- The paper introduces EEAgent, a framework using reflective long and short-term memory for self-evolving robotic manipulation.
- It combines vision-language models with LLM-based policy planning, achieving a 92.2% success rate on complex VIMA-Bench tasks.
- Ablation studies show that enhanced perception via larger VLMs and SAM variants significantly boosts performance and interpretability.
Evolvable Embodied Agent for Robotic Manipulation via Long Short-Term Reflection and Optimization
Motivation and Framework
The pursuit of general-purpose robotic manipulation agents has intensified with the advent of foundation models, especially VLMs and LLMs. However, conventional paradigms relying on fixed action sets or reinforcement learning remain limited in adaptability, scalability, and interpretability. This paper introduces EEAgent, a framework explicitly designed to enable self-evolution in embodied robotic manipulation, inspired by the human cognitive process of reflecting upon past successes and failures. EEAgent operationalizes this paradigm by integrating both short-term and long-term memory within prompt engineering, enabling dynamic prompt optimization that substantially improves generalization and robustness in complex environments.
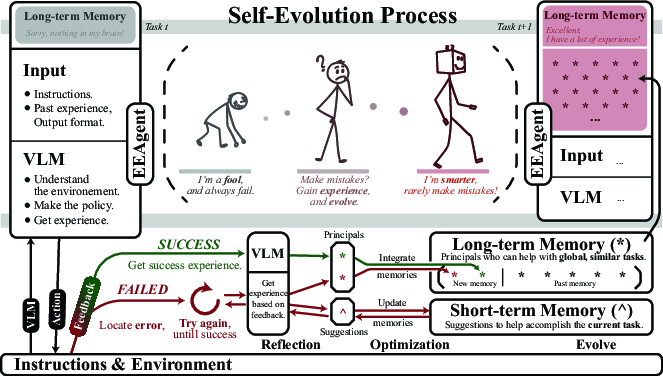
Figure 1: EEAgent motivation—emulating human learning through short-term and long-term memory, fostering self-evolution via experience-driven prompt refinement.
Architecture: Environment Interpreter and Policy Planner
EEAgent consists of two key modules: the environment interpreter and the policy planner. The environment interpreter leverages function-calling VLMs in combination with specialized tools—including the Segment Anything Model (SAM) for object segmentation—to extract and semantically interpret environmental entities. Multiple match functions (image_match, semantic_match, and scene_match) support diverse entity matching modalities (visual, text, and scene-based).
The policy planner, implemented as an LLM, synthesizes executable action sequences from environmental information and task instructions, constrained by a defined action library (PickPlace, PickRotate). Prompt composition and strategic use of environmental and instructional context enable precise planning in multimodal, visual-linguistic scenarios.
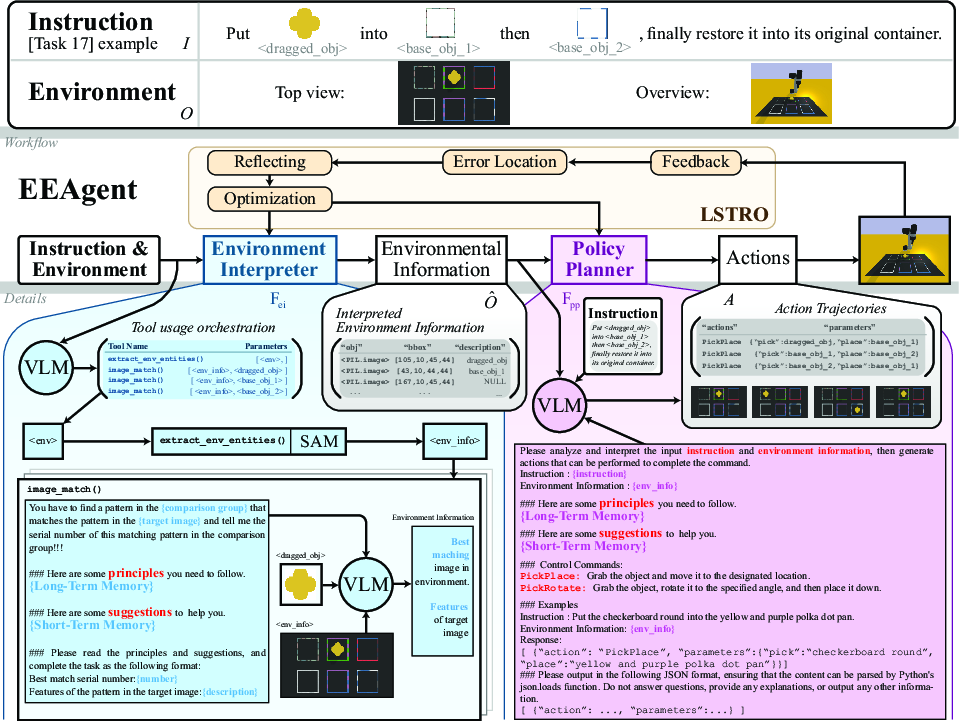
Figure 2: EEAgent architecture—environment interpreter (VLM + SAM) and policy planner (LLM) collaborating through memory-driven prompt updates.
Long Short-Term Reflection and Optimization (LSTRO) Mechanism
The LSTRO mechanism is the distinguishing contribution of this framework. It emulates hierarchical human memory by maintaining interpretable, dynamic long-term memory (global principles) and short-term memory (current task suggestions). Success and failure feedback drive reflective optimization: successful experiences enrich long-term memory, while failures invoke error-localized diagnostics (using image-description and action-instruction consistency checks) and iterative updating of both memory tiers. This reflective loop continuously refines the prompt, enhancing both environmental interpretation and policy planning.
A core aspect is the automated consolidation and contradiction resolution within memory, leveraging LLM evaluation for generality and semantic redundancy. This addresses the inherent risk of memory hallucination and redundancy in LLM-generated reflections, supporting scalable, interpretable self-evolution.

Figure 3: Illustration of learned long and short-term memory—showing interpretable, differentiated knowledge consolidation for robust task execution.
Empirical Evaluation and Numerical Results
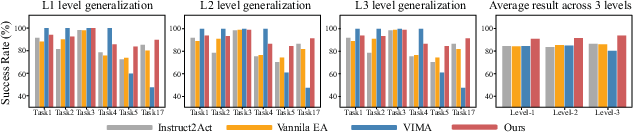
EEAgent was evaluated on six VIMA-Bench sub-tasks characterized by increasing complexity and visual-linguistic generalization requirements. Comparative experiments with LLM-planning-based (CaP, Instruct2Act, CLIN), learning-based (VIMA-20M, VIMA-Gato, Flamingo, GPT), and prompt-strategy baselines highlight several strong results:
Implications and Future Directions
EEAgent’s architecture and LSTRO mechanism present notable implications for both practical robotics and theoretical agent design:
- The integration of VLMs and LLMs through decoupled environment interpretation and policy planning, managed via a memory-driven reflective loop, enables high interpretability and generalization with minimal retraining.
- The tool-based approach circumvents the limitations of end-to-end code generation, facilitating real-time adaptation and error-localized self-improvement without incurring prohibitive computational or storage costs.
- The formalization of short- and long-term memory in prompt learning provides a scalable blueprint for future embodied systems, supporting lifelong learning, explainability, and rapid adaptation.
Potential future developments include extending EEAgent to open-ended real-world tasks, enhancing memory consolidation criteria (e.g., through reinforcement learning rewards), and integrating active retrieval mechanisms for selective memory formation. The framework’s robust handling of hallucination and consistency in memory updating may inform broader AI research in interpretability and continual learning.
Conclusion
The paper presents a technically rigorous framework for evolvable embodied agents in robotic manipulation by uniting large vision-LLMs with a formalized long short-term reflective optimization mechanism. EEAgent demonstrates state-of-the-art performance in multimodal task generalization, robust adaptation, and interpretable self-evolution, underscoring memory-driven prompt engineering as a viable pathway toward scalable, general-purpose robotics.