- The paper introduces a novel architecture that separates semantic reasoning and spatial localization via autoregressively generated query banks and a specialized anchor token.
- It implements Token–Mask Cycle Consistency (TMCC) to align coarse token responses with pixel-level masks, enhancing both training regularization and model interpretability.
- Empirical results show state-of-the-art performance on multiple segmentation benchmarks, demonstrating significant gains in both reasoning accuracy and spatial precision.
AnchorSeg: Language Grounded Query Banks for Reasoning Segmentation
Complex visual scenes often require pixel-level segmentation grounded not only in explicit referring expressions but also in implicit, reasoning-dependent language. Existing works such as LISA and GSVA have extended Large Multimodal Models (LMMs) with a segmentation token (e.g., <SEG>) to bridge the gap between language and vision. However, their bottleneck design—using a single unified query vector—obligates implicit fusion of both semantic reasoning (what to segment) and spatial localization (where to segment) into one embedding. This approach has demonstrated limitations in disambiguating semantic and spatial conditioning, especially under long or abstract queries, leading to performance degradation in reasoning segmentation.
This paper proposes to recast reasoning segmentation as a structured conditional generation problem, introducing language grounded query banks that explicitly disentangle intermediate semantic reasoning from final spatial grounding. AnchorSeg thus addresses the major architectural bias in prior LMM-based approaches by factorizing language-to-vision alignment via a bank of autoregressively generated reasoning tokens and a specialized spatial anchor token.
AnchorSeg Framework
AnchorSeg comprises three core components: (1) a LLM (LMM) that produces both latent reasoning queries and an explicit segmentation anchor; (2) a spatial conditioning module computing a language-informed spatial prior via anchor–image token similarity; and (3) a mask decoder (SAM), conditioned on the query bank and the spatial prior, that produces the final segmentation mask.
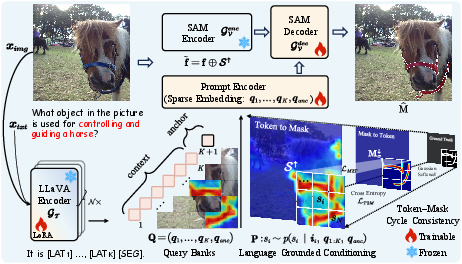
Figure 1: Overview of AnchorSeg, where the LMM generates contextual reasoning tokens and a segmentation anchor, producing a language grounded query bank that explicitly separates semantic and spatial information for conditioning the SAM mask decoder.
During inference, a textual query is processed by the LMM, which autoregressively emits K latent reasoning tokens followed by a specialized anchor token. These are projected into an ordered query bank. The anchor token computes a similarity-based spatial prior over image tokens, forming an explicit spatial grounding signal injected into the visual backbone. The full query bank, now explicitly factoring "what" (contextual) and "where" (anchor), cross-conditions the masked attention layers in the SAM decoder. This architecture decouples semantic modulation from spatial localization, enabling coherent, interpretable, and robust reasoning-based segmentation.
Language Grounded Token-Mask Cycle Consistency
A significant challenge in bridging structured language reasoning and dense pixel-wise supervision is resolution mismatch. AnchorSeg introduces Token–Mask Cycle Consistency (TMCC), a bidirectional objective that aligns token-level spatial responses (coarse, LMM side) with pixel-level ground-truth masks (vision side) at both scales. TMCC consists of a token-to-mask loss (upsampling token responses and matching to soft pixel masks) and a mask-to-token loss (downsampling masks and aligning with token-level activations). This two-way constraint regularizes training and enforces semantic and spatial alignment across the language-vision interface, leading to improved generalization and interpretability.
Empirical Results
AnchorSeg achieves state-of-the-art performance across multiple reasoning segmentation benchmarks, especially on the challenging ReasonSeg and G-RefCOCO datasets.
- On the ReasonSeg test set, the 13B model reaches 67.7% gIoU and 68.1% cIoU, outperforming the best prior finetuned READ-13B and RSVP baselines by substantial margins.
- In referring comprehension tasks (RefCOCO, RefCOCO+, RefCOCOg), AnchorSeg achieves leading [email protected], with gains exceeding +8% absolute over previous SOTA on RefCOCO+ val.
- On G-RefCOCO, AnchorSeg surpasses GSVA-Vicuna-7B by +8.29% gIoU and +13.57% null-target accuracy on validation, indicating robust handling of negative and one-to-many cases.
Qualitative evaluations underscore the stability and precision of segmentations under compositional, long, or abstract queries, where AnchorSeg consistently disambiguates target regions beyond the capability of previous single-query models.

Figure 2: Visual comparison on the ReasonSeg validation set, illustrating more precise and stable masks from AnchorSeg compared to SOTA methods under complex linguistic instructions.
Additionally, analysis of the learned query banks shows that as each latent token approaches the anchor position, its activation map evolves from semantically diffuse to highly localized, culminating in the anchor token's sharp spatial focus—empirically demonstrating the progressive semantic-to-spatial refinement within the query bank.
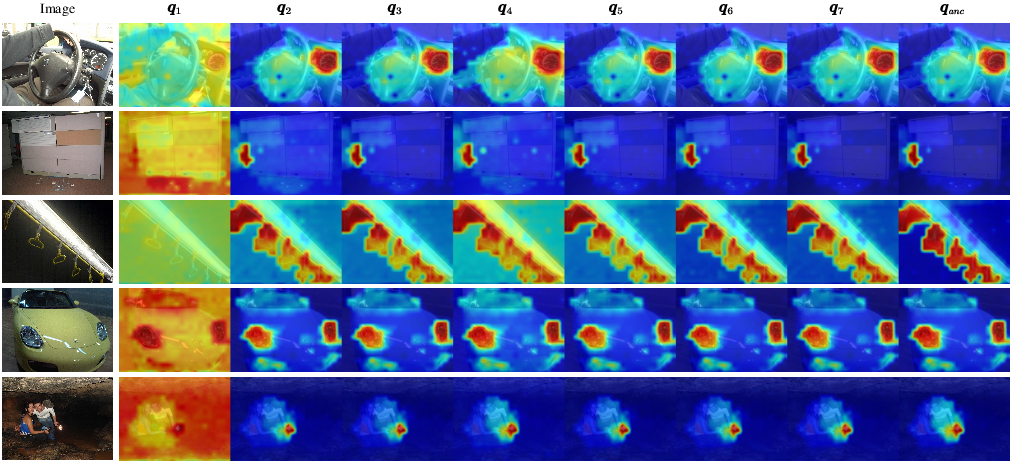
Figure 3: Query bank analysis: as reasoning tokens progress toward the anchor, their similarity maps shift from broad semantic responses to highly localized activations, validating explicit disentanglement.
Ablations and Computational Considerations
Detailed ablations verify:
- The superiority of an ordered query sequence (optimal length N=8 on ReasonSeg val), confirming the claim that both too short and too long sequences degrade performance.
- Both the explicit spatial prior injection and TMCC are essential; removing either leads to a 2–4% cIoU drop.
- Contextual queries (excluding anchor) further boost cIoU by 1.9% over anchor-only, demonstrating that semantic modulation is a critical capacity bottleneck in complex segmentation.
In terms of training cost, AnchorSeg introduces moderate additional memory and time overhead relative to single-query baselines (training latency 2.94s vs. LISA's 1.26s per iteration at batch size 2), but maintains competitive runtime throughput (4.00 FPS).
Theoretical and Practical Implications
Explicitly factorizing language-to-vision alignment via structured query banks substantially enriches the interpretability and flexibility of MM reasoning architectures. The mechanism naturally extends to multi-anchor variants for multi-object reasoning and enables more granular error analysis by disentangling semantic and spatial failure modes. Practically, the framework is compatible with any LMM or segmentation backbone, allowing for modular improvements as underlying models advance.
AnchorSeg's performance demonstrates the limitations of implicit bottleneck conditioning in current LLM–vision interfaces and offers a scalable template for chain-of-thought and compositional reasoning under dense prediction.
Limitations and Future Work
The performance of AnchorSeg is fundamentally coupled to the quality of the LMM. Weak reasoning capabilities can bottleneck the expressivity of the query bank (section 6.1). The anchor/query count is statically determined, which may be sub-optimal for dynamic reasoning complexity. Moreover, the introduction of multiple tokens and TMCC imposes non-trivial overhead, making resource efficiency and adaptivity vital future research directions. Exploring fully adaptive query structures, intelligent anchor allocation for multi-instance segmentation, and more efficient or sparse conditioning mechanisms is of high interest.
Conclusion
AnchorSeg advances reasoning segmentation by explicitly separating semantic reasoning from spatial grounding via a language grounded query bank and a token-level cycle consistency objective. Its demonstrated improvements—both quantitative and qualitative—validate the hypothesis that direct factorization of reasoning and localization yields more robust, interpretable, and generalizable segmentation systems. The AnchorSeg paradigm sets a foundation for subsequent work in structured multimodal reasoning, compositional segmentation, and modular language–vision interaction architectures.
(2604.18562)

