- The paper introduces WoW, a closed-loop embodied world model that integrates perception, prediction, judgment, reflection, and action to generate physically consistent videos.
- The method employs a diffusion-based DiT backbone enhanced with DINOv2 and an FM-IDM module to translate imagined video predictions into executable robot actions with high success rates.
- The evaluation on WoWBench demonstrates robust generalization and superior performance in physical reasoning, achieving state-of-the-art metrics in instruction understanding and law adherence.
WoW: Towards a World-Omniscient World Model Through Embodied Interaction
Introduction and Motivation
The WoW model addresses a central limitation in current video generative models: the lack of genuine physical intuition and causal reasoning, which arises from training on passively observed data. Unlike models such as Sora, which excel at photorealism but often fail at physical consistency, WoW is trained on 2 million real-world robot interaction trajectories, explicitly grounding its predictions in causally rich, embodied experience. The core hypothesis is that authentic physical understanding in AI requires large-scale, interactive data, not just passive observation.

Figure 1: WoW integrates perception, prediction, judgement, reflection, and action, learning from real-world interaction data to generate physically consistent robot videos in both seen and out-of-distribution scenarios.
World Model Foundations and Embodied Intelligence
WoW builds on the tradition of world models in model-based RL, extending the paradigm from latent state-space models (e.g., Dreamer, PlaNet) to high-fidelity, action-conditioned video generation. The model formalizes the world model as a transition function fθ that predicts future states st+1 given current state st, action at, and plan pt, operating in a compressed latent space for high-dimensional sensory inputs.
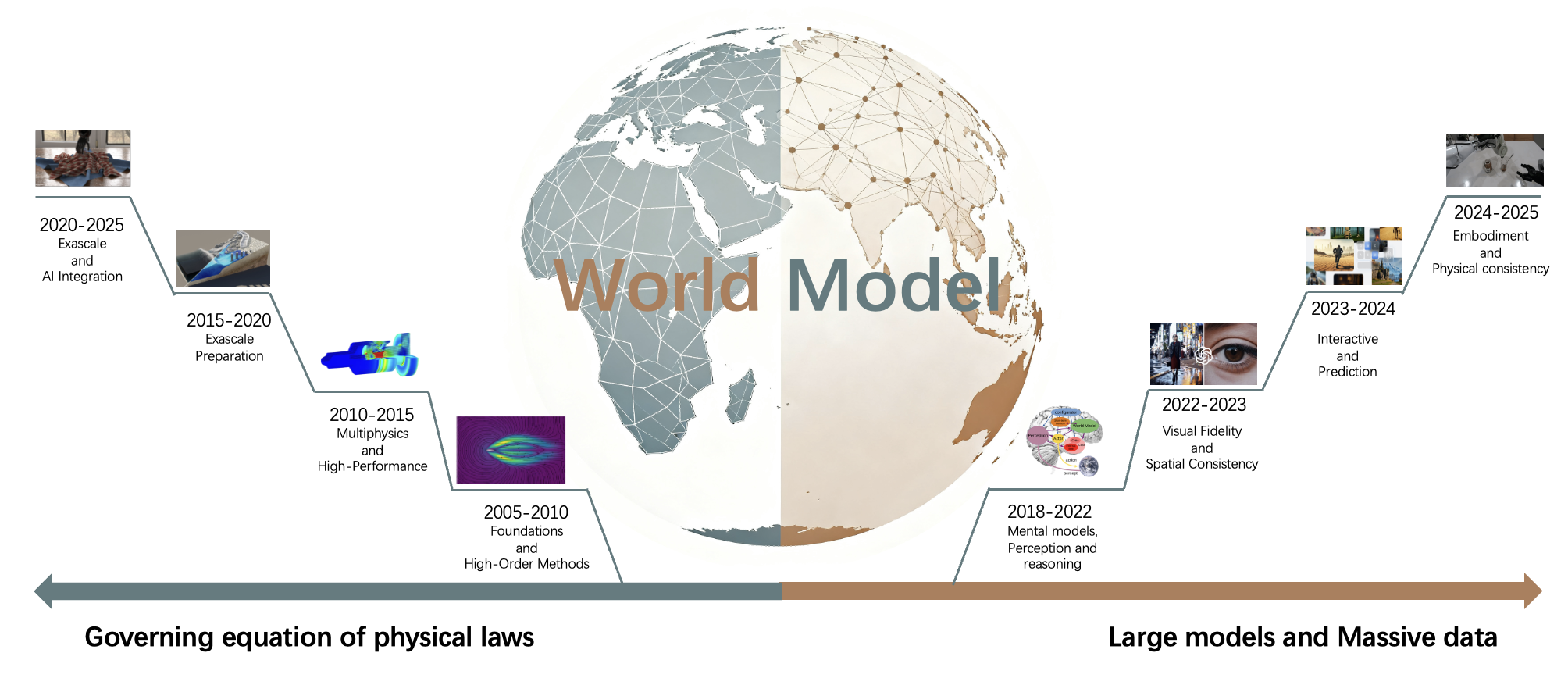
The paper situates WoW within the broader evolution of world models, contrasting two main approaches for achieving intrinsic physical consistency:
The architecture of an embodied agent with a world model is conceptualized as a closed-loop system, where perception, memory, reasoning, and action are tightly integrated.
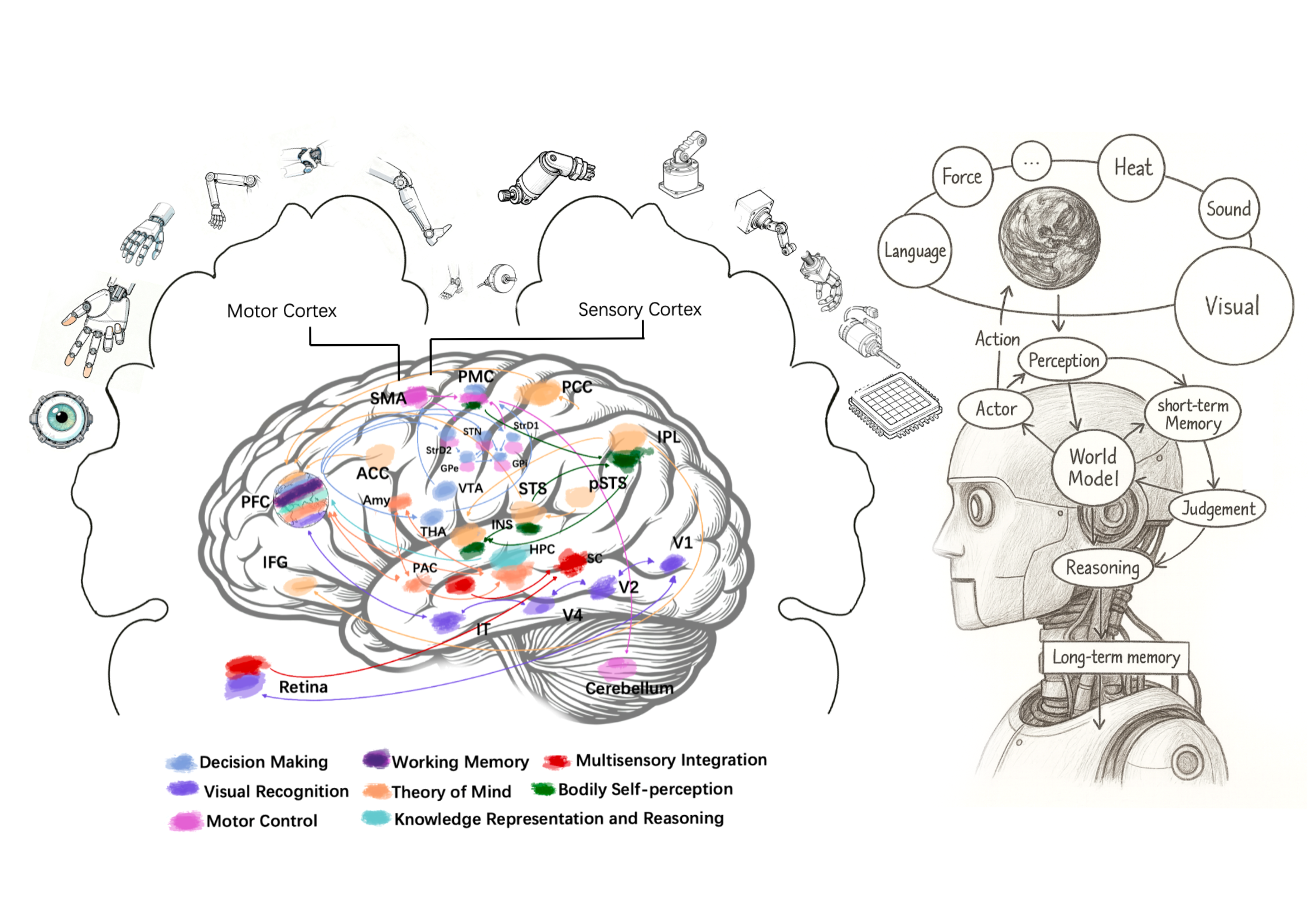
Figure 3: An embodied agent perceives, predicts, reasons, and acts via an internal world model, enabling planning and execution in complex environments.
SOPHIA Paradigm and WoW Architecture
WoW is instantiated within the SOPHIA (Self-Optimizing Predictive Hallucination Improving Agent) paradigm, which unifies imagination, reflection, and action in a closed-loop framework. The architecture consists of three main stages:
- Task Imagination: A diffusion-based video generation model (DiT backbone) predicts future frames conditioned on initial observations and language instructions.
- Experience Reflection: A vision-LLM (VLM) agent acts as a critic, evaluating the physical plausibility of generated videos and providing structured feedback.
- Behavior Extraction: A Flow-Mask Inverse Dynamics Model (FM-IDM) translates imagined video trajectories into executable robot actions.
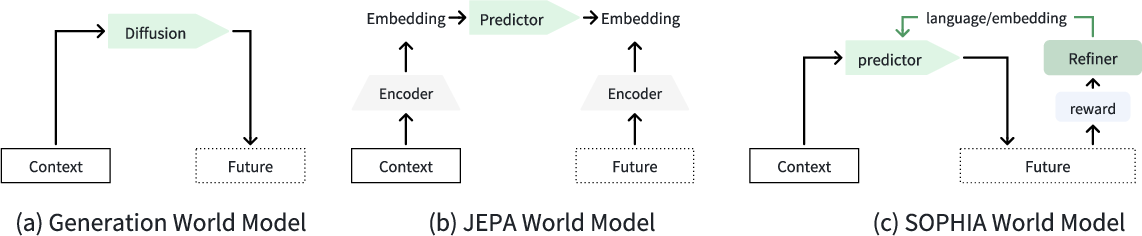
Figure 4: Comparison of Diffusion, JEPA, and SOPHIA. SOPHIA introduces a closed-loop of prediction, critique, and refinement, guided by language and embedding feedback.
The video diffusion world model leverages a large, curated dataset of robot interactions, with careful filtering, caption refinement, and task rebalancing to ensure both diversity and quality. The DiT backbone is enhanced with DINOv2 features for improved spatial-temporal modeling, and training is supervised via a token relation distillation loss.
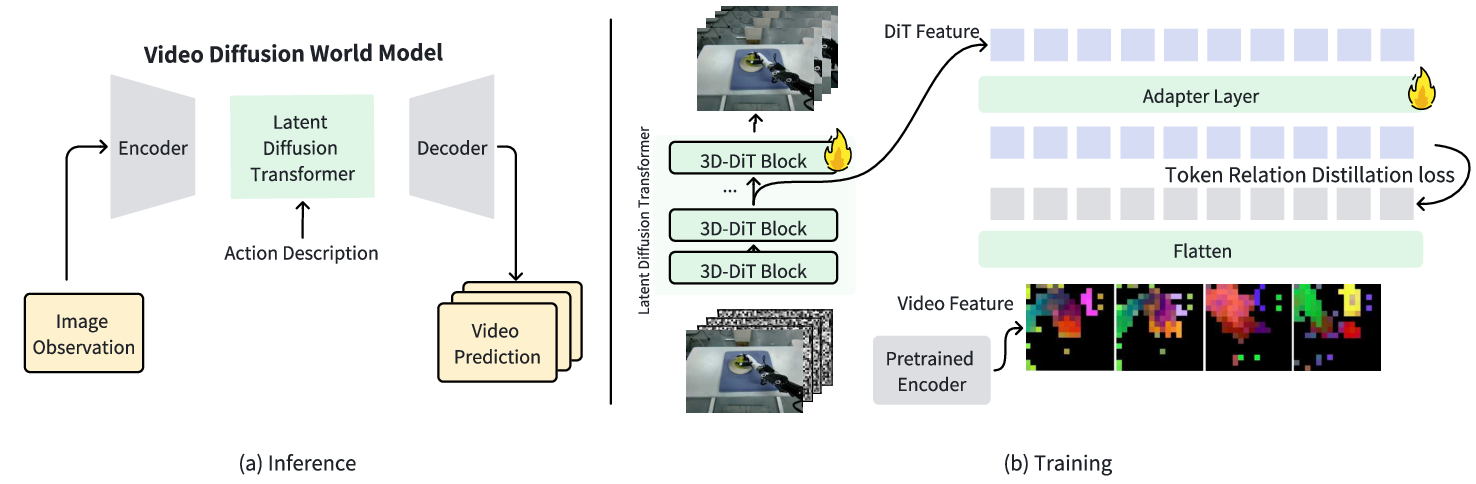
Figure 5: (a) Inference: latent diffusion transformer predicts future frames from images and text. (b) Training: DINO features supervise DiT representations for better spatial-temporal modeling.
Closed-Loop Generation: Solver-Critic Agents
A key innovation is the solver-critic agent system, which iteratively refines video generations. The Refiner Agent rewrites prompts based on feedback from a Dynamic Critic Model Team (fine-tuned VLMs), forming a closed-loop optimization process. This enables the model to converge on physically plausible, semantically correct outcomes without retraining the generative backbone.
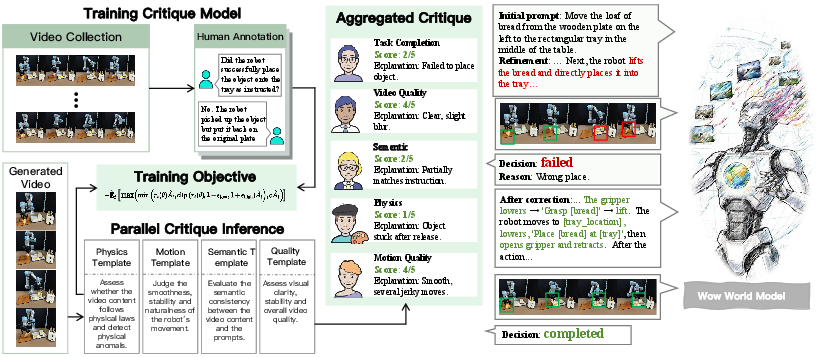
Figure 6: Left: Dynamic Critic Model Team evaluates physical plausibility. Right: Refiner Agent iteratively rewrites prompts and regenerates videos, closing the loop.
This architecture operationalizes the Prover-Verifier paradigm in high-dimensional, continuous video generation, optimizing for non-differentiable objectives such as "physical realism" through structured, language-based feedback.
Imagination-to-Action: Flow-Mask Inverse Dynamics Model
The FM-IDM module bridges the gap between imagined futures and real-world execution. Given two predicted frames, it estimates the delta end-effector action required for the robot to realize the transition. The model uses a two-branch encoder-decoder: one branch processes the masked current frame (via SAM), the other processes optical flow (via CoTracker3), and both are fused with DINO features before an MLP head predicts the 7-DoF action.
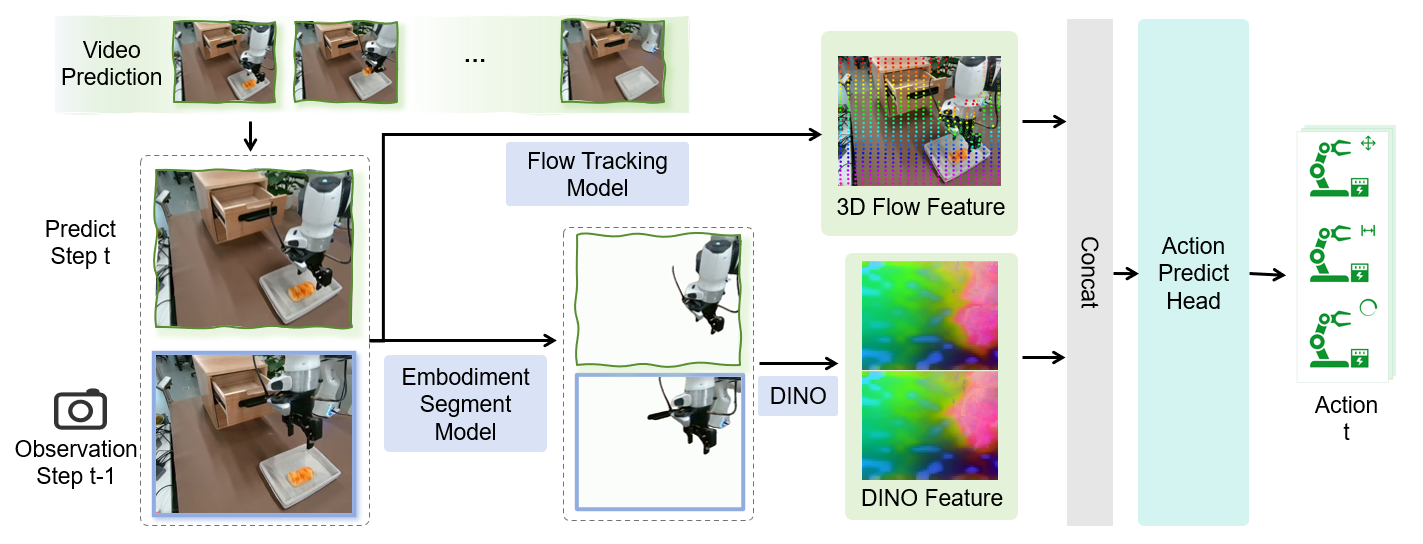
Figure 7: FM-IDM estimates the delta end-effector action from two predicted frames, enabling translation of imagined trajectories into executable robot actions.
This approach generalizes across tasks, backgrounds, and occlusions, and is robust to noise in video-based prediction.
WoWBench: Benchmarking Physical Consistency and Causal Reasoning
WoWBench is introduced as a comprehensive benchmark for embodied world models, focusing on four core abilities: Perception, Planning, Prediction, and Generalization. The benchmark includes 606 samples across 20 sub-tasks, with multi-faceted metrics for video quality, planning reasoning, physical rules, and instruction understanding. Evaluation combines automated expert models and human-in-the-loop assessment.
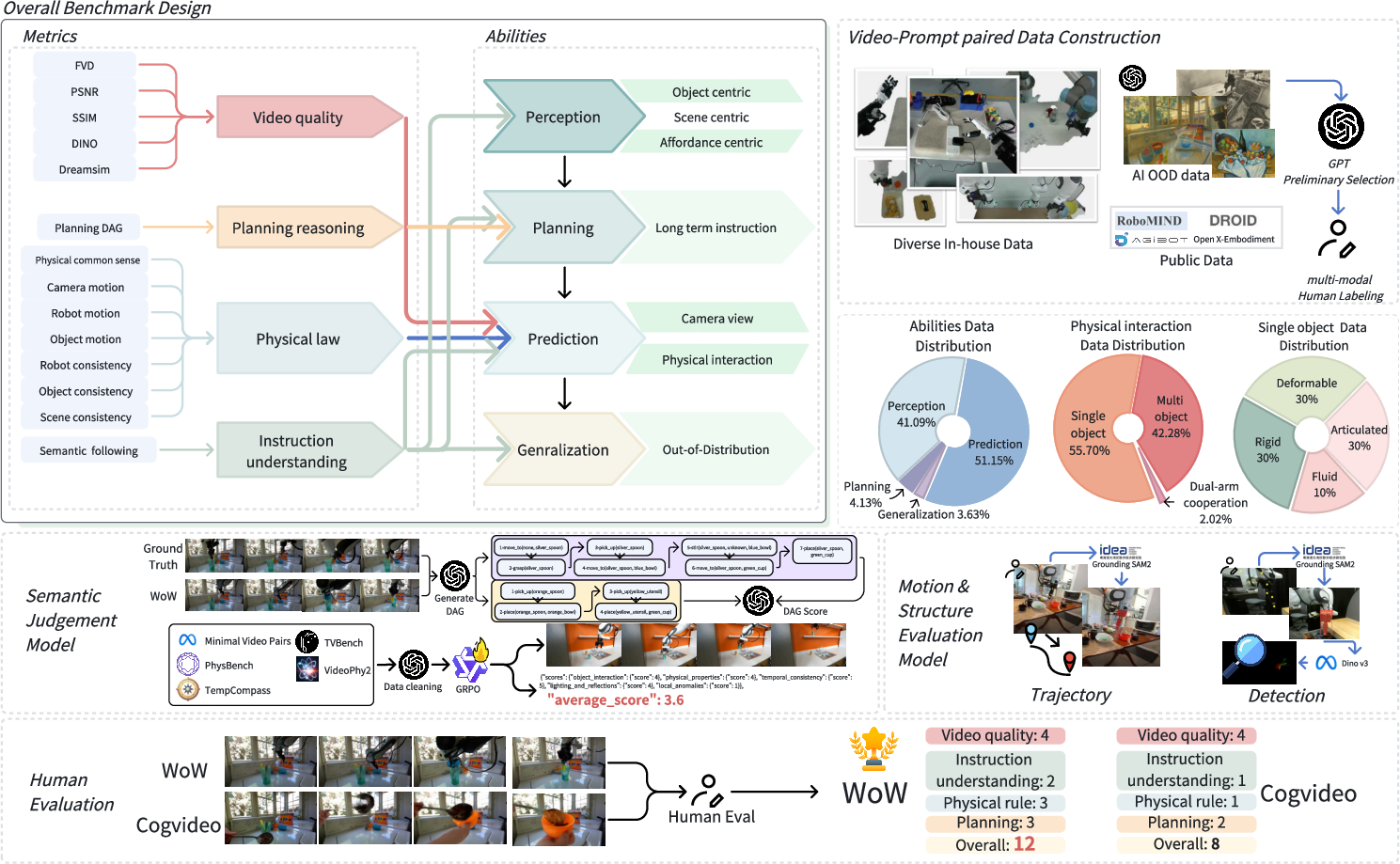
Figure 8: WoWBench structure: metrics suite, core abilities, data construction pipeline, evaluation methods, and human expert assessment.
Metrics include standard video quality measures (FVD, SSIM, PSNR), mask-guided regional consistency, instruction understanding (via GPT-4o), physical and causal reasoning (trajectory consistency, physical common sense), and planning (DAG-based key-step recall, precision, and sequential consistency).
Experimental Results and Scaling Laws
WoW achieves state-of-the-art performance on WoWBench, with particularly strong results in instruction understanding (96.53%) and physical law adherence (80.16%). Scaling analysis reveals:
- Data Scaling: Performance improves with more data, especially on hard tasks, with no saturation observed up to 2M samples.
- Model Scaling: Larger models (up to 14B parameters) yield better performance, but with diminishing returns and increased inference cost.
- Generalization: WoW generalizes across robot embodiments, manipulation skills, and visual domains (including OOD styles and objects) without fine-tuning.
Real-World Robotic Execution
The FM-IDM enables high success rates in real-world robot manipulation: 94.5% on easy, 75.2% on medium, and 17.5% on hard tasks, outperforming all baselines. Fine-tuning is critical for bridging the sim-to-real gap, and WoW's plans can be directly executed on physical robots, demonstrating robust grounding of imagined physics.
Advanced Reasoning and Applications
WoW demonstrates counterfactual reasoning (e.g., simulating failed lifts for "impossibly heavy" objects), tool-use generalization via iterative prompt refinement, and logical compositionality (handling negation and conditionals in instructions). The model also supports novel-view synthesis, trajectory-guided video generation, action-to-video generation, and visual style transfer for data augmentation.
WoW can serve as a cognitive sandbox for VLM planners, enabling iterative self-correction and dramatically improving planning and task success rates in complex, ambiguous tasks.
Conclusion
WoW represents a significant advance in embodied world modeling, integrating perception, imagination, reflection, and action in a closed-loop, physically grounded architecture. The model's strong empirical results on WoWBench, robust generalization, and real-world deployment capability provide compelling evidence for the necessity of large-scale, interactive data in developing physical intuition in AI. The closed-loop solver-critic framework, FM-IDM for imagination-to-action, and comprehensive benchmarking set a new standard for evaluating and developing world models.
Future directions include further scaling of data and model size, improved memory and temporal consistency mechanisms, and tighter integration with downstream embodied agents for autonomous, open-ended learning and reasoning.