- The paper introduces a self-play reinforcement learning framework that enables data-free training of LLMs by alternating between Challenger and Solver roles.
- It employs KL regularization and self-reward mechanisms to stabilize training, achieving competitive results on benchmarks like AlpacaEval.
- Experimental results demonstrate that LSP boosts win rates (up to 43.1% post-RL calibration) on open-ended tasks, highlighting its potential for autonomous improvement.
Language Self-Play for Data-Free Training: A Technical Analysis
Introduction and Motivation
The paper "Language Self-Play For Data-Free Training" (2509.07414) introduces a reinforcement learning (RL) framework for LLMs that obviates the need for external training data. The approach leverages a game-theoretic self-play paradigm, wherein a single LLM alternates between two roles: Challenger (query generator) and Solver (response generator). This setup enables perpetual, autonomous training on self-generated, increasingly challenging data, addressing the data bottleneck that constrains post-training improvement in LLMs.
Figure 1: The Language Self-Play agent alternates between Challenger and Solver modes, enabling perpetual training on self-generated, increasingly challenging data.
Game-Theoretic Framework
The core innovation is the casting of LLM training as a competitive minimax game. The Challenger generates queries designed to minimize the Solver's reward, while the Solver seeks to maximize its reward by producing high-quality responses. Both roles are instantiated by a single model, πθ, using role-specific prompts. This eliminates the need for a separate adversarial model and leverages the shared token action space of LLMs for stable self-play.
RL Losses and Group-Relative Policy Optimization
The training loop proceeds as follows:
- Query Generation: The Challenger generates N queries.
- Response Generation: For each query, the Solver produces G responses.
- Reward Computation: Rewards are assigned to each response using either verification-based or preference-based metrics.
- Group Baseline: The average reward per query, V(qi), serves as a baseline for advantage calculation.
- Advantage Functions:
- Solver: A(qi,aij)=R(qi,aij)−V(qi)
- Challenger: A(qi)=V−V(qi), where V is the global average reward
- KL Regularization: KL-divergence to a reference model is included to prevent semantic drift and adversarial nonsense.
- Self-Reward Regularization: A self-reward RQ is computed by prompting the reference model to score the interaction, which is added to both players' rewards to stabilize training and maintain quality.
The combined loss is differentiated with respect to θ and used for gradient updates. The algorithm is summarized in the provided pseudocode.
LSP-Zero vs. LSP
- LSP-Zero: Pure zero-sum self-play without self-reward regularization.
- LSP: Augmented with self-reward, yielding a non-zero-sum game that empirically stabilizes training and improves quality.
Experimental Results
Experiments were conducted using Llama-3.2-3B-Instruct on the AlpacaEval benchmark. Models trained with LSP-Zero and LSP (no external data) were compared to a baseline RL model trained with Group-Relative Policy Optimization (GRPO) on Alpaca data.
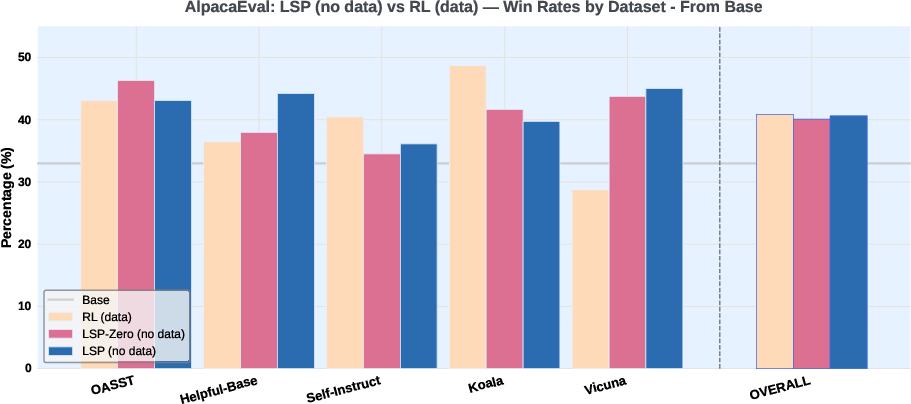
Figure 2: Win-rate comparison on AlpacaEval: LSP-Zero and LSP (no data) match or slightly outperform GRPO (data-based RL), all surpassing the base model.
- Overall Win Rates: GRPO 40.9%, LSP-Zero 40.1%, LSP 40.6%
- All methods outperform the base model (Llama-3.2-3B-Instruct).
- LSP and LSP-Zero excel on open-ended tasks (e.g., Vicuna), indicating the Challenger's ability to generate diverse, challenging prompts.
Self-Play as Post-RL Calibration
Further experiments initialized LSP-Zero and LSP from the GRPO-trained model, evaluating the effect of self-play as a post-RL calibration step.
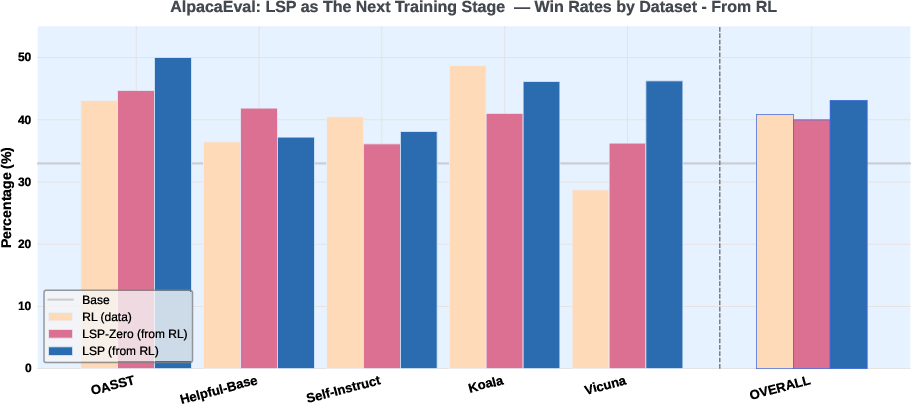
Figure 3: LSP post-RL calibration yields a significant win-rate increase (43.1%) over GRPO (40.9%), especially on conversational tasks.
- Win Rates: GRPO 40.9%, LSP-Zero 40.0%, LSP 43.1%
- LSP achieves a substantial improvement, particularly on Vicuna (from 28.7% to 46.3%).
- LSP-Zero can degrade performance in some cases, underscoring the necessity of self-reward regularization.
Implementation Considerations
Practical Deployment
- Model Requirements: Only a single LLM instance is required, with role-specific prompting for Challenger and Solver.
- Reward Model: Preference-based reward models (e.g., Skywork-Reward-V2-Llama-3.2-3B) are used for evaluation; verifiable rewards can be substituted for tasks with ground-truth.
- Computational Cost: The method is resource-efficient, as it does not require external data or adversarial models, but does require multiple rollouts per query for stable advantage estimation.
- Quality Control: KL regularization and self-rewarding are essential to prevent reward hacking and semantic drift.
Limitations
- Reward Model Dependency: The upper bound of LSP performance is constrained by the quality of the reward model.
- Query Diversity: The Challenger may bias towards structured queries, potentially limiting generalization to highly diverse user interactions.
- Degeneration Risks: Without self-reward regularization, self-play can devolve into adversarial or nonsensical behavior.
Theoretical and Practical Implications
The LSP framework demonstrates that LLMs can achieve competitive or superior performance to data-driven RL baselines through autonomous, data-free training. This has significant implications for scaling LLMs beyond the limits of human-generated data, enabling perpetual self-improvement. The approach is particularly promising for domains where reward functions are verifiable or can be reliably estimated.
Theoretically, the work extends self-play from strategic games to open-ended language tasks, leveraging the shared action space of LLMs for stable competitive learning. The integration of self-reward regularization aligns with recent trends in self-referential and meta-learning algorithms, suggesting a pathway toward fully autonomous, self-improving AI systems.
Future Directions
- Robust Query Generation: Enhancing the diversity and realism of Challenger-generated queries to better simulate real-world user interactions.
- Reward Model Improvement: Developing more robust and generalizable reward models to further raise the performance ceiling.
- Embodied AI: Extending LSP to embodied agents capable of collecting empirical data, potentially expanding the scope of AI knowledge acquisition.
- Multi-Agent Extensions: Investigating multi-agent self-play with heterogeneous models or roles for richer training dynamics.
Conclusion
Language Self-Play (LSP) provides a principled, practical framework for data-free LLM training, leveraging competitive self-play and self-reward regularization to achieve and surpass data-driven RL baselines. The method is resource-efficient, scalable, and adaptable to a wide range of tasks, with strong empirical results on instruction-following benchmarks. LSP represents a significant step toward autonomous, perpetual improvement in LLMs, with broad implications for the future of scalable AI systems.

