- The paper demonstrates that under equal token budgets, Single-Agent LLMs outperform Multi-Agent systems by leveraging full global context.
- It employs an information-theoretic framework and rigorous empirical evaluation across models and benchmarks like FRAMES and MuSiQue.
- Under severe context degradation, Multi-Agent systems can reclaim competitiveness, emphasizing the trade-off between architectural design and context efficiency.
The paper investigates the comparative efficacy of single-agent systems (SAS) versus multi-agent systems (MAS) for multi-hop reasoning with LLMs, under the constraint of equal "thinking token" budgets. The analysis is motivated by the observation that many empirical MAS improvements are potentially confounded by increased compute at test time, making it unclear whether observed performance gains are truly architectural or simply the byproduct of greater resource allocation.
Using an information-theoretic argument anchored in the Data Processing Inequality (DPI), the authors show that, under a fixed reasoning-token budget, a single-agent system with full access to the global context is theoretically optimal in terms of information utilization. Specifically, for a given reasoning process, the message-passing bottlenecks in MAS architectures necessarily introduce information loss, with the result that I(Y;C)≥I(Y;M). Fano’s inequality makes this argument tangible for prediction error: the minimal achievable error based on MAS intermediates is lower bounded by that using a full SAS trajectory.
However, when the effective context for a single agent is degraded (via deletion, masking, substitution, or distractors), MAS can partially recover task-relevant information by structuring computation and filtering out noise, potentially allowing MAS to match or exceed SAS in severely corrupted scenarios.
Experimental Methodology
The empirical section encompasses models from three major families: Qwen3, DeepSeek-R1-Distill-Llama, and Gemini 2.5. The main evaluation benchmarks are FRAMES and MuSiQue (restricted to 4-hop questions), focusing on multi-hop world knowledge questions with concise reference answers.
A meticulous protocol ensures matched reasoning-token budgets for all systems. SAS is implemented as a unified forward trajectory; a variant (SAS-L) encourages more "visible" internal reasoning without increasing token budget. Five MAS variants are examined: Sequential, Subtask-parallel, Parallel-roles, Debate, and Ensemble, controlling for planning and aggregation overhead. The primary MAS baseline is Sequential, which structurally mimics SAS but with explicit decomposition and stepwise message-passing.
The evaluation metric uses an LLM-as-judge rubric: outputs are scored for semantic equivalence to reference answers by a dedicated model, controlling for formatting and paraphrasing.
Main Results: SAS vs. MAS Under Matched Budgets
Across all families, SAS matches or outperforms all MAS variants when computation is tightly controlled. In no regime (except severe context degradation) does MAS realize a generalized architectural advantage over the SAS baseline under equal token budgets. On Gemini models, the SAS-L variant can further close gaps previously attributed to MAS, particularly by unlocking underutilized internal reasoning channels.
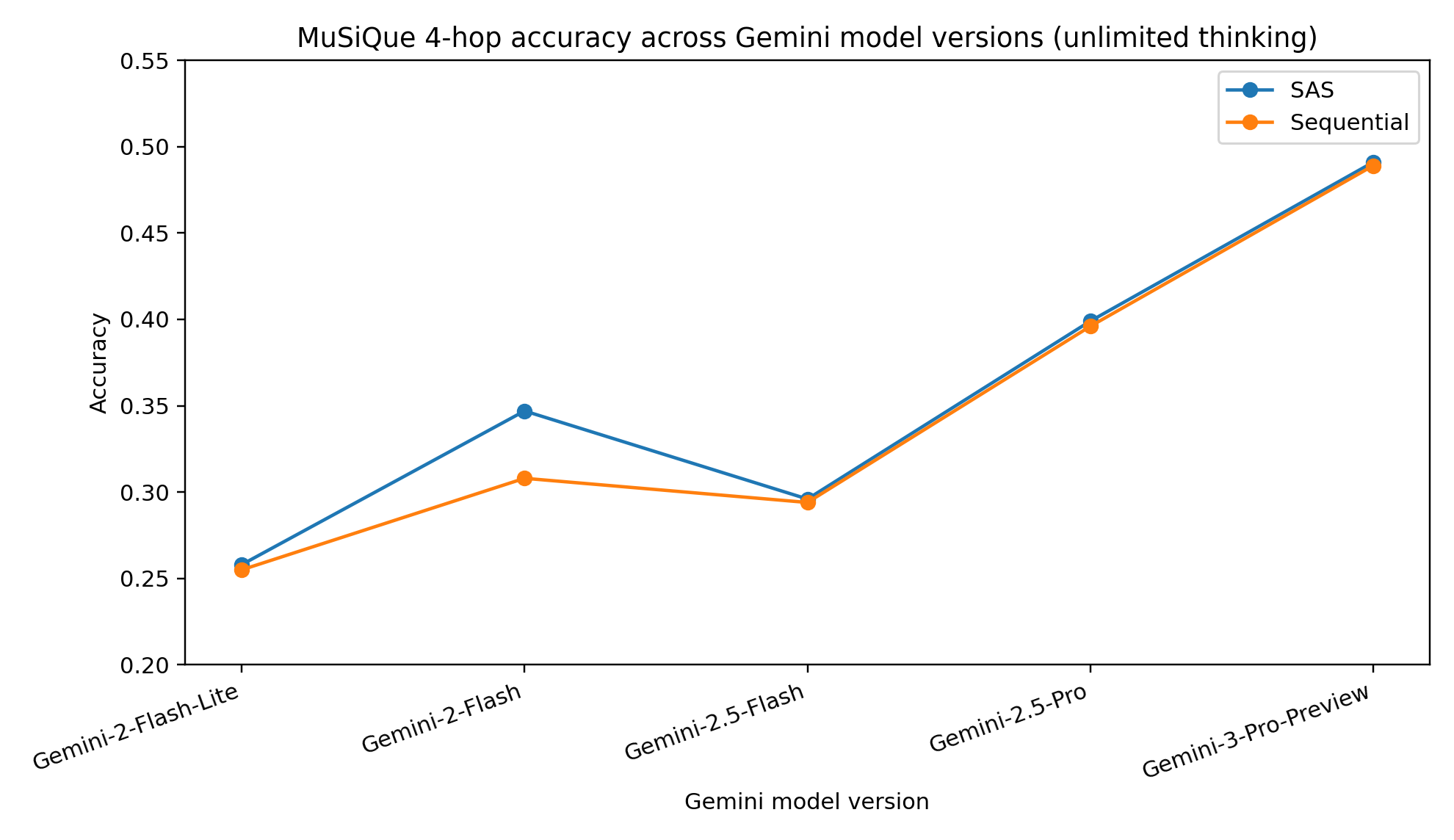
Figure 2: MuSiQue 4-hop answer accuracy for multiple Gemini model versions (unlimited thinking tokens): SAS is always at least competitive with Sequential MAS, with both improving with scaling.
Detailed ablations with Gemini model versions (Figure 1) show the SAS is consistently competitive or superior to Sequential MAS in every API release, with accuracy scaling monotonically with model quality but not with MAS adoption.
In detection of API artifacts, the paper reveals that visible reasoning with SAS is often truncated by the underlying serving infrastructure, and that thought token accounting using Gemini APIs can be highly unreliable. This has critical implications for reproducibility and fidelity in compute-bound comparisons.
Context Degradation and Robustness
Under controlled context degradation, the theoretical predictions are experimentally borne out: as the effective context available to the SAS is intentionally corrupted, MAS approaches (particularly those with greater diversity or verification, such as Debate) become competitive and, under heavy masking or substitution, clearly surpass SAS.
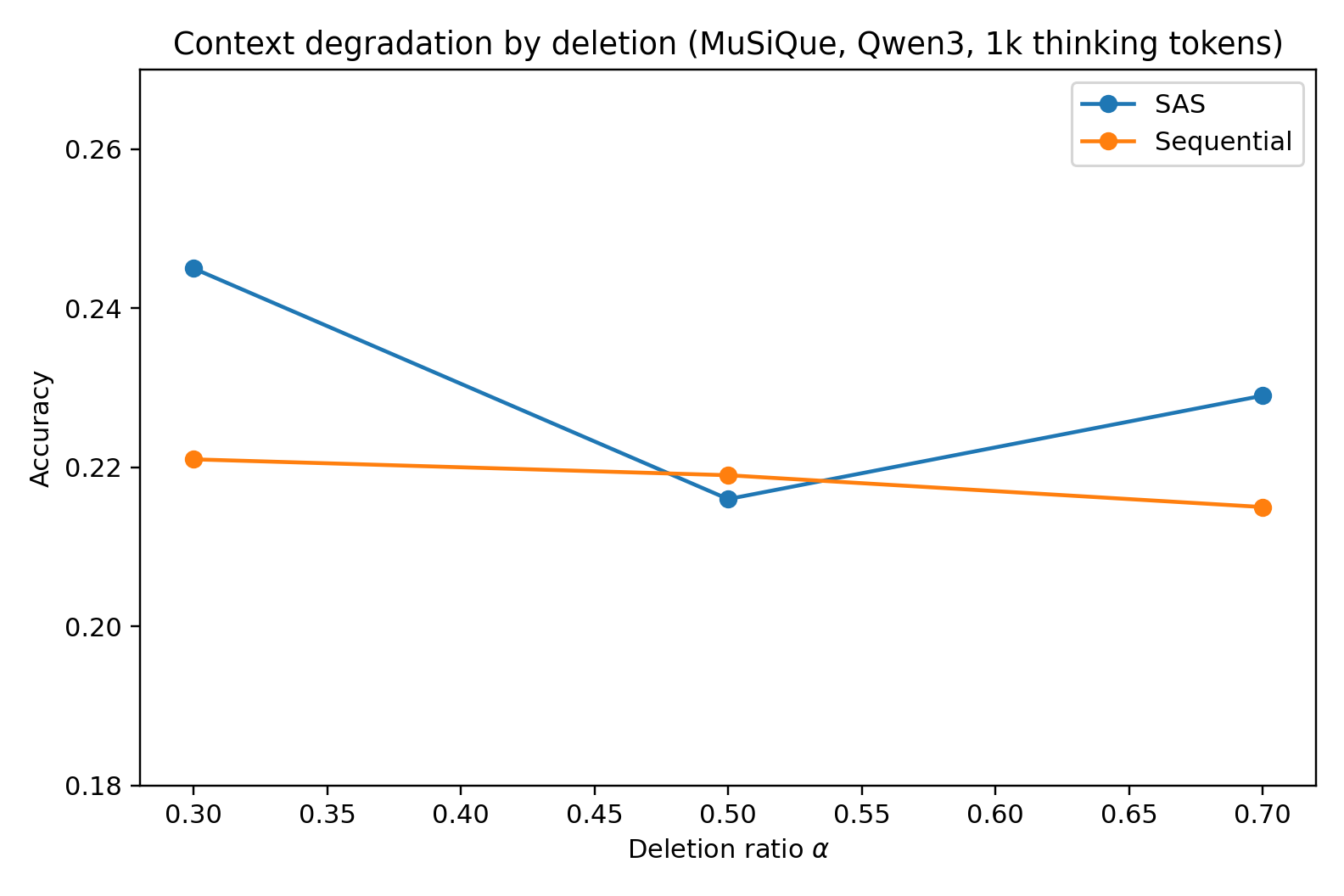
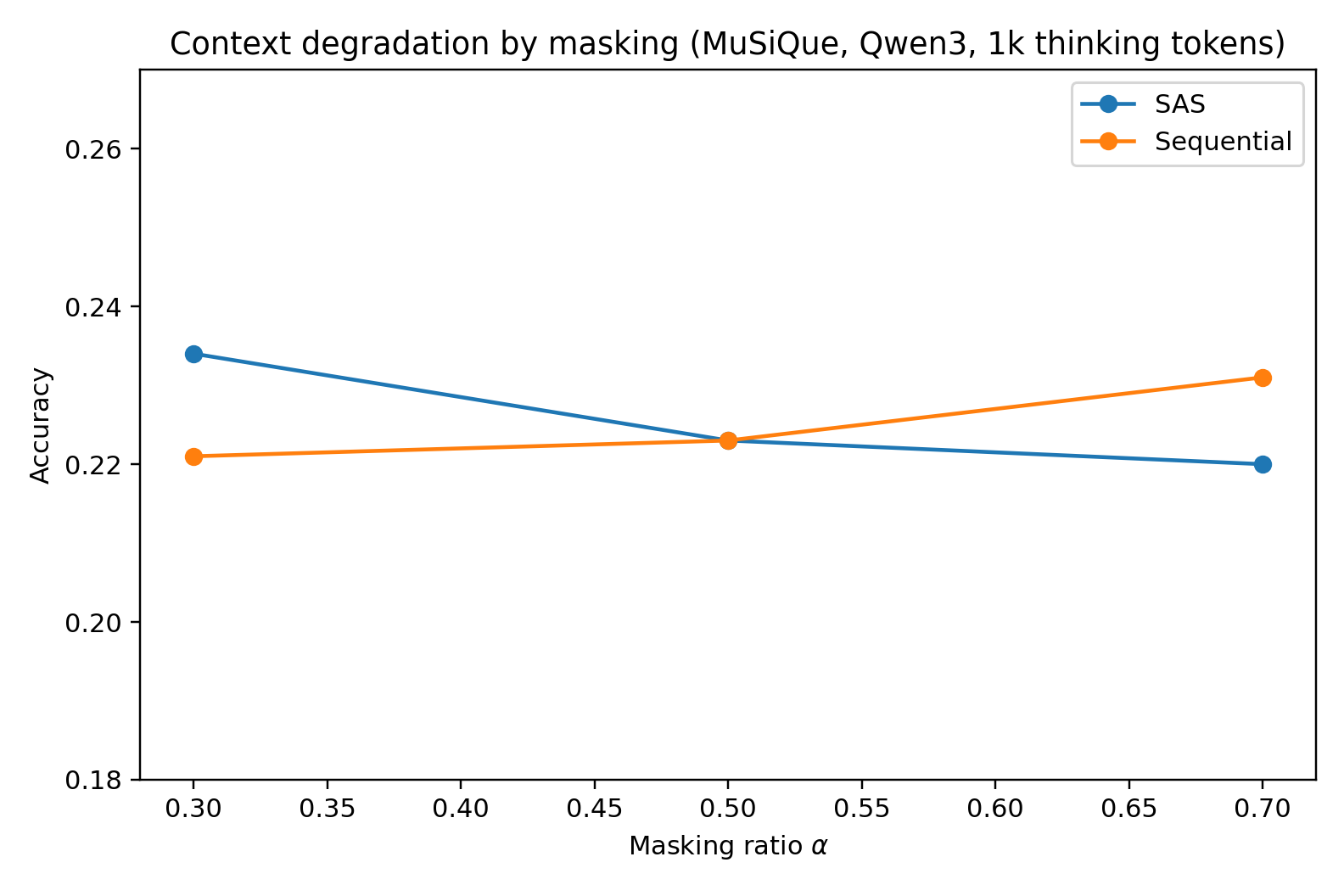
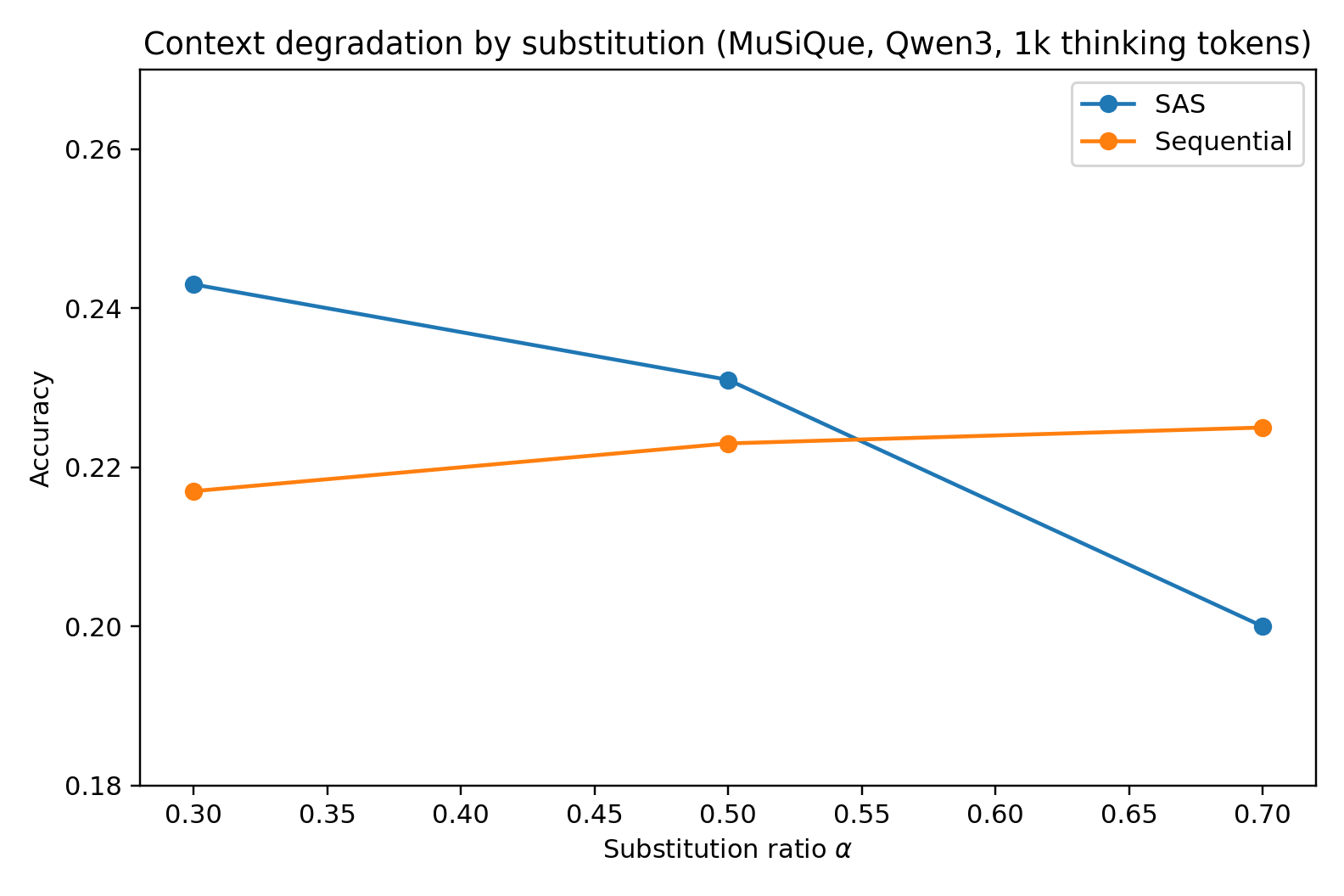
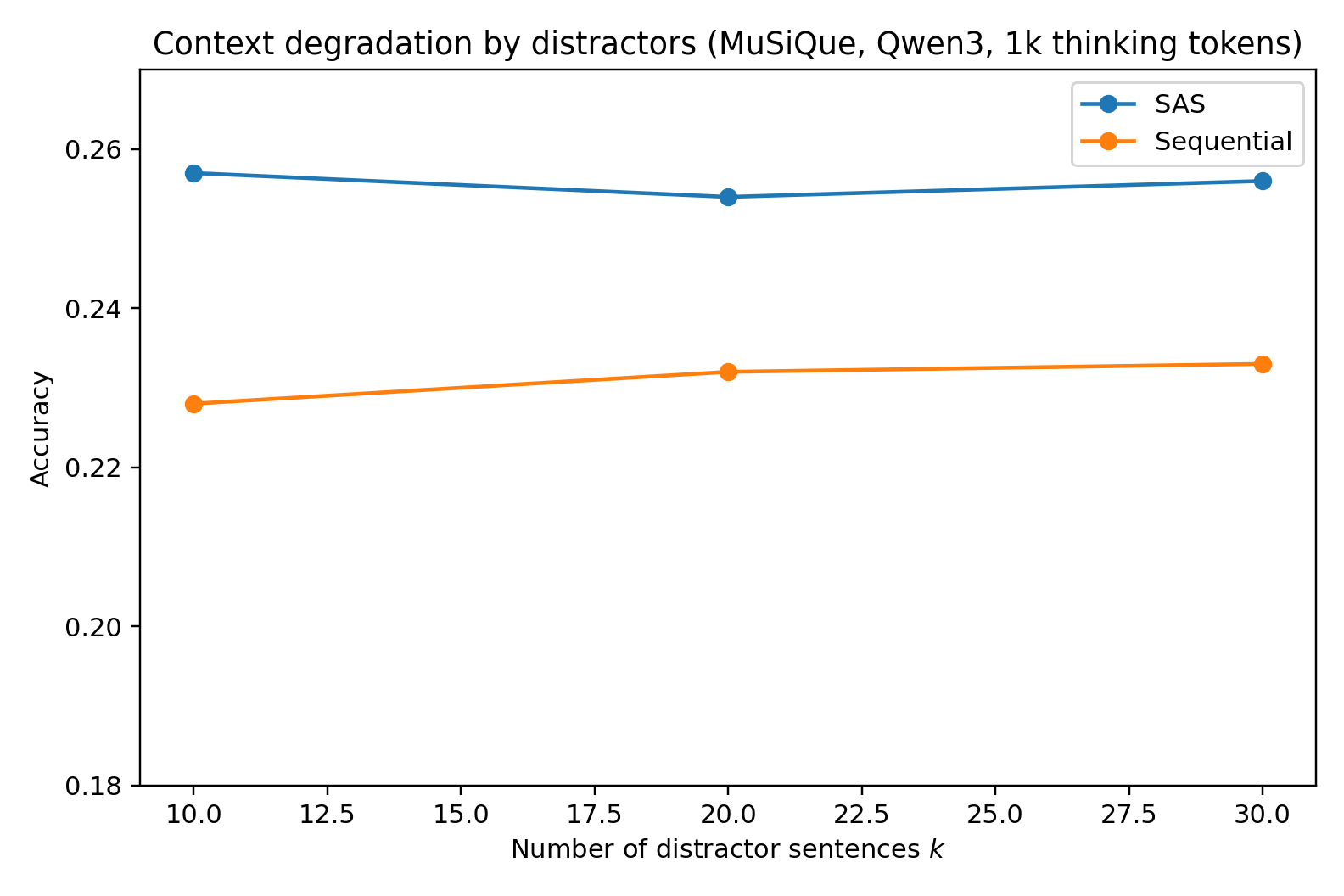
Figure 1: Context degradation (masking, substitution, deletion, distractors) on MuSiQue 4-hop with Qwen3-30B-A3B at 1000-token budget—SAS dominates at low degradation but MAS overtakes at highest corruption levels.
The transition point—the α or k value for which MAS outperforms—depends strongly on the corruption method. For deletions and distractors, SAS maintains its edge longer; for masking/substitution (where misleading content is injected), MAS gains a clear advantage at high degradation, validating the DPI-based theoretical argument.
Additional analyses show MAS architectures do not yield inherent gains even with extended compute or compositional diversity; any improvements track directly to expanded resource usage or more elaborate context filtering—not to any fundamental MAS design property.
Implications and Future Directions
The core result is a direct challenge to the prevailing assumption that multi-agent orchestration is inherently beneficial for complex LLM reasoning under compute-equated conditions. Across settings, the majority of MAS performance improvements in the literature are accounted for by unbalanced compute and context utilization, not architectural invention.
From a theoretical perspective, this shifts the focus to optimizing context and compute allocation within SAS, as orchestration and explicit communication in MAS architectures can only compensate when single-agent access to task-relevant context is severely bottlenecked by context degradation. MAS should be reserved for scenarios where attention and memory are provably the limiting factors, or where robust distributed filtering is required.
Practically, these findings advise greater care in interpreting MAS benchmarks for real-world deployment. For compute-constrained or latency-critical settings, optimal allocation is to maximize intra-agent reasoning depth rather than architecturally fragmenting the problem. For hybrid or degraded contexts, future work should investigate adaptive/hierarchical approaches that blend SAS and MAS strengths.
Experimentally, the findings highlight the necessity of precise token accounting and robust context auditing, particularly for API-mediated models where visible computation and internal inference may diverge.
Conclusion
The paper provides a comprehensive, rigorously controlled comparison of SAS and MAS settings for multi-hop LLM reasoning under normalized thinking token budgets. Theoretical and empirical evidence robustly supports the claim that SAS is always at least as competitive as any MAS analog in the computation-matched setting, except in the regime of extreme context degradation. These results call for a re-examination of the comparative regimes in which multi-agent orchestration is justified, and underscore the priority of resource and context efficiency over architectural proliferation in next-generation LLM system design.