results are shown, potentially underestimating achievable efficiency/quality.
- For discrete-token generation, the effect of ILSD on token confidence calibration and error propagation in early exits is not measured.
Scope and generalization
- Limited conditioning setups: only class-conditional generation is evaluated; no text-to-image/video, image-to-image, or multi-modal conditioning (e.g., COCO, LAION, MSR-VTT).
- Resolution and data scale are constrained: no experiments beyond ImageNet 256×256, nor higher resolutions (512/1024) or larger-scale datasets to assess high-fidelity scalability.
- Video results (UCF-101) are insufficiently presented (truncated) and appear limited to short clips and low resolution; long-horizon, higher-res, or complex datasets (e.g., Kinetics, WebVid) are not studied.
- No evaluation under data-scarce regimes despite claims of robustness to overfitting; small-data or class-imbalanced settings are missing.
- No assessment of out-of-distribution robustness, compositional generalization, or transfer learning performance (e.g., finetuning ELT on new domains).
Comparisons and baselines
- Missing comparisons to other parameter-efficiency techniques (e.g., Mixture-of-Experts, low-rank/LoRA adapters, shared-block/U-Net weight-tying) under iso-inference-compute.
- No head-to-head with adaptive-depth methods (Universal Transformers with ACT, early-exit transformers) to quantify ELT’s advantages on elastic inference.
- Limited baselines for video; broader masked and diffusion video baselines are absent, making it hard to contextualize ELT’s video performance.
Metrics and diagnostics
- Quality metrics focus on FID/IS (images) and mention FVD (videos) without broader diagnostics (e.g., Precision/Recall, CLIPScore, human studies) to probe diversity, fidelity, or semantic alignment.
- Efficiency metrics omit power/energy, latency distributions, and peak memory footprint; GFLOPs alone can be misleading across hardware.
- Any-Time evaluation lacks formal Pareto analyses under varied deployment constraints (e.g., strict latency budgets, mobile vs. server).
Hardware and systems claims
- Throughput gains are only shown on a single TPU v6e configuration with batch size 8; generality across GPUs/TPUs, different batch sizes, and multi-device sharding is unverified.
- The “on-chip weight residency” claim lacks direct measurements (e.g., HBM↔SRAM traffic, cache hit rates) and end-to-end energy/latency profiles.
- No training memory usage measurements or profiling of activation checkpointing across loops, which are critical for practical deployment.
Practical design questions
- How to set and for ILSD, and how sensitive performance is to these choices, is not explored.
- Whether multiple intermediate students per batch (multi- supervision) improve elasticity vs. single-sample is unknown.
- Compatibility with guidance techniques (e.g., stronger classifier-free guidance, prompt-to-image guidance for discrete models) is not analyzed.
- Interaction with better tokenizers/codebooks (e.g., modern semantic tokenizers, binary tokens) is noted but untested within ELT.
- No investigation into auxiliary regularizers that might help looping (e.g., spectral norms, orthogonalization, or per-loop normalization tweaks).
These gaps suggest concrete next steps: develop adaptive halting for loops, expand evaluations to text-conditional and high-resolution settings with modern samplers, perform thorough ILSD ablations and hardware profiling, and derive theoretical insights for stable, convergent looped refinement.
Glossary
- Any-Time inference: The ability to flexibly stop inference early at various depths to trade off compute and quality without retraining. Example: "Any-Time inference capability"
- Autoregressive decoding: A generation process that produces tokens sequentially where each token depends on previously generated ones. Example: "In autoregressive decoding, images are generated sequentially, one pixel/token at a time, following a raster scan order"
- Classifier-free guidance: A diffusion sampling technique that improves conditioning by mixing conditional and unconditional predictions. Example: "we use classifier-free guidance by dropping class condition labels for of the training batches."
- Codebook: The discrete set of latent tokens used by a vector-quantized tokenizer. Example: "with a codebook size of 1024 tokens."
- DDPM: Denoising Diffusion Probabilistic Model; a class of diffusion models that iteratively denoise from noise to data. Example: "We train a DDPM-style diffusion model which operates on these latents using a DiT architecture."
- Diffusion models: Generative models that learn to reverse a noise corruption process to synthesize data. Example: "Diffusion models generate data by learning to reverse a process that gradually corrupts a signal into Gaussian noise through a predefined noise schedule."
- Diffusion Transformer (DiT): A transformer architecture for diffusion that treats image latents as token sequences. Example: "the Diffusion Transformer (DiT) architecture shifts away from this design"
- Elastic Looped Transformers (ELT): A recurrent, weight-shared transformer design for visual generation that supports elastic compute. Example: "We introduce Elastic Looped Transformers\ (ELT), a highly parameter-efficient class of visual generative models based on a recurrent transformer architecture."
- Fréchet Inception Distance (FID): A metric that measures the distance between real and generated image feature distributions; lower is better. Example: "ELT\ achieves a competitive FID of 2.0 on class-conditional ImageNet "
- Fréchet Video Distance (FVD): A metric that measures the distance between real and generated video feature distributions; lower is better. Example: "FVD of 72.8 on class-conditional UCF-101."
- GFLOPs: Giga floating-point operations; a measure of computational cost. Example: "we evaluate model efficiency using inference-time GFLOPs and throughput (samples generated per second)."
- HBM-to-SRAM transfers: Data movement between high-bandwidth memory and on-chip static RAM that can bottleneck throughput. Example: "reducing repeated HBM-to-SRAM transfers."
- Intra-Loop Self Distillation (ILSD): A training method where intermediate loop outputs (student) are distilled from the full-depth output (teacher) within the same model. Example: "we propose the idea of Intra-Loop Self Distillation (ILSD), where student configurations (intermediate loops) are distilled from the teacher configuration (maximum training loops)"
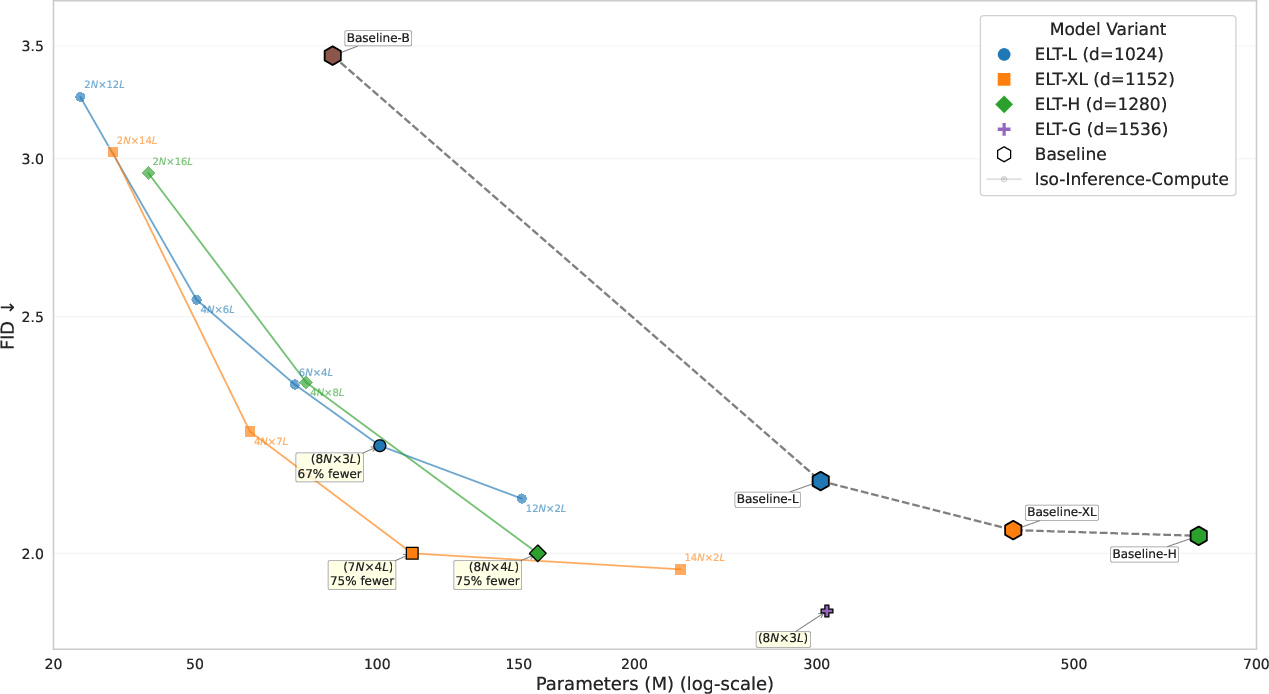
- Iso-inference-compute: Comparing models under equal inference compute budgets to assess parameter efficiency fairly. Example: "under iso-inference-compute settings"
- Masked Generative Image Transformer (MaskGIT): A non-autoregressive image generator that predicts all tokens in parallel with iterative refinement. Example: "Masked Generative Image Transformer (MaskGIT) introduced a novel approach to image generation that significantly differs from traditional autoregressive models."
- "Memory wall" bottleneck: The performance limit imposed by memory bandwidth/latency relative to compute speed. Example: "by minimizing the ``memory wall'' bottleneck."
- MLM head: A masked language modeling head used to predict masked tokens from intermediate representations. Example: "allowing the model to exit early and predict from any intermediate block via a shared MLM head."
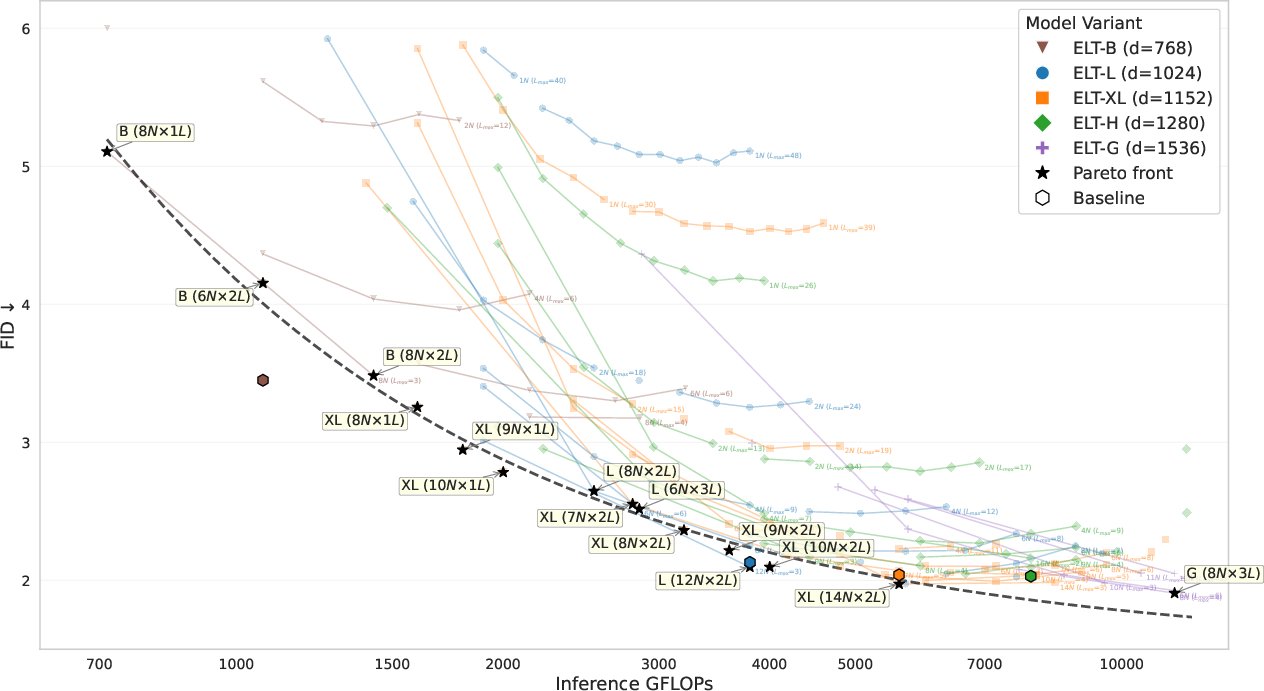
- Pareto front: The set of configurations that achieve the best trade-offs between competing objectives (e.g., quality vs. compute). Example: "Pareto front of FID vs. Inference GFLOPs."
- Raster scan order: A sequential order that traverses image pixels or tokens row by row. Example: "following a raster scan order"
- Recurrent transformer architecture: A transformer that applies the same block multiple times (with shared weights) to deepen computation. Example: "based on a recurrent transformer architecture."
- Shifted cosine noise schedule: A specific schedule for diffusion timesteps that shapes noise levels via a shifted cosine function. Example: "We employ a shifted cosine noise schedule and sigmoid-weighted MSE loss for training"
- Sigmoid-weighted MSE: A mean squared error loss scaled by a sigmoid function of time in diffusion training. Example: "We employ a shifted cosine noise schedule and sigmoid-weighted MSE loss for training"
- Stochastic Student Sampling (S3): Randomly selecting an intermediate loop count for the student path during training to diversify supervision depths. Example: "Stochastic Student Sampling ():"
- Stop-grad: A training operation that prevents gradients from flowing through specific tensors (teacher outputs). Example: "where sg is stop-grad for teacher ($L_{\text{max}$) in ILSD,"
- Universal Transformers: A model that popularized looping a transformer block to share parameters across depth. Example: "looping of transformers was popularized by Universal Transformers"
- VAE: Variational Autoencoder used here as the latent tokenizer/decoder in latent diffusion setups. Example: "We use a pretrained Stable Diffusion v1.4 VAE model to map images into a continuous latent space"
- Vector Quantized (VQ) autoencoders: Models that compress data into discrete codebook indices for token-based generation. Example: "The tokens are discrete and obtained using Vector Quantized (VQ) autoencoders, learned with self-reconstruction and photo-realism losses"
- Weight-shared transformer blocks: Transformer blocks whose parameters are reused across multiple loop iterations to reduce model size. Example: "weight-shared transformer blocks"
- Weight-tied (looped) transformer: A transformer where the same parameters are tied and applied repeatedly to simulate greater depth. Example: "In a standard weight-tied (looped) transformer, the model is typically optimized only for its final output after fixed $L_{\text{max}$ iterations"
Practical Applications
Overview
Elastic Looped Transformers (ELT) introduce a recurrent, weight-shared transformer block for visual generation (images and videos), trained with Intra-Loop Self Distillation (ILSD) so intermediate loop outputs are high quality. This yields:
- Any-Time inference: a single model can “dial” compute up/down at test time by varying loop count L, trading latency for fidelity without retraining.
- Parameter efficiency: 2–4× fewer parameters than comparable baselines at similar quality; higher throughput by keeping shared weights on-chip and reducing memory transfers.
- Generality across masked-token (e.g., MaskGIT/MAGVIT) and diffusion transformer (DiT) families.
Below are concrete applications, organized by deployment horizon, with sectors, potential tools/workflows, and key assumptions/dependencies.
Immediate Applications
The following can be prototyped or deployed now using the paper’s methods and reported performance.
- Tiered-quality image generation services with “compute-as-a-knob” (Software/Cloud, Media/Advertising)
- What: Serve class-conditional image generation with a quality slider that maps to loop count L, enabling low-latency previews and high-fidelity finals from one model.
- Tools/workflows:
- ELT-based inference API with L as a request parameter.
- Autoscaling middleware to set L based on SLA/queue length.
- A/B tests for quality-vs-latency budgets.
- Assumptions/dependencies:
- Training with ILSD to ensure intermediate loops maintain quality.
- Hardware/compiler support to keep shared weights resident on-chip for throughput gains.
- Preview→Refine UX for creative tools (Content creation platforms, DCC apps)
- What: Instant coarse previews (low L) that refine to production quality (high L) without model switches.
- Tools/workflows:
- “Progressive refine” button/slider tied to loop count.
- Batch finalization pipeline executing higher L during export.
- Assumptions/dependencies:
- Stable, consistent outputs across loop counts (provided by ILSD).
- Integration with existing tokenizers/VAEs and content pipelines.
- On-device generative features under tight memory/latency (Mobile/Edge, Consumer apps)
- What: AI photo editing, background replacement, style transfer, simple class-conditional assets, running offline with adjustable quality.
- Tools/workflows:
- ELT inference kernels for mobile NPUs/GPUs (e.g., Core ML/NNAPI/TensorRT).
- Power-aware loop scheduling (fewer loops on battery, more when plugged in).
- Assumptions/dependencies:
- Quantization/compile support for recurrent blocks and shared-weights loops.
- Mobile-capable tokenizer (VQ-VAE) or latent diffusion VAE.
- Throughput-optimized inference in data centers (Cloud/Infrastructure)
- What: Increase images/sec by reducing HBM↔SRAM transfers via compact shared weights; prioritize ELT for tiers where baseline models are memory-bound.
- Tools/workflows:
- XLA/TVM graph-level fusion to keep ELT parameters on chip across loops.
- Model placement and batching tuned for looped compute.
- Assumptions/dependencies:
- Accelerators with sufficient on-chip SRAM and compiler support (e.g., TPU v6e-like setups).
- Parameter sets small enough to reside on chip.
- Cost/energy-aware serving for sustainability (Energy/Policy, FinOps)
- What: Dynamically lower L to reduce energy/cost per request during peak loads; report lower carbon per generated image at equivalent perceived quality.
- Tools/workflows:
- Budget-aware scheduling that adapts L to carbon or dollar quotas.
- Cost/energy telemetry per loop configuration.
- Assumptions/dependencies:
- Reliable quality metrics vs. L mapping for service-level guarantees.
- Organizational reporting frameworks for energy/cost attribution.
- Efficient training and research in compute-limited labs (Academia/Research)
- What: Replicate high-fidelity class-conditional generation with fewer parameters; apply ILSD to study recurrent refinement and scaling laws.
- Tools/workflows:
- Open-source ELT layers and ILSD trainer (PyTorch/JAX).
- Benchmarks that report FID/FVD vs parameters and GFLOPs.
- Assumptions/dependencies:
- Access to standard datasets (ImageNet, UCF-101) or domain-specific data.
- Existing tokenizers/VAEs compatible with ELT backbones.
- Low-latency social video features with adjustable fidelity (Media/Social, Video gen)
- What: Short class-conditional clips or templated motions with loop-controlled latency for mobile/social contexts.
- Tools/workflows:
- MAGVIT-style tokenizers with ELT backbones.
- Serving profiles by device tier: low L for entry phones, higher L for flagships.
- Assumptions/dependencies:
- Video tokenization quality and compute budgets on-device/cloud.
- Stability in intermediate frames at low L (validated by ILSD).
- Privacy-preserving on-device generation (Policy/Privacy, Mobile)
- What: Keep prompts and content local by performing generation on device at acceptable quality.
- Tools/workflows:
- On-device ELT inference with loop-controlled latency.
- Optional cloud refinement using higher L for users who opt in.
- Assumptions/dependencies:
- Sufficient device compute for low-L runs.
- UX to disclose/privacy-opt choices.
Long-Term Applications
These need further research, scaling, or engineering to mature.
- Text-to-image/video with any-time inference (Creative AI, Media, Software)
- What: Extend ELT+ILSD to large text-conditioned diffusion transformers, enabling prompt-driven generation with loop-controlled QoS.
- Tools/products:
- “ELT for DiT” with cross-attention and classifier-free guidance tuned for text.
- SDKs exposing semantic quality vs compute controls for UGC platforms.
- Assumptions/dependencies:
- Training at scale on multimodal datasets and handling long-context conditioning.
- Maintaining consistency and style across loop counts at larger scales.
- Generative video codecs and bandwidth-adaptive decoding (Streaming/Compression)
- What: Use ELT decoders to progressively refine frames as bandwidth/latency allows, improving quality when resources are available.
- Tools/workflows:
- Hybrid codec stacks with generative post-processing that increases L as buffer allows.
- Rate-control integrated with loop scheduling.
- Assumptions/dependencies:
- Integration with existing codec standards and real-time constraints.
- Robust perceptual quality under varied L and network dynamics.
- Onboard world models for robots/AR with compute-aware refinement (Robotics, AR/XR)
- What: Generative predictors (e.g., scene hallucination, inpainting) that adjust loop counts to fit tight real-time budgets on edge hardware.
- Tools/workflows:
- Control-loop policies that set L based on latency budget.
- Safety validation for generative predictions in the loop.
- Assumptions/dependencies:
- Domain-specific training (egocentric robotics data).
- Strict latency and reliability guarantees.
- Hardware–software co-design for recurrent generative inference (Semiconductors, Systems)
- What: Architectures and compilers that pin shared weights on-chip across loops; dynamic-halting/early-exit primitives optimized for ELT.
- Tools/products:
- SRAM-rich accelerators, weight-staging caches, loop kernels.
- Compiler passes to detect and optimize recurrent blocks.
- Assumptions/dependencies:
- Vendor roadmaps to expand on-chip memory and control-flow optimizations.
- Standardized IR patterns for looped transformers.
- Domain-specific ELT for healthcare imagery and scientific data (Healthcare, Scientific computing)
- What: Parameter-efficient generative augmentation or enhancement under strict compute and data constraints; potential on-device support for privacy.
- Tools/workflows:
- Fine-tuned ELT on medical/scientific modalities (with appropriate VAEs/tokenizers).
- Validation pipelines for clinical/regulatory compliance.
- Assumptions/dependencies:
- Extensive safety/efficacy studies and regulatory approval.
- Bias and hallucination risk management; constraints on generative use.
- Standards and SLAs for “any-time” generative services (Policy/Standards, Cloud)
- What: Industry benchmarks and APIs guaranteeing quality tiers tied to loop counts; pay-per-quality pricing models.
- Tools/workflows:
- Quality metrics aligned with human perception for multiple L.
- API standards exposing quality/latency knobs.
- Assumptions/dependencies:
- Cross-vendor agreement on metrics and test suites.
- Transparent reporting of compute/energy per quality tier.
- Cross-modal extensions (Audio, Multimodal, Code)
- What: Apply ILSD-guided looping to other generative domains (audio synthesis, multimodal video-audio, or even LLMs) for any-time inference.
- Tools/workflows:
- Recurrent blocks with shared weights and early-exit decoders per domain.
- Assumptions/dependencies:
- Task-specific losses and tokenizers/latents.
- Demonstrations that intermediate loops are semantically usable beyond vision.
- Continual and low-parameter adaptation (MLOps, Enterprise)
- What: Combine ELT with parameter-efficient fine-tuning (e.g., LoRA) for fast domain/style adaptation with loop-aware distillation.
- Tools/workflows:
- PEFT layers integrated into looped blocks; per-tenant adapters.
- Assumptions/dependencies:
- Stability of ILSD under adapter training.
- Tooling for managing multiple adapters and loop schedules.
- Content authenticity and watermarking consistent across loops (Safety/Trust)
- What: Watermarks that persist and remain detectable at different loop counts.
- Tools/workflows:
- Loop-consistent watermarking embedded in the generative path.
- Assumptions/dependencies:
- Robustness of watermarking to loop variation and downstream edits.
- Agreement on authenticity standards.
Notes on General Dependencies
- Tokenizers/VAEs: Masked-token ELT requires VQ-VAE-like tokenizers; diffusion ELT relies on latent VAEs (e.g., Stable Diffusion VAE). Quality of these strongly affects outcomes.
- Hardware behavior: Throughput gains assume the shared parameter block fits on-chip and compilers avoid reloading between loops; benefits may vary by accelerator.
- Training regime: ILSD requires careful λ scheduling and sampling of intermediate L_int; reproducible results need the outlined curricula.
- Task conditioning: Paper demonstrates class-conditional setups; extending to rich text prompts or multi-conditional inputs needs additional engineering and data.
- Evaluation alignment: FID/FVD are proxies; product deployments should include task-specific human evaluation and safety checks.
Collections
Sign up for free to add this paper to one or more collections.