- The paper proposes a causal query-driven mask decoder (CQMD) that enforces spatial grounding before text recognition in OCR-oriented vision-language models.
- It introduces the large-scale TextAnchor-26M dataset and a stochastic prior injection technique to provide robust spatial supervision.
- Empirical evaluations demonstrate significant improvements in text-to-region tasks, validating the design’s effectiveness in challenging visual contexts.
Query-Driven Text Anchoring in OCR-Oriented Vision-LLMs: Q-Mask
Motivation and Benchmarking
The paper addresses a core limitation in Vision-LLMs (VLMs) pertaining to Optical Character Recognition (OCR): reliable text anchoring—the ability to ground queried text tokens within corresponding spatial regions. Despite recent progress in both general-purpose and OCR-specialized VLMs, systematic evaluation with the proposed TextAnchor-Bench (TABench) reveals substantial deficiencies in establishing accurate text anchors, especially across complex and text-rich visual scenes.
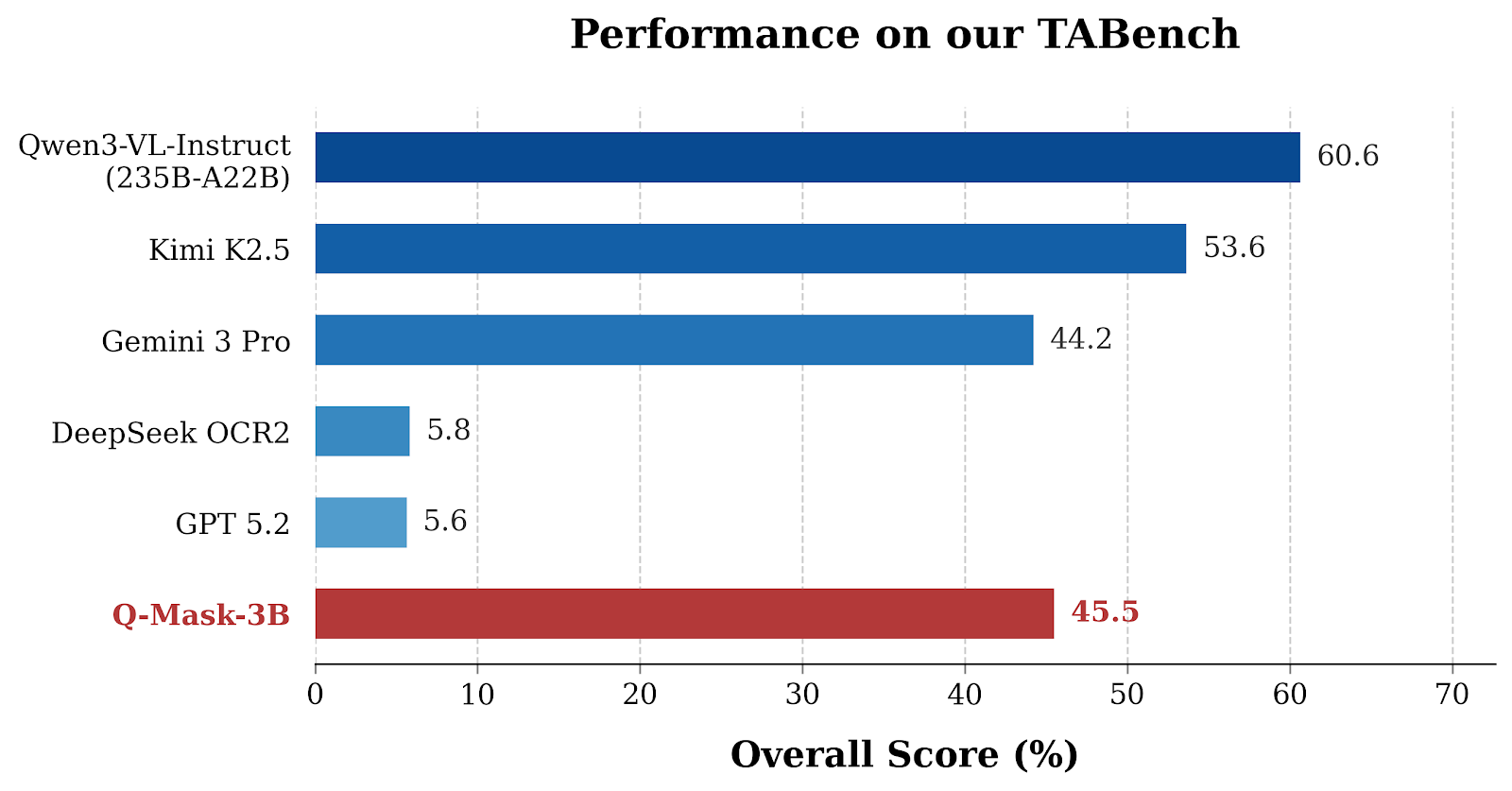
Figure 1: Performance comparison of mainstream general-purpose VLMs and OCR-specific VLMs on TABench, highlighting persistent instability in text anchoring.
This deficit is attributed primarily to prevailing training paradigms. Standard VLMs typically operate on image-text pair corpora, developing recognition capability without explicit spatial grounding. Although embeddings for coordinates are sometimes incorporated, they fail to instate robust, explicit anchoring logic. Mask-based VLMs provide spatial supervision during training but do not guarantee causal, query-driven mask outputs interpretable as spatial priors during inference.
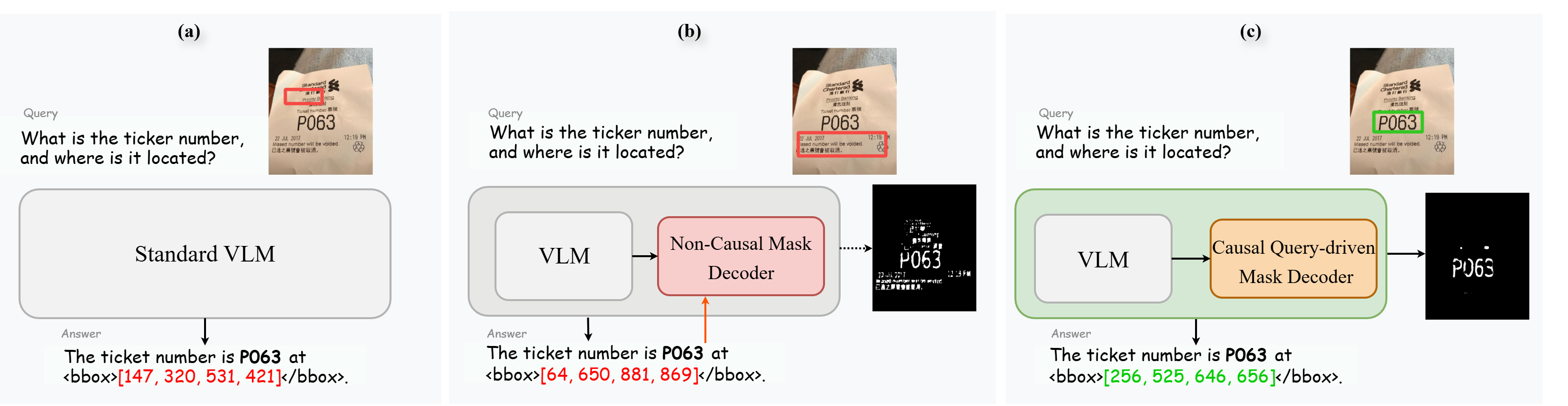
Figure 2: Comparison of OCR-specific VLM training paradigms; only Q-Mask establishes explicit query-grounded text regions prior to recognition.
Q-Mask Architecture: Causal Query-Driven Mask Decoder
Q-Mask introduces a structured reasoning paradigm inspired by Chain-of-Thought (CoT) to enforce causality between spatial grounding (“where”) and content recognition (“what”). The centerpiece is the Causal Query-Driven Mask Decoder (CQMD):
- CQMD extracts hidden states corresponding exclusively to visual and query tokens, excluding answer tokens to ensure causal separation.
- Query-aware spatial features are computed via cross-attention from visual tokens to query tokens, producing latent spatial support variables (masks) independent of future answer tokens.
- Mask supervision is imposed through a joint objective including next-token prediction and segmentation loss.
This design guarantees that spatial masks serve as query-conditioned priors for autoregressive decoding, decoupling spatial grounding from content generation.
Large-Scale Spatial Supervision: TextAnchor-26M Dataset
Robust spatial anchoring demands large-scale, high-fidelity supervision. The TextAnchor-26M dataset is constructed to this end, comprising ~26.7M image-text instances with precise masks and bounding boxes. Four complementary sources provide coverage across unconstrained scene text, academic documents, synthesized typography-rich text, and targeted VQA instances with explicit answer localization.
Figure 3: Construction pipeline for TextAnchor-26M; stochastic prior injection (SPI) and de-stylized mask rendering yield unified spatial supervision.
- Stochastic Prior Injection (SPI): Simulates OCR priors with empirical noise models, exposing Q-Mask to realistic, noisy spatial cues.
- De-stylized Mask Rendering: Masks are generated from transcripts and bounding boxes with generic fonts, promoting modality-agnostic localization and reducing sensitivity to low-level textures.
Empirical Evaluation: Benchmarking and Error Analysis
Extensive evaluation on TABench and multiple VQA/document-understanding benchmarks demonstrates that even high-capacity generalist VLMs (e.g., Gemini 3.0 Pro, Qwen3-VL) exhibit unbalanced anchoring performance (bidirectional R2T/T2R tasks). The Q-Mask framework achieves substantial gains in both directions, particularly in challenging text-to-region tasks.
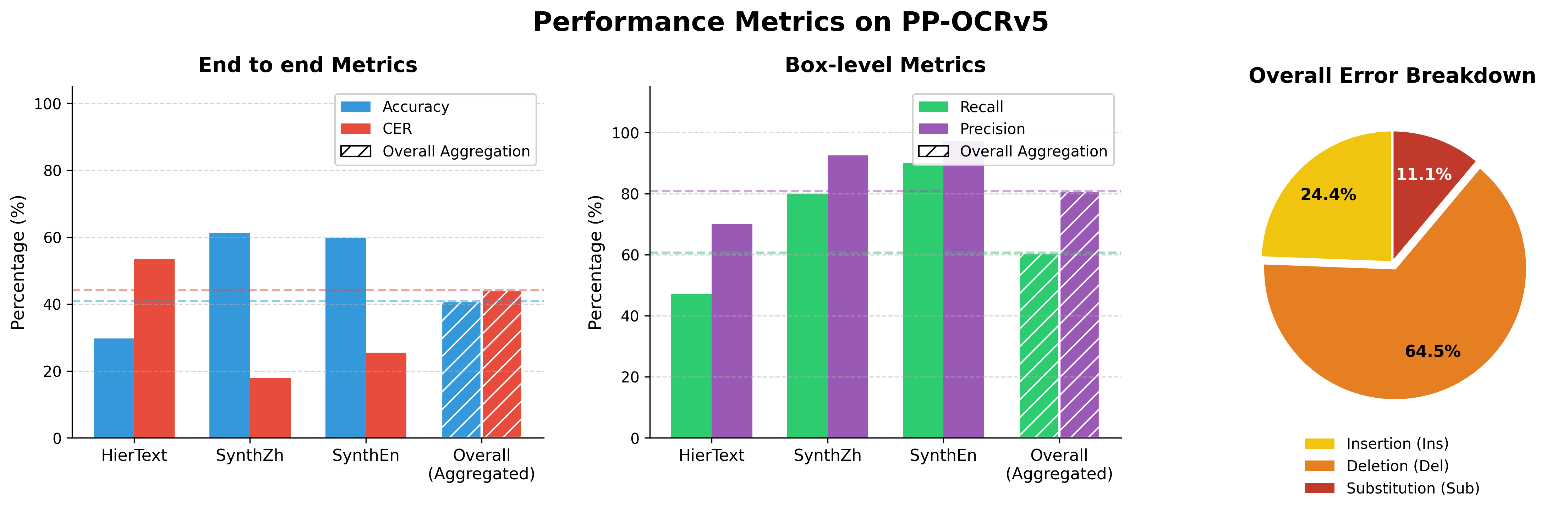
Figure 4: Empirical error profile of PPOCR-V5 on scene text; localization and recognition errors are decomposed for targeted augmentation.
Ablation studies further isolate the contribution of CQMD and SPI, affirming that query-only spatial conditioning and dynamic prior injection are critical for balanced anchoring. Scaling analysis shows Stage-1 spatial metrics strongly correlate with downstream performance, validating the diagnostic value of TABench.
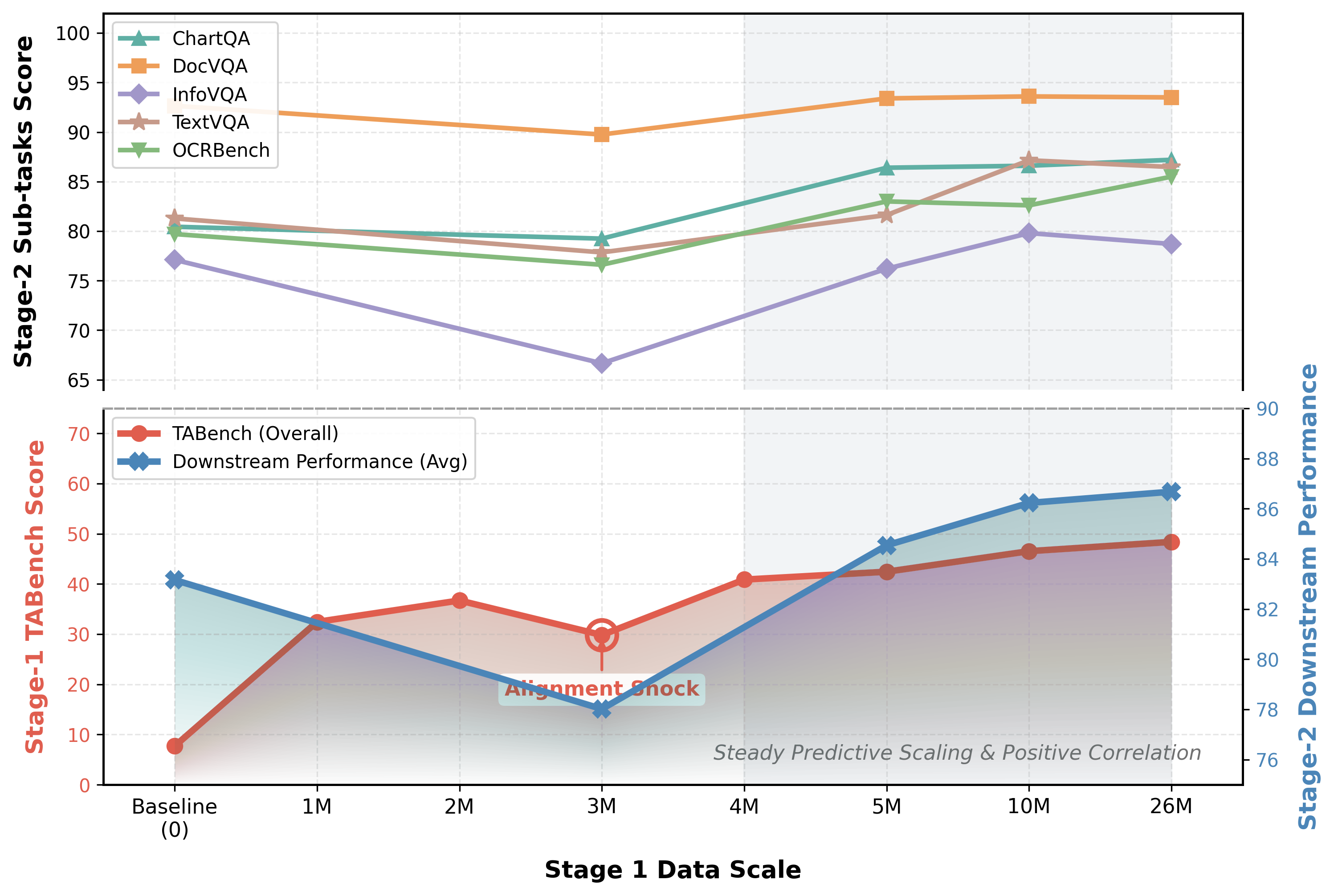
Figure 5: Correlation between Stage-1 spatial pre-training signals and Stage-2 downstream task performance under fixed instruction-tuning protocol.
Qualitative Results
Qualitative visualization demonstrates Q-Mask’s ability to localize and read text robustly in small, low-contrast, and crowded regions—substantially outperforming baselines in region-to-text (R2T) cases.
Figure 6: Q-Mask achieves superior text reading accuracy in challenging spatial contexts; robustness is evident across fixed query regions.
The two-stage pipeline maintains query-conditioned spatial cues during both training and inference. In VQA, causal masks highlight candidate regions prior to answer generation, providing interpretable grounding for multimodal reasoning.

Figure 7: Q-Mask’s query-driven mask decoder predicts spatial regions prior to content generation; heatmaps visualize candidate localization during inference.
Practical and Theoretical Implications
The architectural decoupling realized by Q-Mask yields several consequential improvements:
- Spatial priors are interpretable and available before decoding, enhancing transparency and model interpretability in vision-language reasoning.
- Parameter efficiency: Q-Mask delivers competitive performance with substantially fewer parameters than contemporaneous models employing non-causal spatial conditioning.
- Robustness to diverse document and scene layouts, supporting interactive and downstream tasks in wearable/assistive computing, document analysis, and VQA.
Theoretically, Q-Mask’s causal factorization sets a precedent for intermediate spatial representations in multimodal models. Spatial grounding prior to answer decoding enables systematic reasoning, more principled evaluation, and opens avenues for hierarchy-aware, modular, or token-efficient spatial priors.
Future Directions
Open problems include:
- Extending anchoring mechanisms to broader scripts, multi-lingual, and multi-domain datasets.
- Developing more efficient spatial priors for ultra-long document contexts.
- Integrating causal spatial reasoning into broader multimodal, agentic, or GUI task frameworks.
Conclusion
Q-Mask substantiates a query-driven, causally structured mask decoder, establishing reliable text anchors and bridging the gap between visual perception and language understanding in OCR-oriented VLMs. TABench and TextAnchor-26M provide rigorous evaluation and training infrastructure, while empirical analysis validates the proposed factorization and augmentation strategies. The compositional separation of "where" and "what" enables both practical gains and theoretical clarity, positioning Q-Mask as a paradigm for interpretable spatial reasoning in AI systems (2604.00161).

