MultiWorld: Scalable Multi-Agent Multi-View Video World Models
Abstract: Video world models have achieved remarkable success in simulating environmental dynamics in response to actions by users or agents. They are modeled as action-conditioned video generation models that take historical frames and current actions as input to predict future frames. Yet, most existing approaches are limited to single-agent scenarios and fail to capture the complex interactions inherent in real-world multi-agent systems. We present \textbf{MultiWorld}, a unified framework for multi-agent multi-view world modeling that enables accurate control of multiple agents while maintaining multi-view consistency. We introduce the Multi-Agent Condition Module to achieve precise multi-agent controllability, and the Global State Encoder to ensure coherent observations across different views. MultiWorld supports flexible scaling of agent and view counts, and synthesizes different views in parallel for high efficiency. Experiments on multi-player game environments and multi-robot manipulation tasks demonstrate that MultiWorld outperforms baselines in video fidelity, action-following ability, and multi-view consistency. Project page: https://multi-world.github.io/





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
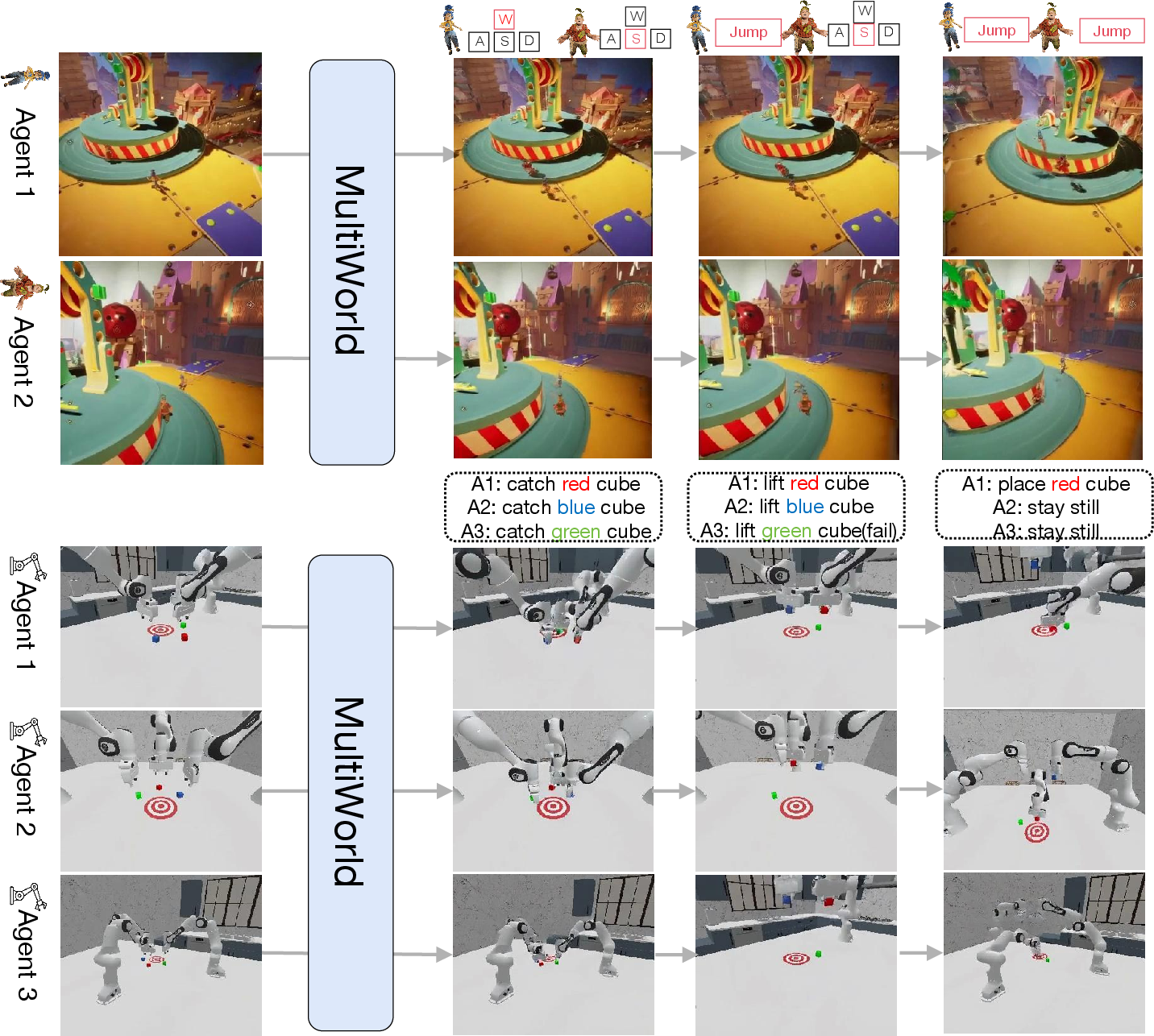
This paper introduces MultiWorld, an AI system that can “imagine” the future in a shared world with many agents (like players or robots) and many cameras. Think of a co-op video game or a robot factory: several characters act at the same time, and multiple cameras watch them from different angles. MultiWorld predicts what happens next as a video for each camera, while making sure all the views agree with each other and each agent follows its own controls.
What questions are they trying to answer?
- How can we control several agents at once in a single shared world, so each one correctly follows its own actions?
- How can we make videos from different cameras that all show a consistent version of the same world (no contradictions across views)?
- How can we make a system that works even when the number of agents or cameras changes?
How does their method work?
At a high level, MultiWorld is a “video world model.” It takes:
- recent frames (what the cameras saw),
- the actions for each agent (like “move left,” “jump,” “grab”), and predicts the next frames for each camera.
To do this, it uses two key parts: a Multi-Agent Condition Module (to control many agents clearly) and a Global State Encoder (to keep all camera views consistent). Here’s the idea in everyday terms.
Multi-Agent Condition Module (MACM): keeping agents separate and fair
Problem: If you just dump all agents’ actions into one pile, the model can get confused about which action belongs to which agent, especially when actions “mirror” each other (e.g., Player A left vs. Player B right).
Solution: MACM gives each agent a clear “name tag” inside the model and adjusts attention to the agents that matter most right now.
- Agent Identity Embedding (AIE): Imagine giving each agent a unique color so the model can always tell them apart, even if they do similar things. AIE does this mathematically by rotating each agent’s action embedding in a distinctive way, so identities don’t get mixed up.
- Adaptive Action Weighting (AAW): Not all agents are equally active every moment. AAW is like turning up the volume for the agents who are moving and turning it down for those standing still. That helps the model focus on the actions that actually change the scene.
Global State Encoder (GSE): keeping camera views consistent
Problem: Multiple cameras watch the same world from different angles. If the model treats each camera separately, the videos might disagree (e.g., a box appears in one camera but disappears in another).
Solution: GSE builds a shared “global state” of the scene that all cameras use. Think of it like the world’s stage plan or a 3D mental map that every camera respects.
- How it works: The model looks at the latest images from all cameras and extracts a 3D-aware summary of the environment (using a pretrained 3D vision model). This summary is then used to guide the video prediction for each camera. That way, every camera view stays consistent with the same underlying world.
Scalable design: flexible numbers of agents and cameras
- More agents: Because AIE labels agents in a relative, flexible way, you can add or remove agents without redesigning the model.
- More cameras: Because GSE compresses any number of views into a single global state, you can add more cameras and still generate their videos in parallel (fast and efficient).
Training and generation (in simple terms)
- The model learns by predicting how future frames should look given past frames and the agents’ actions. You can think of it as repeatedly practicing: “If these are the actions and this is what the world looks like now, what will it look like next?”
- For long videos, it works in chunks. After generating a short segment for all cameras, it updates the global state with the newest frames and continues—like rolling planning.
What did they find, and why is it important?
They tested MultiWorld on two types of data:
- A two-player co-op video game (It Takes Two), where each player has their own camera view and actions.
- A multi-robot manipulation simulator (RoboFactory), with 2–4 robots and changing camera setups.
Compared to other methods, MultiWorld:
- Makes higher-quality videos (clearer, more realistic).
- Follows the given actions more accurately (each agent does what it’s supposed to).
- Keeps different camera views consistent with each other (no contradictions).
- Scales better to more agents and more cameras, and can generate views in parallel (faster).
This matters because many real tasks—team sports, factory robots, self-driving fleets, multiplayer games—need accurate, coordinated multi-agent simulation that looks consistent from every angle.
What could this research lead to?
- Better training and testing for multi-robot teams without risking real hardware (it can even simulate failure cases, like collisions, safely).
- Smarter AI planning for groups of agents (e.g., coordinating tasks from multiple viewpoints).
- More realistic and controllable multiplayer game simulations and tools for creators.
- Stronger foundations for future AI systems that need to understand and predict complex, shared worlds.
Key terms explained simply
- World model: An AI that learns to “imagine” how a world changes over time based on what agents do.
- Multi-agent: Several players/robots acting at the same time in the same world.
- Multi-view: Multiple cameras recording the same world from different angles.
- Consistency: All camera views agree about where things are and what’s happening.
- 3D-aware global state: A shared, compact representation of the scene that captures its 3D structure, helping all cameras stay in sync.
- Action controllability: How well the model makes each agent follow the actions it’s told to do.
In short, MultiWorld is like a smart movie director for complex, shared worlds: it keeps track of many actors, listens to their instructions, and films from several cameras at once—making sure every shot tells the same story.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of unresolved issues and open directions that emerge from the paper’s methods, experiments, and claims.
- Scaling behavior with agent/view count: The framework claims scalability but is only evaluated on 2–4 agents and up to a small number of views; there is no characterization of quality, memory, or latency as the number of agents (e.g., ≥8) or views (e.g., ≥8–16) increases.
- Camera parameter handling and generalization: The method does not explicitly condition on camera intrinsics/extrinsics; it is unclear how well it generalizes to novel camera intrinsics, new viewpoints, or wide-baseline settings, and whether calibration is required or used.
- Moving/variable cameras: Training data are filtered for “stable camera motion,” leaving open how the approach handles fast or non-smooth camera motions, moving sensors, or dynamically changing camera configurations.
- Asynchronous/missing views: The approach assumes synchronized multi-view inputs; robustness to asynchronous views, dropped frames, or differing frame rates is not evaluated.
- Explicit 3D modeling vs. latent GSE: The GSE relies on latent features from a frozen 3D reconstruction backbone (VGGT) without explicit geometry or pose conditioning; the trade-offs versus explicit 3D scene representations (e.g., point clouds, NeRFs) for consistency and controllability remain unexplored.
- Dynamic scenes and VGGT suitability: VGGT is typically optimized for multi-view 3D reconstruction of (quasi-)static scenes; the impact of dynamic, multi-agent, non-rigid scenes on the fidelity of the extracted “3D-aware” global state is not quantified.
- Training–inference mismatch in GSE updates: During long-horizon autoregression, the GSE is updated with generated frames, potentially causing compounding errors; there is no analysis of self-conditioning, noise-aware training, or scheduled sampling to reduce this gap.
- Long-horizon stability limits: While results indicate 2×–4× context length generation, the failure modes, drift rates, and stability limits at significantly longer horizons are not measured or characterized.
- Identity persistence and tracking: The paper does not quantify whether per-agent visual identities are preserved over time and across views (e.g., ID switches), nor provide metrics for cross-view identity consistency.
- Heterogeneous agents and action spaces: The method assumes a uniform action encoding per agent; support for agents with heterogeneous action spaces, mixed discrete/continuous controls, or different control rates is not demonstrated.
- Variable agent sets over time: Scenarios where agents enter/leave the scene (spawn/despawn), or the number of agents changes mid-episode, are not evaluated; robustness of AIE and AAW under such changes is unknown.
- AIE extrapolation and alternatives: The agent identity embedding (RoPE-based) is tuned (e.g., base=20) but not validated beyond the training range; alternative identity schemes (learned embeddings, hashing, permutation-equivariant designs) and their scaling/robustness are unexplored.
- AAW aggregation and per-agent credit: Adaptive Action Weighting collapses per-frame actions into a single token; its effect on per-agent disentanglement, credit assignment, and fine-grained controllability is not rigorously measured.
- Action-following evaluation: The use of an IDM-based metric (from VPT) can be biased and task/domain-dependent; per-agent, per-action adherence metrics and task-success measures for multi-agent coordination are not reported.
- Multi-view consistency metrics: RPE is used, but the details (e.g., reliance on ground-truth poses or estimated geometry) are missing; broader 3D consistency metrics (e.g., epipolar consistency, cross-view optical-flow consistency) and ablations under varying baselines/occlusions are absent.
- Occlusions and large viewpoint changes: Robustness to heavy occlusions, disocclusions, and significant parallax is not tested; failure modes under extreme cross-view differences remain unknown.
- Real-time performance and system profiling: Claims about parallel view generation lack detailed throughput/latency profiles, GPU memory scaling, and breakdown of costs (DiT vs. GSE) for practical on-policy use.
- Rare-event and failure-mode simulation: The approach claims to simulate failures, but data scarcity, calibration of probabilities, and reliability under rare or safety-critical events are not studied.
- Physical plausibility: There is no quantitative evaluation of physics fidelity (e.g., contact dynamics, momentum conservation, collision handling), nor mechanisms to enforce physics consistency beyond causal masking.
- Domain transfer and real-world deployment: Generalization from a single game and a simulator to real robotic settings (sensor noise, calibration drift, latency) is not validated; sim-to-real transfer strategies are not explored.
- Integration with downstream control/RL: Closed-loop evaluations (e.g., planning with the model-in-the-loop, sample efficiency for RL, robustness to model bias) are not provided.
- Data availability and reproducibility: It is unclear whether the collected datasets (ItTakesTwo subset, RoboFactory episodes) and calibration/meta-data will be released, which limits reproducibility and benchmarking.
- Baseline coverage: Comparisons to recent multi-agent, multi-view world models (e.g., concurrent works) are not included quantitatively; ablations on more competitive baselines or strong single-view models with cross-view constraints are missing.
- Robustness to visually identical agents: The ability of AIE to maintain correct action-to-agent mapping when agents are visually indistinguishable (same appearance) is not assessed.
- Uncertainty quantification: The model provides samples but no calibrated uncertainty estimates; how to quantify or control uncertainty across views/agents remains open.
- Goal- or language-conditioned control: The framework is action-conditioned; extending to higher-level controls (goals, language) and joint action-and-camera control remains unexplored.
Practical Applications
Overview
MultiWorld introduces two core technical innovations—Multi-Agent Condition Module (MACM: Agent Identity Embedding + Adaptive Action Weighting) and a Global State Encoder (GSE) built on a 3D-aware VGGT backbone—that together enable action-controllable, multi-agent, multi-view video world modeling with scalable agent/view counts, parallel multi-view synthesis, and autoregressive long-horizon rollout. These capabilities translate into a range of practical applications summarized below.
Immediate Applications
Below are actionable use cases that can be piloted now with offline or near–real-time workflows and moderate integration effort.
- Multi-camera synthetic data generation for perception systems
- Sector: robotics, autonomous driving, security/video analytics, retail analytics
- What: Generate synchronized, multi-view videos with controllable agent actions to augment datasets for multi-object tracking, re-identification, pose estimation, and cross-view consistency training
- Tools/products/workflows: “MultiWorld Data Forge” (dataset generator); scripts that take action traces + seed frames and output parallel multi-view clips; RPE-based multi-view consistency checks in CI for data quality
- Dependencies/assumptions: Domain gap to real imagery; need starter viewpoints (initial frames) and action schemas; compute budget for batch generation; licensing constraints if training on proprietary content
- Multi-robot coordination prototyping and failure analysis
- Sector: manufacturing, logistics/warehousing, service robotics
- What: Rapid “what-if” simulation of coordinated robot behaviors and plausible failure trajectories (collisions, deadlocks) for HRI safety review and controller debugging
- Tools/products/workflows: ROS/ROS2 adapter to stream action sequences from planners; failure library generation; regression gates using action-following metrics
- Dependencies/assumptions: Not physics-accurate contact dynamics; requires mapping planner actions to model’s action tokens; domain-specific visual assets may be needed
- Game QA, playtesting, and level design assistance
- Sector: gaming
- What: Auto-generate multi-player playthroughs across multiple camera angles from scripted action sequences to hunt for soft locks, pacing issues, and multi-agent interaction bugs
- Tools/products/workflows: “MultiWorld Playtest Runner” that ingests controller traces or bot policies; side-by-side ground-truth vs generated runs; bug triage via action-following deviations
- Dependencies/assumptions: Access to authentic action logs; model adaptation to target game art style; integration with build/data pipelines
- Multi-angle content creation for e-sports and trailers
- Sector: media and entertainment
- What: Produce synchronized cinematic replays from minimal action logs to create multi-view highlights and trailers
- Tools/products/workflows: Replay generator that renders parallel views; automated shot selection via RPE and motion saliency
- Dependencies/assumptions: Asset/IP permissions; offline generation time; stylistic fidelity
- Academic benchmarking and method development
- Sector: academia/AI research
- What: Evaluate multi-agent controllability (MACM), multi-view consistency (GSE), and long-horizon autoregression; build stronger baselines and ablations
- Tools/products/workflows: Open-source training/inference recipes; standardized metrics (FVD, RPE, IDM-based action-following) and evaluation scripts; variable K (agents) and C (cameras) stress tests
- Dependencies/assumptions: GPU availability; dataset access or recreation; reproducibility of reported settings (e.g., RoPE base for AIE)
- Education and hands-on labs for multi-agent systems
- Sector: education
- What: Teaching modules on multi-agent coordination, view synthesis, and world-model-based simulation with reproducible labs (RoboFactory tasks, dual-agent games)
- Tools/products/workflows: Classroom notebooks; packaged checkpoints; “turn actions into multi-view videos” assignment kits
- Dependencies/assumptions: Compute quotas; curated starter datasets; simplified action spaces for pedagogy
- Multi-camera surveillance R&D and training data
- Sector: public safety, transportation hubs, retail loss prevention
- What: Privacy-preserving synthetic multi-view footage for training re-id and cross-camera tracking; incident pattern augmentation
- Tools/products/workflows: Synthetic scene templating; controllable agent scripts for crowd flows; bias audits comparing real vs synthetic
- Dependencies/assumptions: Ethical use and governance; realism sufficient for downstream generalization; calibration approximations via GSE are implicit (no explicit geometry)
- AV and mobile robotics scenario sketching
- Sector: autonomous vehicles, AMRs
- What: Draft multi-agent interactions (merges, cut-ins, occlusions) and multi-camera recordings for early-stage perception/planning experiments
- Tools/products/workflows: Scenario DSL → action tokenization → multi-view clip generation; perception stress tests with RPE thresholds
- Dependencies/assumptions: Street-scene domain adaptation; alignment of control/action spaces; lack of LiDAR/radar channels (video only)
- Camera placement previsualization
- Sector: factories, retail, venues, film pre-viz
- What: Evaluate blind spots and cross-view coverage by synthesizing new camera views conditioned on the same global state
- Tools/products/workflows: “GSE View Planner” that scores candidate camera layouts using reprojection error and coverage heuristics
- Dependencies/assumptions: Approximate environment initial frames; no explicit metric geometry; qualitative rather than metrologically precise
Long-Term Applications
The following require further research for real-time performance, stronger physical fidelity, scaling, or formal validation before production deployment.
- Real-time, generative multi-agent game engines
- Sector: gaming
- What: Replace or augment parts of a game engine with a world model that renders multi-player, multi-camera content live from action streams
- Tools/products/workflows: “MultiWorld Runtime” with streaming inference and camera control; adaptive AIE for lobbies with variable player counts
- Dependencies/assumptions: Tight latency budgets; robust action-to-visual determinism; content safety and moderation
- Enterprise digital twins for multi-robot operations
- Sector: manufacturing, logistics, fulfillment centers
- What: Closed-loop planning and monitoring with learned video twins that scale to dozens of robots and cameras, enabling A/B testing of policies and layouts
- Tools/products/workflows: Planner-in-the-loop simulators; large-scale parallel view generation; rollout analytics dashboards
- Dependencies/assumptions: Higher physical realism; calibrated asset libraries; rigorous sim2real validation
- Regulatory scenario libraries and safety validation
- Sector: policy/regulation (AVs, robotics, public safety)
- What: Curate standardized, reproducible multi-agent, multi-view synthetic scenarios for conformance testing, rare-event analysis, and policymaker sandboxes
- Tools/products/workflows: Scenario catalogs with metadata; acceptance criteria based on action adherence and cross-view consistency; audit trails
- Dependencies/assumptions: Regulatory acceptance of video-only simulation; transparency on training data; traceability and reproducibility requirements
- Surgical and clinical team simulation (multi-robot/multi-camera OR)
- Sector: healthcare
- What: Train collaborative surgical assistants and multi-camera OR analytics with controllable, multi-agent world models
- Tools/products/workflows: OR digital twin with action-conditioned generative video; curriculum generation for failure modes
- Dependencies/assumptions: Medical visual fidelity; domain-specific dynamics; stringent safety, privacy, and validation standards
- Smart-city and crowd simulation for planning
- Sector: urban planning, transportation, emergency response
- What: City-scale, multi-camera simulations of evacuations, transit flows, and incident responses; optimize CCTV layouts and response policies
- Tools/products/workflows: Policy “wind-tunnel” that replays interventions as multi-view videos; placement optimization using GSE
- Dependencies/assumptions: Behavior models for diverse agents; ethical governance; scalability to hundreds of views
- Household multi-robot teams and home digital twins
- Sector: consumer robotics, smart home
- What: Plan and train cooperative tasks (tidying, cooking assistance) with multi-view video twins for different rooms and camera devices
- Tools/products/workflows: Task script → action tokens → multi-view generation → policy improvement loop
- Dependencies/assumptions: Generalization to clutter and varied lighting; private in-home training; low-power inference pathways
- Autonomous drone swarms, inspection, and SAR training
- Sector: energy, infrastructure, public safety
- What: Simulate multi-UAV coordination with synchronized onboard and external views for training and risk rehearsal
- Tools/products/workflows: Waypoint-to-action adapters; multi-angle situational awareness video synthesis
- Dependencies/assumptions: Outdoor domain adaptation; wind/flight physics approximations; 3D geometry grounding
- Broadcast and virtual production “AI director”
- Sector: media and entertainment
- What: An agent that chooses and synthesizes camera angles consistent with a shared global state during live events or virtual sets
- Tools/products/workflows: Camera policy learning with RPE and saliency rewards; latency-optimized MultiWorld inference
- Dependencies/assumptions: Real-time constraints; style/brand consistency; rights management for likeness and scenes
- Standards and governance for synthetic multi-view datasets
- Sector: policy, standards bodies, compliance
- What: Best practices for dataset disclosure, bias assessment, and safety evaluation for multi-agent, multi-view synthetic data
- Tools/products/workflows: Documentation templates capturing action sources, view generation parameters, and RPE metrics; audit pipelines
- Dependencies/assumptions: Cross-stakeholder consensus; reference implementations; lifecycle management
Cross-Cutting Notes on Feasibility
- Strengths enabling adoption
- Variable agent/view scalability via AIE and GSE; parallel view synthesis keeps latency nearly constant with adequate compute; demonstrated action adherence and multi-view consistency; autoregressive long-horizon rollout
- Key assumptions and dependencies
- Fidelity: The model is video-only and not explicitly physics-grounded or metrically calibrated; GSE is 3D-aware in latent space but does not output explicit geometry
- Data: Requires initial view frames and well-defined action schemas; domain adaptation to target visuals and dynamics is often necessary
- Compute/latency: Current training/inference is offline or batch-oriented; real-time use will need optimized inference stacks and possibly distilled models
- Governance: IP/licensing for source data; privacy for human-in-the-loop scenarios; regulatory acceptance for safety-critical uses
These applications map directly from MultiWorld’s contributions—MACM for precise multi-agent control, GSE for cross-view coherence, and a scalable, parallelizable inference strategy—positioning the method as a practical tool today for offline simulation and data generation, and as a foundation for future real-time, safety-critical, and policy-relevant systems.
Glossary
- 3D-aware: Refers to representations or models that encode three-dimensional structure so that predictions remain geometrically consistent across viewpoints. "a global 3D-aware environment state via the Global State Encoder (GSE)"
- Action-conditioned video generation: Video synthesis where future frames are predicted based on provided action inputs (from users or agents). "They are modeled as action-conditioned video generation models that take historical frames and current actions as input to predict future frames."
- Adaptive Action Weighting (AAW): A mechanism that dynamically scales each agent’s action embedding by its importance, prioritizing active agents. "we introduce an Adaptive Action Weighting mechanism that dynamically prioritizes active agents over static ones"
- Agent Identity Embedding (AIE): An embedding scheme that assigns distinct identities to agents (here via rotary position embeddings) to resolve identity ambiguity in multi-agent control. "which consists of Agent Identity Embedding (AIE) and Adaptive Action Weighting."
- Autoregressive inference: Generating long sequences by conditioning each step on previously generated outputs, enabling extension beyond the training context. "supporting autoregressive inference to generate beyond the training context length"
- Causal mask: A temporal masking strategy that prevents attention to future information, enforcing causality during generation. "we apply a frame-wise causal mask to the action cross-attention"
- Cross-attention: An attention mechanism where one set of tokens attends to another set (e.g., video tokens attending to action or state tokens). "Finally, is injected into the DiT via cross-attention"
- DiT (Diffusion Transformer): A Transformer-based diffusion model architecture used for image/video generation. "injected into the DiT backbone through causal cross-attention."
- Flow Matching (FM): A training framework that learns velocity fields to transform noise into data, serving as an alternative to standard diffusion objectives. "Our model is built on Flow Matching (FM)~\cite{lipman2023flow, liu2023flow} with a Transformer backbone."
- Fréchet Video Distance (FVD): A distributional metric evaluating video quality by comparing feature statistics between generated and real videos. "FVD (Fréchet Video Distance)~\cite{unterthiner2018towards}"
- Global State Encoder (GSE): A module that encodes multi-view observations into a shared 3D-aware latent state to enforce cross-view consistency. "the Global State Encoder (GSE)"
- Inverse Dynamics Model (IDM): A model that predicts the action given consecutive observations; used here to assess action-following performance. "we evaluate action-following ability using the Inverse Dynamics Model (IDM) following VPT~\cite{baker2022vpt}."
- Learned Perceptual Image Patch Similarity (LPIPS): A perceptual metric measuring similarity using deep features aligned with human judgments. "LPIPS (Learned Perceptual Image Patch Similarity)~\cite{zhang2018unreasonable}"
- Multi-Agent Condition Module (MACM): A conditioning module combining AIE and AAW to enable scalable, precise control over multiple agents. "we propose the Multi-Agent Condition Module (MACM) (Sec.~\ref{sec:macm})"
- Multi-Agent Controllability: The capability to correctly associate and synchronize distinct agents’ actions with their behaviors in a shared environment. "Multi-Agent Controllability: controlling multiple agents requires associating specific actions with corresponding agents and synchronizing their executions."
- Multi-view consistency: The requirement that generated observations from different viewpoints remain visually and geometrically coherent. "while maintaining multi-view consistency."
- Peak Signal-to-Noise Ratio (PSNR): A signal-based metric (in dB) assessing reconstruction fidelity relative to ground truth. "PSNR (Peak Signal-to-Noise Ratio)"
- Reprojection Error (RPE): An error measure indicating geometric consistency across views by comparing projected points between viewpoints. "reprojection error (RPE)~\cite{wu2025geometryforcing}"
- Rotary Position Embedding (RoPE): A positional encoding technique that rotates embedding pairs to encode positions (or identities) in attention. "we adopt Rotary Position Embedding~\cite{rope} to compute agent identity embeddings."
- Structural Similarity Index (SSIM): A perceptual metric evaluating image similarity based on luminance, contrast, and structure. "SSIM (Structural Similarity Index)~\cite{wang2004image}"
- Variational Autoencoder (VAE): A generative model that encodes data into a latent distribution and decodes samples back to data space. "leveraging pretrained VAEs to provide basic cross-view information."
- VGGT: An end-to-end 3D reconstruction foundation model used to extract 3D-aware environmental features from multiple views. "we employ a pretrained VGGT~\cite{wang2025vggt}"
- Video world models: Generative models that simulate future environment dynamics conditioned on inputs like actions or text. "Video world models have achieved significant success in accurately predicting future environment dynamics conditioned on text or actions."
Collections
Sign up for free to add this paper to one or more collections.