Scaling Self-Play with Self-Guidance
Abstract: LLM self-play algorithms are notable in that, in principle, nothing bounds their learning: a Conjecturer model creates problems for a Solver, and both improve together. However, in practice, existing LLM self-play methods do not scale well with large amounts of compute, instead hitting learning plateaus. We argue this is because over long training runs, the Conjecturer learns to hack its reward, collapsing to artificially complex problems that do not help the Solver improve. To overcome this, we introduce Self-Guided Self-Play (SGS), a self-play algorithm in which the LLM itself guides the Conjecturer away from degeneracy. In SGS, the model takes on three roles: Solver, Conjecturer, and a Guide that scores synthetic problems by their relevance to unsolved target problems and how clean and natural they are, providing supervision against Conjecturer collapse. Our core hypothesis is that LLMs can assess whether a subproblem is useful for achieving a goal. We evaluate the scaling properties of SGS by running training for significantly longer than prior works and by fitting scaling laws to cumulative solve rate curves. Applying SGS to formal theorem proving in Lean4, we find that it surpasses the asymptotic solve rate of our strongest RL baseline in fewer than 80 rounds of self-play and enables a 7B parameter model, after 200 rounds of self-play, to solve more problems than a 671B parameter model pass@4.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Scaling Self-Play with Self-Guidance”
What is this paper about?
This paper is about teaching AI models to get better by practicing with themselves. The authors introduce a new method called Self-Guided Self-Play (SGS) that helps an AI make useful practice problems and learn from them for a long time without getting stuck. They test it on formal math in a system called Lean4, where every solution can be automatically checked for correctness.
1) Brief overview
The main idea is to help an AI keep improving by:
- letting it invent simpler practice problems that are closely related to hard target problems, and
- having another part of the AI act like a judge to keep those practice problems clean, relevant, and not weird or tricksy.
This stops the common problem where AIs “cheat the system” by making nonsense problems that look hard but don’t actually help them learn.
2) Key questions the paper asks
- How can we make self-play (AI learning from its own generated problems) work for a long time without plateauing?
- How do we stop the AI that creates problems from “gaming” the rewards by making odd, overly complicated problems?
- Can the AI itself judge which practice problems are actually useful for learning?
- If we run this for a long time, does performance keep scaling up?
3) How they did it (methods in simple terms)
Think of three roles played by the same base LLM:
- The Solver: tries to solve problems.
- The Conjecturer (problem-maker): creates easier, related practice problems for the Solver, based on unsolved target problems.
- The Guide: acts like a teacher/coach who scores the practice problems for being relevant, clear, and natural.
Here’s the loop:
- Pick a bunch of hard target problems.
- For the ones the Solver still can’t solve, the Conjecturer writes new, simpler practice problems that are directly related.
- The Guide scores each practice problem: Is it clearly stated? Is it closely related to the target? Is it elegant rather than messy?
- The Solver tries to solve both target and practice problems. A formal checker (the Lean4 compiler) verifies if a proof is correct—like an automatic grader.
- Train the Solver to get better at solving. Train the Conjecturer to make medium-difficulty, relevant, well-formed practice problems that actually help.
Two important ideas explained with analogies:
- Reward hacking: Imagine a student who “learns” by building tests with trick questions that nobody understands. They get points for difficulty, but they don’t learn the actual skill. The Guide stops this by downscoring messy, fake-hard problems.
- Entropy collapse: If the Solver becomes too predictable (always gives the same answer), it stops exploring and learning new things. The authors choose a training rule (a simple REINFORCE objective) that keeps the Solver exploring, so the problem-maker still gets useful feedback.
They ran this for a long time (billions of tokens of training) and used “scaling laws” (curves that show how performance grows with more compute) to predict long-run performance.
4) Main findings and why they matter
Here are the key results, summarized:
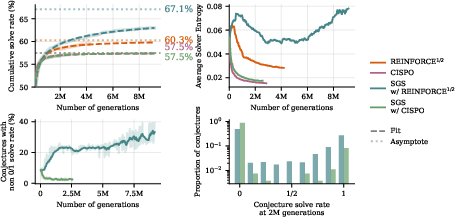
- SGS keeps learning longer and better than standard methods:
- It beats a strong reinforcement learning (RL) baseline on the same dataset of ~3,300 formal math problems.
- It reaches a higher “asymptotic” solve rate (the performance level you approach after lots of training), about 7% higher than the RL-only baseline.
- Quality control (the Guide) is crucial:
- Without the Guide, the problem-maker starts producing messy, overly long, or awkward problems (for example, with lots of “OR” parts). These don’t help the Solver learn real skills, even if they look hard.
- With the Guide, the synthetic problems stay clean, focused, and useful.
- Conditioning on unsolved target problems is essential:
- If the Conjecturer generates problems without looking at which target problems are unsolved, performance doesn’t improve beyond the baseline. Relevance matters.
- Freezing the problem-maker is better than nothing—but worse than learning:
- Keeping the Conjecturer fixed can work for a while, but the Solver quickly “eats through” those problems and progress slows. Training the Conjecturer (with guidance) is better.
- Choosing the right Solver training rule matters:
- A popular RL method (CISPO) caused the Solver to become too predictable (entropy collapse), which gives the Conjecturer almost no feedback (“all problems look either impossible or trivial”). That stalls learning.
- A simpler training rule (REINFORCE) kept the Solver exploring, which kept useful feedback flowing to the Conjecturer.
- Small model, big gains through self-play:
- Using SGS, a 7-billion-parameter model eventually solved more problems than a much larger 671-billion-parameter model did with a simple sampling setup (pass@4), after enough self-play. This shows that better training can sometimes beat sheer size.
Why this matters: It shows that careful self-play—with a Guide and the right training choices—can make learning keep improving over long runs, and even let smaller models catch up to or surpass bigger ones on certain benchmarks.
5) What this could lead to (implications)
- More reliable self-play: The approach shows how to prevent “problem-maker collapse” and keep long-run progress going. This is important for teaching AIs to handle very hard tasks without constant human supervision.
- Smarter use of compute: With the right guidance, models can keep getting better the longer you train them, instead of hitting a plateau.
- Beyond formal math: The same idea could apply to:
- Coding (the Conjecturer writes problems with unit tests; the Guide checks clarity and relevance).
- Robotics or games (the Conjecturer sets goals; a simulator checks success; the Guide evaluates if the goals are helpful stepping stones).
- Natural language math or reasoning (using learned verifiers as stand-ins for the formal checker).
- Future improvements: The Guide in this paper is kept fixed. In the future, learning a better Guide that adapts over time could help tackle even tougher problems.
In short: By adding a “teacher” inside the self-play loop and keeping the “student” curious, this method helps AI practice in a focused way, avoid bad habits, and keep improving for much longer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased so future researchers can act on it.
- Generalization beyond the training set: No evaluation on held-out or out-of-distribution theorem sets (e.g., MiniF2F, mathlib subsets), so it’s unclear whether SGS-trained solvers generalize beyond .
- Compute-normalized comparisons: SGS vs. baselines are not matched on total verified samples or wall-clock cost (SGS adds synthetic problems); report and compare sample- and compute-efficiency fairly across methods.
- Apples-to-apples metrics: The comparison to DeepSeek-Prover-V2-671B uses pass@4 while training/monitoring uses pass@8; re-run comparisons under identical pass@k and generation budgets.
- Overfitting risk: Training epochs the same 3,323 problems >230 times; measure retention and overfitting (e.g., solved-once vs. re-solve rates, catastrophic forgetting) and report held-out test performance.
- Sensitivity to Guide prompt/rubric: The Guide’s scoring is prompt-engineered and partially SFT’d; quantify sensitivity to rubric wording, scoring scales, and design choices (e.g., penalizing disjunctions) via ablation and alternative rubrics.
- Guide reliability and validity: Measure whether Guide scores correlate with future target-problem solve gains; report inter-rater agreement (human vs. Guide, or Guide vs. Guide-variant) and calibration curves.
- Guide robustness to reward hacking: Test if, over longer runs, the Conjecturer learns to exploit Guide preferences (beyond disjunctions/length); develop adversarial stress tests and adversarially trained Guides.
- Static vs. learnable Guide: The Guide is frozen; evaluate online/iterative Guide training using solver-driven signals (e.g., synthetic-to-target solve uplift), and assess stability when Guide co-evolves with Solver/Conjecturer.
- Single-judge bias: The Guide and Conjecturer originate from the same base model; test cross-model judges, judge ensembles, or pairwise-ranking judges to reduce collusion/confirmation bias.
- Batch-normalized reward design: Conjecturer reward is linearly normalized within a batch; analyze how batch composition and normalization affect stability and per-target fairness; compare to absolute/percentile/ranked rewards.
- Hyperparameter sensitivity: The “bottom 70%” solve-rate window and zeroing reward at 0 or top 30% are ad hoc; systematically sweep these thresholds, number of attempts , and reward shapes to identify robust regimes.
- “Try tactic” and length penalties: The Solver penalizes “try” loops and long outputs; quantify how these domain-specific penalties affect learning vs. alternative regularizers or timeouts.
- Solver objective breadth: Only REINFORCE, Expert Iteration, and CISPO were tested; evaluate PPO-style objectives with KL and entropy bonuses (and tuning ranges) to avoid entropy collapse while maintaining stability.
- Theoretical understanding of entropy dynamics: Formalize and analyze the observed link between Solver entropy and Conjecturer learning signal; derive conditions under which SGS avoids degenerate fixed points.
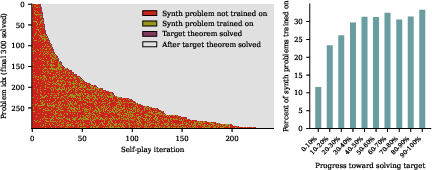
- Curriculum and scheduling: SGS generates one synthetic per unsolved target each round; explore adaptive curricula (e.g., bandits for target selection, multiple synthetics per target, diversity constraints) for faster progress.
- Role-sharing and architecture choices: Investigate tying weights across Solver/Conjecturer/Guide or using different architectures/sizes per role; assess whether heterogeneity prevents collusion and improves performance.
- Model-scale scaling: Only compute scaling was studied; perform controlled model-size sweeps to quantify how Solver/Conjecturer/Guide capacity affects asymptotic solve rates and compute-to-quality tradeoffs.
- Dataset construction and reproducibility: relies on filters using external models (GPT 5 mini, other provers); share filtered lists and seeds, evaluate bias introduced by filtering, and test SGS on publicly standard benchmarks.
- Handling impossible/ill-posed targets: Despite filtering, some problems may be unsolvable; measure SGS robustness when a fraction of targets are impossible, and add detection/avoidance mechanisms.
- Measuring synthetic problem quality: Beyond length and disjunction rate, define and report richer quality metrics (e.g., minimality, premise redundancy, structural similarity) and their correlation with downstream gains.
- Evidence of causality: The paper shows more synthetic-problem training near solve time; quantify causal uplift via interventions (e.g., shuffling/removing high-scoring synthetics) to validate that guided synthetics cause target solves.
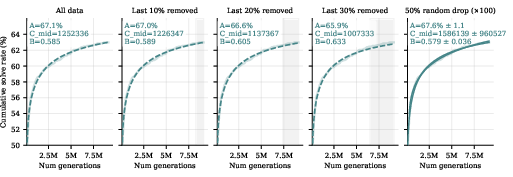
- Long-horizon stability: Runs reached ~6–8M generations; extend runs or conduct restarts to test if Guide remains robust and if new forms of degeneracy emerge at larger scales.
- Scaling-law modeling: Fits use a single sigmoidal form and omit early data; compare alternative functional forms (Gompertz, double logistic), provide uncertainty bands/credible intervals, and analyze how early-phase truncation affects asymptotes.
- Fair comparisons to STP and other self-play methods: Report consistent compute budgets, pass@k, and identical datasets/prompts to isolate SGS’s contribution from other confounds.
- Extension beyond formal math: Demonstrate SGS in domains requiring full MDP specification (e.g., robotics simulators, code with unit tests, natural language math with learned verifiers), and quantify verifier noise tolerance required for stable learning.
- Guide–Conjecturer co-evolution safety: When learning the Guide, specify safeguards (e.g., anti-collusion audits, multi-judge oversight) to prevent mutual reinforcement of biases or reward hacks.
- Diversity vs. elegance trade-offs: The Guide favors “clean” problems; measure whether this suppresses necessary diversity or certain proof styles, and design constraints to maintain diversity while enforcing usefulness.
- Effect of rollouts budget: Only attempts per problem were used in training; sweep and study how pass@k budget interacts with SGS dynamics and compute efficiency.
- Code/data availability for Guide SFT: The 2,048 SFT examples for Guide formatting were GPT-generated; release examples or replicable generation scripts and test other formatting strategies to reduce dependency on proprietary models.
Practical Applications
Immediate Applications
Below are concrete ways the paper’s Self-Guided Self-Play (SGS) method can be used today, especially in domains with clear verifiers (compilers, unit tests, formal checkers) and in training pipelines where data quality and reward hacking are challenges.
- Formal theorem proving curriculum generation and proof assistance
- Sectors: software (formal verification), academia (mathematics, PL)
- Tools/products/workflows: “SGS-Prover” that auto-generates related, simpler subtheorems for unsolved Lean4 goals; IDE plugin to propose guided stepping-stones and verify them; nightly CI job to expand formal libraries by targeting current unsolved lemmas
- Assumptions/dependencies: access to a formal verifier (Lean4), base prover with reasonable competence, compute budget for long runs, Guide prompt quality and calibration
- Test-driven self-play for code generation and repair
- Sectors: software, DevOps/CI
- Tools/products/workflows: “SGS-Coder” tri-agent loop where the Conjecturer proposes unit tests or minimal repros tied to failing tickets; Solver writes code; Guide scores tests for relevance and clarity; CI gate that prioritizes high-Guide-score test cases and avoids degenerate tests; failure-focused curriculum for flaky tests
- Assumptions/dependencies: robust unit-test harnesses and coverage, reliable sandboxes, policy to reject adversarial/degenerate tests, monitoring of Solver entropy (e.g., KL or entropy bonus if using grouped RL)
- Targeted fuzzing and property-based testing with self-guidance
- Sectors: software, security
- Tools/products/workflows: Conjecturer generates structured inputs targeting unsolved failures; Guide rejects “pathological” or over-complex inputs; integrated with fuzzers (e.g., hypothesis/QuickCheck) to prioritize elegant, relevant cases
- Assumptions/dependencies: oracle/validator (crash, invariant check), safe execution environment, Guide rubric tuned to avoid “reward hacking” through contrived edge cases
- SQL and data pipeline QA via self-play
- Sectors: data engineering, finance
- Tools/products/workflows: SGS generates unit tests and edge-case datasets tied to unsolved ETL defects; Guide filters unclear or overly complex specifications; Solver proposes SQL or transformation code; CI “Solve-Rate Monitor” to stop overtraining on trivial cases
- Assumptions/dependencies: executable test DBs and data contracts, deterministic validators, strong logging to attribute test relevance to specific defects
- Synthetic dataset generation with an LLM Guide filter
- Sectors: academia/industry ML, content ops
- Tools/products/workflows: “Guide-Score Filter” for synthetic Q&A, math, or code corpora; Guide rejects messy, unnatural, or spurious items; integrates into data pipelines to prevent dataset drift toward degenerate distributions
- Assumptions/dependencies: carefully designed Guide rubric, periodic human calibration, drift detection for Guide scoring over time
- Personalized practice problem generation for education
- Sectors: education, consumer edtech
- Tools/products/workflows: “SGS Tutor” that conditions the Conjecturer on unsolved learner skills and produces clean, targeted subproblems; Guide enforces clarity and prevents overlong, convoluted items; auto-graded problems via rule-based or formal checkers (e.g., symbolic algebra, geometry)
- Assumptions/dependencies: reliable auto-graders or CAS checks, content alignment with curricula, safety filters for inappropriate content
- Training stability and governance for RL-based LLM fine-tuning
- Sectors: ML platforms, MLOps
- Tools/products/workflows: “Entropy Guard” to monitor policy entropy and solve-rate distributions; switch or regularize objectives (e.g., REINFORCE vs. grouped RL + entropy bonus/KL) to prevent solver collapse; dashboards that track Guide/Solver rewards and cumulative solve-rate curves
- Assumptions/dependencies: instrumentation of RL runs, scalable logging/metrics, ability to adjust RL objectives mid-run
- Compute budgeting and stopping rules using solve-rate scaling laws
- Sectors: ML ops, finance/budgeting, program management
- Tools/products/workflows: Fit sigmoidal solve-rate curves vs. generations to estimate asymptotes and midpoints; “Solve-Rate Planner” that forecasts marginal returns for continued training and sets stop criteria or reallocation suggestions
- Assumptions/dependencies: stable logging and periodic evaluation, awareness that asymptote estimates carry uncertainty (paper notes ~1.1% sd under subsampling)
- Benchmark curation with an LLM Guide
- Sectors: academia, evaluation groups, standards bodies
- Tools/products/workflows: Use a Guide rubric to triage and filter noisy/degenerate synthetic items in benchmarks (math, coding, reasoning), keeping problem naturalness and clarity near the seed distribution
- Assumptions/dependencies: human-in-the-loop spot checks, periodic recalibration to prevent rubric overfitting
Long-Term Applications
These rely on maturing verifiers/simulators, better multimodal Guides, or more scalable training infrastructure. They extend SGS to less strictly verifiable domains and to complex, safety-critical systems.
- Robotics and embodied control with self-guided curricula
- Sectors: robotics, manufacturing, logistics
- Tools/products/workflows: “SGS-Robotics” where the Conjecturer proposes subgoals and scenes in simulators or learned world models (e.g., Genie-like); VLM-based Guide scores task relevance/cleanliness; Solver learns policies via RL; transfer to real via sim2real
- Assumptions/dependencies: high-fidelity simulators/digital twins, robust reward definition via VLMs/sensors, safety gates for real-world deployment, domain randomization
- Scientific discovery and experiment planning
- Sectors: R&D, pharma, materials science
- Tools/products/workflows: “SGS-Scientist” that proposes sub-experiments/hypotheses toward unsolved goals (e.g., synthesis targets); simulators (QSAR, docking, MD) provide reward; Guide promotes elegant, minimal confound designs
- Assumptions/dependencies: trustworthy simulators/auto-evaluators, lab automation integration, careful bias control, human oversight for ethics and safety
- General-purpose web and tool-use agents with self-guided tasks
- Sectors: software, customer support, enterprise automation
- Tools/products/workflows: Conjecturer generates sub-tasks grounded in unsolved workflows (ticket triage, RPA tasks); tool execution provides verifiable reward; Guide filters contrived or brittle tasks; curricula evolve with real user backlog
- Assumptions/dependencies: reliable tool execution logs as verifiers, careful sandboxing, alignment and guardrails to avoid reward hacking behavior
- Formalization and compliance reasoning for law and policy
- Sectors: public policy, legal tech, regtech
- Tools/products/workflows: Formal methods to encode policy/regulatory constraints; SGS proposes sub-clauses or clarifying lemmas that lead to provable compliance; Guide promotes clarity and naturalness of formalizations
- Assumptions/dependencies: adoption of formal representations (typed logic/DSLs), institutional buy-in, rigorous validation and auditing
- Grid, energy, and operations control via digital twins
- Sectors: energy, industrial automation
- Tools/products/workflows: “SGS-Grid”—Conjecturer creates sub-scenarios (load spikes, faults) relevant to unsolved reliability goals; digital twin gives reward; Guide rejects unrealistic or overly complex scenarios
- Assumptions/dependencies: high-fidelity twins, safety and stability constraints, regulator-approved evaluation, robust sim-to-field generalization
- Financial risk stress testing and scenario generation
- Sectors: finance, risk management
- Tools/products/workflows: SGS generates stress scenarios aligned with unsolved portfolio constraints; simulators/backtests produce reward; Guide prioritizes realistic, regulator-aligned stressors
- Assumptions/dependencies: credible market simulators, model risk governance, avoidance of overfitting to historical anomalies
- Large-scale automated refactoring and modernization
- Sectors: software, enterprise IT
- Tools/products/workflows: Self-play proposes targeted property tests and intermediate refactoring subgoals; Guide filters degenerate tests/specs; Solver performs staged transformations in massive codebases
- Assumptions/dependencies: property/invariant discovery at scale, CI/CD capacity, rollback and safety policies, deterministic build systems
- Multimodal design and verification (EDA/CAD/architecture)
- Sectors: semiconductors, mechanical design, architecture
- Tools/products/workflows: SGS generates assertions and subproblems (timing, power, constraints) verified by simulators/formal tools; Guide suppresses contrived constraint sets
- Assumptions/dependencies: mature verifiers, IP and data confidentiality, integrated toolchains
- Self-evolving benchmarks and curricula for STEM at scale
- Sectors: education, workforce training
- Tools/products/workflows: “AutoBench/AutoCurriculum” that continuously proposes and curates problem sets targeted to cohort weaknesses; Guide enforces clarity and alignment; outcome-driven reward via proctoring/auto-graders
- Assumptions/dependencies: reliable outcome measures, bias and fairness monitoring, accreditation acceptance
- Healthcare decision support with simulators and constrained reasoning
- Sectors: healthcare
- Tools/products/workflows: SGS to propose sub-differentials or test orders tied to unsolved diagnostic goals; simulators/clinical pathways provide partial rewards; Guide enforces clean, guideline-conformant reasoning
- Assumptions/dependencies: validated medical simulators or pathway engines, strict regulatory oversight, privacy, extensive clinical validation
Cross-cutting assumptions and dependencies
- Verifiers/simulators: SGS thrives where correctness is machine-checkable; for non-verifiable domains, proxy verifiers (e.g., VLMs, digital twins) must be sufficiently reliable and periodically audited.
- Guide quality and calibration: The Guide must be instruction-following, consistent, and aligned with domain-specific “naturalness/clarity” rubrics; periodic human calibration reduces drift.
- Solver entropy management: Use objectives and regularization (e.g., REINFORCE, entropy bonus, KL to base model) to avoid entropy collapse that starves the Conjecturer of learning signal.
- Prompting and format adherence: Tri-role prompts should be standardized; small SFT stages (as in the paper) may be necessary to ensure formatting fidelity for the Guide/Conjecturer.
- Compute and infrastructure: Long-running self-play requires scalable generation–verification pipelines, efficient fault tolerance, and monitoring of cumulative solve rates.
- Safety, governance, and ethics: Especially for high-stakes domains (healthcare, finance, critical infrastructure), integrate human oversight, audit trails, red-teaming, and policy constraints to prevent reward hacking and unsafe behavior.
Glossary
Below is an alphabetical list of advanced terms from the paper, each with a concise definition and a verbatim usage example.
- Asymmetric self-play: A self-play setup with distinct roles (e.g., task proposer and solver) that learn through interaction. "SGS is an instance of asymmetric self-play, methods in which agents with asymmetric roles, typically a Conjecturer generating tasks and Solver solving them, learn through interaction."
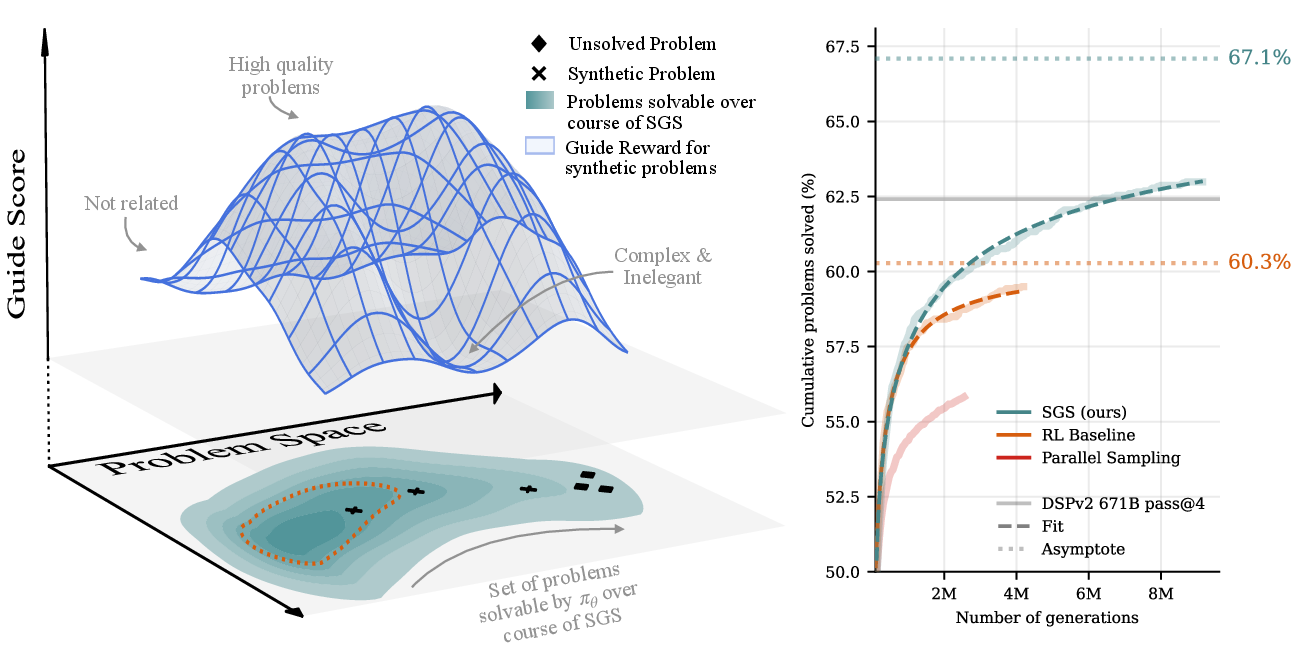
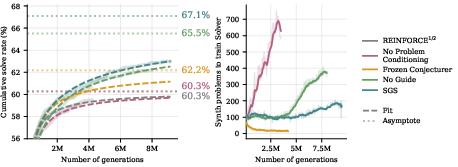
- Asymptotic solve rate: The performance level a method approaches as compute grows very large. "surpasses the asymptotic solve rate of our strongest RL baseline in fewer than 80 rounds of self-play"
- bfloat16 precision: A 16‑bit floating-point format with a wider exponent than FP16, used for efficient training. "All models use bfloat16 precision and a maximum sequence length of 8192 tokens."
- CISPO: A grouped RL objective for LLMs (clipped-importance-sampling style policy optimization) used as a baseline. "CISPO performs poorly due to entropy collapse"
- Conjecturer: The model role that generates synthetic problems (often conditioned on unsolved targets) to train the Solver. "a Conjecturer model creates problems for a Solver, and both improve together."
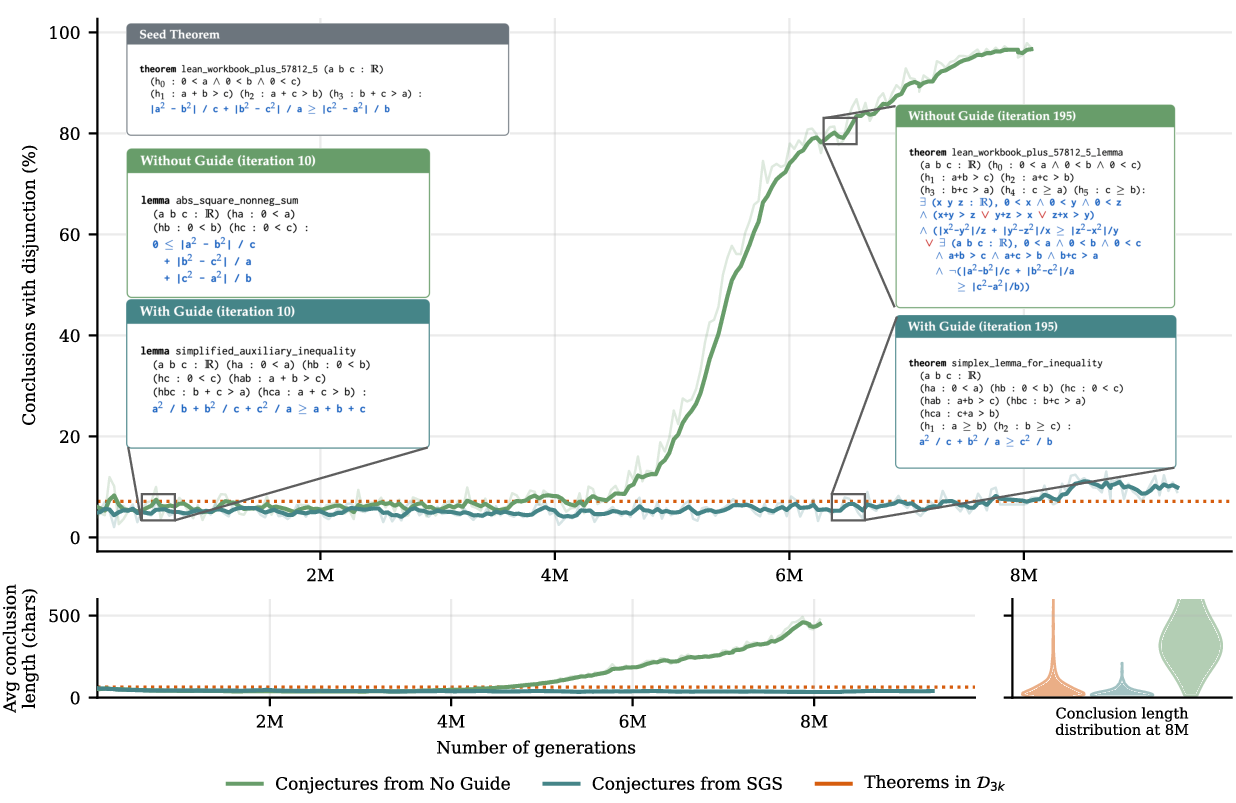
- Disjunctive conclusion: A logical conclusion formulated as a disjunction (OR) of clauses. "Top: Percentage of generated problems with disjunctive conclusions."
- Entropy bonus: A regularizer added to RL objectives to encourage exploration by increasing policy entropy. "such as the use of an entropy bonus or KL regularization to the base model"
- Entropy collapse: The degeneration of a policy into near-determinism, reducing exploration and training signal. "CISPO performs poorly due to entropy collapse"
- Expert Iteration: An iterative training framework that alternates expert search/labeling and policy learning. "We also test a variant of Expert Iteration suggested by \citet{dong2025stp}, which involves only sampling solutions for any problem that we have solved fewer than 16 times."
- Guide: An LLM-based judge that scores synthetic problems for relevance and quality to prevent degenerate tasks. "model takes on three roles: Solver, Conjecturer, and a Guide that scores synthetic problems by their relevance to unsolved target problems"
- Importance weight: The ratio used in off-policy RL to correct for sampling distribution differences, often clipped for stability. "For CISPO, we set $\epsilon_{\mathrm{low} = 1.0$ and $\epsilon_{\mathrm{high} = 3.0$ (clipping the importance weight to )."
- KL regularization: Penalizing the Kullback–Leibler divergence from a reference policy to stabilize RL training. "such as the use of an entropy bonus or KL regularization to the base model"
- Lean4: A formal proof assistant and language used to write and machine-check mathematical proofs. "for our experiments, using the Lean4 compiler"
- Markov Decision Process (MDP): The standard formalism for sequential decision-making (states, actions, transitions, rewards). "the Conjecturer would have to produce an entire Markov Decision Process (MDP), including a reward function, to train the Solver."
- pass@4: The probability that at least one correct solution appears within 4 sampled outputs. "We see that at 6.3M generations, SGS applied to the 7B parameter DeepSeek-Prover-V2 model exceeds the pass@4 of the larger 671B counterpart."
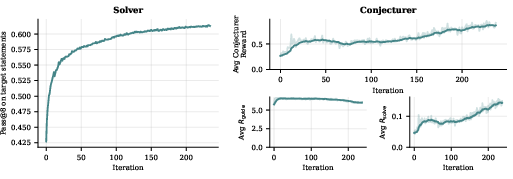
- REINFORCE: A Monte Carlo policy-gradient method that maximizes expected reward via log-likelihood weighting of sampled returns. "We use a REINFORCE objective on all problems with solve rate less than or equal to 0.5"
- Scaling laws: Empirical relationships modeling how performance scales with compute/data/model size. "Second, we fit scaling laws to the cumulative solve rate over training, allowing us to extrapolate long-run behavior"
- Sigmoidal curve: An S-shaped function used here to model bounded accuracy (solve rate) versus log-compute. "we adopt a sigmoidal curve (with respect to log compute) of the form"
- Soft Overlong Punishment: A length-penalty scheme that discourages near-context-limit generations by assigning negative rewards. "We apply a length penalty to all RL updates inspired by Soft Overlong Punishment \citep{yu2025dapo}."
- Solver: The model role that attempts to solve target and synthetic problems and is trained from verification rewards. "a Conjecturer model creates problems for a Solver, and both improve together."
- Solve rate: The fraction of sampled attempts that successfully solve a given problem. "Let $s(\tilde{x}) = \frac{1}{k} \sum_{i=1}^k v(y^i_{\tilde{x})$ be the solve rate of the synthetic problem."
- Speculative reassignment: A systems technique that duplicates straggling tasks to idle workers to reduce tail latency. "Second, speculative reassignment: when no pending tasks remain but some are still in progress, the server assigns duplicate copies of in-progress tasks to idle workers, preferring the task with the fewest current workers."
- Synthetic problem: A model-generated training task intended to be simpler yet relevant to a target problem. "the Conjecturer is prompted to produce a synthetic problem that is useful for solving that problem."
- try tactic: A Lean tactic that attempts to apply a sequence of tactics; here discouraged due to looping behavior. "We also give 0 reward to any Solver proof with the try tactic"
- ZeRO Stage-2: A distributed optimization technique (Zero Redundancy Optimizer) that shards optimizer states across data-parallel workers. "Training uses a single H200 node with ZeRO Stage-2 distributed optimization."
Collections
Sign up for free to add this paper to one or more collections.

