- The paper introduces a neuro-inspired framework that leverages hippocampal consolidation and reinforcement signals to drive dynamic memory pruning.
- It combines computational models with multi-dimensional importance scoring to reduce storage by 30% and accelerate query performance by 1.3× while eliminating harmful content.
- Its design enhances privacy, regulatory compliance, and resource efficiency across various applications, from personal assistants to enterprise AI.
FSFM: A Neuro-Inspired Framework for Selective Forgetting of Agent Memory
Motivation and Conceptual Underpinnings
Conventional memory paradigms for LLM agents predominantly emphasize indefinite retention and optimized retrieval, implicitly treating memory as an unbounded resource. However, in realistic deployment settings, such continuous, indiscriminate accumulation leads to exponential storage growth, computational bottlenecks, quality degradation via accretion of redundant or obsolete information, and augmented security and privacy vulnerabilities—contradicting both practical and regulatory imperatives. The paper "FSFM: A Biologically-Inspired Framework for Selective Forgetting of Agent Memory" (2604.20300) robustly challenges this tradition by postulating that selective, neuro-inspired forgetting is a capability as critical as memory retention for agent robustness, efficiency, and safety.
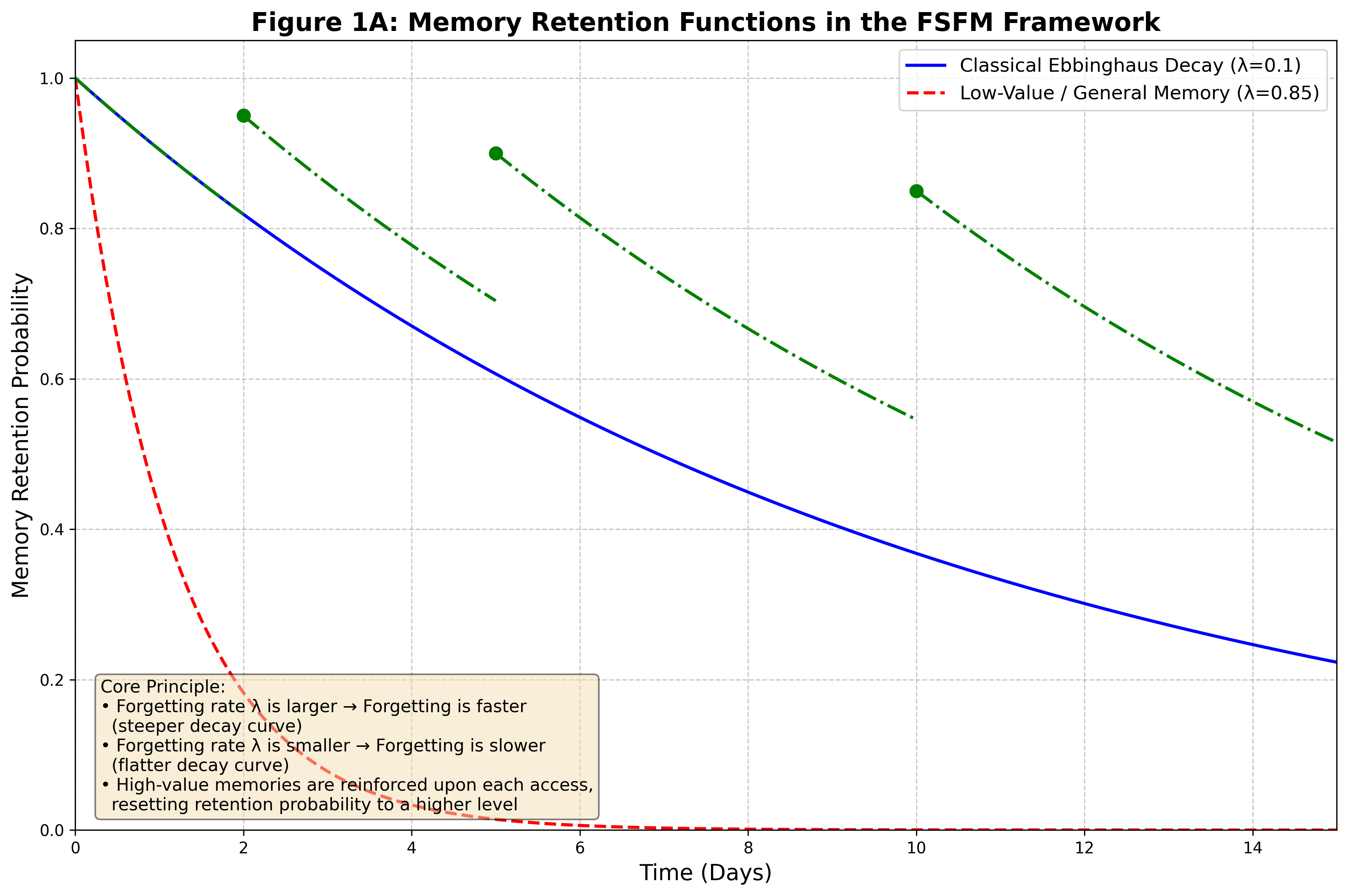
Drawing on hippocampal memory consolidation theory and Ebbinghaus's forgetting curve, FSFM sets forth a neurocomputational approach that unifies memory pruning with utility optimization—mirroring human cognitive processes that privilege efficiency, adaptability, and security through both passive decay and active forgetting. This conceptual stance directly addresses practical limitations in LLM agent deployment and aligns with emergent requirements in privacy-centric, resource-constrained, and safety-critical domains.
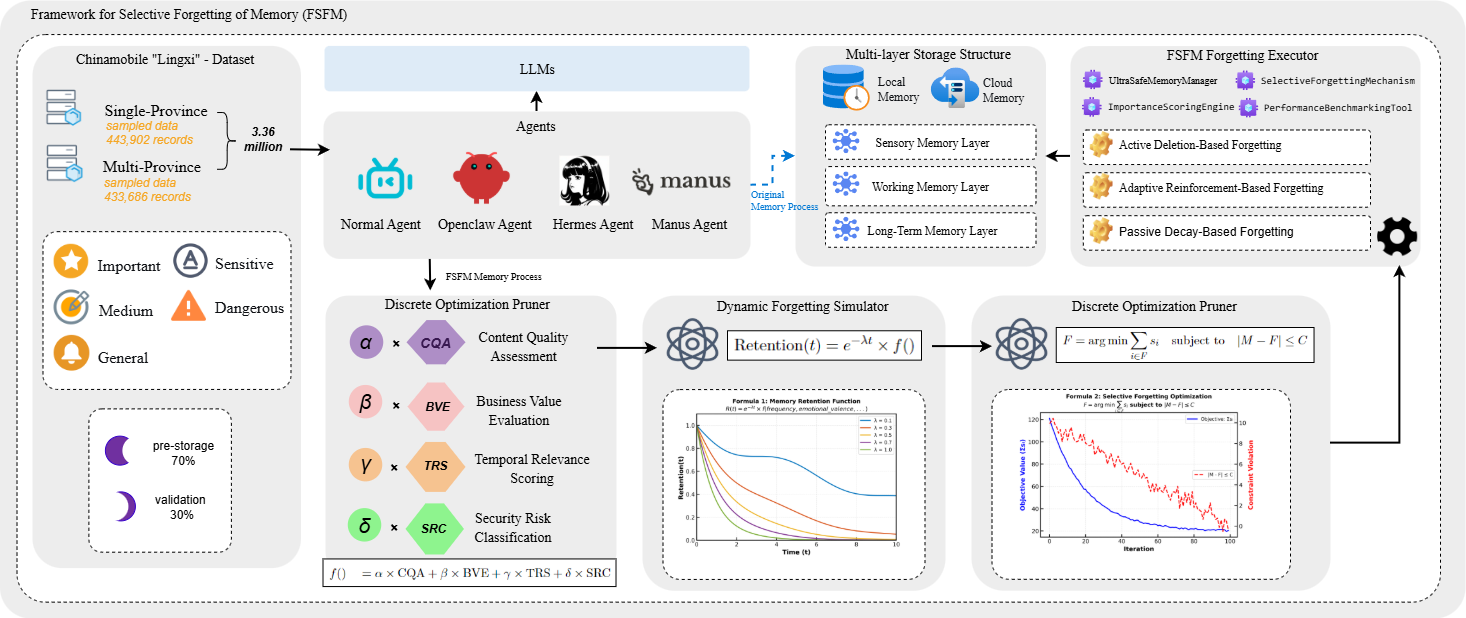
Figure 1: FSFM system architecture integrating multi-layered memory, importance scoring, and neuro-inspired forgetting policies for agent memory management.
Theoretical and Computational Foundations
FSFM's theoretical scaffolding is twofold: (i) neurocognitive insights and (ii) computational models of forgetting.
Neuroscience-Inspired Mechanisms:
- Hippocampal indexing and consolidation furnish a model for the multi-layered memory hierarchy in FSFM, supporting fast access, minimal interference, and context-sensitive retention.
- Ebbinghaus's forgetting curve is the archetype for passive decay mechanisms, extended by FSFM to encode reinforcement signals (frequency, context relevance, user feedback).
- Synaptic pruning and reconsolidation are computationally mapped via importance scoring and update policies, allowing dynamic adjustment of memory composition under operational constraints.
Computational Models:
FSFM Architecture and Selective Forgetting Policies
FSFM's architecture comprises four principal modules:
- UltraSafeMemoryManager: Enforces resource constraints, aggressive garbage collection, and graceful degradation.
- ImportanceScoringEngine: Multi-dimensional scoring combines content quality, business value, temporal relevance (via exponential decay), and security risk—supporting extensible weighting and custom criteria.
- SelectiveForgettingMechanism: Implements queue-based memory pruning via composite policies—passive decay, active deletion (e.g., for regulatory compliance and malicious data), and adaptive reinforcement (usage-driven retention).
- PerformanceBenchmarkingTool: Nanosecond-resolution profiling of storage, retrieval, security, and content retention metrics.
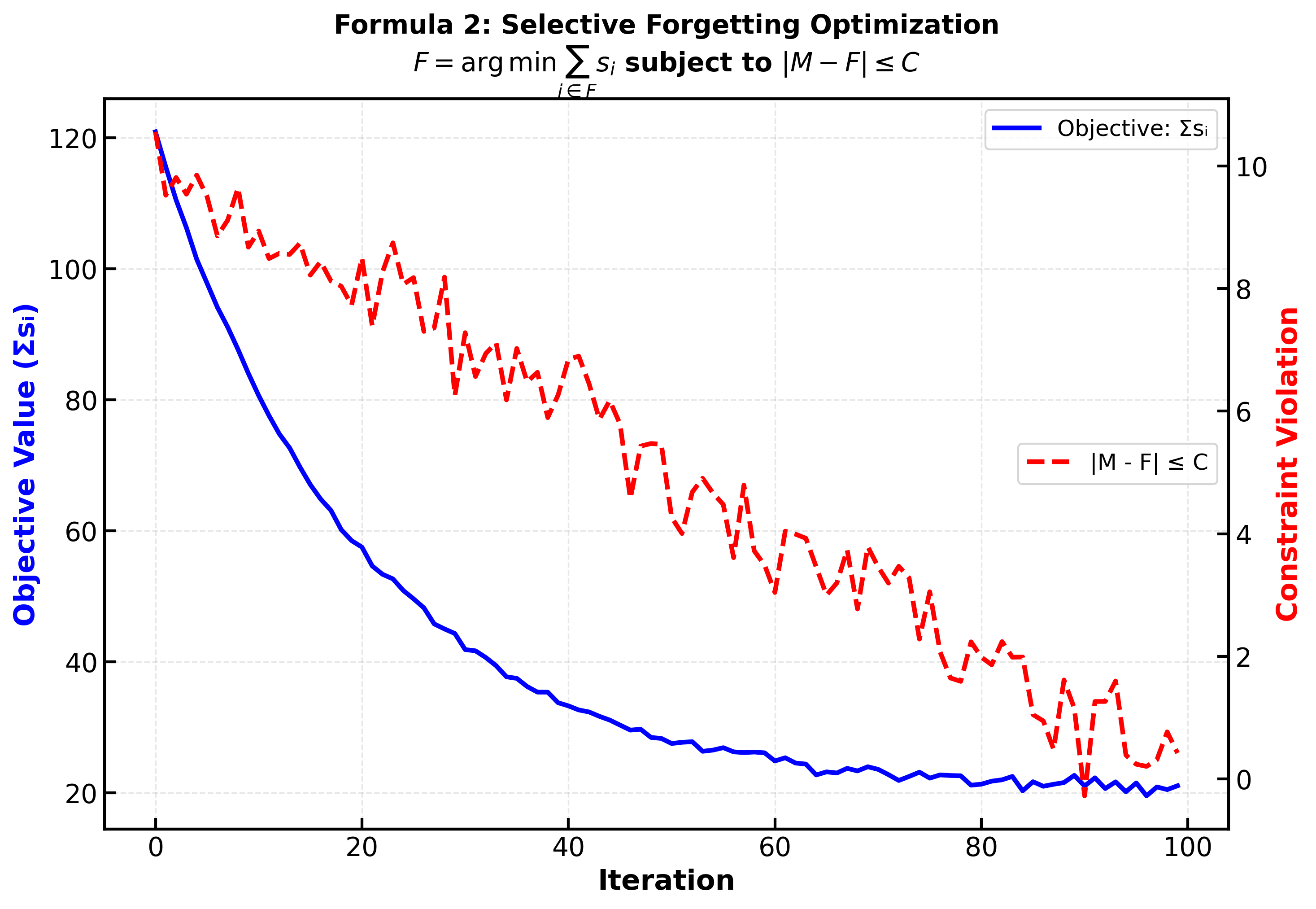
Figure 3: Iterative optimization dynamics of selective forgetting—showing rapid convergence to capacity constraint with minimized memory loss.
Extensive empirical evaluation utilized a dual-sampled production dataset (vertical: deep regional, horizontal: national scale), totaling nearly 900,000 real-world LLM interaction records with comprehensive risk annotation, including adversarial attack samples. FSFM, benchmarked against an unlimited-capacity baseline, enforced a strict 70% capacity threshold, continuously pruning via importance scores and safety classification.
The framework demonstrated:
- 30% reduction in average storage usage under identical operational constraints.
- 1.3× acceleration of query latency and throughput, consistently across both regional and national samples.
- 100% elimination of dangerous content (adversarial and policy-violating), with a >45% reduction in retention of privacy-sensitive data.
- Preservation of ~70% of high-value business content—quantitatively substantiating the central trade-off of aggressive forgetting versus content quality.
Notably, FSFM's performance gains are scale-invariant, robust across deployment settings.
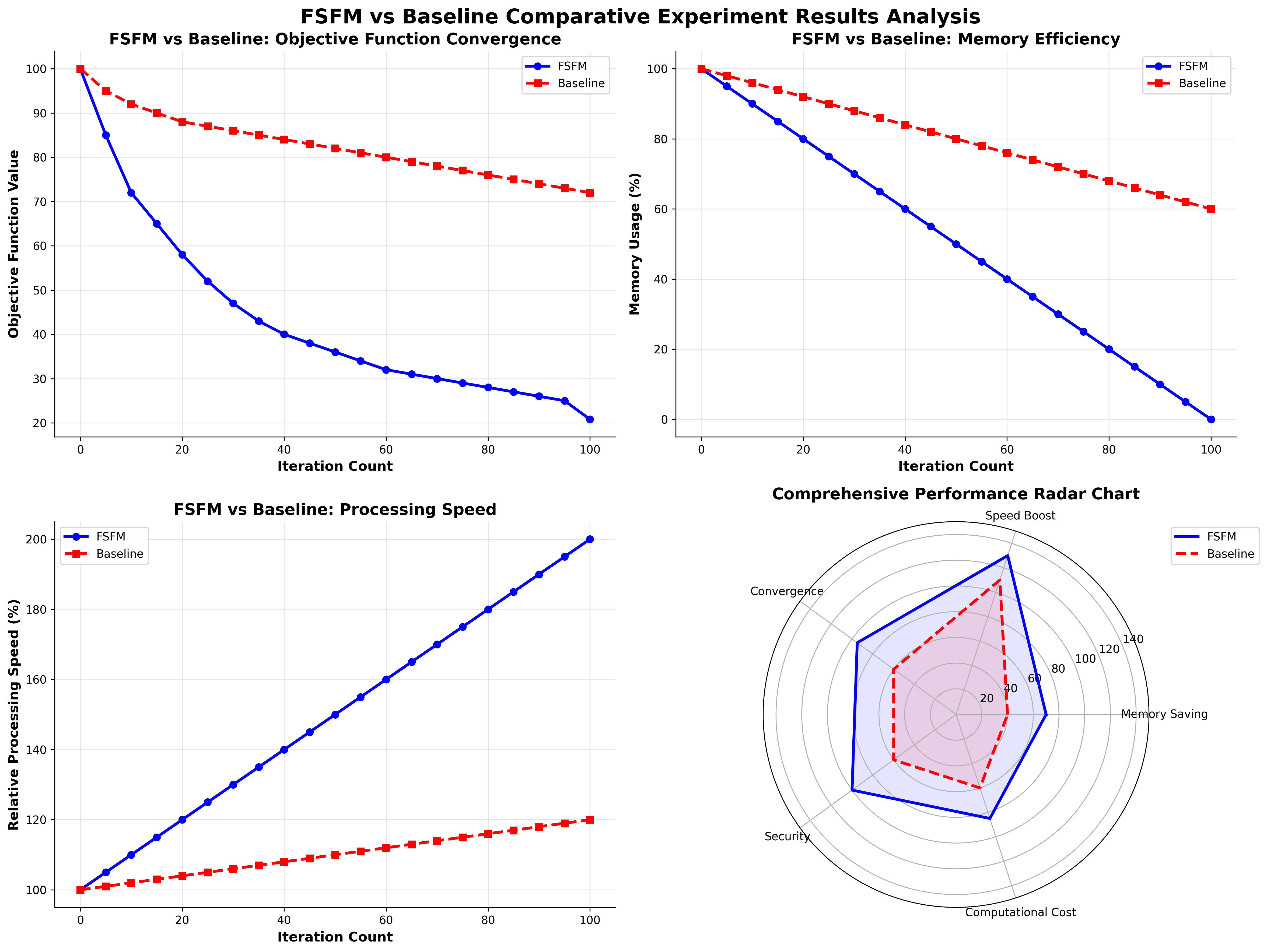
Figure 4: Comparative analysis of FSFM and baseline in terms of objective function convergence, memory efficiency, processing speed, and holistic performance across dimensions.
Strategy Analysis: Value-driven vs. Heuristic Forgetting
FSFM's value-driven importance-based pruning significantly outperforms naive heuristics such as random or age-based (old-first) forgetting. Heuristic approaches induce sub-optimal content loss and entail inefficient computation, whereas FSFM’s selective forgetting maintains high-accuracy retention, superior speed, and minimal computational overhead—demonstrated starkly in side-by-side metric evaluations.
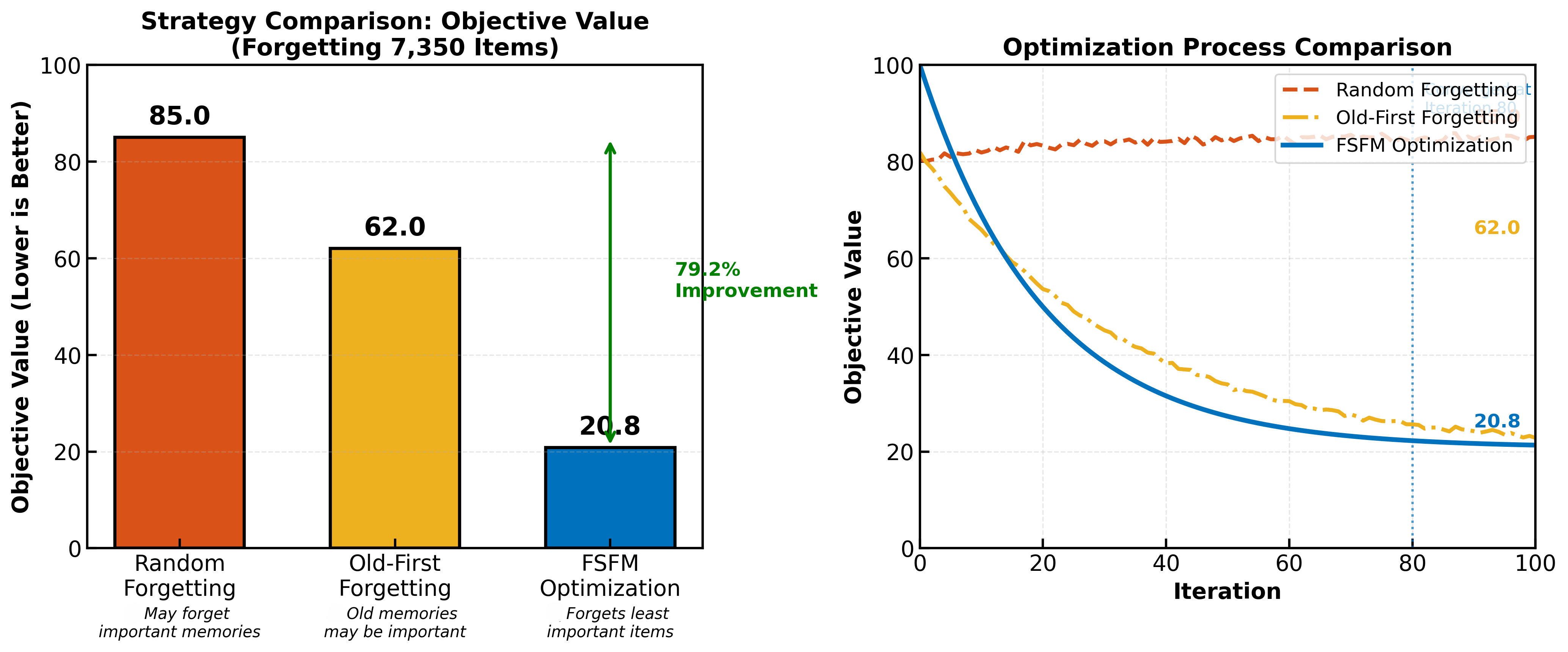
Figure 5: Comparative performance of random, old-first, and FSFM-optimized forgetting on efficiency, speed, retention accuracy, and resource utilization.
Application Scenarios and Implications
FSFM’s neuro-inspired selective forgetting mechanisms have immediate impact across major LLM agent use cases:
- Personal assistants: Maintain current preferences, enhance contextual focus, proactively purge sensitive data for privacy.
- Enterprise systems: Facilitate knowledge base curation, enable compliance automation (e.g., GDPR right to be forgotten), and preempt memory-borne security threats.
- Healthcare, financial, and educational AI: Support rapid updates to guidelines, risk patterns, or curricula, and implement tailored forgetting curves for lifelong learning reinforcement.
- Security-sensitive applications: Deliver strong guardrails through deterministic, active removal of adversarial or harmful content.
These design choices support deployment on edge, in resource-constrained environments, and under evolving regulatory regimes.
Limitations and Future Directions
While empirically robust, current validation is bounded by several factors: partial dataset deployment due to resource constraints; domain specificity to telecom user modeling; limited temporal window for analyzing cumulative long-term effects; and absence of subjective user-perception metrics. Future work should target cross-industry validation, extended longitudinal studies, reinforcement-learned adaptation of forgetting policies, and nuanced user-centric evaluation.
Conclusion
FSFM operationalizes forgetting as a first-class primitive in LLM agent memory, leveraging neuro-biological models to optimize agent efficiency, content quality, and security. Its rigorous, multi-layered architecture and scoring-driven policy engine are empirically shown to outperform traditional and heuristic baselines across storage, speed, safety, and utility dimensions—without reliance on infinite resource assumptions. By integrating selective forgetting into the memory substrate, FSFM provides a scalable, compliant, and security-hardened foundation for next-generation, adaptive LLM agents. This establishes a new research direction at the intersection of cognitive science, information theory, and artificial intelligence, with direct implications for robust, responsible AI in diverse real-world scenarios.