GASP: Guided Asymmetric Self-Play For Coding LLMs
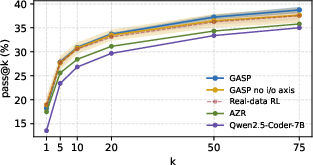
Abstract: Asymmetric self-play has emerged as a promising paradigm for post-training LLMs, where a teacher continually generates questions for a student to solve at the edge of the student's learnability. Although these methods promise open-ended data generation bootstrapped from no human data, they suffer from one major problem: not all problems that are hard to solve are interesting or informative to improve the overall capabilities of the model. Current asymmetric self-play methods are goal-agnostic with no real grounding. We propose Guided Asymmetric Self-Play (GASP), where grounding is provided by real-data goalpost questions that are identified to pose a hard exploration challenge to the model. During self-play, the teacher first generates an easier variant of a hard question, and then a harder variant of that easier question, with the goal of gradually closing the gap to the goalpost throughout training. Doing so, we improve pass@20 on LiveCodeBench (LCB) by 2.5% over unguided asymmetric self-play, and through the curriculum constructed by the teacher, we manage to solve hard goalpost questions that remain out of reach for all baselines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
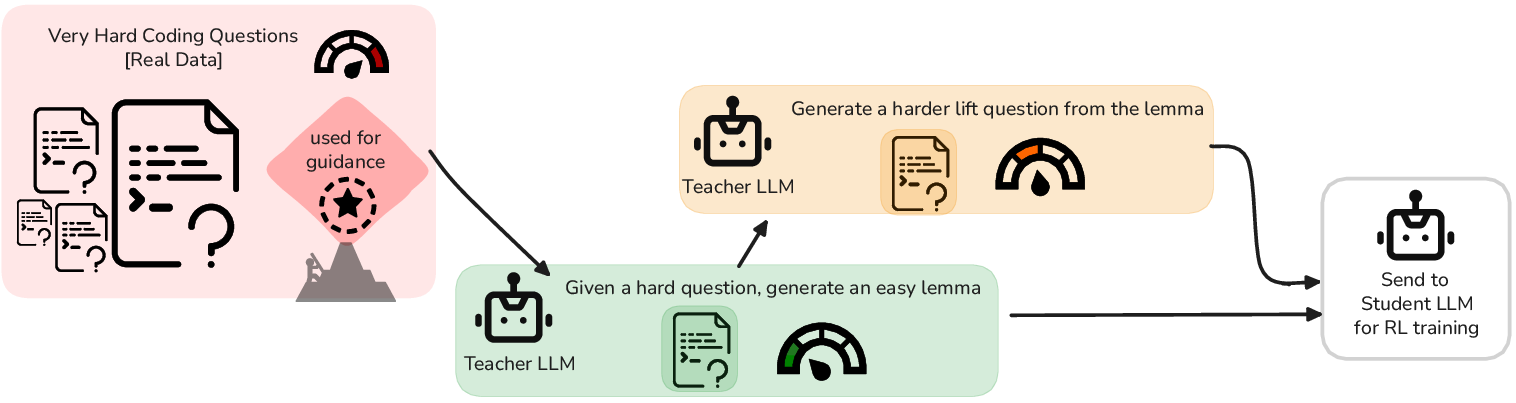
This paper introduces a new way to train coding AIs (computer programs that write code) so they get better at solving tough problems without needing lots of new human-made practice questions. The method is called GASP, which stands for Guided Asymmetric Self-Play. The key idea is to guide the AI with real, very hard coding problems and build a step-by-step path (a curriculum) that helps it reach those hard problems over time.
What questions were the researchers asking?
They focused on two simple questions:
- If we point the training toward real hard problems (the “goalposts”), can the AI actually make progress on them during training?
- Does this guidance help the AI learn better overall, so it does better on standard coding tests?
How did they do it? (Methods in everyday language)
Think of a sports coach and a player:
- The “teacher” (coach) creates practice drills.
- The “student” (player) tries to solve them.
- Over time, the coach adjusts the difficulty to push the player’s skills forward.
Here’s how GASP turns that into an AI training method:
- Goalposts: First, they pick a set of real coding problems that are known to be very hard for the AI. These are the “goalposts” — the distant targets to reach.
- Lemma, then Lift (stepping stones): For each hard goalpost:
- The teacher makes an easier version of the problem called a “lemma.” It should keep the same general idea as the goalpost but be solvable with effort. If it’s too easy or too hard, they discard it and try again.
- Next, starting from that lemma, the teacher makes a slightly harder version called a “lift.” This nudges the student closer to the original hard goalpost.
- The student practices on these lemma and lift problems, gradually learning the skills needed to tackle the goalpost.
- Two ways to make problems harder:
- Change the examples to make the same rule trickier to figure out (like changing how input data is arranged). Think: same game, trickier positions.
- Make the underlying rule itself more complex (like adding extra logic). Think: same game, but with new rules.
- Keep it challenging but learnable: The teacher aims for problems that are “not too easy and not too hard,” so the student gets useful feedback and improves steadily.
- Quality and variety checks: They automatically reject practice problems that are broken, unsafe, or almost duplicates of ones already seen. This avoids the AI getting stuck practicing the same thing over and over.
- Different puzzle styles: During practice, the student sometimes:
- Learns the rule from several input/output examples (induction).
- Runs a known rule on a new input (deduction).
- Finds an input that matches a desired output (abduction).
- This variety keeps training balanced.
- Optional extra: They also test a version that mixes in real, human-written coding problems during training, alongside the guided self-play data.
What did they find, and why does it matter?
On a modern coding benchmark called LiveCodeBench (LCB), the method did well:
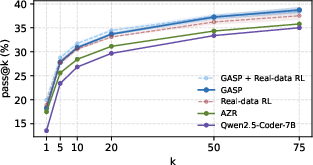
- Better than unguided self-play: GASP beat a popular baseline (Absolute Zero, or AZR) that does self-play without guidance. On “pass@20” — roughly, “if the AI is allowed 20 tries, how often does at least one solution pass the tests?” — GASP improved by about 2.5 percentage points over unguided self-play. That’s a solid boost for this kind of benchmark.
- Competitive with training on real data: GASP, even without extra real-data training, was similar to a standard method that relies on real, human-written problems (RL with verifiable rewards).
- Even better together: When they combined GASP with real-data training, results improved further.
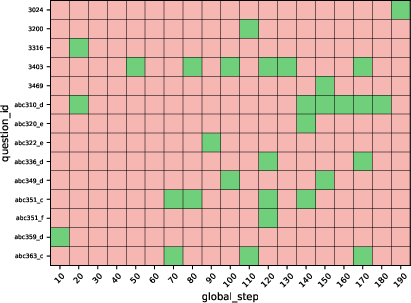
- Solving actually hard stuff: Importantly, GASP managed to solve some of the hard goalpost problems that none of the other methods could solve. That shows the step-by-step curriculum really helped the AI reach tougher challenges.
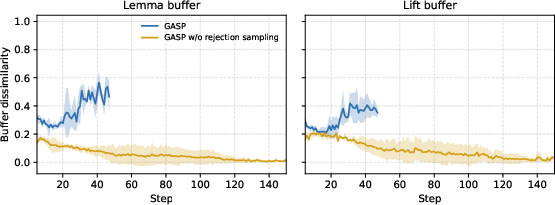
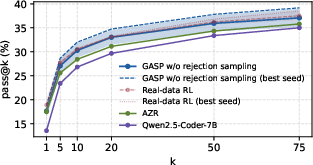
- Stability from variety: The “reject similar or broken questions” rule made training more stable by keeping practice problems diverse.
Why it matters: These results suggest that guiding self-play with real hard targets and building a smart curriculum helps coding AIs learn more relevant skills, not just random tricky puzzles.
Why is this important? (Implications and impact)
- Less human effort: GASP can generate its own useful training problems, reducing the need for tons of new human-made exercises.
- More relevant learning: By aiming at real hard problems, the AI practices skills that actually improve performance on standard coding tests.
- Works alone or in combo: It can stand on its own or be combined with regular training on real data to get even better results.
- A path to harder reasoning: The step-by-step “lemma → lift” approach is like building a staircase to reach very tough problems, which could help beyond coding (for example, in math or logic).
Simple limitations to keep in mind:
- Not every generated step perfectly matches the original hard problem’s idea; sometimes the AI adds extra complications that aren’t the most helpful.
- The system uses a fixed set of hard targets; updating these targets as the AI improves could make it even better.
- Future versions could add a “judge” to better check whether each step truly moves toward the goal.
Overall, GASP shows a practical and effective way to guide an AI to learn from its own practice, while staying focused on real, meaningful challenges.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up work:
- Alignment between stepping stones and goalposts
- No quantitative metric to ensure lemma/lift preserve the “motif” of a goalpost; need automatic alignment checks (e.g., judge/reward models, semantic/AST-based similarity) and empirical analyses of motif fidelity.
- No definition of a “distance-to-goalpost” metric; cannot track whether generated tasks are truly closing the gap to the target.
- Reward design and sensitivity
- Learnability reward shapes and pass-rate bands (e.g., 0.3–0.7 for lemma, 0.1–0.5 for lift) are heuristic; no ablations on α, exponents, band widths, or adaptive targeting of difficulty.
- No analysis of pass-rate estimation noise vs. N trials; need confidence-interval–aware acceptance and cost–benefit trade-offs.
- Curriculum and axis control
- Teacher often drifts back to functional (f) axis when I/O axis was chosen; no mechanism to enforce axis adherence or to adaptively choose axes based on student feedback.
- Only a two-stage (lemma→lift) curriculum is explored; richer multi-step curricula, adaptive stage lengths, or goal-conditioned schedules are unexplored.
- Static goalpost set
- Goalposts are fixed; no policy for adding/removing/updating goalposts as capabilities improve, or for prioritizing by estimated tractability or impact.
- No robustness study when goalposts are mis-specified (e.g., ambiguous, unsolvable, or off-distribution).
- Persistence and consolidation of gains
- Goalpost solves are intermittent; no mechanism to consolidate capabilities (e.g., replay of solved goalposts, targeted fine-tuning on near misses, stability-driven selection).
- No analysis of how often and why previously solved goalposts regress at subsequent checkpoints.
- Baselines and checkpoint selection
- Checkpoint selection maximizes pass@20 on the evaluation split (LCBv5), risking test-set overfitting; a clean validation set and pre-registered selection criteria are needed.
- AZR comparison uses a single public checkpoint with different training/selection protocols; fairness requires re-training baselines under matched compute, data, and selection rules.
- Scope and generalization
- Evaluation is mostly on LCBv5 (plus limited greedy pass@1 on HumanEval+ and MBPP+); broader benchmarks (multi-file, multi-language, real repos) and robustness tests are missing.
- Unclear whether guided self-play transfers to other domains (math, theorem proving) without major re-engineering of goalposts and reward shapes.
- Data usage and reliance on real data
- Pure GASP “does not train on” real data but uses real-data goalposts as prompts; need controlled studies isolating the effect of using real-data guidance vs. purely synthetic anchors.
- Teacher/student design choices
- Teacher and student share parameters; no study of decoupled roles (separate models), asymmetric update frequencies, or stabilizing techniques (e.g., target-network–like teachers).
- Teacher generates only induction tasks; the effect of having the teacher also generate deduction/abduction problems is unexplored.
- Mixture schedules in joint training
- For GASP + Real-data RL, the mixing ratio, ordering, and schedule are ad hoc; no systematic tuning or sensitivity analysis of how real-data and synthetic data should be interleaved.
- Diversity enforcement and rejection sampling
- Embedding-based novelty threshold (0.95) and embeddings used are not justified; need ablations on thresholds, embedding types, acceptance rates, and their impact on performance/variance.
- Lack of quantitative diversity/coverage metrics for generated tasks (beyond rejection sampling), and no measurement of mode collapse frequency.
- Safety, determinism, and execution environment
- Safety and non-determinism filters are only described at a high level; sandbox specs, resource limits, and false positive/negative rates are not reported.
- Potential exploitability of teacher-generated tests (e.g., brittle or adversarial test design) is not assessed.
- Test design and generalization for synthetic tasks
- Details of public/private split for teacher-generated I/O are sparse; no evaluation of generalization to held-out synthetic tests distinct from visible examples.
- No safeguards against the teacher crafting tasks where superficial heuristics yield the target pass-rate without teaching generalizable skills.
- Compute and efficiency
- No reporting of wall-clock time, token budget, acceptance rates, or cost per improvement vs. RLVR; sample/compute efficiency remains unclear.
- The multi-stage generate–evaluate–reject loop could be expensive; guidelines to reduce cost (e.g., early stopping, low-cost prefilters) are missing.
- Scaling behavior
- Only Qwen2.5-Coder-7B is studied; no scaling curves with larger/smaller backbones to test whether gains persist, saturate, or grow with model size.
- No investigation of how the size of the goalpost pool or synthetic data volume affects outcomes.
- Mechanistic understanding and failure cases
- LLMs often add constraints or borrow surface metaphors; no taxonomy of failure modes or interventions (e.g., motif extraction via AST/program analysis, semantic perturbations).
- No causal disentanglement of what drives improvements (goalpost prompting vs. lemma-lift design vs. reward shape vs. diversity filters).
- Distance-to-goalpost tracking
- No quantitative evidence that lemma/lift proposals get “closer” to goalposts over training; need trajectory analyses using semantic similarity or invariants.
- Robustness to seed and hyperparameters
- Some ablations show large seed variance; lack of systematic hyperparameter sweeps (e.g., N, M, learning rates, band thresholds) to identify stable regimes.
- Ethical and security considerations
- No discussion of the risk that synthetic tasks encourage unsafe code patterns or sandbox escape attempts despite filters; need explicit auditing and mitigation strategies.
Practical Applications
Immediate Applications
Below are concrete ways GASP (Guided Asymmetric Self-Play) can be used now, drawing on its guided curriculum generation, learnability-based rewards, and verifiable RL loop for coding tasks.
- Software engineering and AI product teams
- CI-integrated “self-play fine-tuning” to reduce build failures
- Workflow: Mine failing or flaky tests and unresolved tickets as goalposts; generate lemma (easier) and lift (harder) problem variants; fine-tune the in-house code LLM with RLVR using verifiable unit tests as rewards; redeploy the model in the IDE/CI.
- Potential tools/products: “Goalpost Miner” service; “Lemma–Lift Generator” prompt library; “Self-Play Trainer” using Task-Relative REINFORCE++; diversity filter module (rejection sampling).
- Dependencies/assumptions: Safe sandboxed execution for tests; a base model with sufficient coding ability; compute budget for RL; robust pass/fail test suites (verifiable rewards); monitoring for distribution shifts.
- Rapid domain adaptation of code assistants to internal APIs
- Workflow: Treat recurring internal API misuse or unsolved API-specific tasks as goalposts; synthesize targeted curricula that preserve the motif (API usage patterns) and progressively increase complexity.
- Dependencies/assumptions: Access to logs or telemetry to identify goalposts; curated safety rules for code execution; embeddings for similarity filtering to avoid near-duplicate data.
- Test-input stress generation via the I/O difficulty axis
- Workflow: For a given task motif, generate edge-case input–output examples to harden test suites (e.g., nested structures, multi-argument cases).
- Dependencies/assumptions: Mechanisms to validate that examples are truly within-motif; automated deduplication and determinism checks.
- Education and EdTech
- Personalized programming curricula with scaffolding
- Workflow: Use a student’s unsolved problems as goalposts and automatically create lemma (scaffold) and lift (stretch) exercises; integrate into LMS/autograder.
- Potential products: “Instructor Copilot” that generates course-aligned variants; plug-ins for coding practice platforms.
- Dependencies/assumptions: Availability of per-student performance data; verifiable test-based grading; content alignment checks to ensure pedagogical fit.
- Guided remediation within coding autograders
- Workflow: After a wrong submission, present a “lemma” exercise that isolates the underlying motif, then a “lift” to consolidate learning before retrying the original problem.
- Dependencies/assumptions: Clear motif extraction from goalposts; reliable difficulty control via pass-rate bands.
- Research and open-source model training
- Data-efficient post-training of coding LLMs with minimal human data
- Workflow: Adopt GASP to generate targeted synthetic coding tasks from a curated hard subset; update a base model (e.g., 7B) to improve pass@k on modern benchmarks.
- Dependencies/assumptions: Compute availability; reproducible evaluation (e.g., LCB); robust filtering for safety and novelty.
- Dynamic benchmark curation and targeted evaluation
- Workflow: Maintain a “hard set” of unsolved items as standing goalposts; report model progress not only by aggregate pass@k but also by resolution of goalposts over time.
- Dependencies/assumptions: Stable labeling of unsolved vs solved; checkpoint tracking; seed-controlled evaluations.
- Hiring and developer upskilling platforms
- Scaffolded interview and practice tracks
- Workflow: Convert failed questions into personalized lemma/lift variants to build toward the original challenge, improving candidate preparation and feedback.
- Dependencies/assumptions: Verifiable tasks aligned with assessment criteria; content variation to avoid leakage of future items.
- Daily life and individual learners
- Self-paced coding practice tailored to personal weaknesses
- Workflow: A desktop/web tool that ingests your failed problems and generates graded exercises (lemma→lift→goalpost).
- Dependencies/assumptions: Local or cloud sandbox to run tests safely; basic LLM access; progress tracking.
- Tooling you can build today (cross-cutting)
- “Goalpost Miner” (logs/tests to hard set), “Lemma–Lift Generator” (prompt templates for I/O vs f-axis), “Self-Play Curriculum Engine” (learnability-based rewards, pass-rate banding), “Diversity Gate” (similarity filtering), “CI RLVR Runner” (safe code execution, checkpointing).
- Dependencies/assumptions: Embedding model for similarity; test harnesses; secure isolation for code execution; observability dashboards.
Long-Term Applications
These applications extend GASP’s guided self-play beyond coding or require additional research, scaling, or infrastructure before deployment.
- Cross-domain guided curricula with verifiable rewards
- Mathematics and formal reasoning
- Idea: Use unsolved proofs/problems as goalposts; generate formal lemma and lift conjectures to bridge to hard theorems.
- Dependencies/assumptions: High-quality formal verifiers (e.g., proof assistants); domain-specific prompting; reliable reward signals.
- Data/analytics and SQL/spreadsheet automation
- Idea: Treat failing queries or incorrect spreadsheet formulas as goalposts; generate simpler/harder tasks to train assistants for robust data transformations.
- Dependencies/assumptions: Deterministic reference outputs; sandboxes with representative datasets; privacy-preserving setups.
- Robotics and autonomous systems
- Idea: In simulation, designate unsolved tasks as goalposts; generate simplified environments (lemma) and progressive variants (lift) to overcome exploration barriers.
- Dependencies/assumptions: High-fidelity simulators, safety constraints, and verifiable success metrics; sim-to-real transfer strategies.
- Continual learning and dynamic goalpost management
- Always-on adaptation pipelines
- Idea: Production systems continuously mine fresh goalposts from failures; automatically update curricula and models, with regression checks.
- Dependencies/assumptions: Strong monitoring and rollback; automated risk assessment; drift detection; governance for model updates.
- Judge/reward models for better alignment
- Idea: Add a learned judge to score how well lemma/lift preserve the target motif and contribute to solving goalposts, reducing surface-level shortcuts.
- Dependencies/assumptions: High-quality preference data; robust reward-model training; defenses against reward hacking.
- Software agents and program repair
- Multi-step software maintenance with verifiable objectives
- Idea: Use failing CI/CD pipelines as goalposts; generate scaffolding repair tasks and incremental refactoring challenges for agent training.
- Dependencies/assumptions: Rich, realistic repos; policy/safety controls for code changes; comprehensive test suites.
- Security and reliability training
- Vulnerability remediation curricula
- Idea: Use real CVEs as goalposts; generate sanitized lemma/lift tasks to train secure coding assistants and agents without exposing exploits directly.
- Dependencies/assumptions: Secure sandboxes; ethical guidelines; automatic sanitization and decontamination; rigorous red-team evaluation.
- Policy and standards
- Goalpost-guided RL as a responsible training pattern
- Idea: Incorporate verifiable, safety-gated, goalpost-guided self-play into AI governance playbooks for coding assistants in regulated sectors (e.g., healthcare, finance, public sector IT).
- Dependencies/assumptions: Audit trails for training data and checkpoints; standardized verifiable metrics; third-party evaluation frameworks.
- Synthetic data governance and privacy
- Motif-preserving synthetic curricula to reduce reliance on sensitive/copyrighted corpora
- Idea: Derive challenge motifs from protected datasets internally but publish only synthetic lemma/lift tasks for broader training.
- Dependencies/assumptions: Processes to ensure motif retention without leakage; legal review; watermarking and traceability.
- Benchmarking and ecosystem evolution
- Dynamic benchmarks driven by unsolved tasks
- Idea: Benchmarks that automatically promote persistent failures to goalposts and track “unlocking” over time, measuring frontier shifts rather than only aggregate scores.
- Dependencies/assumptions: Community agreements on protocols; reproducibility infrastructure; transparent checkpoint selection.
In all cases, feasibility hinges on key assumptions central to GASP: the presence of verifiable rewards (unit tests, formal checkers, measurable success criteria), reliable mining of genuinely hard yet relevant goalposts, sufficient model capacity and compute for RL post-training, safe and deterministic execution environments, and mechanisms to enforce novelty/diversity in generated data.
Glossary
- Abduction: Inverse reasoning task where an input consistent with a given output must be inferred, often used in program synthesis. "Abduction:\quad & (f, o) \;\Rightarrow\; f(\hat i) = o"
- Absolute Zero (AZR): A self-play framework for training LLMs in coding by generating and solving tasks without relying on large human datasets. "Most notably and closest to our setting, Absolute Zero (AZR) employs asymmetric self-play in the coding domain."
- Asymmetric self-play: A training paradigm where a teacher model proposes tasks and a student model solves them, with both roles often sharing parameters. "Asymmetric self-play, in contrast, generates problems on-the-go."
- Curriculum: An ordered progression of tasks designed to gradually increase difficulty and facilitate learning. "In this way, and serve as stepping stones that build a curriculum."
- Deduction: Forward reasoning task where an output is produced from a given program and input. "Deduction:\quad & (f, i) \;\Rightarrow\; \hat o = f(i)"
- Few-shot anchoring: Guiding a model using a small number of labeled examples to steer generation or reasoning. "However, their grounding relies on few-shot anchoring to a small labeled dataset, rather than steering toward a designated hard set of real-data goalposts as in GASP."
- f axis: The difficulty-adjustment dimension that changes the underlying algorithmic mapping itself (increasing functional complexity). "(2) The axis increases (or decreases) algorithmic complexity by modifying the mapping itself, e.g by introducing additional constraints or composing new operations that require extra logic beyond the original rule."
- GASP (Guided Asymmetric Self-Play): The proposed method that guides self-play using real-data hard “goalpost” questions and a lemma→lift curriculum. "We propose Guided Asymmetric Self-Play (GASP)"
- Goalpost (goalpost questions): Real-data hard questions used to ground and guide the teacher’s task generation. "We refer to this subset as our goalpost questions."
- Hard exploration (challenge): A setting where the reward signal is sparse or difficult to reach, making problems persistently unsolved without targeted guidance. "In practice, a non-trivial portion of this dataset remains consistently unsolved because it poses a hard exploration challenge."
- Induction: Task where the underlying function must be inferred from multiple input–output examples. "Induction:\quad & {(i_p,o_p)}_{p=1}{P} \;\Rightarrow\; \hat f"
- I/O axis: The difficulty-adjustment dimension that alters input–output instance or representation complexity while preserving the algorithmic motif. "(1) The I/O axis increases (or decreases) instance or representation complexity while aiming to preserve the same underlying algorithmic motif, e.g by changing the input schema (one list to multiple lists or nested lists) or by selecting examples that make the function harder to infer."
- Knowledge boundary: The frontier of what the current model can reliably solve; training aims to push this boundary outward. "Iterative training on generated lemma and lift questions expands the student's knowledge boundary, while the generated questions move closer to the goalpost ."
- Learnability: A difficulty metric maximizing training signal when tasks are neither too easy nor too hard. "Learnability is defined as with ."
- Lemma (lemma question): An easier stepping-stone instance derived from a goalpost that is still non-trivial and learnable for the student. "the teacher is prompted to generate an easier instance , which we refer to as the lemma, that aims to preserve the high-level motif of ."
- Lift (lift question): A harder variant generated from the lemma to incrementally approach the goalpost’s difficulty. "we refer to as the lift question."
- LiveCodeBench (LCB): A live, evolving coding benchmark used for evaluation. "Doing so, we improve pass@20 on LiveCodeBench (LCB) by 2.5\% over unguided asymmetric self-play"
- Meta-learning: Training a system to learn how to learn, often by optimizing over tasks to improve rapid adaptation. "\citet{sundaram2026_soar} propose SOAR, a meta-learning approach that targets hard exploration in RLVR"
- Mode collapse: A generative failure mode where outputs lack diversity, concentrating on few patterns. "This diversity filter prevents mode collapse and encourages the teacher to generate a broad set of distinct lemma/lift questions."
- pass@k: The probability (or fraction) that at least one of k independent samples solves a task; a common LLM coding metric. "We evaluate GASP\ and report pass@k on our LiveCodeBench evaluation split (LCB\textsuperscript{v5})."
- Regret (student regret): A teacher-side signal estimating how much better an optimal agent could perform compared to the current student, used to prioritize tasks. "prioritizes levels with high student regret, i.e a gap between the current agent and an optimal agent"
- Rejection sampling: A filtering step that discards invalid or overly similar generated tasks to maintain diversity and quality. "we perform a rejection sampling step in GASP to ensure that the generated lemma and lift proposals maintain sufficient diversity."
- Reinforcement Learning with Verifiable Rewards (RLVR): RL where rewards are derived from objective, checkable criteria (e.g., tests) rather than human labels. "In reinforcement learning with verifiable rewards (RLVR) in the coding domain, we start from a static dataset of programming problems."
- Task-Relative REINFORCE++: A policy-gradient variant used for updating the teacher based on relative task difficulty signals. "For RL updates, we use Task-Relative REINFORCE++ as proposed in Absolute Zero (AZR)"
- Unsupervised environment design: Automatically creating and scheduling tasks/environments without explicit labels to induce effective learning progress. "Unsupervised environment design and automated curricula."
Collections
Sign up for free to add this paper to one or more collections.