HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
Abstract: We introduce HY-World 2.0, a multi-modal world model framework that advances our prior project HY-World 1.0. HY-World 2.0 accommodates diverse input modalities, including text prompts, single-view images, multi-view images, and videos, and produces 3D world representations. With text or single-view image inputs, the model performs world generation, synthesizing high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes. This is achieved through a four-stage method: a) Panorama Generation with HY-Pano 2.0, b) Trajectory Planning with WorldNav, c) World Expansion with WorldStereo 2.0, and d) World Composition with WorldMirror 2.0. Specifically, we introduce key innovations to enhance panorama fidelity, enable 3D scene understanding and planning, and upgrade WorldStereo, our keyframe-based view generation model with consistent memory. We also upgrade WorldMirror, a feed-forward model for universal 3D prediction, by refining model architecture and learning strategy, enabling world reconstruction from multi-view images or videos. Also, we introduce WorldLens, a high-performance 3DGS rendering platform featuring a flexible engine-agnostic architecture, automatic IBL lighting, efficient collision detection, and training-rendering co-design, enabling interactive exploration of 3D worlds with character support. Extensive experiments demonstrate that HY-World 2.0 achieves state-of-the-art performance on several benchmarks among open-source approaches, delivering results comparable to the closed-source model Marble. We release all model weights, code, and technical details to facilitate reproducibility and support further research on 3D world models.
First 10 authors:











Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
HY-World 2.0, explained for curious teens
What is this paper about?
This paper introduces HY-World 2.0, a system that can both imagine and rebuild 3D worlds. It takes in different kinds of inputs—like a text description (“a cozy wooden cabin in snowy mountains”), a single photo, several photos from different angles, or a video—and turns them into a virtual 3D environment you can walk around in. It uses a fast 3D format called “3D Gaussian Splatting,” which you can think of as painting the world with tiny glowing dots that together form surfaces, textures, and objects.
The big idea is to combine two skills in one open-source system:
- Generation: creating a believable 3D world from little information (like text or one image).
- Reconstruction: accurately rebuilding a 3D world when given many views (like multi-view images or a video).
What were the authors trying to do?
In simple terms, they asked:
- Can one system handle many types of input (text, one image, many images, videos) and produce a 3D world you can explore?
- Can we make the 3D worlds both imaginative (when information is missing) and accurate (when we have lots of visuals)?
- Can we plan smart camera paths to “look around” and fill in the world’s details?
- Can we stitch everything together into a clean 3D format that works well in games, VR, and simulations?
- Can we make all of this fast, consistent, and easy for others to use by releasing code and models?
How does the system work?
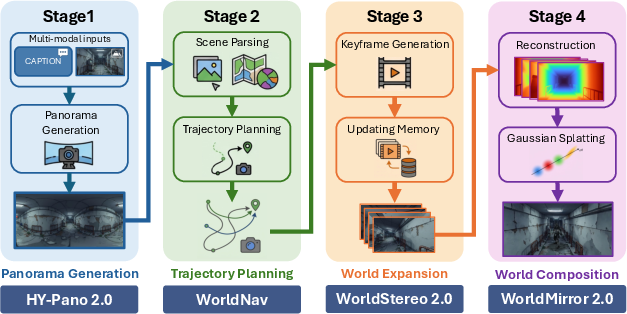
HY-World 2.0 follows a four-step process, a bit like how a person might imagine, explore, and then build a model of a place.
1) Panorama Generation (HY-Pano 2.0)
- What it does: Creates a 360-degree image (a “panorama”) from text or a single photo. Imagine standing in one spot and seeing everything around, including above and below you—like a full bubble view.
- How it works in everyday terms: Instead of needing exact camera settings, it uses a powerful image generator (a diffusion transformer) that learns to “unwrap” a normal photo into a full 360° scene. It also uses tricks to avoid seams where the panorama wraps around, so the image is smooth.
- Why this matters: Starting with an all-around view gives the system a strong, consistent base world to explore and expand.
2) Trajectory Planning (WorldNav)
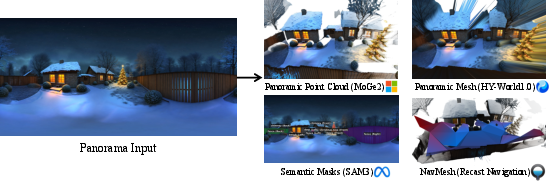
- What it does: Plans the camera’s path to explore the scene and collect the most useful views while avoiding obstacles—like plotting a safe tour through a new place.
- How it works in everyday terms: It builds a rough 3D map (point clouds and meshes), tags important objects (like sofas, trees, or cars), and creates a “walkable area” map (NavMesh) so the virtual camera doesn’t bump into things.
- The planned paths include:
- Regular paths for general coverage
- Surrounding paths circling important objects
- Reconstruction-aware paths targeting areas that were poorly seen
- Wandering paths that head toward far or narrow spaces (like hallways)
- Aerial paths that look from higher angles
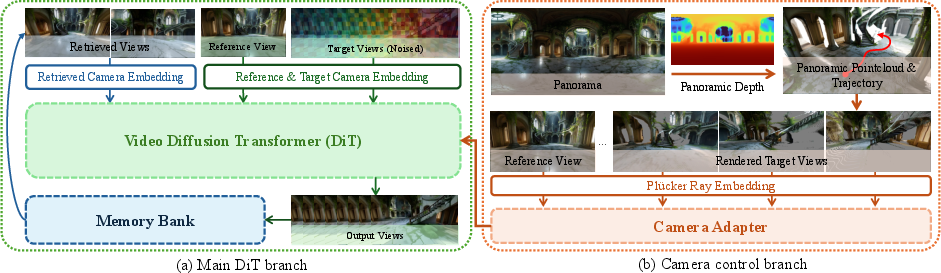
3) World Expansion (WorldStereo 2.0)
- What it does: Generates many new, consistent views along those paths to “fill in” the world with detail.
- Key ideas explained simply:
- Keyframes instead of every frame: Rather than compressing both space and time (which can make things blurry), it focuses on important frames (“keyframes”) to keep details sharp. Think of it like taking the best snapshots instead of a fuzzy video.
- Camera control: It uses rough 3D hints (point clouds and camera rays) as a guide so the generated views match the planned camera path.
- Memory to stay consistent:
- Global-Geometric Memory (GGM): Uses a combined point cloud (a rough 3D “skeleton” of the scene) to keep the overall structure steady across different paths.
- Spatial-Stereo Memory (SSM++): Remembers and re-uses relevant past views to keep fine details (like patterns on a couch) consistent when seen from new angles. It’s like flipping back to earlier photos to ensure the stripes on the sofa stay the same.
- Training in three stages:
- 1) Domain adaptation: Teach the model to follow cameras and generate high-detail keyframes.
- 2) Memory training: Teach it to use global structure and retrieved views to stay consistent.
- 3) Distillation (speed-up): Compress the model to generate results in fewer steps without losing much quality.
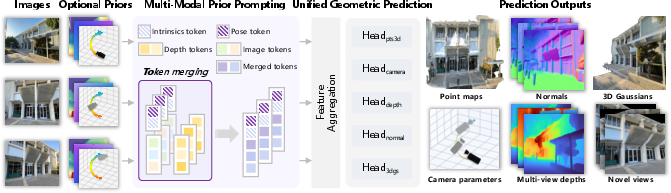
4) World Composition (WorldMirror 2.0)
- What it does: Reconstructs the full 3D world from all the generated (or real) views and outputs 3D Gaussian Splatting (3DGS) assets.
- How it works in everyday terms: A feed-forward model takes multiple images and predicts depth (how far things are), surface directions (normals), camera positions, and a dense point cloud—then converts it into a fast, renderable 3D format (3DGS). It’s like turning a photo album into a navigable 3D diorama.
- Improvements over the earlier version: Better handling of different image sizes, stronger consistency between depth and normals, and more efficient processing of many views.
Bonus: WorldLens (the viewer/renderer)
- What it does: Lets you explore the 3D world interactively. It includes lighting that adapts automatically, collision detection (so characters don’t walk through walls), and works with different engines.
- Think of it as the “game engine” side that makes the 3D world feel real and responsive.
What did they find?
- HY-World 2.0 produces high-quality, explorable 3D worlds from text, single images, multiple images, or videos.
- It achieves state-of-the-art results among open-source systems and comes close to a strong closed-source system called Marble.
- The new panorama generator is smoother and more flexible (no strict camera info needed).
- The planning system covers more of the scene smartly and safely.
- The world expansion model is sharper (thanks to keyframes), more consistent (thanks to memory), and faster (thanks to distillation).
- The reconstruction model is more robust and scalable, making final 3D outputs cleaner and more accurate.
- They release model weights, code, and details to help others reproduce and build on their work.
Why is this important?
- One unified system that can both imagine and rebuild 3D worlds is powerful for many fields: robotics (simulating environments), video games (quickly building levels), VR/AR (creating immersive spaces), and mapping (turning photos into 3D).
- Better consistency and planning mean fewer glitches and more believable worlds.
- Using 3D Gaussian Splatting gives fast, good-looking results that run well in real-time applications.
What could this lead to?
- Faster world building for creators and game studios.
- Safer, more realistic training environments for robots and self-driving systems.
- Better open tools for education and research, since everything is released publicly.
- A stepping stone toward AI that understands and interacts with 3D spaces as easily as we do—expanding from single rooms to large outdoor scenes and even whole cities.
In short, HY-World 2.0 is like giving an AI the ability to both dream up a world from a brief description and carefully rebuild it when given more views—then package it into a form you can walk through, explore, and use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances a multi-stage, offline 3D world model, but several aspects remain uncertain or underexplored. Future work could address the following concrete gaps:
- Panorama generation (HY-Pano 2.0)
- Robustness of the implicit perspective-to-ERP mapping without camera intrinsics across extreme FoVs, tilted/roll angles, and highly off-center inputs is not quantified; failure modes and calibration sensitivity are not characterized.
- Handling of ERP polar distortions and severe parallax near the poles remains unclear beyond circular padding/blending; no analysis of geometric consistency across the full sphere under diverse structures.
- Domain generalization across indoor/outdoor extremes, low-light/high-dynamic-range scenes, reflective/transparent materials, and highly cluttered environments is not reported.
- The balance and impact of real vs. synthetic panoramic data on generalization (and the risk of domain bias) are not ablated; data selection/label noise sensitivity is unstudied.
- Trajectory planning (WorldNav)
- Heuristic planning rules lack principled information-gain objectives; no learning-based or uncertainty-aware planner is used to maximize reconstruction quality or reduce ambiguity.
- Reliance on monocular-depth–derived panoramic meshes/NavMesh may propagate geometric errors (e.g., floaters, scale ambiguity) into trajectories; robustness to wrong geometry/semantics is not evaluated.
- Physical scale and gravity alignment are not established; metric consistency for robotics or simulation use cases (e.g., realistic agent speeds, step heights) is not addressed.
- Coverage guarantees and stopping criteria for large, multi-room or sprawling outdoor spaces are unspecified; single-origin panorama initialization may constrain reachable extent.
- Semantic grounding via Qwen3-VL + SAM3 may hallucinate or miss obstacles; the impact of semantic errors on safety and coverage is not analyzed.
- World expansion (WorldStereo 2.0)
- Keyframe-VAE trades temporal compression for spatial fidelity, but the compute/memory cost and throughput at high resolutions and long sequences are not quantified; scaling limits and deployment requirements are unclear.
- Global-Geometric Memory (GGM) depends on monocular point clouds; failure modes under severe depth errors (thin structures, translucency, specularities, textureless regions) are not characterized.
- SSM++ retrieval policy, selection budget (T_r), and 3D-FoV similarity thresholds are heuristically defined; their effect on detail preservation vs. compute and on long-range consistency is not ablated.
- Cross-trajectory consistency over very long paths and across widely separated viewpoints is not guaranteed; accumulation/drift of appearance/geometry inconsistencies is unquantified.
- Distillation to a 4-step DiT lacks a detailed quality–speed trade-off analysis (e.g., different step counts, failure cases); impact on camera-following precision and fine detail under fast motion is not reported.
- Scene dynamics are not modeled; moving objects and non-rigid changes are out of scope, limiting applicability to dynamic environments.
- World reconstruction (WorldMirror 2.0) and composition
- The feed-forward reconstruction is used on generated views; robustness to generative artifacts (inconsistent textures, small pose errors) and their impact on final 3DGS quality are not quantified.
- Camera parameter estimation/refinement: it is unclear whether bundle-adjustment–style global refinement is performed; how camera drift or misalignment is corrected (if at all) is not described.
- Materials and lighting are not physically modeled; final 3DGS assets likely lack view- and light-consistent reflectance, limiting relighting, PBR workflows, and realism under lighting changes.
- Handling of reflective/transparent surfaces, thin structures, and complex geometry in depth/normal estimation and 3DGS reconstruction remains unaddressed.
- Output assets are 3DGS-centric; availability of watertight meshes, semantic labels, and instance segmentation for downstream robotics/graphics tasks is not discussed.
- Tailored 3DGS optimization “on generated views” is mentioned but not detailed; convergence behavior, failure cases, and trade-offs versus reconstruction from real views are not evaluated.
- System-level considerations and evaluation
- Metric scale calibration and absolute unit consistency across stages (panorama, trajectories, reconstruction, 3DGS) are not validated, which is critical for robotics and physics-based simulation.
- Scalability to very large-scale environments (multi-panorama origins, multi-floor buildings, long outdoor routes) and memory/retrieval management for growing memory banks are not assessed.
- Reliability and uncertainty estimation are not provided; the system does not expose confidence measures to flag hallucinated or low-confidence regions for users or downstream planners.
- Generalization to real-world videos with rolling-shutter, lens distortion, and unknown intrinsics is not studied; robustness to noisy/inaccurate camera metadata is unclear.
- Prompt fidelity (text-to-world) and controllability evaluation (e.g., adherence to specified objects/layouts) are not reported; mechanisms for user-guided corrections or edits are absent.
- WorldLens supports collision detection and IBL, but broader physics (rigid-body dynamics, friction, constraints) and agent–environment interactions are not supported or evaluated.
- Compute efficiency and latency for end-to-end world generation at practical resolutions are not benchmarked; no profiling of bottlenecks (VAE, DiT, memory retrieval, 3DGS optimization).
- Data release status for the UE multi-trajectory synthetic set used for SSM++ training is unspecified; reproducibility of memory training without this data may be limited.
- Comparative evaluation versus closed-source Marble is qualitative in the text; standardized, reproducible benchmarks and public metrics for coverage, geometric accuracy, and render fidelity are not detailed.
- Safety, ethics, and robustness
- Content safety and bias controls for text/image-conditioned world generation are not discussed; potential for generating unsafe or biased environments is unaddressed.
- Privacy/IP considerations for training data sources (especially real panoramas) are not covered.
- Failure handling and fallback strategies (e.g., when depth/semantics are unreliable or the panorama is low quality) are not specified.
Practical Applications
Immediate Applications
These applications can be implemented with the released HY-World 2.0 models (HY-Pano 2.0, WorldNav, WorldStereo 2.0, WorldMirror 2.0) and the WorldLens rendering platform as described in the paper and project page.
- Rapid level blockout and scene prototyping from text or a single image
- Sectors: software/gaming, media & entertainment, XR
- What/how: Use HY-Pano 2.0 to generate a high-fidelity 360° panorama from a prompt or image; plan camera paths with WorldNav; expand views with WorldStereo 2.0; reconstruct a navigable 3DGS scene with WorldMirror 2.0; explore interactively in WorldLens.
- Tools/workflows: “Text-to-level” or “photo-to-level” plug‑ins for Unity/Unreal via WorldLens; asset iteration loops for art directors; fast previz for storyboards and virtual production.
- Dependencies/assumptions: 3DGS needs engine integration or conversion to meshes for some pipelines; dynamic objects and physics are limited; GPU resources for diffusion and 3DGS optimization.
- Virtual production backdrops and environment plates
- Sectors: film/TV/VFX
- What/how: Generate seamless 360° HDR-like panoramas (HY-Pano 2.0) and static explorable environments (3DGS) for LED volumes or compositing; WorldLens supports automatic IBL lighting.
- Tools/workflows: “Prompt-to-panorama” plate generator; 3DGS-to-IBL extraction; WorldLens as an on-set viewer.
- Dependencies/assumptions: Color calibration and dynamic range alignment with capture systems; legal clearance for prompts and inputs; static scene assumption.
- Fast VR/AR environment creation for previews and demos
- Sectors: XR, education, marketing
- What/how: Produce explorable 3D worlds from minimal inputs and deploy via engine-agnostic WorldLens; collision and character support enable basic interaction.
- Tools/workflows: Demo VR walkthroughs; AR occlusion testing using reconstructed depth/point maps from WorldMirror 2.0.
- Dependencies/assumptions: Mobile XR performance constraints; 3DGS runtime support on target devices (or conversion to meshes).
- Autonomous navigation research environments from a single panorama
- Sectors: robotics, embodied AI
- What/how: Use HY-Pano 2.0 to create a full 360° scene; WorldNav generates NavMesh-aware trajectories; WorldStereo 2.0 expands views along these paths; WorldMirror 2.0 reconstructs geometry for training/testing navigation stacks.
- Tools/workflows: Rapid generation of diverse indoor/outdoor environments; dataset augmentation for visual navigation, mapping, and collision avoidance.
- Dependencies/assumptions: Static scenes; sim-to-real gap persists; 3DGS collision fidelity acceptable for agent training but not a substitute for physics engines.
- Site documentation and walkthroughs from casual video
- Sectors: architecture/engineering/construction (AEC), real estate, insurance
- What/how: Feed multi-view images or phone video into WorldMirror 2.0 to get depth, normals, point clouds, camera poses, and 3DGS; visualize in WorldLens.
- Tools/workflows: Quick “scan-to-walkthrough” for listings or claims; export point clouds for measurements; generate marketing media.
- Dependencies/assumptions: Reconstruction accuracy depends on view coverage and input quality; metric accuracy may be insufficient for compliance-critical measurements without calibration.
- Interior design and staging from a single reference image
- Sectors: e-commerce, interior design, real estate marketing
- What/how: HY-Pano 2.0 + WorldStereo 2.0 expand a single image into an explorable room; WorldLens provides lighting and interaction to test layout ideas or virtual furniture placement.
- Tools/workflows: “Photo-to-showroom” landing pages; interactive product staging; quick design previews.
- Dependencies/assumptions: Scene geometry is hallucinated beyond observed regions; not a substitute for CAD/BIM; material properties approximated.
- Curriculum content generation and interactive learning worlds
- Sectors: education
- What/how: Convert textbook images or descriptive prompts into explorable 3D environments for history, geography, and STEM demos.
- Tools/workflows: Lesson-authoring tools that call HY-Pano 2.0 and WorldLens to produce and distribute interactive scenes.
- Dependencies/assumptions: Pedagogical validation; content moderation and bias control for prompt-based generation.
- Cultural heritage virtual tours from public photo collections
- Sectors: museums, tourism, cultural preservation
- What/how: Aggregate multi-view photos into WorldMirror 2.0 for reconstruction; fill gaps with WorldStereo 2.0; publish explorable 3DGS tours via WorldLens.
- Tools/workflows: “Photos-to-tour” pipelines; browser viewers backed by engine-agnostic WorldLens.
- Dependencies/assumptions: Rights management for community images; recon quality varies by coverage; scene dynamics (crowds) may introduce artifacts.
- Data generation for 3D perception research
- Sectors: academia, AI/ML R&D
- What/how: Use the multi-modal pipeline to synthesize paired multi-view imagery, camera poses, depths, normals, and 3DGS assets for training/testing reconstruction and view-synthesis models.
- Tools/workflows: Automated dataset scripts calling WorldNav for coverage; WorldStereo 2.0 for appearance diversity; WorldMirror 2.0 for supervisory signals.
- Dependencies/assumptions: Synthetic-to-real domain gaps; bias from training priors; hardware budgets for large-scale generation.
- Path planning and coverage analysis on novel scenes
- Sectors: robotics, mapping
- What/how: Apply WorldNav to real panoramas for obstacle-aware trajectories and coverage maximization; useful for planning capture routes (e.g., scanning a site) or robot patrol paths in a static scene.
- Tools/workflows: “Panorama-to-coverage-plan” utility; export planned routes for capture teams or sim agents.
- Dependencies/assumptions: Derived geometry from monocular cues; requires validation on-site; static layout assumption.
- Browser-based 3DGS product showcases
- Sectors: retail/e-commerce, marketing
- What/how: Generate explorable product or store environments from a few photos/prompts; use WorldLens’ lighting to present consistent visuals.
- Tools/workflows: “Prompt-to-showroom” microsites; shareable interactive embeds.
- Dependencies/assumptions: 3DGS web viewer availability; licensing and branding controls; static-only scenes.
- Open-source benchmarking and reproducibility in world models
- Sectors: academia, policy (AI transparency)
- What/how: The release of weights and code supports replicable benchmarks for multi-modal 3D world modeling; enables comparative evaluations against closed models.
- Tools/workflows: Standardized evaluation scripts; community leaderboards; ablation studies on memory mechanisms (GGM, SSM++).
- Dependencies/assumptions: Consensus on metrics for “world quality”; compute equity for fair comparisons.
Long-Term Applications
These require further research, scaling, integration with physics/dynamics, or productization beyond what’s described as delivered in HY-World 2.0.
- Safety-critical robotics simulation and policy validation
- Sectors: autonomous vehicles/robots, defense, logistics
- Vision: Text/image-driven generation of large-scale, high-fidelity, dynamic simulation worlds (traffic, pedestrians) for training and validating policies.
- Needed advances: Dynamic agents and realistic physics; controllable semantics; validated metric accuracy; closed-loop online world modeling; domain randomization at scale.
- Dependencies/assumptions: Regulatory acceptance; robust sim-to-real transfer; standardized interfaces to physics engines.
- City-scale digital twins and urban planning engagement
- Sectors: smart cities, public policy, civil engineering
- Vision: Construct explorable, updatable, multi-kilometer worlds from sparse public imagery and plans; use for stakeholder consultation and impact analysis.
- Needed advances: Scalable reconstruction (beyond scenes) with georegistration; temporal updates; efficient streaming of 3DGS or mesh conversions; integration with GIS layers.
- Dependencies/assumptions: Data governance and privacy; compute and storage budgets; interoperability with planning tools.
- Real-time on-device AR world building
- Sectors: consumer XR, mobile platforms
- Vision: Run WorldMirror 2.0–like reconstruction and WorldStereo 2.0–like inpainting on edge devices to build and update personal digital twins of rooms in real time.
- Needed advances: Model distillation and hardware acceleration; memory footprint reduction; online, causal updates; power constraints.
- Dependencies/assumptions: Dedicated NPUs/GPUs on wearables/phones; privacy-preserving on-device inference.
- Personalized therapeutic and training environments
- Sectors: healthcare (rehab, exposure therapy), sports/skills training
- Vision: Generate individualized VR spaces from a photo or short video for graded exposure, motor rehab, or skill drills with precise layouts.
- Needed advances: Clinically validated protocols; controllable difficulty and stimuli; integration with motion analysis; safety guardrails.
- Dependencies/assumptions: Medical device regulation; outcome evidence; robust tracking and latency for immersion.
- Automated content pipelines for live events and sports
- Sectors: media & entertainment
- Vision: Near-real-time reconstruction of venues from multi-view broadcast feeds, fused with generative filling for occluded areas, to create explorable replays.
- Needed advances: Real-time multi-view ingestion; fast and accurate geometry; handling dynamic crowds/players; low-latency rendering.
- Dependencies/assumptions: Rights to feeds; robust dynamic object modeling; streaming infrastructure.
- Self-updating facility twins for maintenance and inspection
- Sectors: energy/utilities, manufacturing, construction
- Vision: Continuous world models of plants/sites reconstructed from periodic walkthrough videos and drones; highlight differences and hazards.
- Needed advances: Change detection, temporal consistency, metric calibration, integration with CMMS/BIM; handling reflective/textureless materials.
- Dependencies/assumptions: Safety-compliant capture; alignment with asset registries; indoor GPS alternatives.
- Insurance, risk assessment, and claims automation
- Sectors: finance/insurance
- Vision: Policyholders upload videos; systems reconstruct spaces, estimate damages/risks with geometry-aware analytics.
- Needed advances: Quantitative accuracy and calibration; material/structural inference; standardized reports; fraud detection.
- Dependencies/assumptions: Regulatory compliance; privacy; adjudication standards acceptance.
- Collaborative 3D world authoring with AI assistants
- Sectors: creative software, productivity
- Vision: Multi-user co-editing of generated worlds, with agents that propose edits, plan trajectories, and perform reconstructions in the loop.
- Needed advances: Versioned world representations; mesh/3DGS interoperability; fine-grained editing controls; human-in-the-loop UX.
- Dependencies/assumptions: Cloud collaboration infrastructure; rights management for generative content.
- Training embodied agents with curriculum worlds
- Sectors: AI research, robotics
- Vision: Automatically generate worlds with progressively harder layouts and tasks (via prompts) to train navigation and manipulation policies.
- Needed advances: Task and affordance annotation; procedural control over semantics; physics-based interactions; reward specification.
- Dependencies/assumptions: Benchmarks for generalization; sim-to-real bridging.
- Consumer “memory palaces” and life logging in 3D
- Sectors: consumer apps, social
- Vision: Turn everyday photos/videos into personal explorable spaces for journaling, sharing, or spatial search.
- Needed advances: Privacy/security, efficient personal indexing, temporal layering to show change, lightweight viewers.
- Dependencies/assumptions: User consent and data protection; device compatibility; content moderation.
- Regulatory and public consultation tools with transparent world models
- Sectors: government, urban policy
- Vision: Use open, auditable world-model pipelines to visualize proposed infrastructure or zoning changes and solicit feedback.
- Needed advances: Traceable data provenance, bias audits of generative priors, integration with official datasets and standards.
- Dependencies/assumptions: Procurement processes; accessibility requirements; governance frameworks.
- Marketplace for 3DGS assets and conversion services
- Sectors: software, creative economy
- Vision: Platforms offering “prompt-to-world,” “photo-to-world,” and “video-to-world” services with quality tiers, plus 3DGS-to-mesh/PBR conversion.
- Needed advances: Robust conversion tools; standardized asset packaging; quality and IP verification.
- Dependencies/assumptions: Demand for 3DGS-native content; legal clarity on AI-generated assets.
Notes on feasibility across applications:
- 3DGS strengths and limits: excellent view synthesis and rendering efficiency but weaker for dynamic physics and precise topologies; mesh conversion often required for downstream CAD/physics-heavy workflows.
- Input quality and coverage: reconstruction and generation quality depend heavily on input diversity and prompt specificity; monocular depth priors may introduce biases.
- Compute and latency: diffusion-based stages are GPU-intensive; post-distillation helps but mobile/on-device use needs further compression.
- Legal/ethical: ensure rights for input media; content moderation for text prompts; privacy when reconstructing personal spaces.
- Evaluation/accuracy: for compliance-critical use (AEC, insurance), metric calibration and validation are required beyond current generative capabilities.
Glossary
- 3D-FoV retrieval: Retrieval strategy based on overlap in 3D fields of view to select relevant frames or keyframes. "for 3D-FoV retrieval."
- 3D Gaussian Splatting (3DGS): A point-based 3D representation that renders scenes using anisotropic Gaussian primitives for fast, high-quality view synthesis. "synthesizing high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes."
- Any-Modal Tokenization: A scheme that encodes heterogeneous inputs (images, poses, intrinsics, depth) into a unified token sequence for a transformer. "Any-Modal Tokenization, which encodes all input modalities, including images, camera poses, intrinsics, and depth maps, as tokens within a unified sequence."
- Autoregressive (AR): A generation paradigm that synthesizes sequences one step at a time using previous outputs as inputs. "Autoregressive (AR) models sequentially generate long videos."
- Bidirectional greedy search: A path construction heuristic that grows from both ends to form a continuous trajectory segment efficiently. "using a bidirectional greedy search."
- Camera intrinsic parameters: Internal camera parameters (e.g., focal length, principal point, FoV) defining projection from 3D to image. "camera intrinsic parameters (e.g, focal length and FoV)"
- Causal padding: Padding scheme that preserves causal ordering (no future information leakage) in encoders/decoders. "causal-padding image encoder"
- Circular padding: A padding technique that wraps feature maps at boundaries to enforce periodic continuity, useful for panoramas. "we apply circular padding to the latent features"
- Cross-attention: Attention mechanism that conditions one sequence of tokens on another (e.g., conditioning generation on guidance). "we freeze the cross-attention and feed-forward layers"
- Diffusion Transformer (DiT): A transformer-based architecture used within diffusion models for image/video generation. "Video Diffusion Transformer (DiT) branch"
- Dijkstra algorithm: A shortest-path algorithm on graphs used for path planning on navigation meshes. "using the Dijkstra algorithm~\cite{dijkstra2022note} on the NavMesh."
- Distribution Matching Distillation (DMD): A distillation method that matches the student’s score distribution to a teacher’s to accelerate diffusion inference. "we apply the modified Distribution Matching Distillation (DMD)~\cite{yin2024improved} to accelerate the inference"
- DPT heads: Dense Prediction Transformer heads used to decode transformer features into pixel-wise predictions. "decoded by multiple DPT heads~\cite{wang2025vggt}"
- Equirectangular projection (ERP): A mapping that represents 360° panoramas by uniformly sampling longitude-latitude onto a rectangle. "the equirectangular projection (ERP) domains."
- Field-of-view (FoV): The angular extent of the observable world captured by the camera. "field-of-view (FoV)"
- GAN loss: Adversarial loss term from Generative Adversarial Networks used to improve realism in generative models. "We omit the GAN loss, as we found its impact to be insignificant while substantially slowing down training."
- Global-Geometric Memory (GGM): A memory mechanism that uses global point clouds as 3D priors to enforce structural consistency across generations. "Global-Geometric Memory (GGM) renders extended point clouds into videos as global 3D priors"
- GPU-accelerated LSMR solver: A GPU-optimized implementation of the Least-Squares Minimal Residual solver for faster large-scale optimization. "via a GPU-accelerated LSMR solver."
- KD-Tree: A k-dimensional tree data structure for efficient nearest-neighbor and range searches, used here for mesh processing. "a KD-Tree accelerated search"
- Keyframe-VAE: A spatial-only variational autoencoder that encodes sparsely sampled keyframes to preserve high-frequency detail. "Keyframe-VAE preserves appearance consistency in reconstructions and substantially improves the fidelity of generated novel views"
- Kullback-Liebler (KL) divergence: A measure of discrepancy between two probability distributions used in variational/distillation objectives. "approximate Kullback-Liebler (KL) divergence"
- Least-Squares Minimal Residual (LSMR): An iterative solver for large sparse least squares problems used to align monocular depth estimates. "Least-Squares Minimal Residual (LSMR) across perspective views"
- Multi-Modal Diffusion Transformer (MMDiT): A diffusion transformer that jointly processes multiple modalities (e.g., images and panorama latents). "a Multi-Modal Diffusion Transformer (MMDiT), as illustrated in \Cref{fig:pano_arch}."
- NavMesh: A polygonal mesh representing traversable areas for agent/camera navigation. "Navigation Mesh (NavMesh) using Recast Navigation"
- Non-Maximum Suppression (NMS): A selection procedure to suppress redundant detections by keeping only representative maxima. "we employ Non-Maximum Suppression (NMS) to extract representative cluster centers"
- Plücker rays: A ray representation in projective geometry capturing lines in 3D space, used for camera ray guidance. "camera Plücker rays~\cite{sitzmann2021light}"
- Ray-casting: A technique that traces rays through a scene to detect intersections, used for collision checks and visibility. "we utilize ray-casting to prevent the camera from clipping into the panoramic mesh."
- Recast Navigation: An open-source library for building navigation meshes and performing pathfinding. "Recast Navigation~\cite{recastnavigation}"
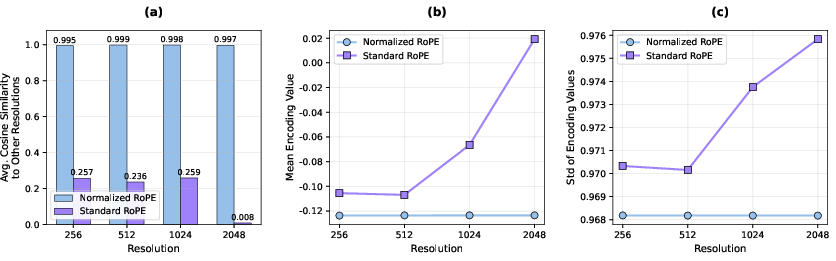
- Rotary Positional Embedding (RoPE): A positional encoding mechanism enabling attention to be aware of relative positions via rotations in embedding space. "Rotary Positional Embedding (RoPE)~\cite{su2024roformer}"
- SAM3: A segmentation model variant used to generate semantic masks from images. "SAM3~\cite{carion2025sam3segmentconcepts} is utilized to yield 2D semantic masks"
- Spatial-Stereo Memory (SSM++): A retrieval-based memory that stitches retrieved-reference and target views to enforce fine-grained correspondence. "the retrieval-based improved Spatial-Stereo Memory (SSM++) for fine-grained consistency."
- Stochastic gradient truncation: A training stabilization technique that truncates gradients to mitigate instability in optimization. "The stochastic gradient truncation~\cite{huang2025self} is employed to stabilize the training phase."
- Trajectory Planning: The process of computing collision-free, informative camera paths through a scene. "Subsequently, the elaborate Trajectory Planning (\Cref{sec:traj_plan}) is performed"
- Variational Score Distillation (VSD): A distillation method that aligns a student’s score function with a teacher’s in diffusion models. "Variational Score Distillation (VSD)~\cite{wang2023prolificdreamer}"
- Video Diffusion Models (VDMs): Diffusion-based generative models that synthesize videos via iterative denoising in a latent or pixel space. "Video Diffusion Models (VDMs)"
- Video-VAE: A variational autoencoder that jointly compresses spatial and temporal dimensions of videos into a latent space. "Unlike (a) Video-VAE, which performs spatio-temporal compression"
Collections
Sign up for free to add this paper to one or more collections.