LLM-Enabled Multi-Agent Systems: Empirical Evaluation and Insights into Emerging Design Patterns & Paradigms
Abstract: This paper formalises the literature on emerging design patterns and paradigms for LLM-enabled multi-agent systems (MAS), evaluating their practical utility across various domains. We define key architectural components, including agent orchestration, communication mechanisms, and control-flow strategies, and demonstrate how these enable rapid development of modular, domain-adaptive solutions. Three real-world case studies are tested in controlled, containerised pilots in telecommunications security, national heritage asset management, and utilities customer service automation. Initial empirical results show that, for these case studies, prototypes were delivered within two weeks and pilot-ready solutions within one month, suggesting reduced development overhead compared to conventional approaches and improved user accessibility. However, findings also reinforce limitations documented in the literature, including variability in LLM behaviour that leads to challenges in transitioning from prototype to production maturity. We conclude by outlining critical research directions for improving reliability, scalability, and governance in MAS architectures and the further work needed to mature MAS design patterns to mitigate the inherent challenges.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about building “teams” of AI helpers, called multi-agent systems (MAS), that are powered by LLMs like the brains behind ChatGPT. The authors explain common design patterns (repeatable ways to build these AI teams), test them in three real-world examples, and share what worked, what didn’t, and why this approach could be useful across different industries.
Key Questions the Paper Tries to Answer
- How should we design and organise AI “agents” (specialised helpers) so they can work together well?
- Can LLM-powered agent teams be built quickly and used in real organisations?
- Where are they most helpful, and what problems do they still have?
- What should researchers and engineers improve next to make these systems reliable and safe?
Methods and Approach
Think of the system like a group project:
- Each agent is a “specialist student” with a brain (the LLM), a toolbox (like web search, databases, or code), and memory (notes from past steps).
- A “coordinator” helps decide who does what and when, like a team leader or a conductor.
What the authors did:
- They reviewed recent academic papers, open-source tools, and industry platforms (like LangChain, AutoGen, and MCP) to understand how people are currently building MAS.
- They described a simple, reusable way to build MAS:
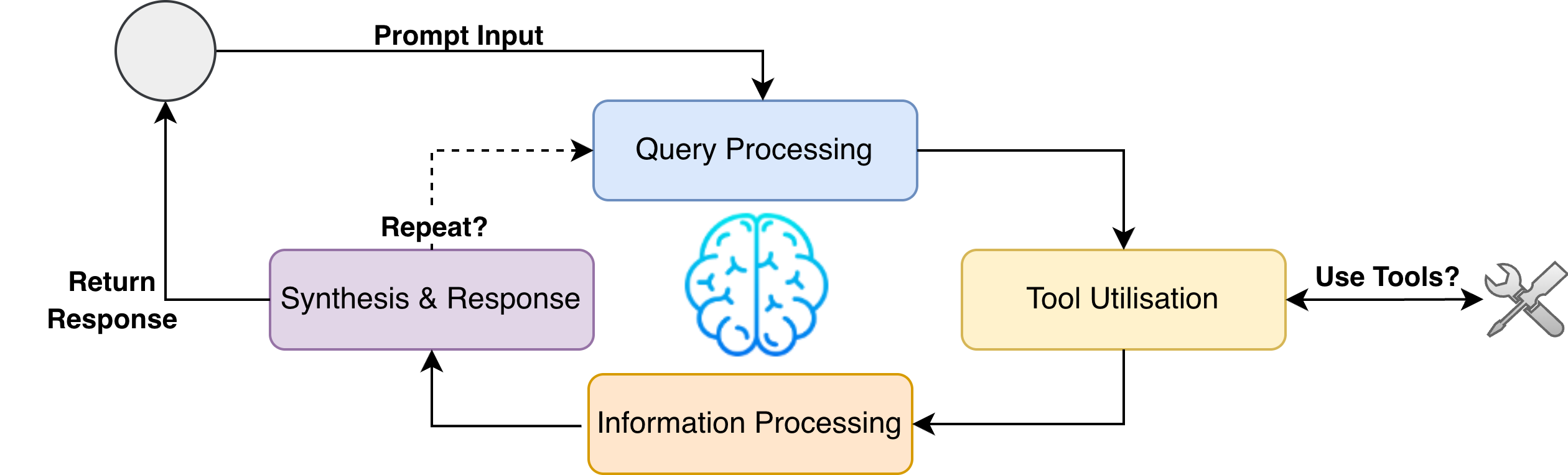
- Agents “think step by step” (called Chain-of-Thought), just like showing your working in math.
- Agents can “look things up” in external data when they need facts (called Retrieval-Augmented Generation, or RAG).
- Agents can pass tasks to each other (“handoff”) and share history when needed, like sharing notes in a group.
- Control can be fixed (a set plan) or dynamic (agents decide the next step based on the situation).
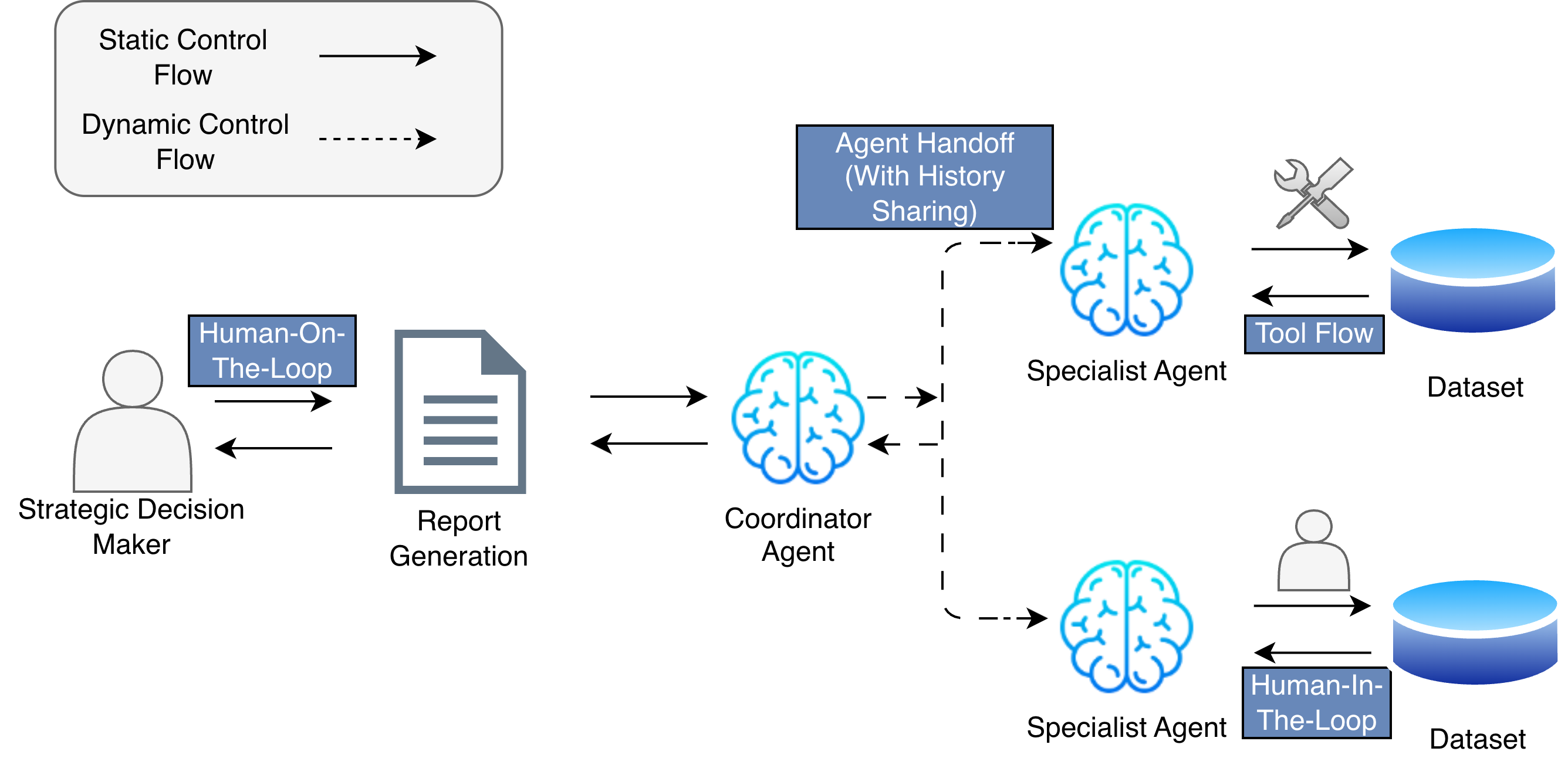
- They built three pilot systems in safe, controlled environments (like putting the system inside a sealed, portable box called a container) and tested them with real users:
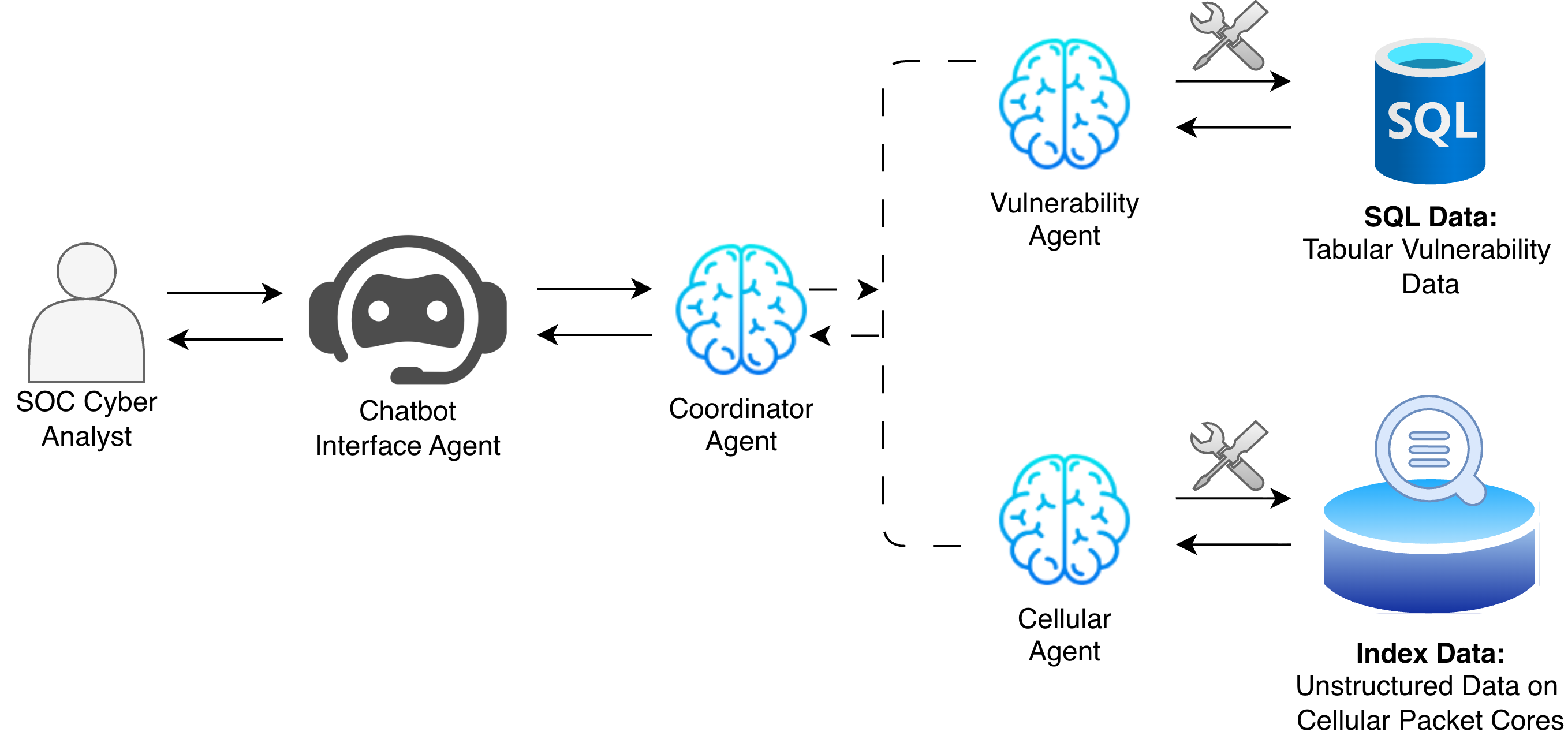
- Telecom security: helping analysts find and connect threat information.
- National asset management: helping staff look up inventory across messy, inconsistent data.
- Utilities customer service: drafting helpful first-time response emails with human review.
Main Findings
Here are the key results, explained simply:
Fast to build:
- Prototypes were ready in about 2 weeks.
- Pilot-ready systems in about a month.
- In one case, an LLM agent produced first results in under 1 hour, compared to about 4.5 hours for a traditional approach.
- Useful in practice:
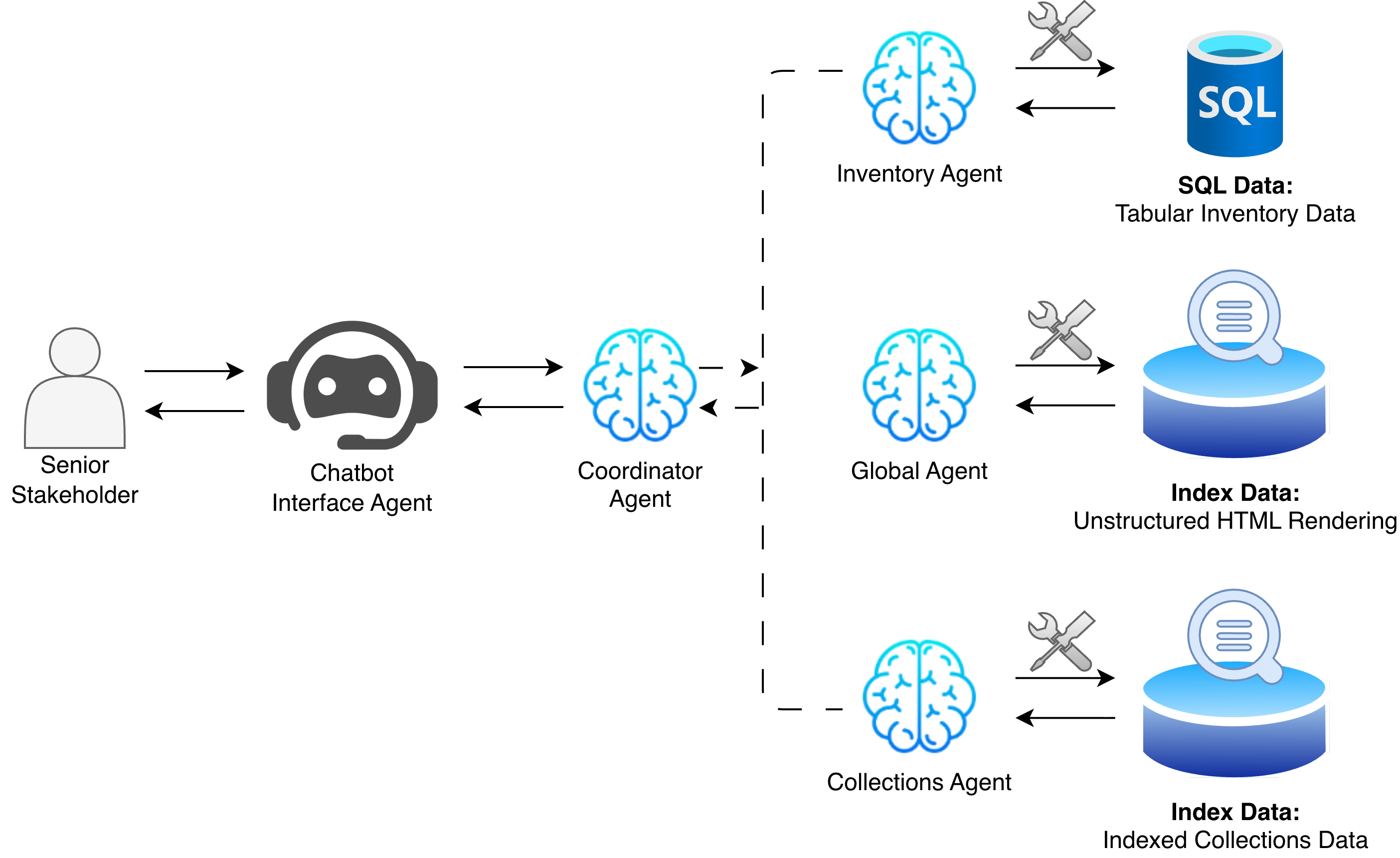
- Telecom security: Analysts liked a chatbot that could pull together both structured data (like tables) and unstructured text (like reports), making their job easier.
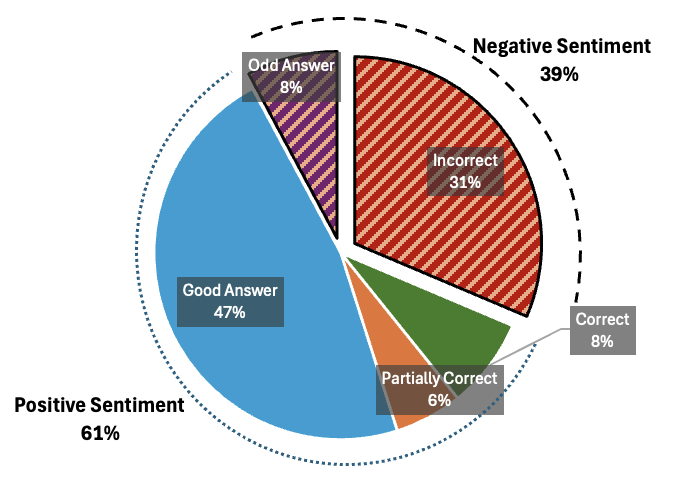
- National asset register: Staff could query inconsistent, messy data through a simple chat interface; feedback was about 61% positive, with clear suggestions for improvement.
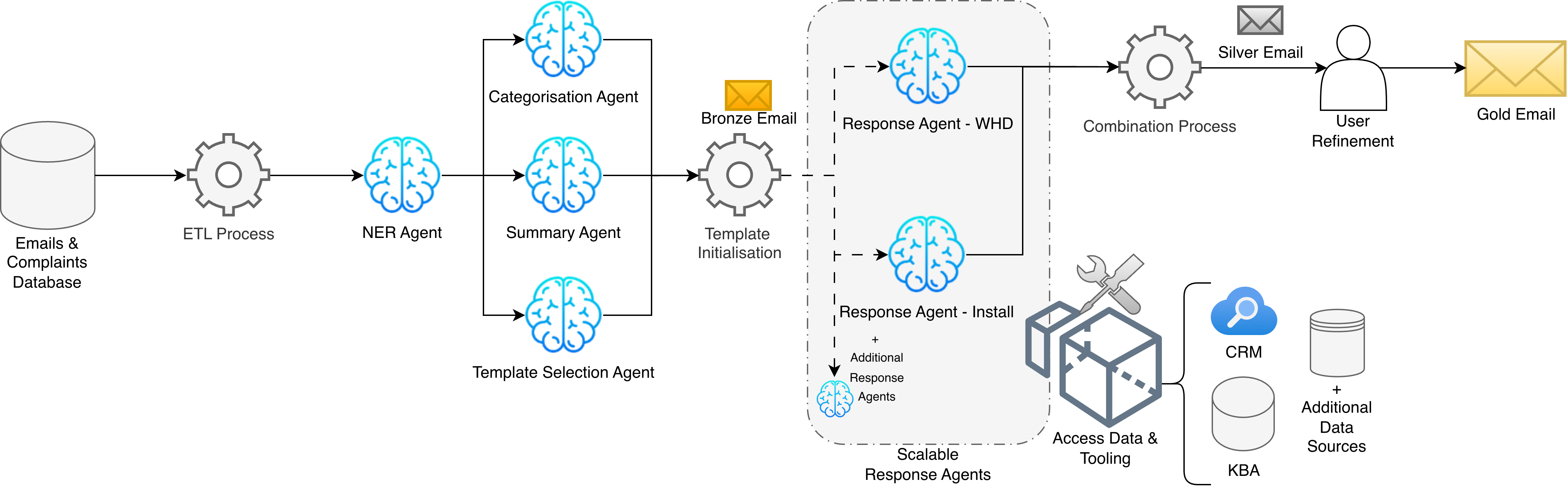
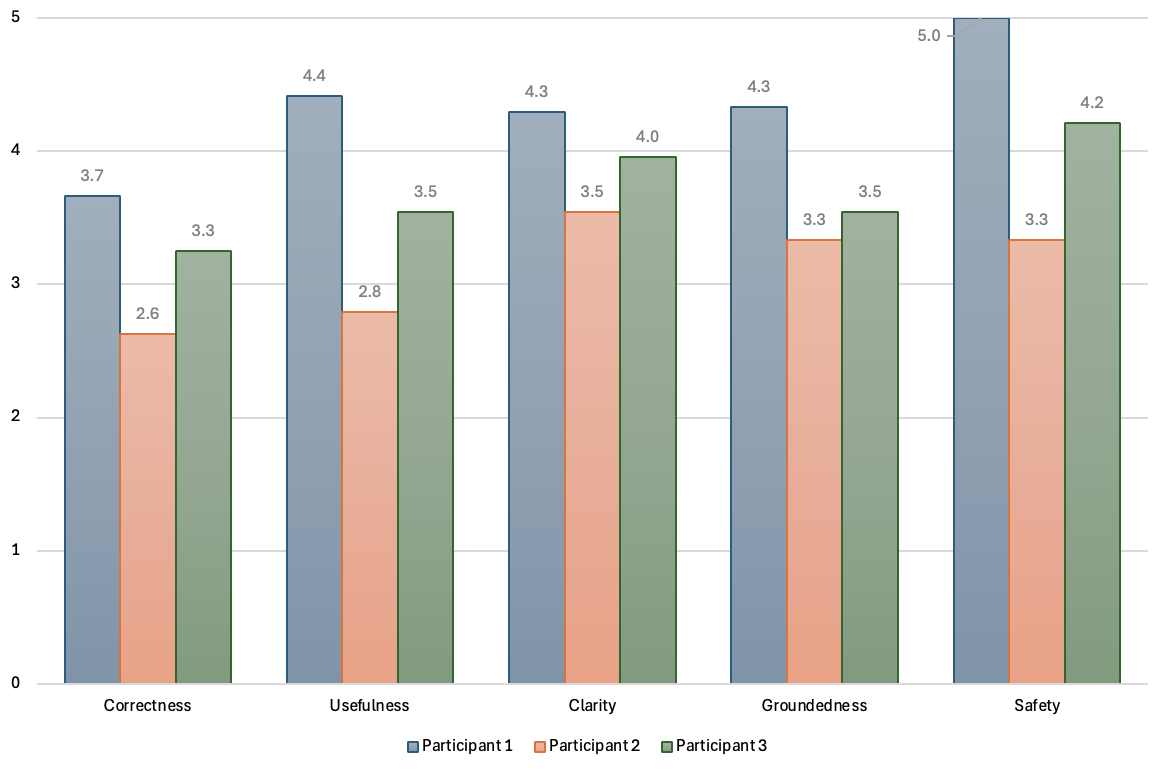
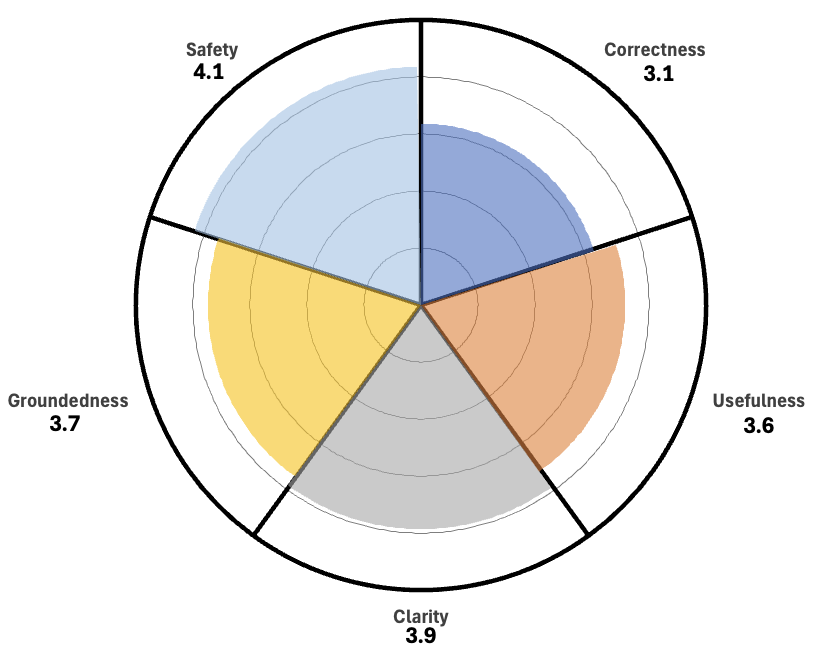
- Utilities customer service: The system drafted about 5 emails per minute at roughly £0.05 each, compared to 3 per minute manually at roughly £0.33 each. Email categorisation was 100% accurate in the test, and response quality scored around 3–4 out of 5 for clarity and safety.
- Limits and challenges:
- LLMs can be unpredictable. Sometimes they vary in how they answer, which makes moving from a demo to a reliable, production system tricky.
- Coordinating many agents can get complex. If one agent makes a mistake, it can spread through the system.
- Human oversight is still necessary. People need to review and approve important steps, especially in sensitive tasks.
Why These Results Matter
- Speed and flexibility: MAS let organisations build useful AI systems fast and adapt them to different domains (security, national assets, customer service) without starting from scratch every time.
- Better access to data: Agents can bridge messy, scattered databases and documents, giving users a single place to ask questions and get answers.
- Cost and efficiency: In some cases, these systems can do more work at lower cost, like writing first draft emails faster and cheaper.
- Practical reality check: The paper confirms known limits—LLMs sometimes behave inconsistently, and agent teams need careful design, testing, and governance to be trustworthy.
Implications and Future Impact
- Short term: MAS can help organisations handle complex data and routine tasks more quickly, especially with a simple chat interface and human checkpoints.
- Medium term: We need stronger patterns and tools to make these systems reliable, scalable, and safe:
- Reliability: Reduce variability and errors, and make reasoning traceable.
- Scalability: Keep coordination smooth even as the number of agents grows.
- Governance and ethics: Ensure accountability, avoid bias, protect privacy, and follow regulations.
- Big picture: If improved, LLM-enabled MAS could become a standard way to build smart, modular AI systems that fit many industries—like having a reusable “team template” you customise for your own needs.
In short, building teams of specialised AI agents powered by LLMs is promising, practical, and fast—but to use them widely and safely, we need better guardrails, clearer design patterns, and ongoing human oversight.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what the paper leaves missing, uncertain, or unexplored, framed to be concrete and actionable for future research.
- Lack of rigorous, quantitative evaluation across case studies: stakeholder feedback and small-sample UAT dominate; no statistical tests, baselines, or error analyses published beyond CS3.
- Generalizability remains untested: pilots are narrow and short; no cross-domain or cross-organisation replication demonstrating transferability of reported benefits.
- No longitudinal production evidence: reliability, failure rates, output drift, maintenance burden, and cost stability under real-world workloads over months are unmeasured.
- Absent lifecycle cost model: cost per-email is reported, but total cost of ownership (engineering, data prep, monitoring, retraining, compliance, incident response) is not quantified.
- Safety and alignment controls are limited: no formal guarantees, red-team assessment, adversarial testing, or measurable safety baselines for MAS tool use or content generation.
- Error propagation in MAS is acknowledged but not characterized: no experiments quantifying cascade frequency/severity or mitigation efficacy (e.g., arbitration, rollback, redundancy).
- Control-flow strategy selection is empirical and unformalized: when to prefer explicit, dynamic, hierarchical, swarm, or supervisor architectures remains an open design question.
- Dynamic routing by LLM “coordinators” lacks reliability guarantees: no metrics on misrouting rates, routing latency/cost overheads, or fallback heuristics under uncertainty.
- Tool overloading threshold (8–12 tools) is asserted without controlled evidence: need task–model–tool interaction studies to validate and refine this constraint.
- Memory policies are underdefined: how to manage short/long-term memory across agents, minimize leakage, prevent prompt injection via shared histories, and ensure privacy is unresolved.
- History-sharing trade-offs are unquantified: full reasoning vs final results—impacts on performance, interpretability, privacy, and attack surface need empirical study.
- RAG quality and grounding metrics are minimal: hallucination rates, citation fidelity, source attribution, and retrieval effectiveness across heterogeneous datasets are not measured.
- Schema harmonization claims lack method and evaluation: accuracy of automated schema mapping/translation, conflict resolution, and ontology alignment is untested.
- Data governance and compliance pathways are unspecified: GDPR/NIS2/sector-specific obligations for PII, retention, residency, auditability, and explainability are not operationalized.
- Security posture is underexplored: prompt-injection defenses, OSINT poisoning resilience, sandboxing for tool execution (e.g., Python), secrets management, and MCP surface hardening are untested.
- Observability and monitoring are not formalized: required telemetry, tracing, incident handling, SLAs/SLOs, and debugging practices for MAS are unspecified.
- Benchmarking is absent: no standardized, reproducible MAS benchmarks, datasets, or metrics (e.g., beyond Boss of the SOC) are proposed or used for comparative evaluation.
- Interoperability and portability across vendors/frameworks are untested: MCP adoption, cross-cloud agent orchestration, latency, and failure modes when mixing stacks need validation.
- Scalability limits are unknown: performance, cost, and reliability impacts as agent counts grow; load balancing, sharding, and fault tolerance for large MAS networks are not evaluated.
- Agent decomposition strategy is ad hoc: criteria and methods to determine agent granularity, specialization, and capability partitioning remain unformalized.
- Automatic agent synthesis and adaptation are missing: no methods for learning specializations, continual learning from feedback, or on-the-fly agent reconfiguration.
- Human-in-the-loop design is not optimized: where to place checkpoints, measure cognitive load, quantify review time, and calibrate trust/authority remains open.
- Compliance-aware templating is only superficially evaluated: formal checks for policy conformity, legal language constraints, and risk thresholds in customer communications are absent.
- Comparative baselining vs classical pipelines is limited: rigorous task-level comparisons (accuracy, latency, maintainability) and conditions where MAS underperforms are not documented.
- Sustainability impacts are unmeasured: energy/carbon costs of LLM-driven MAS, benefits of distillation/compression, and eco-efficiency trade-offs require study.
- Formalism of design patterns is descriptive only: no mathematical models, performance bounds, or verification of orchestration graphs/DSL semantics (e.g., LCEL/LangGraph).
- Provenance and auditability are incomplete: standardized traceability of outputs to sources, cryptographic attestations, and evidentiary chains for regulated domains are not implemented.
- Fairness and bias assessments are missing: distributional harm analysis, demographic parity metrics, and mitigation strategies for customer-facing outputs are not conducted.
- Failure handling and graceful degradation are unspecified: fallback behavior under model outages, tool errors, or routing failures, and human takeover protocols are not defined.
- Risk management in SOC use is limited: systematic evaluation of threat taxonomy bias, prioritization accuracy, and potential misguidance harms is absent.
- SIE (Single Information Environment) is not formally defined: semantics, isolation boundaries, multi-tenancy concerns, and governance models for data-centric MAS need specification.
- Documentation and reproducibility are partial: code/data availability is limited (CS3 link only), environment specifications, model versions, and configuration details are not fully disclosed.
Glossary
- A/B testing: A comparative experimental method for evaluating two variants to determine which performs better under defined metrics. "Future work that prioritises expanded trials is needed, with rigorous A/B testing against manual baselines"
- Agent orchestration: The coordination layer that manages interactions between an LLM and its tools within an agent’s workflow. "Agent orchestration: The overarching system that manages interactions between the LLM and its tools."
- Agentic AI Foundation: A nonprofit stewarding agentic AI standards and interoperability, funded by the Linux Foundation. "And since handed over to the Agentic AI Foundation, directly funded by the Linux Foundation"
- AutoGen: A Microsoft framework for building and coordinating LLM-powered multi-agent systems. "Microsoftâs AutoGen"
- Azure AI Foundry: Microsoft’s beta tooling environment for developing Agentic AI solutions. "Azure AI Foundry"
- Bedrock Agents: An Amazon service for building, integrating, and deploying AI agents. "Amazonâs Bedrock Agents"
- Boss of the SOC dataset: A benchmark dataset used for evaluating security operations center workflows and tools. "Boss of the SOC dataset"
- Chain-of-Thought (CoT) prompting: A prompting technique that elicits step-by-step reasoning before final answers to improve performance on complex tasks. "Chain-of-Thought (CoT) prompting"
- Cognitive interference: Performance degradation in LLM agents due to competing tasks or overloaded context. "context-window overload and cognitive interference"
- Coordinator Agent: An agent responsible for delegating tasks to specialised agents based on query requirements. "The Coordinator Agent delegates tasks to two specialised agents"
- Copilot: Microsoft’s AI assistant product integrated into productivity tools and developer workflows. "Copilot"
- Context-window overload: When inputs exceed an LLM’s effective context capacity, causing reduced performance. "context-window overload"
- Control-flow strategies: Policies determine the sequencing and routing of interactions among agents. "control-flow strategies"
- CRM (Customer Relationship Management): Systems for managing customer data, interactions, and service processes. "Customer Relationship Management (CRM) system"
- Decentralised Internet of AI Agents: A distributed architecture in which vast numbers of AI agents collaborate across networks. "a decentralised Internet of AI Agents framework"
- Distillation: The process of compressing models or agents into smaller, efficient versions optimised for specific tasks. "agents can be distilled into smaller, more efficient versions"
- Error propagation: The cascading effect where an individual agent’s error spreads through the multi-agent system. "error propagation where an agent's incorrect reasoning can cascade through a system"
- Governance: Structures and policies for responsible operation, oversight, and compliance in MAS deployments. "improving reliability, scalability, and governance in MAS architectures"
- Handoff: Passing a prompt or task from one agent to another in a multi-agent workflow. "Handoff: Passes prompt to a new agent."
- Hierarchical: A multi-tier agent network with layered supervisory control for scalability and structured coordination. "Hierarchical: A layered architecture that organises agents under multiple supervisory tiers for scalability and structured control."
- Human-in-the-loop: A design pattern where humans intervene to review, approve, or correct system actions. "Human-in-the-loop: Approve/reject, review tool calls, interrupts."
- Human-on-the-loop: A supervision model where humans oversee the system without constant intervention. "human-on-the-loop oversight"
- Interoperability: The ability of agents and tools to work together across heterogeneous platforms and standards. "the challenge of interoperability becomes more pronounced."
- KBA (Knowledge Base Articles): Canonical articles and documentation used to ground automated responses and workflows. "Knowledge Base Articles (KBA)"
- LangChain Expression language: A domain-specific language for composing chains of LLM agents and tools. "This includes the LangChain Expression language, a domain-specific language that is parsed by the LangChain framework to arrange "chains" of agents"
- LangGraph: A framework extending LangChain to support branching, graph-based multi-agent workflows. "The LangChain expression language is extended by the LangGraph project to manage and arrange branching networks of multiple agents for MAS development."
- Lexicon-Based Matching: A rule-based sentiment analysis method that maps text to sentiment lexicons. "Sentiment analysis using Lexicon-Based Matching"
- Likert-scale: A psychometric rating scale used to measure subjective assessments across ordered levels. "five Likertâscale dimensions"
- MCP (Model Context Protocol): An open standard that connects LLMs to external tools, data sources, and services. "the Model Context Protocol (MCP), an open standard designed to enable LLMs to connect and interact seamlessly with external tools, data sources, and services"
- Microsoft Fabric: A Microsoft data and analytics ecosystem used for hosting and monitoring solutions. "hosted within the Microsoft Fabric ecosystem"
- NANDA: An MIT initiative proposing infrastructure for a large-scale, decentralised network of AI agents. "MITâs NANDA project"
- Ontologies: Formal representations of domain concepts and their relationships used for structured reasoning. "domain-relevant knowledge, ontologies, and reasoning capabilities"
- OSINT (Open-Source Intelligence): Publicly available information used for threat intelligence and analysis. "open-source intelligence (OSINT) must be gathered, filtered and analysed."
- Prompt engineering: Techniques for crafting inputs to guide LLMs toward desired behaviours and outputs. "Beyond prompt engineering and multi-agent invocation, tool integration has emerged as a critical technique"
- RAG (Retrieval-Augmented Generation): A method in which models retrieve external documents to ground and improve generated outputs. "Retrieval-Augmented Generation (RAG)"
- ReAct agent: An agent pattern that interleaves reasoning and actions in iterative loops to solve tasks. "the definition of the ReAct agent"
- Regex: Pattern-based text matching used for classification or extraction in baseline systems. "regularâexpression (regex) categorisation baseline"
- Semantic reasoning: Inference over meaning and relationships in text to extract structured understanding. "advanced NLP and semantic reasoning techniques"
- Semantic similarity: A measure of meaning-based closeness between texts or embeddings used to find relevant context. "retrieved using semantic similarity"
- Sentiment analysis: Methods for detecting opinions or affective states in text. "Sentiment analysis using Lexicon-Based Matching"
- SIE (Single Information Environment): A data-centric MAS configuration unifying access across structured and unstructured sources. "creating an integrated Single Information Environment (SIE)"
- Stochastic nature: The inherent randomness in LLM outputs that can impact reliability and consistency. "the stochastic nature of using LLM's"
- Supervisor agent: An agent coordinating specialised leaf agents to manage workflow execution. "Supervisor: Leaf node agents coordinated by supervisor agents."
- Swarm: A decentralised, non-hierarchical agent network where peers dynamically hand off tasks. "Swarm: A decentralised structure without any hierarchy where agents dynamically hand off tasks to each other based on specialisation."
- Tool flow: A pattern where leaf agents call tools while intermediate nodes handle handoffs and routing. "Tool Flow: Leaf nodes call tools; intermediate nodes manage handoffs."
- Transformer: A deep learning architecture leveraging attention mechanisms, foundational for modern LLMs. "transformer deep learning architecture"
- Tree-of-Thought (ToT): A reasoning approach that explores branching paths to improve performance on complex tasks. "Tree-of-Thought (ToT) introduces branching reasoning paths"
- UAT (User Acceptance Test): End-user evaluation to validate system readiness and usability. "A pilot User Acceptance Test (UAT) involved three participants"
- Vector database: A storage system for high-dimensional embeddings enabling efficient similarity search. "long-term memory is stored externally (e.g., in a vector database)"
- Vector similarity searches: Queries comparing embeddings to retrieve contextually related items. "performs vector similarity searches to extract contextual threat intelligence"
Practical Applications
Below is an overview of practical, real-world applications derived from the paper’s findings, methods, and innovations. Each item notes sectors, potential tools/products/workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
- SOC Analyst Copilot for Threat Intelligence — cybersecurity — Tools/products/workflows: SIE-style MAS with a coordinator agent; specialised agents for CVE/CVSS retrieval (SQL) and OSINT correlation (vector search/RAG); analyst-facing conversational interface; on-prem Docker deployment; LangChain/LangGraph or AutoGen; MCP-based tool connectors; audit logging. — Expected impact: Faster cross-correlation of heterogeneous feeds; reduced analyst workload; improved query navigation. — Assumptions/dependencies: Secure access to vulnerability databases and OSINT feeds; enterprise security policies and RBAC; LLM reliability and cost; stakeholder (CISO) buy-in; robust audit trails.
- Cross-Site Asset Query and Sanitation Assistant — public sector/national heritage, facilities, logistics — Tools/products/workflows: SIE MAS that routes queries to site-specific retrieval agents; RAG over fragmented structured/unstructured datasets; natural language chatbot for non-technical users; Azure cloud deployment using native agent services. — Expected impact: Unified access to siloed asset inventories without immediate schema standardisation; faster data findability. — Assumptions/dependencies: Read access to all site datasets; data privacy/governance compliance; high-quality indexing and embeddings; ongoing feedback cycles to reduce output variability.
- Customer Service First-Time Response (FTR) Autoresponder — utilities, telecom, retail — Tools/products/workflows: Hierarchical MAS pipeline for email triage, KBA/CRM retrieval, template-aligned drafting; human-in-the-loop refinement; Azure agents + Microsoft Fabric + Power BI monitoring; MCP connectors to CRM. — Expected impact: ~5 FTR emails/min at ~£0.05/email vs ~3/min at ~£0.33/email; improved throughput and consistency; accelerated development vs regex baselines. — Assumptions/dependencies: Accurate CRM records and up-to-date KBAs; template coverage for common intents; UAT processes; safety/groundedness guardrails; clear escalation paths for edge cases.
- Enterprise Single Information Environment (SIE) for Disparate and Unstructured Data — finance, government, energy, healthcare — Tools/products/workflows: Coordinator agent + dataset-specialist retrieval agents; RAG pipelines; vector databases; MCP for tool/data interoperability; governance dashboards for human-on-the-loop oversight. — Expected impact: Unified query layer across silos; faster decision support; lower integration overhead vs bespoke pipelines. — Assumptions/dependencies: Data access agreements and governance; privacy/security controls (encryption, masking); observability (logs, traces); cost management for LLM usage.
- MAS Prototyping Kits and Design Pattern Templates — software/IT — Tools/products/workflows: Template repositories for common orchestration graphs (supervisor/hierarchical/SIE); LangChain/LCEL/LangGraph; AutoGen; Bedrock Agents; Azure AI Foundry; CI/CD for agent tests; “agent handoff” scaffolding. — Expected impact: Sub-hour “first outputs” for new agent roles; faster iterations; reusable orchestration components. — Assumptions/dependencies: Developer familiarity with frameworks; stable vendor APIs; internal DevOps support; test data availability.
- AgentOps Monitoring, Governance, and Oversight Dashboards — operations/compliance — Tools/products/workflows: Power BI/Observability stack for agent telemetry; audit log capture of handoffs, tool calls, reasoning traces; human-on-the-loop workflows for approvals and interventions. — Expected impact: Improved accountability and trust; quicker incident triage; policy-compliant operations. — Assumptions/dependencies: Instrumentation at agent/orchestrator layers; clear governance policies; role-based access to dashboards.
- Academic Teaching/Lab Assistants for Requirements Capture and Code Generation — academia/software engineering education — Tools/products/workflows: MAS that assigns domain-expert roles (requirements analyst, reviewer, coder); human-in-the-loop grading and critique; integration with course repositories. — Expected impact: Scaffolds practice-based learning; supports iterative requirements elicitation and validation. — Assumptions/dependencies: Course-specific datasets; clear academic integrity policies; compute quotas.
- Policy “AI Agent Sandbox” Pilots — public administration/regulation — Tools/products/workflows: Containerized MAS deployments with strict audit trails; predefined agent roles; oversight committees; red-teaming and safety evaluation protocols. — Expected impact: Evidence-based policy formation; controlled exploration of agent benefits/risks; faster regulatory learning cycles. — Assumptions/dependencies: Legal authority for pilots; ethics reviews; risk registers; stakeholder transparency.
- Personal Multi-Agent Workflow Assistant — daily life/productivity — Tools/products/workflows: GPTs or MCP-enabled assistants that route tasks to specialist agents (calendar, email summarization, web/RAG lookup); human approvals for sensitive actions. — Expected impact: Time savings for information retrieval and routine communications; improved personal knowledge management. — Assumptions/dependencies: User consent and privacy controls; reliable tool connectors (calendar, email, storage); safe default policies.
Long-Term Applications
- Production-Grade SOC Augmentation and Partial Automation (SIEM/SOAR Integration) — cybersecurity — Tools/products/workflows: MAS integrated with SIEM/SOAR; autonomous playbooks; risk-aware policy engines; robust incident response handoffs; continuous red-teaming. — Expected impact: Reduced mean time to detect/respond; scalable threat handling; analyst focus on higher-order tasks. — Assumptions/dependencies: Reliability and alignment improvements; strong RBAC and auditability; model variance mitigation; supply chain security.
- Intelligent, Secure Data Migration Agents — government defence, regulated industries — Tools/products/workflows: MAS for data sanitation, provenance tracking, schema translation; zero-trust architectures; encrypted pipelines; federated deployments. — Expected impact: Lower migration risk/effort; better traceability of changes; faster modernization timelines. — Assumptions/dependencies: Security clearances; formal verification of data handling; performance under air-gapped constraints.
- End-to-End Customer Service First-Contact Resolution with Minimal Human Oversight — utilities/telecom/banking — Tools/products/workflows: MAS with dynamic risk scoring, compliance validators, escalation logic; A/B testing at scale; automated QA. — Expected impact: Higher resolution rates; reduced operational costs; consistent CX across channels. — Assumptions/dependencies: Strong safety/groundedness; regulatory compliance (consumer protection, GDPR); robust exception handling.
- Domain-Specific Agent Distillation and Edge Deployment — software/embedded/IoT — Tools/products/workflows: Distillation pipelines to create small, efficient specialist models; on-device inference; offline RAG caches. — Expected impact: Lower latency/cost; broader deployment surfaces; resilience in constrained environments. — Assumptions/dependencies: High-quality labeled corpora; maintainable distillation processes; hardware acceleration availability.
- Dynamic Schema Harmonization and Inter-Org Data Standards via MAS — finance/government/healthcare — Tools/products/workflows: Ontology alignment agents; semantic mapping services; cross-organizational data exchange protocols. — Expected impact: Reduced integration costs; improved data interoperability and analytics. — Assumptions/dependencies: Standard adoption and governance; consensus on ontologies; legal frameworks for data sharing.
- Decentralized Internet of AI Agents (NANDA-like Ecosystems) — platforms/infrastructure — Tools/products/workflows: Open protocols (e.g., MCP evolution), agent registries/identity; decentralized orchestration; trust frameworks. — Expected impact: Ubiquitous agent collaboration; new application paradigms; service composability at internet scale. — Assumptions/dependencies: Interoperability standards; global governance; privacy/security assurances; economic models.
- Formal MAS Governance, Safety, and Ethics Frameworks (Certification/Audits) — policy/regulation — Tools/products/workflows: Audit toolchains; bias/robustness monitors; incident reporting standards; certification processes. — Expected impact: Safer deployments; clearer accountability; smoother compliance pathways. — Assumptions/dependencies: Regulator capacity; standardized metrics/benchmarks; stakeholder alignment.
- MAS Reliability and Scalability Research Programs — academia/industry consortia — Tools/products/workflows: Open testbeds; coordination/error-propagation benchmarks; agent alignment methods; reproducible evaluation suites. — Expected impact: Reduced coordination overhead; predictable performance; production-grade design patterns. — Assumptions/dependencies: Funding; shared datasets; community adoption; method transparency.
- Cross-Cloud Agent Marketplaces and Orchestration Standards — software/platforms — Tools/products/workflows: MCP-aligned marketplaces; cross-cloud orchestration APIs; portable agent packaging. — Expected impact: Reduced vendor lock-in; faster assembly of complex workflows; broader innovation. — Assumptions/dependencies: Vendor collaboration; licensing/IP clarity; runtime security.
- Workforce Transformation and Reskilling Programs — HR/organizational development — Tools/products/workflows: Role redesign frameworks; MAS literacy training; human-in-the-loop operating procedures; change management. — Expected impact: Smoother adoption of agentic workflows; reduced displacement risks; improved productivity. — Assumptions/dependencies: Executive sponsorship; training budgets; cultural readiness.
- Federated SIE Across Departments with Privacy-Preserving Techniques — healthcare/finance/public sector — Tools/products/workflows: Federated RAG; differential privacy; homomorphic encryption; secure enclaves. — Expected impact: Cross-unit insights without centralizing sensitive data; stronger compliance posture. — Assumptions/dependencies: Mature privacy tech stacks; governance across federations; performance tuning.
- Adaptive Multi-Agent Educational Tutors at Scale — education — Tools/products/workflows: MAS that orchestrates curriculum-aligned retrieval, formative feedback, and competency tracking; teacher oversight dashboards. — Expected impact: Personalized learning at scale; reduced grading burden; data-driven pedagogy. — Assumptions/dependencies: Safeguarding policies; content licensing; longitudinal assessment design; equity considerations.
Collections
Sign up for free to add this paper to one or more collections.