Vision-Language Models as Differentiable Semantic and Spatial Rewards for Text-to-3D Generation
Abstract: Score Distillation Sampling (SDS) enables high-quality text-to-3D generation by supervising 3D models through the denoising of multi-view 2D renderings, using a pretrained text-to-image diffusion model to align with the input prompt and ensure 3D consistency. However, existing SDS-based methods face two fundamental limitations: (1) their reliance on CLIP-style text encoders leads to coarse semantic alignment and struggles with fine-grained prompts; and (2) 2D diffusion priors lack explicit 3D spatial constraints, resulting in geometric inconsistencies and inaccurate object relationships in multi-object scenes. To address these challenges, we propose VLM3D, a novel text-to-3D generation framework that integrates large vision-LLMs (VLMs) into the SDS pipeline as differentiable semantic and spatial priors. Unlike standard text-to-image diffusion priors, VLMs leverage rich language-grounded supervision that enables fine-grained prompt alignment. Moreover, their inherent vision language modeling provides strong spatial understanding, which significantly enhances 3D consistency for single-object generation and improves relational reasoning in multi-object scenes. We instantiate VLM3D based on the open-source Qwen2.5-VL model and evaluate it on the GPTeval3D benchmark. Experiments across diverse objects and complex scenes show that VLM3D significantly outperforms prior SDS-based methods in semantic fidelity, geometric coherence, and spatial correctness.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Vision–LLMs as Helpers for Making 3D Objects From Text: A Simple Explanation
1) What is this paper about?
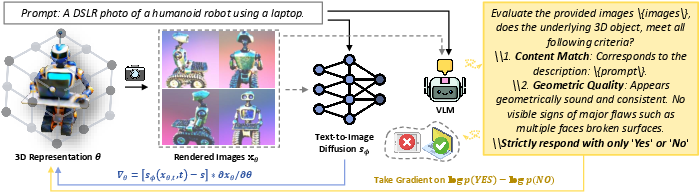
The paper shows a new way to turn a sentence (like “a red apple on a plate beside a green apple”) into a 3D model you can look at from all sides. The authors build a system called VLM3D that uses a special kind of AI, a vision–LLM (VLM), as a smart “judge” to keep the 3D result true to the words and physically consistent from every angle.
2) What problems are they trying to solve?
Here are the two big challenges they tackle:
- Fine‑grained understanding: Many older methods only “roughly” understand the text. They may miss small details (like “holding a sword” or “beside the plate”).
- 3D consistency: Some methods make objects that look okay from one angle but weird from another (for example, a face that looks doubled when seen from different sides—often called the “Janus problem”).
3) How does their method work?
Think of the system as a 3D artist that keeps improving its sculpture by showing it to two “teachers” again and again:
- Teacher A: a powerful image generator (a diffusion model) that knows what things should look like in pictures.
- Teacher B: a vision–LLM (VLM) that can read the text and look at multiple images to decide if the 3D model matches the description and is geometrically sound.
Here’s the process in everyday terms:
- Start with a rough 3D object. Render it from several viewpoints (like photos taken around the object).
- The diffusion teacher gives guidance so the images look realistic and match the style expected for the text.
- The VLM teacher looks at all the views together and answers two strict yes/no questions: 1) Does this match the text description (content)? 2) Do the views fit together into a single solid, consistent 3D object (geometry)?
- The VLM doesn’t just say “Yes” or “No”—it also gives a score under the hood that says how confident it is. The system uses that score to nudge the 3D model in the right direction. You can imagine a “hotter/colder” game: higher “Yes” confidence means you’re getting hotter (better); lower means colder (worse).
- Early on, the system follows the VLM teacher more strongly to get the right overall shape and relationships. Later, it leans more on the diffusion teacher to polish textures and fine details. This “balance shift” helps it get both accurate and pretty results.
Technical note explained simply: The authors made the VLM’s scoring work in a way the computer can use directly to adjust the 3D model automatically (they kept the score “differentiable,” which just means the model can learn from it step by step).
4) What did they find?
The new method, VLM3D, did better than previous approaches on a standard benchmark (GPTEval3D) across all measures:
- Better at matching the text (it listens to details like “using a laptop,” “spilling out of a bag,” or “blue shirt”).
- Better 3D consistency (fewer weird multi‑face or floating‑part issues).
- Better overall quality (textures and shapes look good together).
Examples they highlight:
- A statue description with two people in a kissing pose: VLM3D includes both figures and key pose details, while a baseline method misses one of them.
- A knight “holding a sword” vs. not holding one: VLM3D adds or removes the sword correctly when the prompt changes.
- Apples “inside” a plate vs. “beside” the plate: VLM3D gets the spatial relationship right.
- Multi‑object scenes (like multiple instruments on a stage) are handled more accurately.
They also ran “ablation” tests (turning certain features off to see what breaks). When they removed:
- The geometry check question, or
- The multiple camera views (only one view given), the models showed more errors, like double faces or broken parts. This proves their two‑question design and multi‑view setup really matter.
5) Why does this matter and what’s next?
Impact:
- Easier, more reliable 3D creation from plain text could help game designers, filmmakers, AR/VR creators, teachers, and students quickly build 3D content without expert modeling skills.
- The method shows that letting a vision–LLM “judge” the fit between words and images can teach a 3D system to be both accurate and consistent.
Limitations and future ideas:
- Very long or super‑detailed prompts can still be challenging—some fine details may be missed.
- The authors suggest splitting the VLM’s judging into two separate “heads” (one for content, one for geometry) and using smarter instructions so the VLM captures even more subtle details.
In short, VLM3D blends two kinds of AI teachers—one for visual realism and one for language‑aware checking—to make better 3D models from text, especially for tricky details and solid 3D structure.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, concrete list of gaps and unresolved questions that future researchers could address to strengthen, generalize, and validate the proposed VLM3D framework.
- Reward formulation and gradient quality
- The binary Yes/No log-odds reward may yield saturated or sparse gradients; evaluate alternative reward shapes (temperature scaling, margin losses, calibrated log-probs, or multi-class/multi-attribute scores) and their impact on convergence and fidelity.
- Quantify and mitigate “reward hacking,” where the generator produces images that exploit VLM quirks without genuinely improving 3D geometry (e.g., adversarial textures or view-specific illusions).
- Analyze gradient signal quality through the VLM (e.g., saliency/attribution across views) and its stability under different prompts, view counts, and resolutions.
- Scope and robustness of the VLM backbone
- Generalization beyond Qwen2.5-VL 7B is untested; benchmark multiple VLMs (sizes, training regimes, open vs. closed-source) to assess reward reliability, prompt sensitivity, and spatial reasoning differences.
- Evaluate multilingual prompts and cross-lingual consistency, including mixed-language descriptions and culturally specific attributes, to understand language coverage and bias.
- Multi-view design and view selection
- The choice of eight random views is heuristic; study how view count, distribution (coverage of azimuth/elevation), and curriculum strategies affect 3D consistency and the Janus problem.
- Investigate per-view weighting or view-specific rewards (e.g., aggregating per-view logits or attention) to localize and correct geometry errors observed only in certain viewpoints.
- Separation and attribution of semantic vs. geometric feedback
- The current dual-query prompt shares a single reward; assess separate heads or decoupled losses for semantic alignment and geometric consistency and quantify trade-offs (e.g., a Pareto frontier).
- Explore structured, attribute-level rewards (e.g., scene graph/relationship checks, object counts, color/texture attributes) to target fine-grained details that remain missed in long/dense prompts.
- Evaluation methodology and metrics
- Reliance on GPTEval3D (GPT-4o-mini Elo) lacks validated human correlation; conduct controlled human studies and inter-rater reliability analyses.
- Introduce objective 3D metrics: multi-view consistency scores, normal/curvature consistency, watertightness, self-intersection counts, mesh repair metrics, contact/penetration checks in multi-object scenes, and spatial relation correctness with ground-truth synthetic scenes.
- Measure diversity across seeds and prompts (e.g., distributional coverage, mode collapse risk) rather than only best-case examples.
- Scalability, compute, and efficiency
- Backpropagating through a 7B VLM increases memory/compute; profile step-time breakdown, memory footprint, and scalability to larger VLMs or higher-resolution renderings, and test optimizations (gradient checkpointing, mixed precision, sparse backprop).
- Assess performance on consumer GPUs, distributed training, or parameter-efficient techniques (LoRA, adapters) to broaden practical usability.
- 3D representation coverage
- The pipeline is demonstrated primarily with NeRF; quantify the impact and compatibility with 3D Gaussian Splatting, mesh-based (DMTet), voxel, and hybrid representations for speed, editability, and downstream use (animation, manufacturing).
- Provide systematic mesh-quality evaluations (watertightness, topology correctness, repairability) and test integration with geometry processing pipelines.
- Complex/multi-object scene control
- Spatial relation reasoning is demonstrated qualitatively; establish tasks with precise object counts, positions, orientations, and occlusions, with measurable relational accuracy against ground truth.
- Study failure modes in crowded scenes, severe occlusions, and fine-grained interactions (contact, support, containment), including explicit penalties for physically implausible configurations.
- Long and fine-grained prompts
- The framework still misses nuanced attributes in long/detailed descriptions; evaluate hierarchical prompting (global → local → part-level), iterative refinement, and attribute-specific subqueries to improve recall of small features and relational details.
- Compare single-pass vs. multi-pass VLM feedback loops (e.g., critique-and-revise) and quantify gains on curated long-prompt benchmarks.
- Integration strategy between SDS and VLM reward
- The annealing schedule for λ_VLM is fixed; investigate adaptive schedules (e.g., reward variance, geometry error proxies) and principled optimization (trust-region, alternating optimization, bilevel training).
- Theoretical analysis of convergence and stability under combined SDS + VLM gradients is missing; provide conditions or empirical diagnostics to predict/avoid instability.
- Robustness to prompt phrasing and negative constraints
- Measure sensitivity to paraphrases and negations (“not holding a sword,” “no stripes”) and develop prompt-invariant rewards (e.g., canonicalized attribute checks).
- Support explicit constraints and hard negatives (e.g., “no intersecting geometry,” “exactly three objects”) with verifiable satisfaction checks.
- Extensions not explored
- Video/4D generation: Qwen2.5-VL includes video reasoning, yet text-to-4D or time-consistent 3D dynamics are not studied.
- Image-conditioned 3D generation with text edits (image+prompt) and multimodal constraints (e.g., sketches, depth) remain unexplored.
- Physics-aware rewards (stability, balance, dynamics) and material/lighting consistency are not incorporated.
- Bias, fairness, and safety
- VLM-based rewards may inherit dataset biases; audit outputs across demographics, cultures, and sensitive attributes, and study mitigation (debiasing rewards, constrained optimization).
- Safety/content filters and misuse prevention when optimizing against powerful multimodal rewards are not discussed.
- Reproducibility and engineering details
- The gradient-preserving image preprocessor is critical yet unspecified; document modifications, validate that they do not degrade VLM accuracy, and provide ablations of preprocessing choices (resize, crop, normalization).
- Clarify how “binary-classification head” is realized in Qwen2.5-VL (token log-prob vs. explicit head), and test robustness across different prompt templates and decoding settings.
Glossary
- 3D Gaussian Splatting (3DGS): A fast 3D representation that models scenes with collections of Gaussian primitives for efficient rendering. "Neural Radiance Field (NeRF) or 3D Gaussian Splatting (3DGS)"
- Absolute time encoding: A representation technique that injects absolute temporal positions into a model to improve long-range video reasoning. "Qwen2.5-VL employs dynamic resolution processing to natively handle variable-size images and absolute time encoding for precise long-range video reasoning"
- Annealing schedule: A training strategy that gradually reduces a weight or temperature to improve convergence and stability. "Empirically, this annealing schedule accelerates convergence, suppresses view‑inconsistency artifacts, and yields high-fidelity 3D assets"
- Autoregressive LLM: A generative model that predicts tokens sequentially, conditioning on previously generated tokens. "Modern large VLMs extend this foundation by integrating a powerful autoregressive LLM with a visual encoder"
- Binary-classification head: The final layer(s) of a model that output logits for two classes (e.g., Yes/No). "Then we extract the final “Yes” and “No” logits of the VLM’s binary‑classification head"
- Contrastive learning: A training paradigm that pulls matched pairs together and pushes mismatched pairs apart in embedding space. "employ a dual‑encoder architecture trained via contrastive learning on hundreds of millions of image–text pairs"
- Cosine similarity: A metric measuring the angle between two vectors, commonly used to compare embeddings. "By maximizing cosine similarity for matched pairs and minimizing it for mismatched ones"
- Dense grounding: Mapping text to specific regions or objects in images with fine-grained localization. "open‑ended tasks such as image captioning, visual question answering, dense grounding, and dialogue"
- Denoising score matching: A technique to train score-based models by matching gradients of log densities via noise-perturbed samples. "A neural network s_\phi(\mathbf{x},y,t)\approx\nabla_{\mathbf{x}\log p_t(\mathbf{x}\mid y) is trained via denoising score matching to approximate the score function:"
- Differentiable human‑preference rewards: Learned reward functions reflecting human preferences that support gradient-based optimization. "enhance texture and detail via differentiable human‑preference rewards or non‑differentiable preference‑guided optimization"
- Differentiable renderer: A rendering system that supports backpropagation of gradients from images to 3D parameters. "by optimizing a differentiable renderer against a Score Distillation Sampling (SDS) loss"
- Diffusion coefficient: The term g(t) in an SDE controlling the amount of noise injected at each timestep. "f is the drift, g the diffusion coefficient"
- DMTet: A differentiable tetrahedral mesh optimization framework used for mesh refinement. "complementary refinement techniques—such as Deepmesh (for point cloud to mesh conversion) and DMTet—can be employed to further enhance and fine-tune 3D assets generated by SDS"
- Dual‑encoder architecture: A design with separate encoders for vision and language whose outputs are aligned in a shared space. "employ a dual‑encoder architecture trained via contrastive learning"
- Dual‑query prompt: A prompt design that issues two targeted Yes/No queries to enforce both content alignment and geometric quality. "Its dual‑query prompt—one for content matching and one for geometric consistency and quality—simultaneously enforces semantic fidelity, geometric coherence, and spatial correctness"
- Dynamic resolution processing: A vision module that natively handles varying image sizes for improved spatial understanding. "Qwen2.5-VL employs dynamic resolution processing to natively handle variable-size images"
- Dynamic schedule (for λ_VLM): A time-varying weighting strategy that adjusts the influence of the VLM reward during training. "We adopt a dynamic schedule for λ_VLM during VLM3D training"
- Generative priors: Knowledge captured by generative models that guides synthesis toward plausible outputs. "This approach effectively distills 2D generative priors into the 3D domain"
- GPTEval3D: A benchmark that uses GPT-based evaluators to score text-to-3D results on multiple criteria. "Evaluation is conducted on the public GPTEval3D benchmark"
- Janus problem: A multi-view inconsistency where an object exhibits conflicting appearances from different angles. "the “Janus problem,” where an object appears inconsistently from different angles"
- KL divergence: A measure of discrepancy between probability distributions often used as a loss in generative modeling. "The SDS loss is then formulated as the weighted KL divergence between the distribution of noised renderings and the text‑conditioned diffusion prior"
- Latent diffusion prior: A diffusion model operating in a compressed latent space that serves as a supervisory signal. "a low‑resolution NeRF is first optimized under a latent diffusion prior"
- Log‑odds: The difference between the log probabilities of two classes (e.g., Yes vs. No). "We define the VLM reward as the log‑odds of a “Yes” response:"
- Logits: Unnormalized scores output by a classifier before applying a softmax to obtain probabilities. "extract the final “Yes” and “No” logits"
- Multi‑view inconsistencies: Artifacts where different views of the same 3D object do not agree geometrically or semantically. "can suffer from multi‑view inconsistencies such as the Janus problem"
- Neural Radiance Field (NeRF): A neural representation that models radiance and density fields to render novel views. "distilling the denoising gradients of a large text-to-image diffusion model into a Neural Radiance Field (NeRF)"
- Particle‑based variational inference: A VI method that represents distributions with particle sets to capture uncertainty and diversity. "ProlificDreamer frames the optimization as a particle‑based variational inference problem"
- Qwen2.5‑VL 7B: A large open-source vision–LLM used as the reward backbone. "We instantiate our approach using Qwen2.5-VL 7B as the reward backbone"
- Reinforcement learning from human feedback (RLHF): Training that uses human preference signals to shape model behavior via reward learning. "through reinforcement learning from human feedback"
- Score Distillation Sampling (SDS): A technique that transfers knowledge from a diffusion model’s score network to optimize 3D parameters. "Score Distillation Sampling (SDS) repurposes a pretrained score network s_\phi to optimize 3D scene parameters θ"
- Spatial grounding: The ability to understand and localize objects and relations in space from language and vision. "have demonstrated advanced spatial grounding capabilities—localizing objects, understanding complex relations, and reasoning over multi-object scenes"
- Spatiotemporal understanding: Joint reasoning over space and time in visual inputs. "further enhancing their spatiotemporal understanding"
- Stochastic Differential Equation (SDE): A continuous-time stochastic process used to model forward and reverse diffusion dynamics. "Diffusion models define a forward–time SDE that gradually injects noise into a data sample and a corresponding reverse–time SDE that removes noise"
- Vision–LLMs (VLMs): Models trained on image–text data to align visual and linguistic representations for multimodal tasks. "Vision–LLMs (VLMs) jointly learn from large-scale image–text corpora to produce unified embeddings"
- Wiener process: A continuous-time stochastic process (Brownian motion) used in defining SDEs. "forward and reverse Wiener processes"
- Zero‑shot classification: Recognizing unseen classes without task-specific training by leveraging aligned embeddings. "achieves strong zero-shot classification and retrieval performance across diverse vision benchmarks"
Collections
Sign up for free to add this paper to one or more collections.