- The paper demonstrates that decoupling core attention with CAD significantly reduces compute and memory imbalances in long-context LLM training.
- CAD leverages the statelessness and composability of core attention, using token-level sharding to achieve up to 1.35x throughput improvement.
- Through ping-pong execution and optimized communication, DistCA attains near-linear scaling and cuts memory requirements by 20-25%.
Core Attention Disaggregation for Efficient Long-context LLM Training
Motivation and Problem Analysis
The paper introduces Core Attention Disaggregation (CAD), a system-level technique for mitigating compute and memory load imbalance in long-context LLM training. The imbalance arises from the quadratic scaling of core attention (CA) computation with sequence length, contrasted with the near-linear scaling of other transformer components. Document packing, a standard throughput optimization, exacerbates this issue by creating microbatches with highly variable attention FLOPs, resulting in stragglers in both data parallel (DP) and pipeline parallel (PP) regimes.
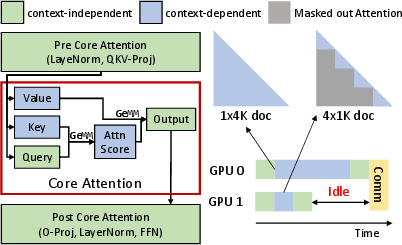
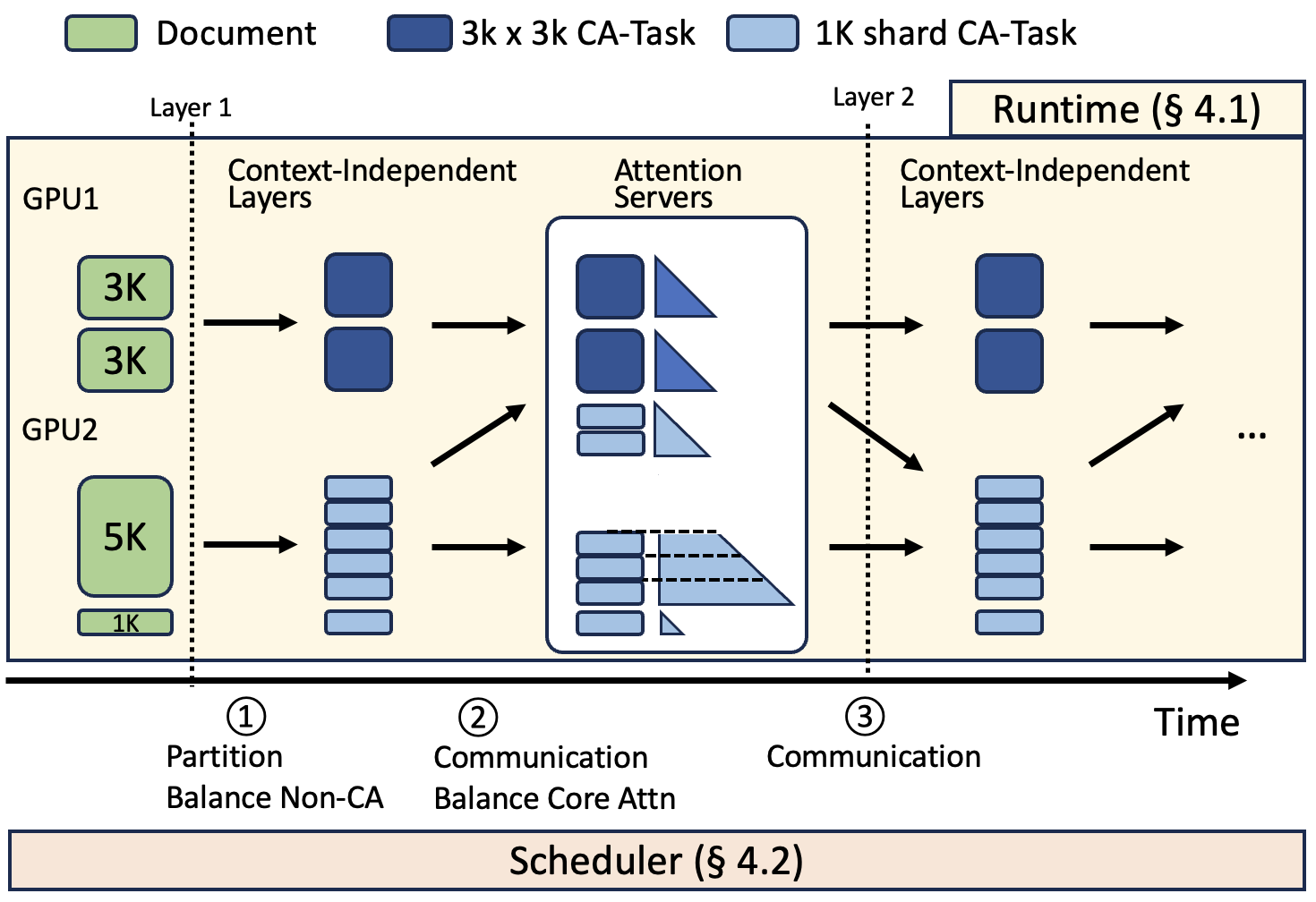
Figure 1: Transformer and its workload imbalance caused by core attention.
Existing remedies—variable-length data chunking and per-document context parallelism (CP)—address either compute or memory balance, but not both. Variable-length chunking equalizes attention FLOPs at the cost of memory divergence, while CP introduces significant all-gather communication and memory overhead, especially at scale.
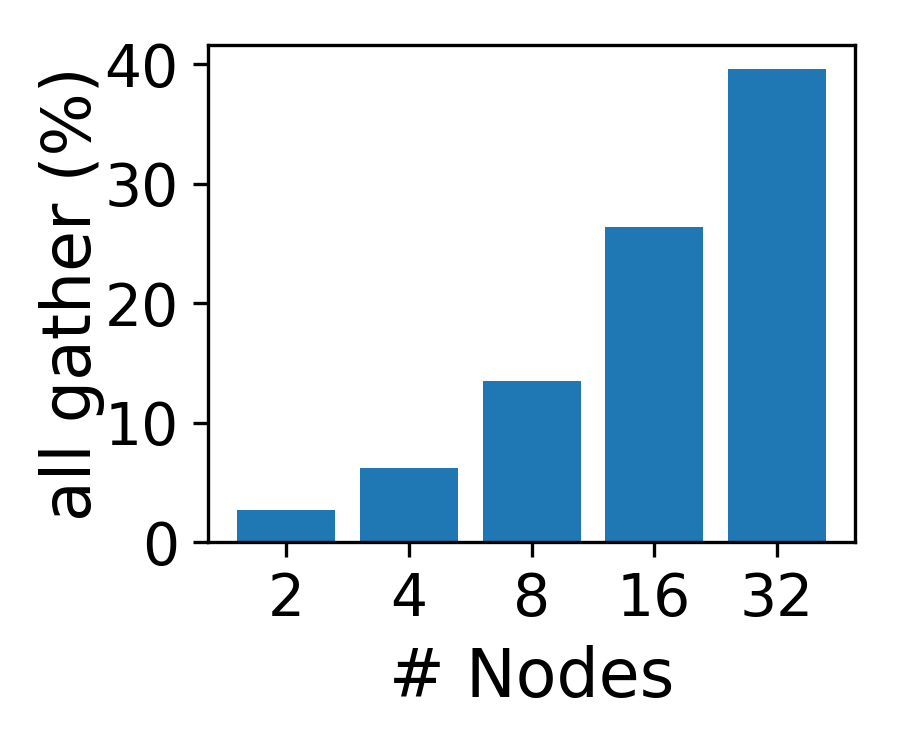
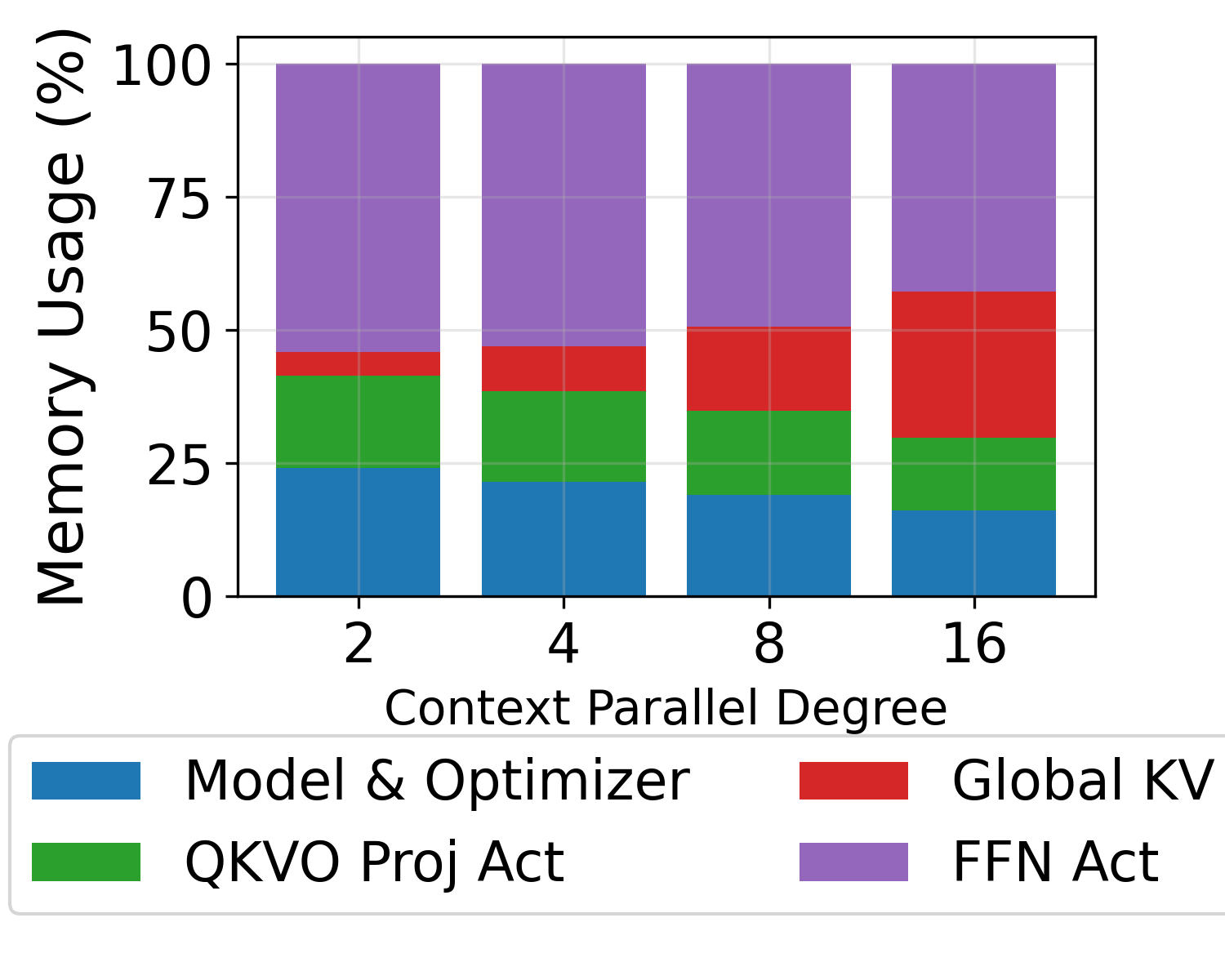
Figure 2: All-gather latency percentage increases with CP degree, limiting scalability.
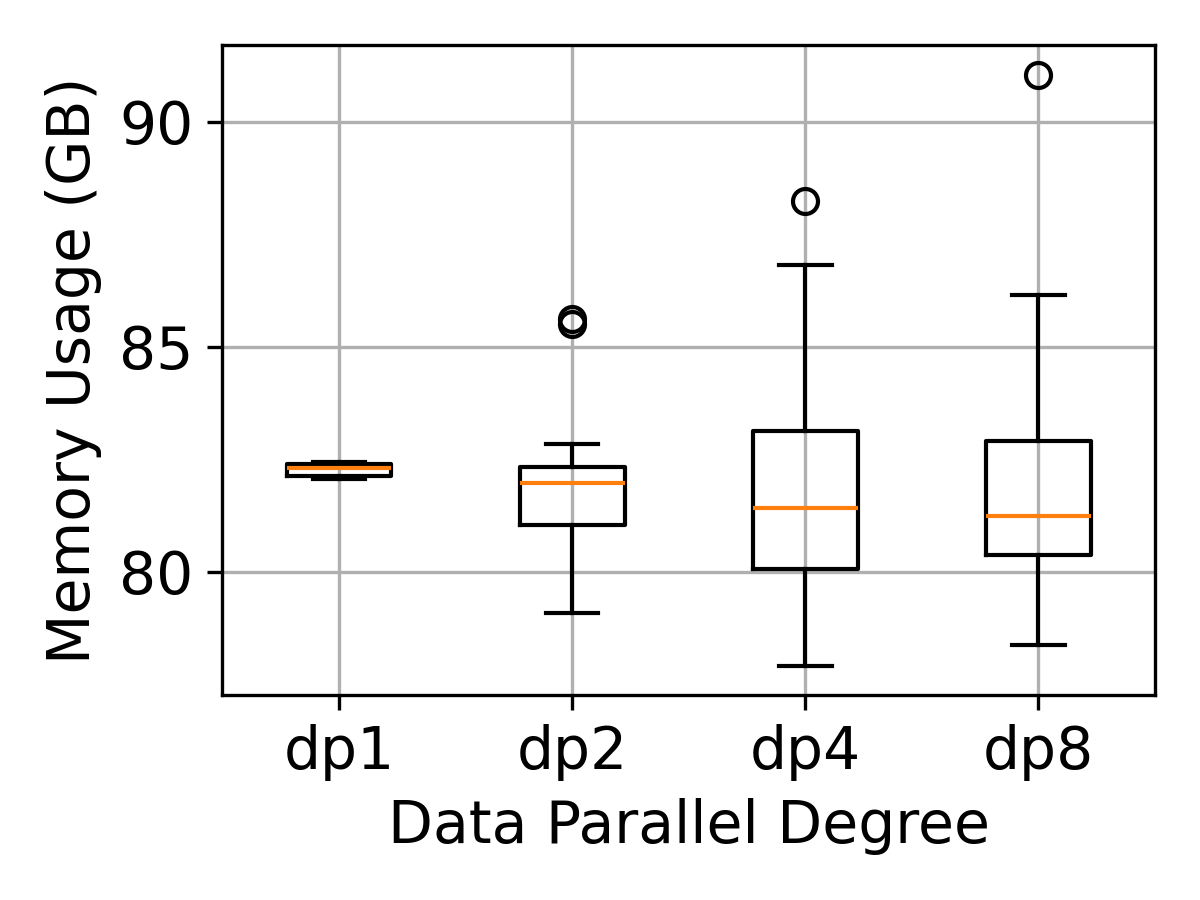
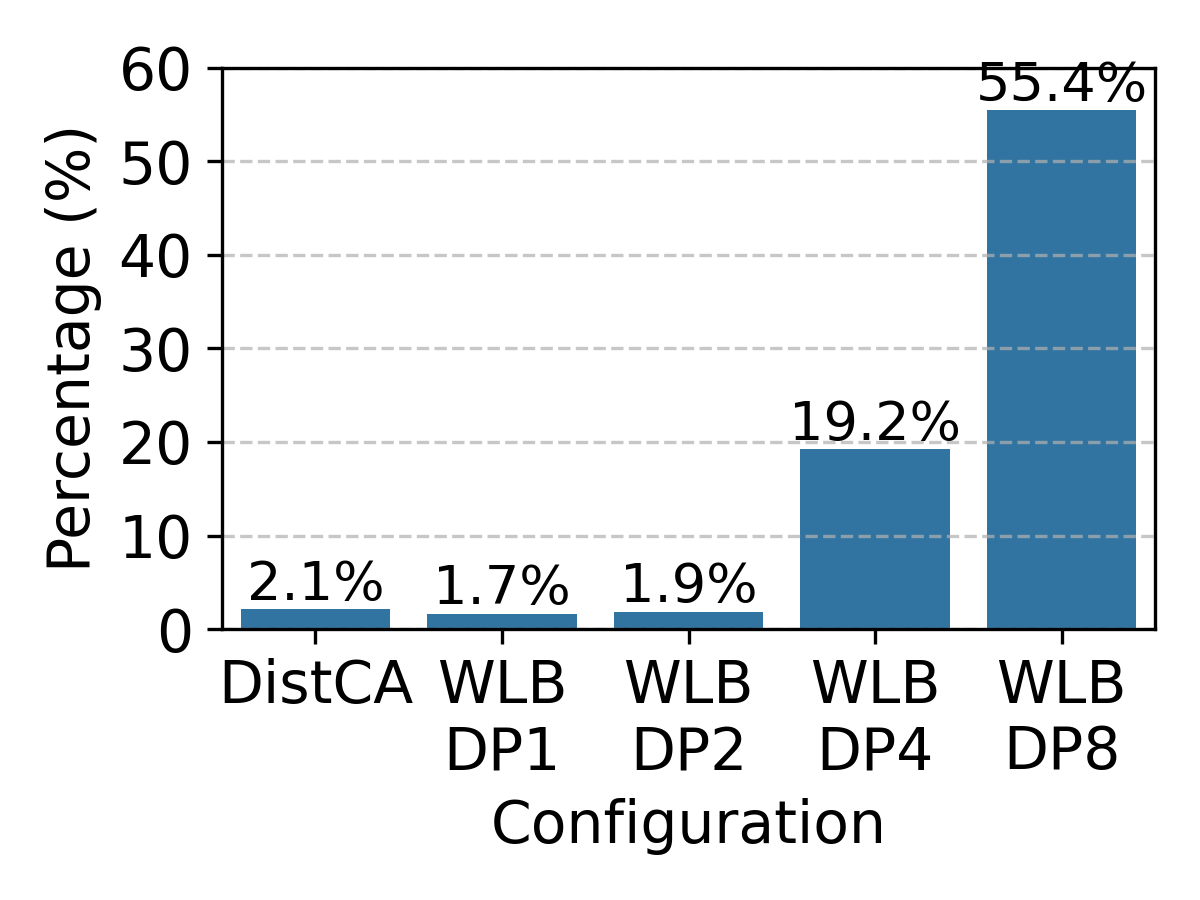
Figure 3: Memory divergence in variable-length chunking grows with DP size, leading to memory imbalance.
Core Attention Disaggregation: Design and Implementation
CAD exploits two properties of core attention: statelessness and composability. CA is parameter-free and generates negligible intermediate state, allowing its computation to be scheduled independently. Furthermore, CA can be partitioned at token granularity and recombined into high-occupancy kernels, leveraging modern attention implementations (e.g., FlashAttention) for efficient execution.
The CAD system, DistCA, disaggregates CA from the rest of the model and schedules CA tasks on a pool of attention servers. Each CA task corresponds to the computation for a shard of query tokens and its context's key-value states. The runtime alternates between context-independent layers and CA, inserting communication as needed. To maximize resource utilization, DistCA implements in-place attention servers, allowing GPUs to time-share between CA and other layers.
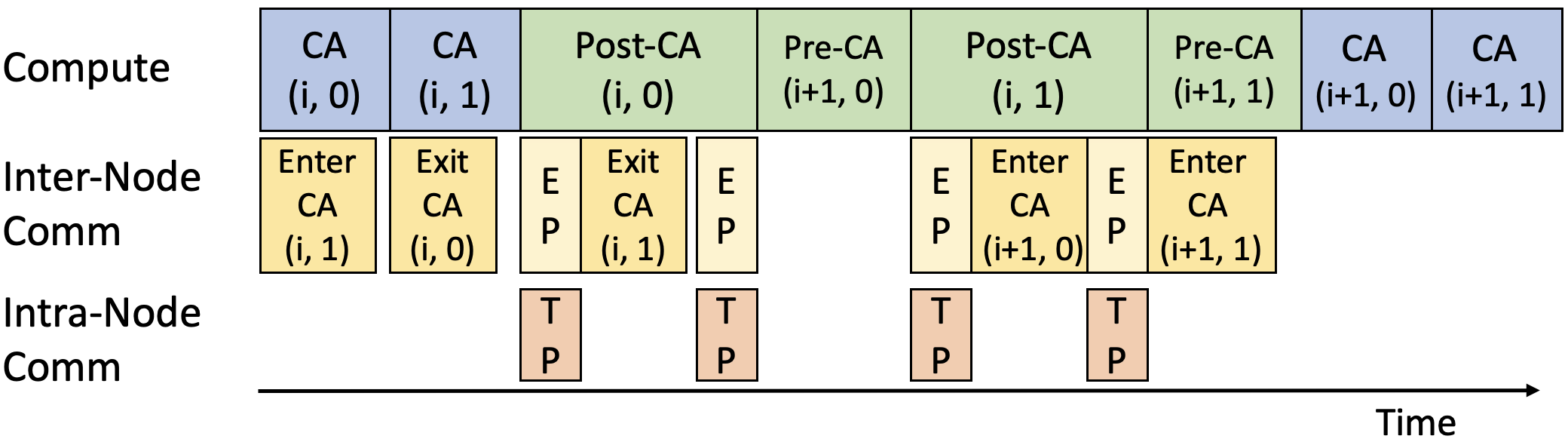
Figure 4: Ping-Pong computation and communication for inplace attention server, overlapping communication with compute.
DistCA employs a ping-pong execution scheme to overlap communication and computation, dividing each microbatch into two nano-batches and interleaving their execution. This design hides communication latency and maintains high throughput.
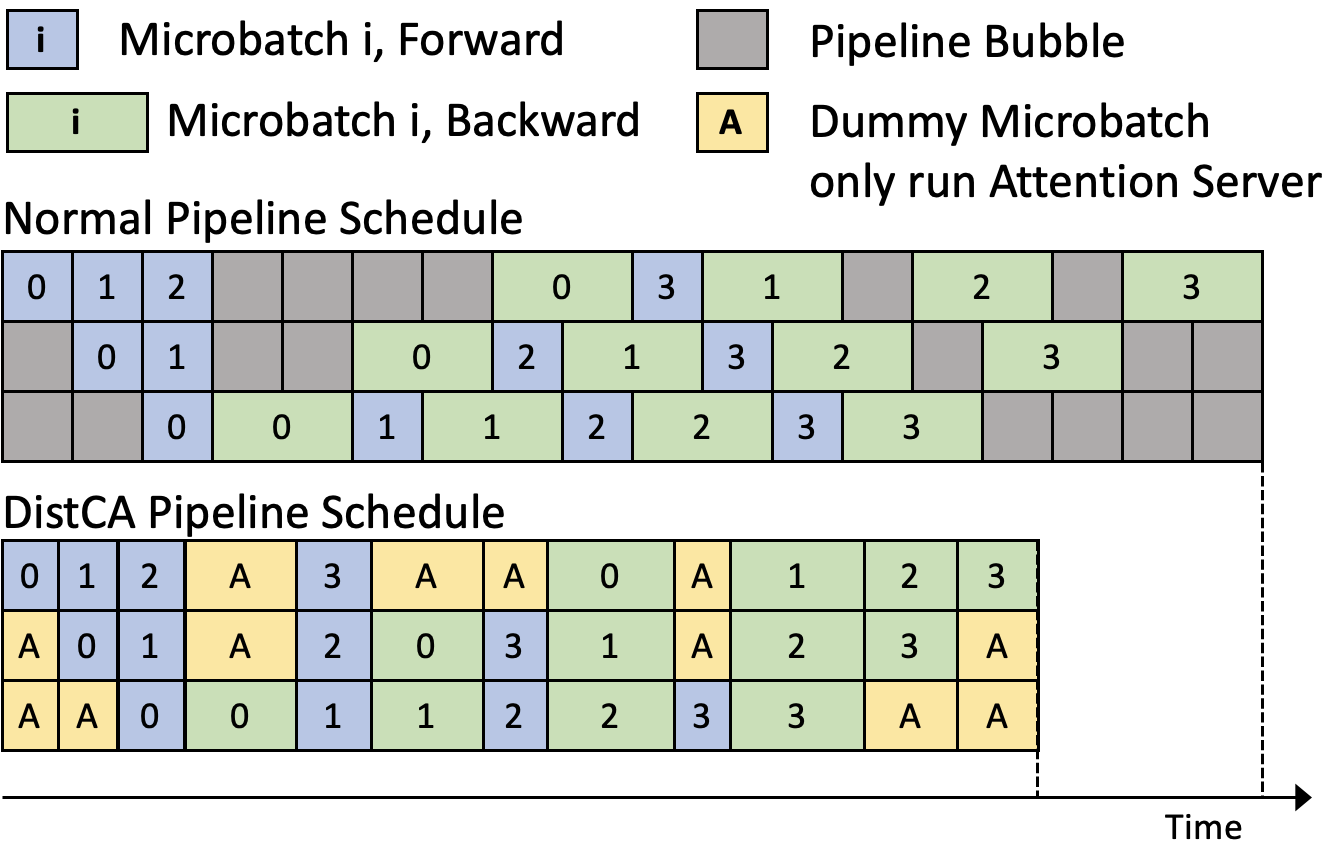
Figure 5: Pipeline Parallel Schedule for normal 1F1B and disaggregated attention, showing integration of CAD with PP.
A central scheduler partitions documents into shards and assigns CA tasks to attention servers, optimizing for both load balance (FLOPs) and communication volume (bytes). The scheduling algorithm uses a cost-benefit heuristic to migrate shards between servers, minimizing communication per unit of compute transferred.
Experimental Evaluation
DistCA is evaluated on LLaMA-8B and LLaMA-34B models with context lengths up to 512K tokens, using up to 512 H200 GPUs. The experiments compare DistCA against WLB-LLM, a state-of-the-art workload-balanced parallelism baseline.
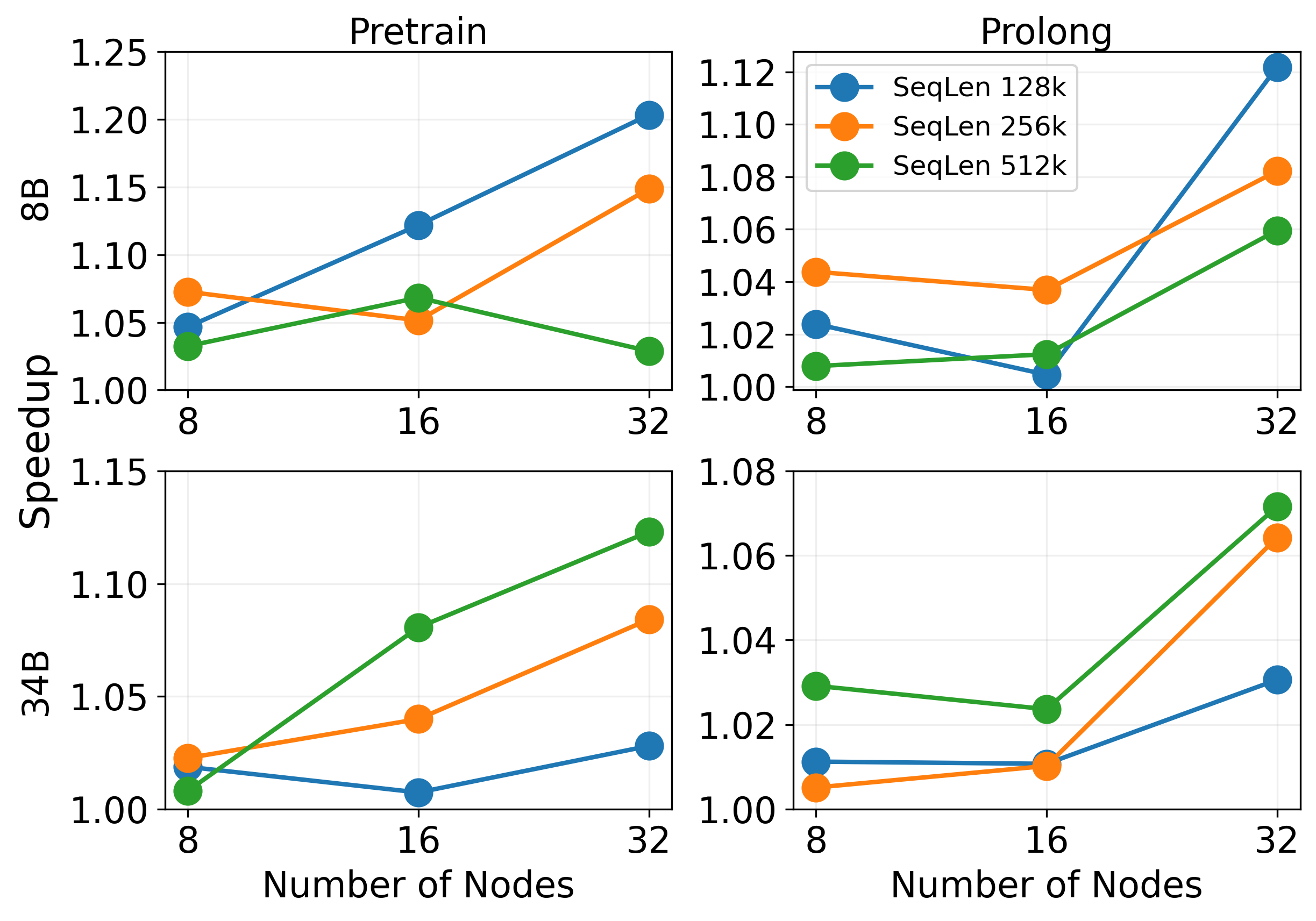
Figure 6: 3D Parallel (no PP) experiment. DistCA achieves 1.07–1.20x speedup over WLB-LLM in Pretrain and 1.05–1.12x in ProLong.
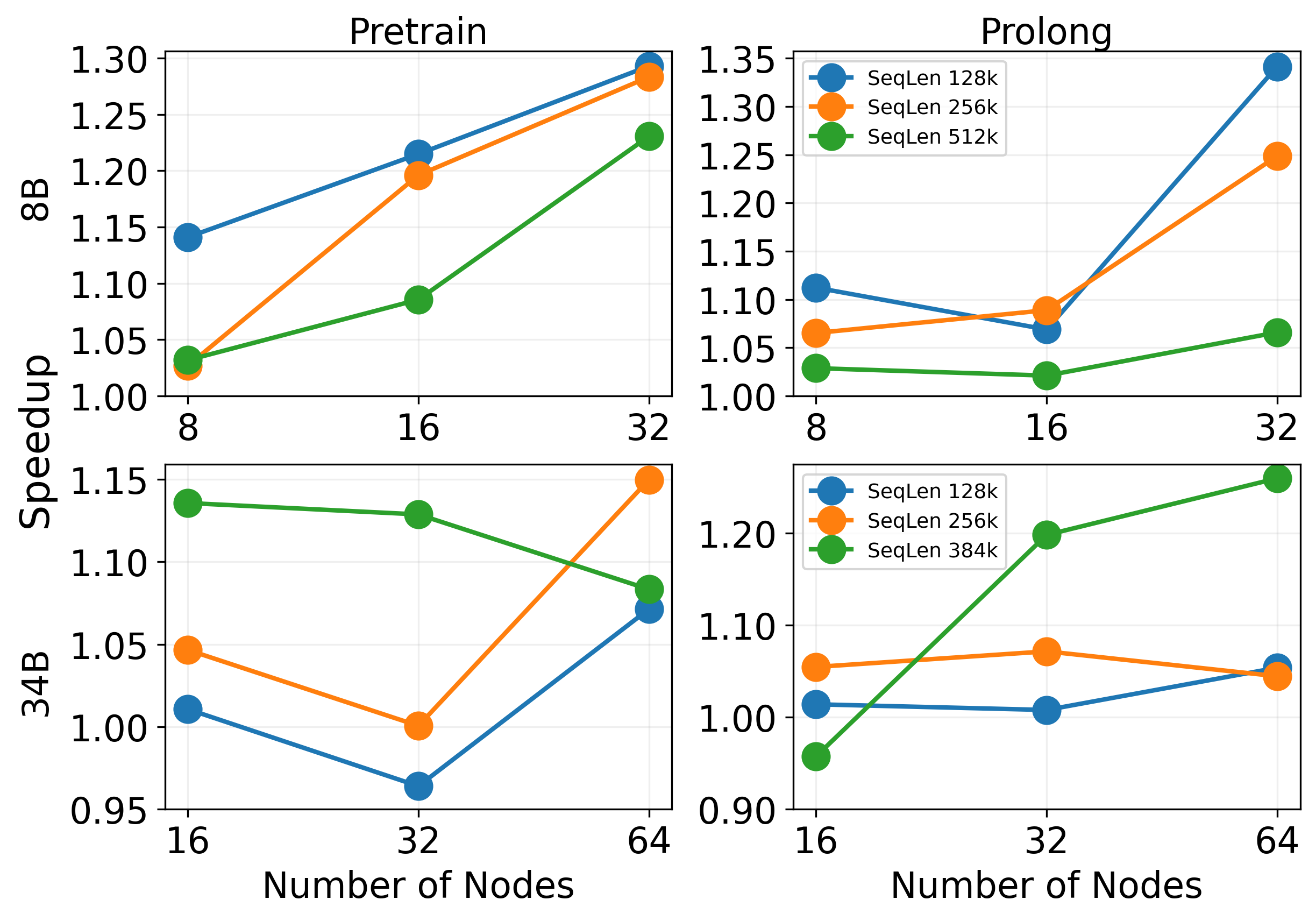
Figure 7: 4D Parallel (with PP) experiment. DistCA achieves up to 1.35x speedup over WLB-LLM, with increasing advantage at larger scale and longer context.
DistCA consistently outperforms WLB-LLM, with speedups up to 1.35x and near-linear weak scaling. The throughput advantage increases with context length and model size, as WLB-LLM suffers from compounded memory and communication bottlenecks. DistCA's flexible token-level scheduling and communication overlap enable near-perfect compute and memory balance.
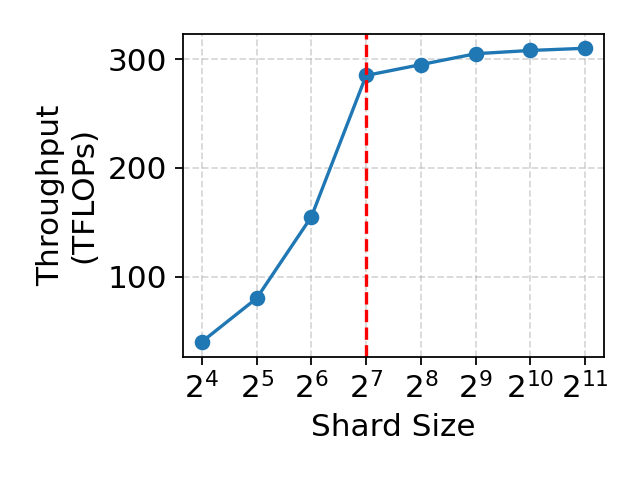
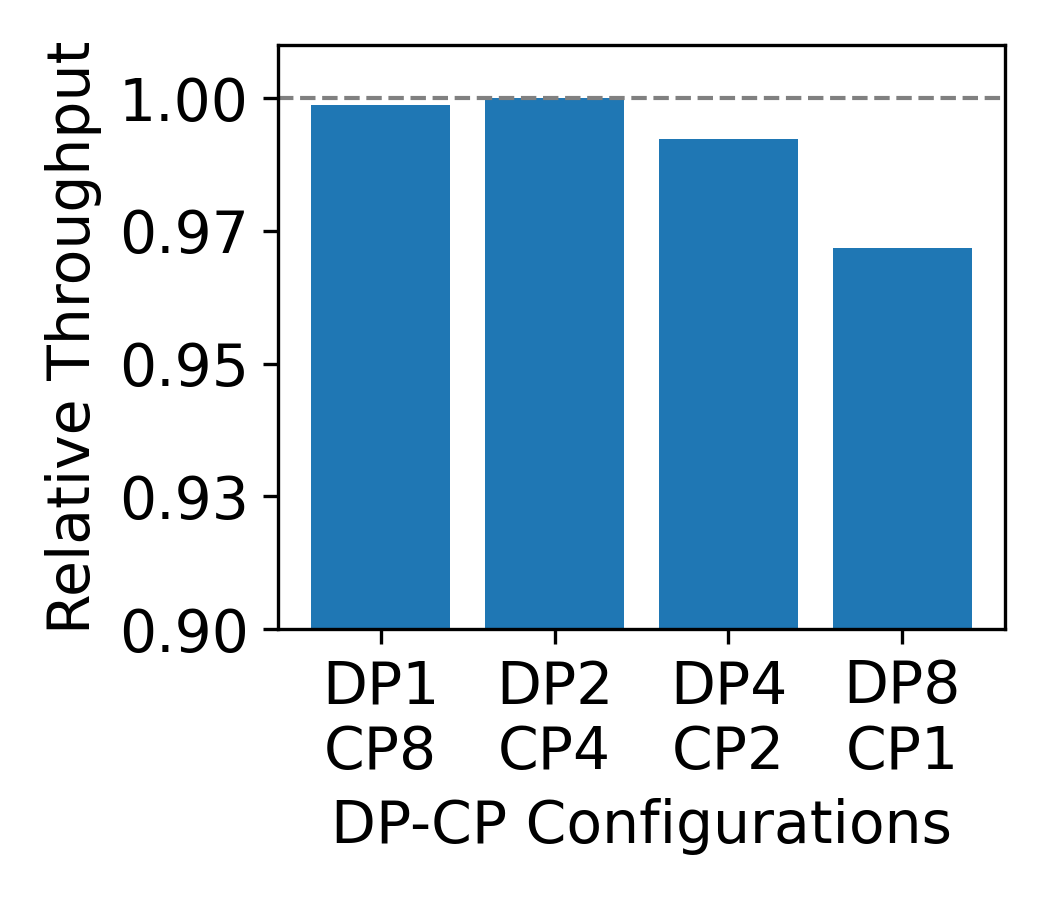
Figure 8: Throughput of core attention remains high for fused shards above kernel tile size, validating composability.
Ablation studies demonstrate that DistCA's ping-pong execution fully hides communication overhead, and that tuning the scheduler's imbalance tolerance factor can reduce memory requirements by 20–25% without impacting latency.
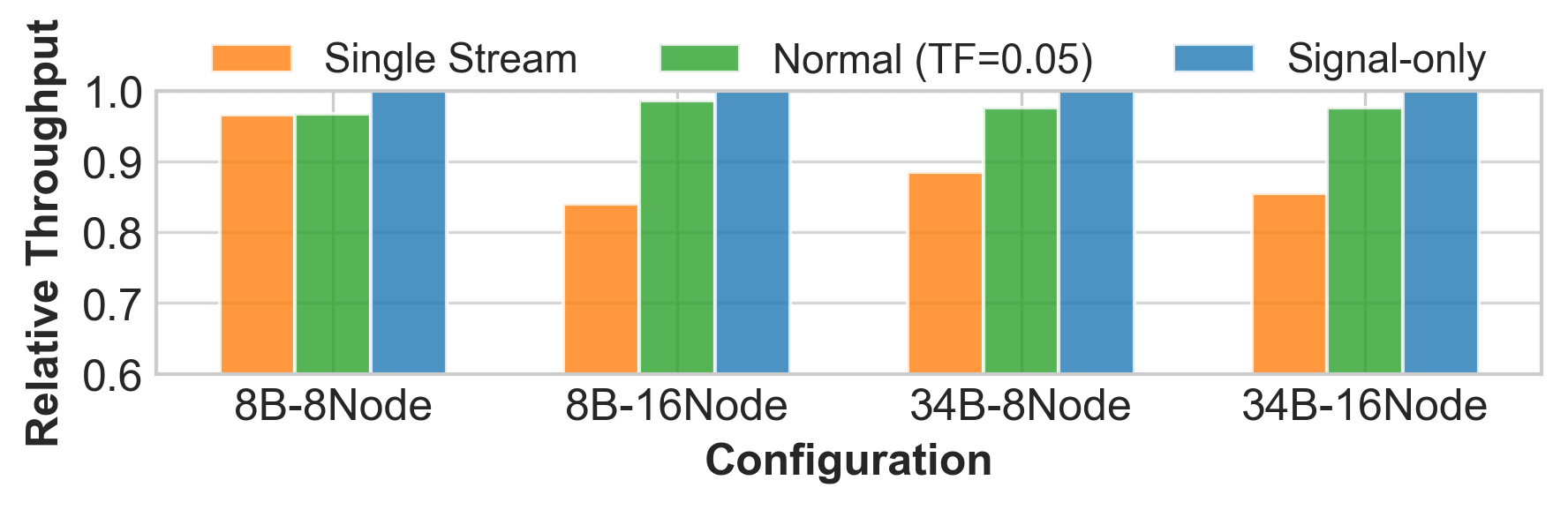
Figure 9: Throughput for different communication patterns, showing that ping-pong execution eliminates communication bottlenecks.
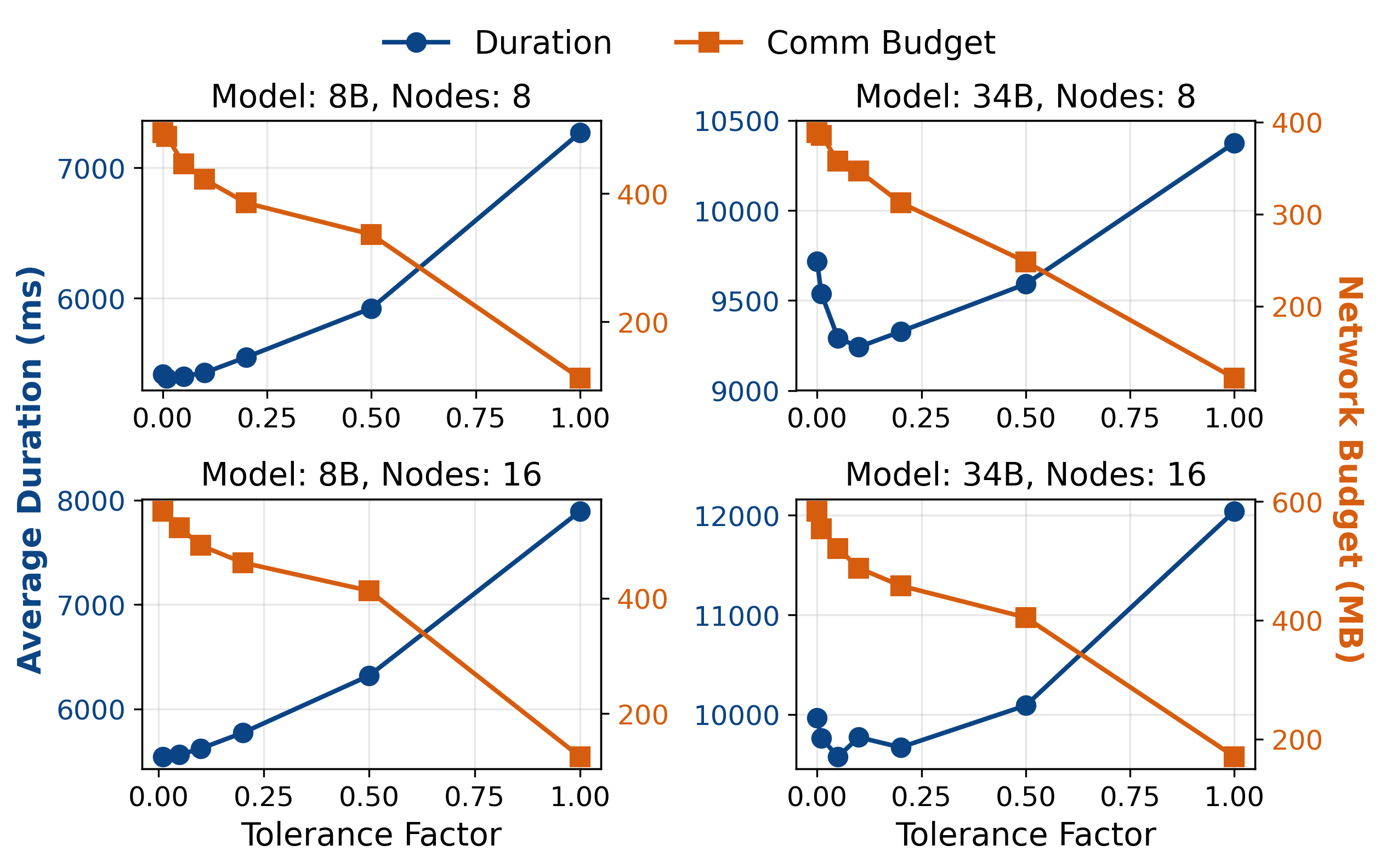
Figure 10: Impact of the compute imbalance tolerance factor; optimal range minimizes memory without increasing iteration latency.
System and Algorithmic Trade-offs
DistCA's design choices—token-level sharding, in-place attention servers, and ping-pong scheduling—address the fundamental mismatch between CA and other transformer components. The system achieves high memory utilization and compute balance without the scalability limitations of CP or the memory divergence of variable-length chunking. The scheduler's cost-benefit heuristic enables fine-grained control over the trade-off between load balance and communication volume.
The main limitation is memory fragmentation due to variable tensor shapes in CA requests, which introduces CPU overhead and degrades performance in large-scale experiments. Static memory allocation and CUDA Graphs are proposed as future optimizations.
Implications and Future Directions
CAD provides a principled approach to decoupling compute and memory scaling in LLM training, enabling efficient utilization of heterogeneous resources. The stateless and composable nature of CA suggests further opportunities for hardware specialization and dynamic resource allocation. Dedicated attention server pools could enhance fault tolerance and performance isolation. Extending the scheduler to support partial context sharding and more precise communication modeling could further improve efficiency.
The separation of CA from context-independent layers may also inform future model architectures and training paradigms, particularly for ultra-long-context or multi-modal models where attention bottlenecks dominate. The demonstrated throughput improvements and scalability suggest that CAD can be foundational for next-generation LLM training systems.
Conclusion
Core Attention Disaggregation, as implemented in DistCA, addresses the critical challenge of load imbalance in long-context LLM training by decoupling and independently scheduling core attention computation. The system leverages the statelessness and composability of CA, achieving up to 1.35x throughput improvement and near-linear scaling on large GPU clusters. The approach eliminates DP/PP stragglers and maintains high resource utilization, with practical implications for scalable, efficient LLM training. Future work may extend CAD to dedicated hardware, more flexible scheduling, and broader model classes.