- The paper reveals that MAS architectures exhibit topological overfitting, leading to significant out-of-distribution performance degradation despite high in-domain accuracy.
- It introduces novel metrics, Role Alignment and Connection Significance, to quantitatively diagnose internal MAS coordination failures.
- The study highlights that correct final answers may mask underlying collaborative breakdowns, urging new evaluation protocols for robust MAS design.
Superficial Success vs. Internal Breakdown: A Critical Analysis of Generalization in Adaptive Multi-Agent Systems
Overview and Motivation
The study "Superficial Success vs. Internal Breakdown: An Empirical Study of Generalization in Adaptive Multi-Agent Systems" (2604.18951) presents an extensive empirical investigation into the true generalization capabilities of adaptive multi-agent systems (MAS) composed of LLM agents. While adaptive MAS architectures promise domain-agnostic collaborative intelligence by learning task-specific topologies—covering both agent roles and communication structures—the paper rigorously interrogates whether such systems can be considered genuinely general-purpose or if their performance is merely superficial when evaluated beyond their ID (in-domain) training distribution.
Adaptive MAS are formalized as frameworks (A,C), where A is the (potentially learned) set of LLM agents instantiated with designated role prompts and C is the induced inter-agent communication graph. Optimization is conducted over a labeled task-specific training set and a fixed underlying LLM backbone (e.g., GPT-oss-20B or Qwen3-30B-A3B), yielding an optimal topology via algorithms such as AFlow or AgentDropout. Notably, these algorithms represent bottom-up (constructive, incremental) and top-down (pruning-based) design philosophies, respectively.
Evaluation spans:
- ID accuracy (standard test split of the training domain),
- OOD performance (cross-domain transfer, holding topology fixed and varying only task/domain),
- Multi-domain learning (mixing data from all domains).
Experiments are conducted on six benchmarks (CaseHOLD, COM2, MuSiQue, SciBench, TheoremQA, and StrategyQA) covering a broad spectrum of reasoning types and task formats.
Topological Overfitting in Adaptive MAS
A primary empirical finding is pervasive topological overfitting: MAS architectures learned on a single domain are brittle under cross-domain transfer. OOD (out-of-distribution) performance frequently degrades substantially relative to ID accuracy, especially when transferring to domains with answer types or reasoning skills distinct from those of the source. For instance, a topology optimized for binary commonsense tasks generalizes poorly to multi-choice or numeric domains.
This phenomenon is visualized and quantified:
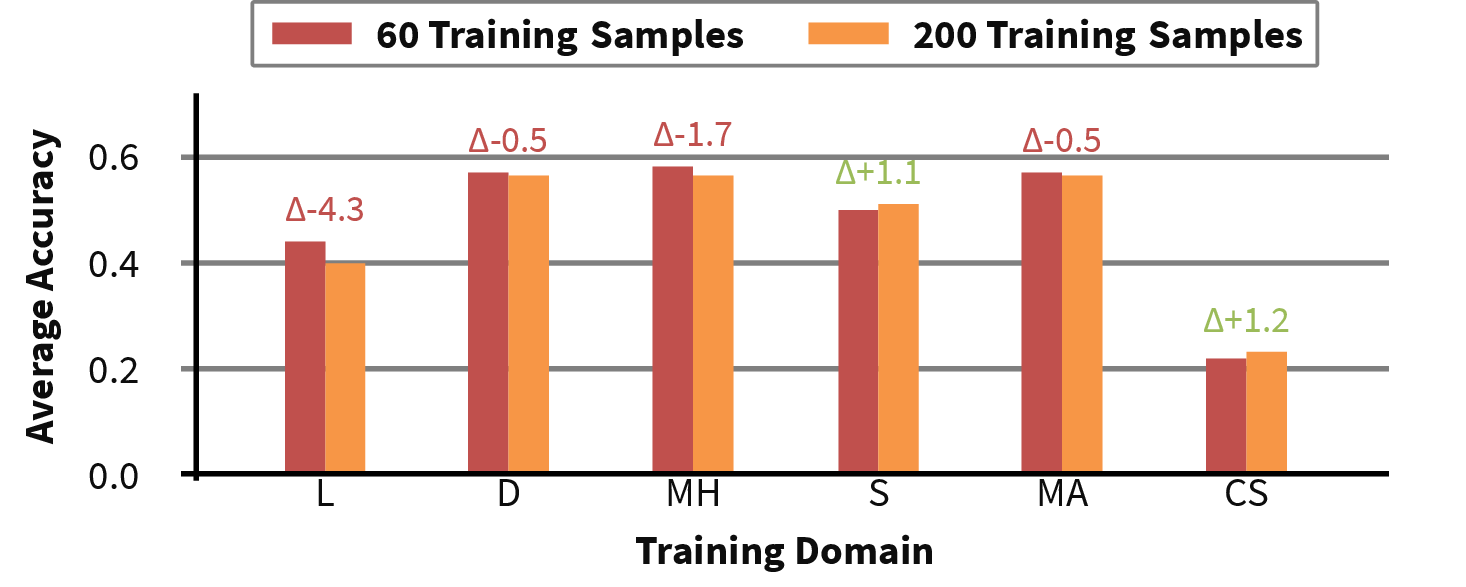
Figure 1: Generalization performance of AgentDropout as a function of training data, revealing that increasing in-domain examples only modestly affects, and sometimes worsens, cross-domain generalization.
Even multi-domain training, which somewhat alleviates overfitting, still lags behind optimally specialized architectures regarding ID accuracy, and its true collaborative merits remain ambiguous.
Illusory Coordination: Superficial Surface Success
A key insight is that high OOD accuracy does not necessarily imply robust MAS collaboration. In numerous cases, the correct final answer is achieved despite severe coordination breakdown among agents—termed "illusory coordination." This superficial success is due to individual LLM prowess rather than any effective agentic interaction, fundamentally contradicting the MAS paradigm.
A case in point:
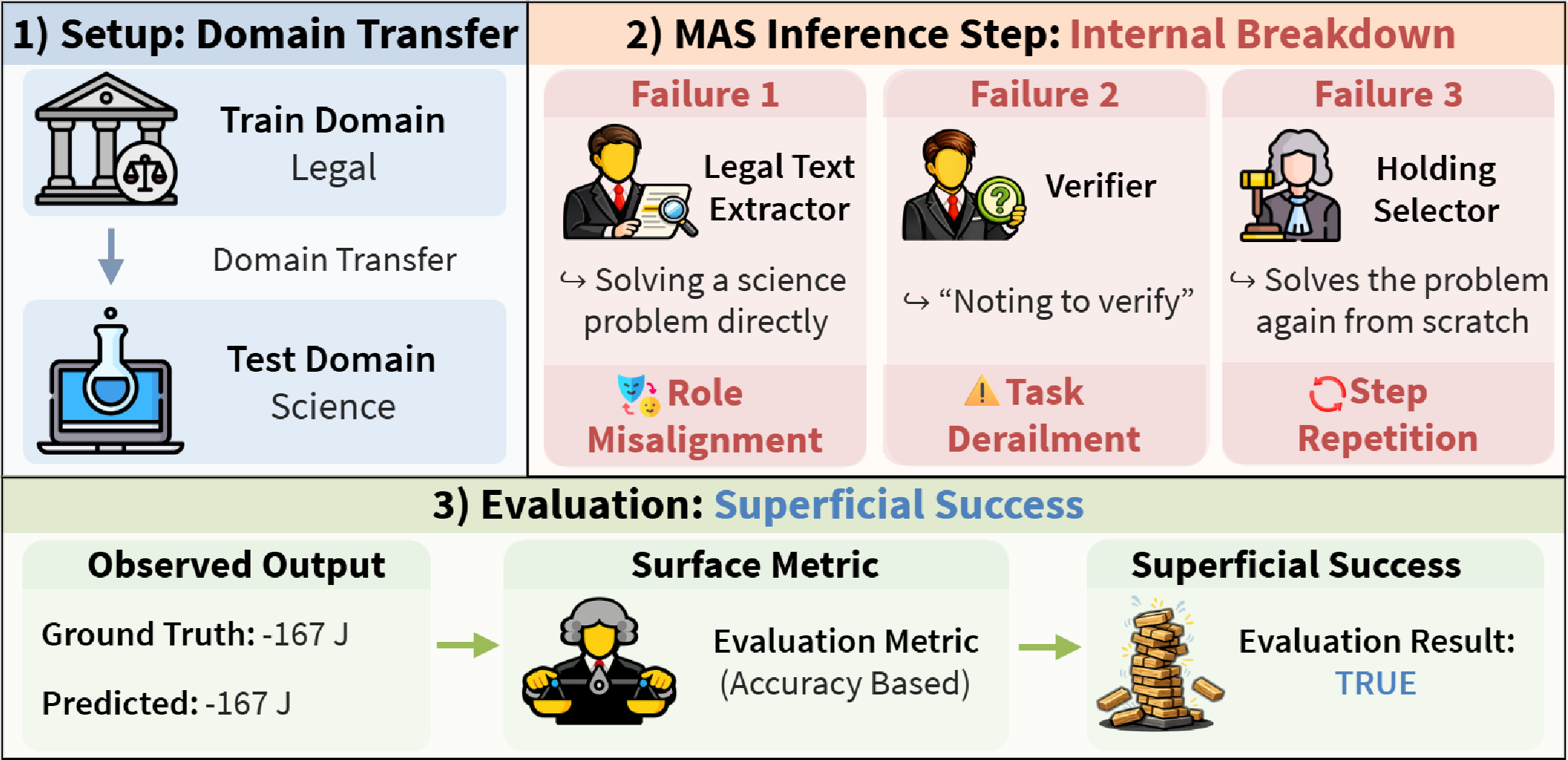
Figure 2: Illustration of illusory coordination: a legal-domain MAS applied to science tasks reaches the correct answer despite erroneous collaborative steps, due to the base LLM's strength.
Qualitative case studies and an error taxonomy (MAST) indicate that over half of the observed failures in MAS transfer derive from role-related or information-flow breakdowns.
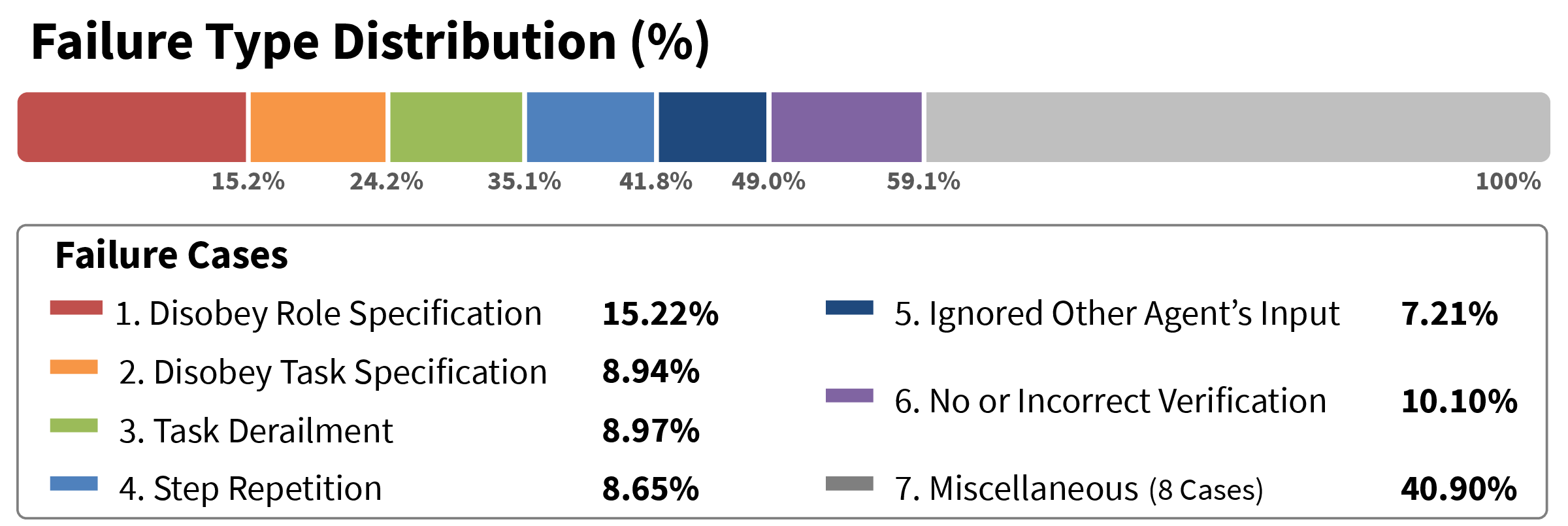
Figure 3: Distribution of failure types under domain transfer, showing dominance of role-related and connection-related failures.
Metrics for Diagnosing Internal MAS Failures
The authors introduce two structural metrics:
- Role Alignment (R): Quantifies the semantic consistency between an agent’s output and its assigned role, while penalizing homogenization among agent outputs. High R values imply that agents maintain role differentiation post-transfer.
- Connection Significance (O): Quantifies (using LLM-judged message usefulness and a softmaxed influence weight) the aggregate informativeness and effect of inter-agent communications beyond each agent’s own priors and task inputs.
High accuracy coupled with low R or non-positive O formally defines "illusory coordination." The authors' quantitative analysis demonstrates that ID to OOD transfer often results in sharp decreases in R and A0, even when accuracy remains stable.
Visualization of Structural Collapse
Trace-level analysis across domain transfers exhibits distinct internal pathologies: role nonadherence, agents ignoring others’ outputs, and format conflicts—often culminating in correct answers only by accident.
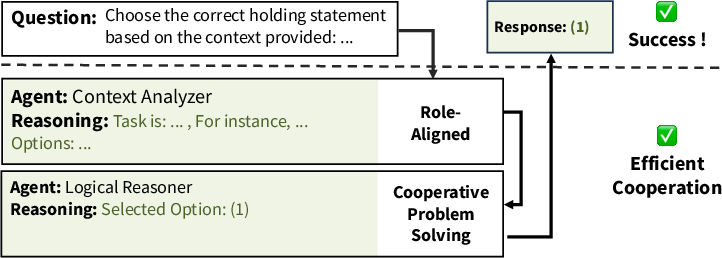
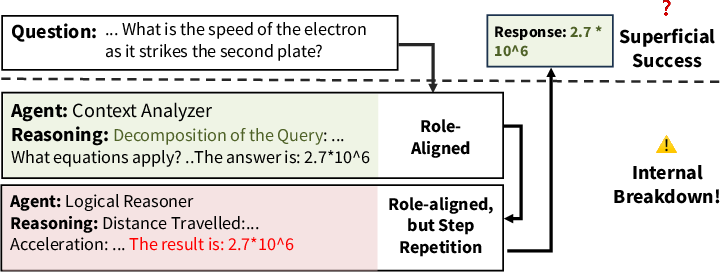
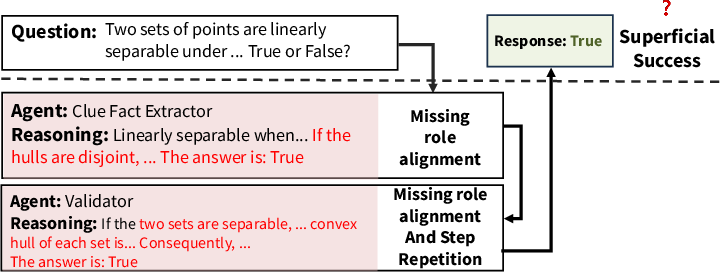
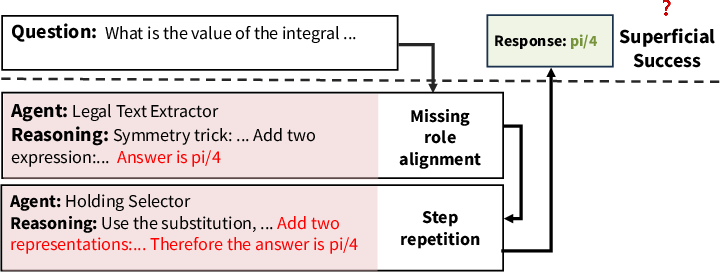
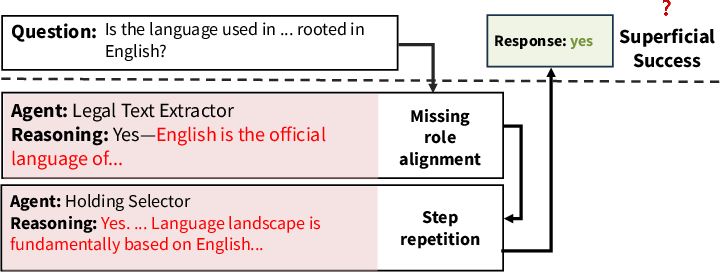
Figure 4: Collaboration trace, trained and tested on the legal domain—agents perform distinct, meaningful roles as expected.

Figure 5: Collaboration trace, topology trained on science domain, transferred to science tasks—correct coordination preserved.

Figure 6: Collaboration trace, topology trained on detective domain, transferred to math domain—internal structure collapses, with agents ignoring communication or misapplying task roles, despite correct output.
This empirically supports the dissociation between final correctness and true MAS structural integrity.
Ablations and Correlation Analyses
The role of topological components is dissected via targeted ablations:
- Swapping out connections (“Connection-OOD”) degrades performance less than swapping agent roles (“Role-OOD”), except on multi-hop reasoning (MuSiQue), where communication topology is particularly vital.
- Pearson correlations of accuracy with A1 and A2 are close to zero, validating the structural metrics’ necessity for MAS evaluation.
Implications and Future Directions
These findings have both practical and theoretical ramifications:
- Evaluation: Reliance on final-answer correctness is insufficient for MAS benchmarks. Structural diagnostics using internal metrics are indispensable for assessing genuine collaborative capacity.
- MAS Design: Architectures optimized for single domains are unlikely to generalize, absent explicit constraints or mechanisms enforcing role and communication robustness.
- Multi-Domain and Few-Shot Approaches: While multi-domain training offers moderate gains, further research is required to relax topological overfitting and enable the persistence of agentic properties under distribution shift.
- Theory: The phenomena documented parallel overfitting and shortcut learning in deep networks but highlight unique challenges in distributed decision-making with LLMs.
Conclusion
This work rigorously demonstrates that current adaptive MAS architectures often overfit topologically and achieve "superficial" generalization only via the underlying LLMs’ individual power rather than collaborative intelligence. Internal MAS analysis using fine-grained metrics such as role alignment and connection significance uncovers widespread coordination breakdowns, thereby calling for new evaluation protocols and topological regularization techniques to realize the full promise of domain-agnostic agentic systems. The authors' methodology and insights set a clear agenda for next-generation MAS research.