The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
Abstract: We present WorldCanvas, a framework for promptable world events that enables rich, user-directed simulation by combining text, trajectories, and reference images. Unlike text-only approaches and existing trajectory-controlled image-to-video methods, our multimodal approach combines trajectories -- encoding motion, timing, and visibility -- with natural language for semantic intent and reference images for visual grounding of object identity, enabling the generation of coherent, controllable events that include multi-agent interactions, object entry/exit, reference-guided appearance and counterintuitive events. The resulting videos demonstrate not only temporal coherence but also emergent consistency, preserving object identity and scene despite temporary disappearance. By supporting expressive world events generation, WorldCanvas advances world models from passive predictors to interactive, user-shaped simulators. Our project page is available at: https://worldcanvas.github.io/.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces WorldCanvas, a way to “paint” short, controllable video events using three kinds of input together:
- Text (what should happen),
- Trajectories (where and when things move),
- Reference images (who or what appears).
The goal is to let people create small “world events” that look realistic and make sense over time—like a person walking in, waving, and leaving—by simply describing the action, drawing paths for motion, and dropping in pictures of the characters or objects.
What questions did the researchers ask?
They wanted to know:
- How can we give users fine-grained control over video events so they can specify what happens, where it happens, when it happens, and who is involved?
- Why isn’t text alone good enough for complex events with multiple moving objects?
- How can we tie text (the story), trajectories (the motion path), and reference images (the look) together so the video follows the plan?
How did they do it?
Think of the world as a digital canvas and the event as a scene you direct. WorldCanvas uses three inputs that work like different tools:
- Trajectories: These are like sketching a dotted line that shows where a toy car should drive. The spacing of the dots tells you how fast it moves; visibility flags say if it’s on screen, hidden, or entering/exiting.
- Reference images: These are like stickers you place on the canvas to define the exact look of a character or object (a specific dog, a certain car).
- Text: This is the script that explains what each character or object should do (e.g., “the dog runs to the ball, the girl waves”).
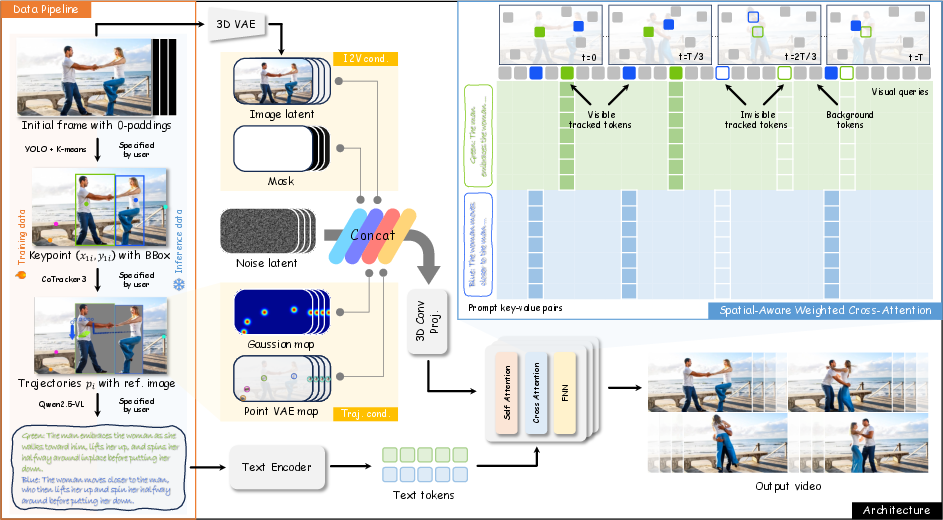
To make this work, the team built a data pipeline and a model:
- Data pipeline (collecting and preparing examples):
- They gathered many short video clips and tracked key points (like the center of an object) over time to create trajectories, using tools that detect objects and follow them frame by frame.
- They made motion-focused captions by showing colored trajectories and asking a vision-LLM to describe each motion clearly (who moves, how, and where), not just the overall scene.
- They extracted and slightly transformed reference images of the main objects (like cropping and rotating them) so the model learns to match images to motion and text.
- Random cropping simulated objects leaving and re-entering the frame, teaching the model about entry/exit.
- Model (turning inputs into video):
- Trajectory injection: The model gets extra channels that represent the drawn paths as soft “heatmaps” (think of glowing trails) and a small “point map” that helps it remember and animate specific points across frames.
- Spatial-Aware Weighted Cross-Attention: In plain terms, this is a smart matching system. It makes the text about a specific object pay more attention to the part of the video near that object’s trajectory. Imagine each caption shines a spotlight on the region where its character moves so actions don’t get mixed up between multiple subjects.
- Training: They trained on a large set of trajectory–text–reference examples, using a technique that teaches the model to transform random noise into a realistic video step by step. You can think of this like learning to “un-blur” a picture into a clear scene, guided by the inputs.
- Inference (how users control it):
- You can set when a motion starts and ends (timing).
- You can draw the motion with a series of points (shape and speed).
- You can mark parts of the path as visible or hidden (occlusions, entry/exit).
- You can attach a specific caption to a specific trajectory (so the right character does the right action).
- You can place reference images on the canvas to pick the exact look of your subjects.
What did they find and why is it important?
Main findings:
- WorldCanvas can generate videos where multiple subjects follow different paths and actions without mixing them up. It performs better than strong baselines at matching user-drawn trajectories, keeping subjects and backgrounds consistent, and aligning the video with the text descriptions.
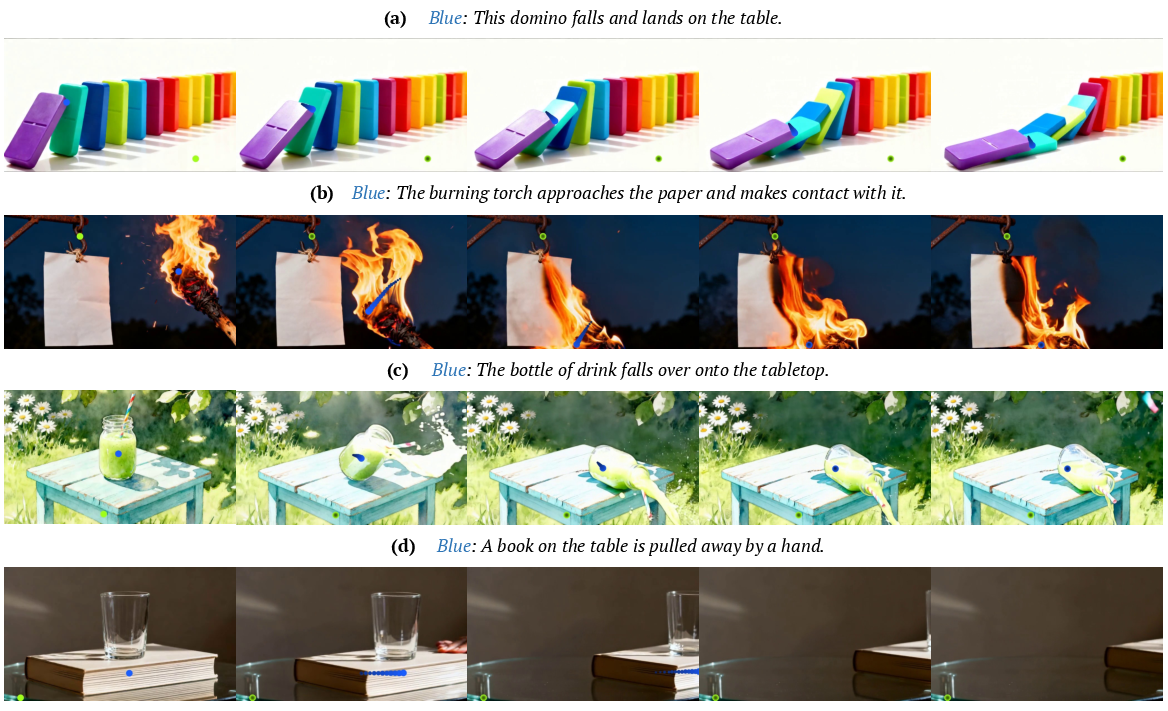
- It handles tricky cases like objects entering or leaving the frame, and it remembers what things look like even if they disappear and reappear (identity and scene consistency).
- The special attention method (Spatial-Aware Weighted Cross-Attention) clearly improves how the model ties the right text to the right motion when there are multiple agents.
Why this matters:
- Text alone often can’t capture “who does what, where, and when,” especially with multiple moving things. This multimodal approach gives creators precise control.
- The model shows signs of “world understanding,” like physical plausibility and causal reasoning in some scenarios (for example, knocking over dominoes or liquid spilling if a bottle tips), which is useful for interactive simulations, education, and game design.
What’s the impact and what could happen next?
Implications:
- For creators: You can direct complex scenes by drawing paths, adding characters via images, and writing short instructions, instead of doing heavy animation work.
- For interactive world models: This approach turns passive “video prediction” into active “video simulation,” where users can shape the events.
- For training agents or testing ideas: More realistic and controllable video worlds can help research in robotics, games, and AI planning.
Potential next steps:
- Handling very complex camera motions and deeper off-screen reasoning (the paper shows some failure cases here).
- Expanding to longer, more detailed stories with many agents.
- Making the user interface even easier (like drag-and-drop timelines or more intuitive path drawing).
Overall, WorldCanvas is a practical step toward letting people “paint” what happens in a video world using simple, understandable controls—text, paths, and images—so the world behaves the way they intend.
Knowledge Gaps
Here is a concise list of concrete knowledge gaps, limitations, and open questions that the paper leaves unresolved:
- Dataset availability and reproducibility: The curated 280k trajectory–video–text triplets are not described as publicly released; details on licenses, splits, annotation protocols, and reproducibility (including seeds, preprocessing, and tool versions) are missing.
- Annotation quality and bias: The pipeline relies on YOLO, SAM, CoTracker3, and Qwen2.5-VL outputs; there is no quantitative audit of detection/tracking/caption errors, no human verification rate, and no study of how such noise/bias propagates into training and inference.
- Benchmarking gap: There is no standardized, publicly available benchmark for multi-agent text–trajectory–reference control (with long-horizon, entry/exit, occlusion), making it hard to compare methods; the paper’s 100-pair test set is small, privately constructed, and not released.
- Metric validity: Key metrics (ObjMC, Appearance Rate, CLIP-T) are acknowledged as imperfect; there is no proposed replacement or validated metric for fine-grained motion–text alignment, visibility correctness, or causal/physical plausibility, nor statistical significance testing.
- Long-horizon evaluation: The approach is not evaluated on long-duration videos, multi-event chains, or shot changes; limits on temporal coherence over minutes and across multiple user-invoked events are unknown.
- Scalability to many agents: The method’s computational and qualitative behavior as the number of controlled agents increases (e.g., attention cost, interference, identity swaps, text–trajectory binding failures) is not characterized; no maximum supported N is reported.
- 2D-only control: Trajectories are 2D and tied to image-space; the method does not handle 3D trajectories, depth-aware control, or explicit camera path inputs, which appear critical for large viewpoint changes and 360° motions (a known failure case).
- Static first-frame bounding boxes: Spatial-Aware Weighted Cross-Attention uses first-frame bboxes to define ROIs; there is no handling of dynamic scale/pose changes, camera motion, or subject leaving/re-entering FOV with different sizes/poses, nor learned/adaptive ROIs.
- Sensitivity analysis: The attention bias hyperparameter (w=30), ROI size, and per-layer placement of spatial weighting lack sensitivity studies; robustness to mis-specified bboxes or trajectory timing is not evaluated.
- Trajectory injection ablation: The contributions of Gaussian heatmaps vs. point VAE maps (kernel size, bandwidth, sparsity), and the role of background points and visibility flags, are not ablated; the minimal representation needed for precise control is unclear.
- Robustness to noisy inputs: It is unknown how the system behaves with imperfect user inputs (jittery or sparse trajectories, conflicting/ambiguous text, wrong visibility flags); there is no arbitration policy for text–trajectory conflicts or uncertainty handling.
- Reference image limits: The approach assumes reference insertion in the first frame and mild affine transforms; scaling to multiple references per class, large pose/illumination/domain shifts, background mismatch, and identity disambiguation among similar instances are not addressed or quantified.
- Identity consistency stress tests: Consistency is shown qualitatively, but not systematically evaluated under challenging conditions (long occlusions, costume/lighting changes, re-entry after long gaps, heavy interactions).
- Physical and causal correctness: Claims of physical plausibility and causal reasoning are qualitative; there is no objective evaluation on physics/causality benchmarks or constraint-checkers (e.g., contact, conservation, continuity), nor mechanisms to enforce physical constraints.
- Collision and interaction modeling: The method does not incorporate object-level states or physics priors; how it handles collisions, contact ordering, and multi-agent interaction outcomes remains an open design and evaluation question.
- Integration into closed-loop world models: Although claimed compatible, there is no demonstration of persistent state across events, agent-in-the-loop control, or impact on downstream tasks (e.g., RL training, planning, data augmentation for policy learning).
- Efficiency and interactivity: Inference latency, memory footprint, and throughput on consumer GPUs are not reported; there are no techniques explored for real-time interactivity (e.g., streaming decoding, token pruning, partial updates).
- UI/authoring workflow: Concrete protocols for mapping text spans to trajectories at scale, resolving ambiguous language, supporting many-to-many text–trajectory bindings, and providing feedback/corrections to users are not described or evaluated.
- Generalization across domains and languages: The system’s robustness to OOD content, specialized domains (e.g., scientific/medical), and multilingual prompts is untested; cross-lingual text–trajectory binding remains open.
- Video editing vs. I2V: The method is built on image-to-video; applicability to editing existing videos (preserving background while enforcing controlled events) is not explored or evaluated.
- Failure mitigation strategies: Known failures (360° rotation blur, incorrect long-interval reasoning like cumulative water fill) lack proposed remedies (e.g., camera-trajectory conditioning, explicit memory modules, physics-regularized objectives).
- User study scope: The human evaluation uses 15 participants and 20 (+10 reference) cases; there is no assessment of inter-rater reliability, power analysis, or release of evaluation protocols/stimuli for replication.
- Data distribution and bias: Filtering out low-motion clips biases the dataset toward dynamic scenes; the impact on generalization to subtle/slow events and on fairness across subjects and settings is unexamined.
- Safety and ethics: The system can synthesize counterfactuals and identity-controlled content via references, but there are no guardrails for harmful content, privacy/consent handling for reference images, attribution/watermarking, or misuse mitigation.
- Releasing artifacts: Code, trained weights, interactive interface, and detailed training recipes (hyperparameters, schedules, augmentations) are not committed for release, limiting independent validation and extension.
Practical Applications
Immediate Applications
The following applications can be deployed with current capabilities of trajectory+text+reference-controlled image-to-video generation, assuming access to a modern I2V backbone (e.g., Wan 2.2) and the presented trajectory/text/reference interfaces.
- Media previsualization and storyboarding
- Sector: Film/TV, Advertising, Game studios
- What: Turn shot lists and beat sheets into animatics by dragging reference characters/props onto a canvas and sketching trajectories tied to action text (e.g., “actor A walks to door; car enters from right, stops”).
- Tools/Workflows: “Canvas-to-animatic” plugin for NLEs; Previs web app where producers draw paths, attach dialog/action text, and drop reference frames from costume/prop lookbooks.
- Assumptions/Dependencies: GPU inference budget; licensing of the base I2V model; production-grade UI for trajectory editing; content usage rights for reference images.
- Motion graphics and explainer video generation
- Sector: Marketing, Education, Enterprise training
- What: Create explainer clips by binding text instructions to paths (e.g., arrows/labels that move along a process line; reference product rotating then moving into exploded view).
- Tools/Workflows: PowerPoint/Keynote/Canva plugin to “animate by path + prompt” with reference logos/products.
- Assumptions/Dependencies: Brand safety, logo/license compliance; simple camera motion preferred for fidelity.
- Social media “draw-to-animate” creation
- Sector: Consumer apps, Creator economy
- What: Users place their pet/friend’s photo as reference and draw comic trajectories (“jump, spin, exit left”).
- Tools/Workflows: Mobile app feature with touch trajectories, visibility toggles for occlusion/entry/exit.
- Assumptions/Dependencies: On-device/offline lightweight inference or server-side GPU; misuse moderation.
- Synthetic data generation for video understanding
- Sector: Software/AI, Retail analytics, Security analytics
- What: Generate long-tail scenarios (occlusions, identity re-entry, multi-agent interactions) to augment datasets for tracking, re-identification, and event detection.
- Tools/Workflows: Data engine that programmatically samples trajectories, visibility flags, and reference identities with motion-focused prompts.
- Assumptions/Dependencies: Domain gap from synthetic-to-real; labeling pipelines; content safety and realism checks.
- Sports coaching and play visualization
- Sector: Sports tech, Education
- What: Animate drills or tactics by specifying player trajectories and roles (e.g., “striker runs near post; winger crosses”).
- Tools/Workflows: Coaching whiteboard app upgraded with video synthesis; export to training reels.
- Assumptions/Dependencies: Team/league IP permissions for likenesses; limited physics realism.
- UI/UX demo generation
- Sector: Software, Product design
- What: Produce product walkthrough videos by dragging UI screenshots as references and scripting cursor/gesture trajectories with text (“hover reveals tooltip; modal slides in”).
- Tools/Workflows: Design-system plugin (Figma/Sketch) to generate demo videos from flows and motion paths.
- Assumptions/Dependencies: High-res reference UIs; deterministic timing control; sensitive data redaction.
- Safety and compliance micro-training
- Sector: Manufacturing, Energy, Logistics
- What: Short clips demonstrating correct/incorrect motions (e.g., forklift routes, lock-out/tag-out steps) by attaching action text to path timing and visibility (occlusion behind shelves).
- Tools/Workflows: LMS content generator with trajectory templates for common procedures.
- Assumptions/Dependencies: Domain-accurate props/PPE references; expert review for correctness.
- E-commerce product showcases
- Sector: Retail, D2C
- What: Reference product images animated along paths (unboxing flow, rotation, placement into context) guided by copy text.
- Tools/Workflows: Merchant dashboard “animate SKU by path” to produce product hero videos at scale.
- Assumptions/Dependencies: Background consistency at scale; brand identity protection.
- Robotics imitation video synthesis (visual demonstrations)
- Sector: Robotics R&D, Academia
- What: Generate visually consistent demonstrations from language+paths (e.g., “gripper moves here, picks cup, places on tray”) to train vision-language imitation pipelines that learn from pixels.
- Tools/Workflows: Data augmentation for behavior cloning from video, with automatic masking/visibility events.
- Assumptions/Dependencies: Sim-to-real gap; 2D video lacks depth/forces; needs domain randomization.
- Education content for physics and causality
- Sector: K-12 and Higher Ed
- What: Create short clips showing cause→effect narratives (dominoes, fluids, friction) by controlling the “cause” trajectory and letting the model render outcomes.
- Tools/Workflows: Interactive lesson builder with path drawing and promptable events (e.g., “torch approaches paper”).
- Assumptions/Dependencies: Physical plausibility is approximate; teacher review required.
- Urban wayfinding and crowd management visuals
- Sector: Transportation, Venues, Events
- What: Visualize pedestrian flows, entry/exit patterns, or vehicle ingress/egress using paths with timed visibility to show occlusion and re-entry.
- Tools/Workflows: Event-planning toolkit that exports guidance videos for staff/visitors.
- Assumptions/Dependencies: Real-world fidelity of densities/flows is limited; use for communication, not engineering.
- Forensics-style event reconstruction (communication aid)
- Sector: Legal, Insurance, Security
- What: Produce explanatory visuals of hypothesized trajectories with identity-stable references (vehicles, persons) to brief stakeholders.
- Tools/Workflows: “Trajectory-based reenactment” storyboard generator for reports.
- Assumptions/Dependencies: Must be labeled as illustrative; not evidentiary; strict governance to avoid bias/misuse.
- Video editing: insert-and-animate objects
- Sector: Post-production, Creator tools
- What: Add a referenced subject into existing footage and guide motion via trajectories while preserving identity across occlusions.
- Tools/Workflows: NLE plugin that ingests a clip and a reference cut-out, then animates along user paths.
- Assumptions/Dependencies: Compositing quality depends on background consistency; license clearance.
Long-Term Applications
The following require further research, scaling, domain adaptation, or integration with 3D/physics/world models before reliable deployment.
- Interactive world-model simulators for agent training
- Sector: Robotics, Autonomous systems, RL research
- What: Closed-loop, promptable video worlds where agents act and environments respond, using text+trajectory+reference as controllable interfaces for multi-agent scenarios.
- Tools/Workflows: “World canvas” front-end coupled with differentiable world models for planning and policy learning.
- Assumptions/Dependencies: 3D consistency, causal dynamics, and real-time inference; safety for autonomous training.
- Rare-event synthesis for AV safety validation
- Sector: Automotive, Insurance, Policy
- What: Generate diverse adverse scenarios (pedestrian dart-out, occluded bicyclist, emergency vehicles) with precise timing/visibility for sensor simulators and perception testing.
- Tools/Workflows: Scenario authoring layer that exports to AV sim stacks; coverage-driven generation.
- Assumptions/Dependencies: Multi-sensor realism (LiDAR/RADAR), 3D geometry and traffic rules; regulatory acceptance.
- Digital twins with promptable incident playbooks
- Sector: Smart factories, Energy plants, Warehousing
- What: Author and “play” incident response sequences by drawing team/equipment trajectories and specifying procedural text, generating communicative video overlays over twin dashboards.
- Tools/Workflows: Digital-twin orchestration with a video layer for what-if and training scenarios.
- Assumptions/Dependencies: Integration with operational data; temporal alignment with telemetry; security constraints.
- Healthcare training and patient education
- Sector: Healthcare, MedEd
- What: Videos depicting tool/tissue interactions or rehab exercises by binding instrument/limb trajectories to step-wise instructions and identity-stable anatomical references.
- Tools/Workflows: Surgical and PT scenario builders; anatomy-grounded reference libraries.
- Assumptions/Dependencies: Domain-specific datasets, stringent clinical validation, consent/IP for references.
- Architecture and urban planning scenario communication
- Sector: AEC, Urban policy
- What: Visualize proposed street designs, evacuation routes, or micromobility flows (multi-agent, occlusions) for stakeholders.
- Tools/Workflows: CAD/BIM integration to export plans into promptable event videos.
- Assumptions/Dependencies: Accurate scale, crowd dynamics, and 3D camera control; governance for public use.
- Game AI and tools for emergent narrative control
- Sector: Gaming
- What: Author multi-agent events by binding NPC behaviors to trajectories and localized prompts; auto-generate cutscenes with identity-consistent references.
- Tools/Workflows: Level editor “event painter”; runtime hooks for AI directors.
- Assumptions/Dependencies: Real-time performance; 3D-to-2D style transfer; IP and modding policies.
- Policy communication and risk visualization
- Sector: Government, NGOs
- What: Communicate regulations or emergency procedures via synthesized scenes with timed agent entries/exits (e.g., shelter-in-place, evacuation).
- Tools/Workflows: Public-information content factory with templated scenarios.
- Assumptions/Dependencies: Accessibility standards, cultural context adaptation, misinformation safeguards.
- Human-robot collaboration rehearsal
- Sector: Manufacturing, Logistics
- What: Simulate worker and robot paths with textual task bindings to explore collision risks and timing before floor deployment.
- Tools/Workflows: HRC prototyping studio linking path plans to synthesized previews.
- Assumptions/Dependencies: Accurate 3D kinematics and safety envelopes; alignment with actual controllers.
- Real-time AR authoring and in-situ overlays
- Sector: AR/VR, Field service
- What: Draw trajectories in AR to guide tools or show parts motion; overlay prompt-driven events on live scenes with reference object anchoring.
- Tools/Workflows: AR app with “draw-and-prompt” authoring and occlusion-aware video synthesis.
- Assumptions/Dependencies: Low-latency on-device models, robust tracking/SLAM, safety.
- Finance and operations scenario illustration
- Sector: Finance, Ops
- What: Visualize operational risks or process flows (warehouse, branch layouts) as short videos to support board/analyst briefings.
- Tools/Workflows: BI platforms with “scenario-to-video” storytelling.
- Assumptions/Dependencies: Not a quantitative simulator; governance on forward-looking statements.
- Multiview, 3D-consistent world event generation
- Sector: VFX, Robotics, Mapping
- What: Generate coherent multi-camera videos of the same event from text+paths+references.
- Tools/Workflows: Multi-view synchronized generation with shared latent scene memory.
- Assumptions/Dependencies: True 3D scene representations and camera geometry conditioning; higher compute.
- Counterfactual and causal reasoning sandboxes
- Sector: Education, Research
- What: Explore “what-if” narratives (e.g., “what if leash snaps”) to teach causality, with more reliable physical adherence and long-horizon consistency.
- Tools/Workflows: Classroom sandbox that constrains physics and evaluates outcomes.
- Assumptions/Dependencies: Stronger physics priors, causal evaluation metrics, teacher-in-the-loop review.
Cross-cutting assumptions and dependencies
- Compute and latency: High-quality I2V generation (14B-class backbones) requires substantial GPU resources; real-time use cases need model distillation or specialized hardware.
- Licensing and rights: Base model terms, reference-image IP, and brand usage must be compliant; privacy for human likenesses.
- Domain adaptation: Specialized sectors (healthcare, AV, industrial) require domain data, safety review, and validation against ground truth.
- UI/UX maturity: Reliable canvas tools for trajectories, timing, and visibility flags; robust text-trajectory binding in multi-agent settings.
- Physical and causal fidelity: Current physical plausibility is approximate; not a substitute for engineering simulators without further integration.
- Safety and governance: Content moderation, provenance/watermarking, and disclosure (especially for forensic/policy contexts).
- Evaluation: Need sector-specific metrics beyond CLIP/trajectory error (e.g., clinical correctness, AV scenario coverage, human factors).
Glossary
- Affine transformations: Basic geometric operations (e.g., translation, scaling, rotation) applied to images or objects that preserve straight lines and parallelism. "apply mild affine transformations (e.g., translation, scaling, rotation) to these objects to generate reference images."
- Appearance Rate: A metric that measures visibility consistency by checking if tracked points are correctly marked visible when the input trajectory indicates visibility. "Appearance Rate~\cite{ATI}: the proportion of frames in which the tracker accurately predicts a point as visible whenever the input trajectory indicates it is visible;"
- Background Consistency: A metric assessing temporal coherence of the background, reflecting stability across frames. "Subject {paper_content} Background Consistency~\cite{vbench}: metrics reflect temporal consistency in video generation;"
- Bounding box: A rectangle enclosing an object in an image, used for detection and localization. "we detect objects in the first frame using YOLO~\cite{yolo} to obtain semantically meaningful bounding boxes corresponding to foreground objects."
- CLIP-T: A text-video alignment score that quantifies how well generated video content matches textual prompts, at global and local levels. "CLIP-T~\cite{tgt}: score reflecting semantic alignment between text and generated video, validated at both global and local levels."
- CoTracker3: A point-tracking model used to obtain trajectories and visibility of keypoints across video frames. "we track them throughout the entire clip using CoTracker3~\cite{cotracker3}"
- Cross-attention: An attention mechanism that lets visual tokens attend to textual tokens (or vice versa) for multimodal alignment. "Instead of computing cross-attention between all video tokens and the full text prompt uniformly, our method encourages the model to focus more on visual tokens that spatially overlap with each trajectory."
- Data augmentation: Techniques used to increase training data diversity by modifying inputs, improving robustness. "We then employ data augmentation techniques like cropping"
- DiT: Diffusion Transformer; a transformer-based architecture for diffusion models used in video generation. "concatenated directly with the original DiT inputs of Wan2.2 I2V model (noise latent, conditional image latent and rearranged mask) along the channel dimension."
- Flow matching: A training framework that learns a velocity field to transform noise into data, often used with reconstruction losses. "We follow the flow matching framework~\cite{flow, flow2} to perform post-training using reconstruction loss."
- Gaussian heatmap: A spatial representation placing Gaussian kernels at specified points to encode trajectory positions. "Specifically, we represent all trajectories using Gaussian heatmap and propagate the image VAE latent feature at the first-frame keypoint location of each trajectory to all subsequent points along that trajectory—forming what we call a point VAE map—"
- Hard cross-attention: A constrained attention variant that zeroes out attention outside regions of interest. "hard cross-attention (only keep attention weights in the region of interest, and set all other positions to zero)"
- Image-to-Video (I2V): Models that generate temporally coherent videos conditioned on images, often with text or trajectory controls. "Trajectory-controlled I2V generation~\cite{namekata2024sg, Levitor, trailblazer, DragNUWA, DragAnything, Tora, to2, frame-in-out, ATI, shi2024motion, lei2025animateanything, gillman2025force, yariv2025through, chuwan} represents an instantiation of such multimodal prompting."
- K-means: An unsupervised clustering algorithm used to select representative keypoints from masks. "select 1–3 representative keypoints per mask via K-means."
- Keypoints tracking and filtering: The process of selecting salient points and tracking them across frames, then filtering based on motion or quality. "Keypoints tracking and filtering:"
- L1 reconstruction loss: Mean absolute error used for training models to reconstruct targets, encouraging robustness to outliers. "We follow the flow matching framework~\cite{flow, flow2} to perform post-training using reconstruction loss."
- Motion score: A scalar measure of overall motion in a clip, computed from cumulative displacements of tracked points. "we further compute a motion score as the average cumulative displacement of all tracked points and filter out clips below a threshold"
- Multimodal triplet: A three-part specification per object consisting of its trajectory, bounding box, and motion-focused caption. "Using our data curation pipeline, we can get our desired multimodal triplet for distinct objects in the video, represented as:"
- ObjMC: A trajectory-following metric measuring mean Euclidean distance between generated and target trajectories. "ObjMC~\cite{motionctrl}: the mean Euclidean distance between generated and user-defined trajectories;"
- Occlusion: Temporary obstruction of an object’s visibility, often requiring visibility flags in trajectories. "visibility flags can signal occlusion or entry/exit."
- Point VAE map: A per-trajectory feature map created by propagating an image VAE latent along keypoint positions over time. "The Gaussian heatmap and point VAE map are then concatenated directly with the original DiT inputs of Wan2.2 I2V model"
- Reference images extraction: The process of obtaining and transforming images of objects to serve as visual identity cues during generation. "Reference images extraction:"
- SAM: Segment Anything Model; used to produce masks from prompts like bounding boxes. "generate corresponding masks with SAM~\cite{sam}"
- Shot boundary detection: An algorithmic method to segment videos into shot-consistent clips. "segment them into shot-consistent clips with a shot boundary detection algorithm~\cite{transnetV2}"
- Spatial-Aware Weighted Cross-Attention: A cross-attention mechanism that biases alignment between trajectory-specific visual regions and their associated captions. "To address this, we propose Spatial-Aware Weighted Cross-Attention that explicitly aligns each caption with its associated trajectory."
- Text-trajectory binding: Explicitly associating a motion caption with a specific trajectory for localized control. "Text-trajectory binding: Each trajectory is associated with a motion caption, ensuring semantic alignment between the described action and the controlled motion."
- Trajectory Injection: A control strategy that feeds trajectory-derived features (e.g., heatmaps) into the generative model. "Trajectory Injection"
- Trajectory-based motion captioning: A data curation step focusing captions on motion by linking trajectories to subject descriptions. "Trajectory-based motion captioning:"
- VAE latent: The latent representation produced by a Variational Autoencoder, used as a feature for conditioning generation. "propagate the image VAE latent feature at the first-frame keypoint location of each trajectory"
- ViCLIP: A video-language representation model used to compute semantic alignment scores. "Measures the overall semantic consistency between the generated video and the input text prompt using ViCLIP~\citep{viclip}."
- Visibility scores: Per-point indicators of whether a trajectory location is visible at a given time. "yielding trajectories and visibility scores."
- Wan2.2 I2V: A large-scale image-to-video generation model serving as the base architecture. "We build based on Wan2.2 I2V 14B model~\cite{Wan}."
- YOLO: An object detection framework producing bounding boxes for foreground objects. "we detect objects in the first frame using YOLO~\cite{yolo}"
Collections
Sign up for free to add this paper to one or more collections.