- The paper presents PixDLM, which integrates dual-path visual encoders with an LLM backbone to enhance pixel-level UAV segmentation.
- It achieves state-of-the-art results on the DRSeg benchmark with 4–7% gains in gIoU and cIoU across spatial, attribute, and scene-level tasks.
- The study emphasizes a robust, instruction-driven pipeline using chain-of-thought supervision to manage complex UAV imagery challenges.
PixDLM: A Dual-Path Multimodal LLM for UAV Reasoning Segmentation
Introduction
The UAV Reasoning Segmentation task introduces new challenges derived from the distinct properties of aerial imagery, including oblique camera viewpoints, high spatial resolution, and significant scale variations. Existing benchmarks and models are predominantly oriented toward ground or satellite imagery and are ill-suited for the unique demands of UAV data, particularly in their inability to capture complex spatial and semantic relationships in scenes featuring densely packed small objects and high-frequency structural cues. The work formalizes UAV Reasoning Segmentation as an instruction-driven, pixel-level categorization problem corresponding to spatial, attribute, and scene-level reasoning targets, and delivers both a large-scale, dedicated dataset (DRSeg) and a novel baseline model (PixDLM) that integrates dual-path visual encoding and hierarchical multimodal reasoning.
Dataset: DRSeg — UAV Reasoning Segmentation Benchmark
The DRSeg benchmark comprises 10,000 high-resolution UAV images annotated with precise pixel-level segmentation masks. Each sample is coupled with a natural language chain-of-thought (CoT) question–answer (QA) supervision, partitioned evenly into three reasoning tasks: spatial, attribute, and scene-level. Scene diversity encompasses urban, residential, industrial, and waterfront environments, under varied visual and illumination conditions.
The dataset is constructed via a four-stage pipeline: human image selection (targeting complexity and diversity), semi-automatic mask generation (using rotated bounding boxes and SAM2 refinement), automated reasoning annotation (GPT-5-driven generation of CoT QA pairs along three reasoning axes), and rigorous human verification for semantic congruence and annotation quality.
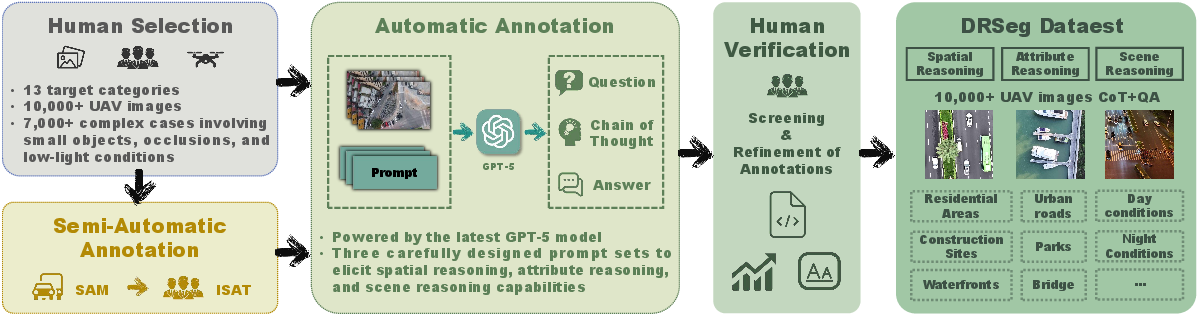
Figure 1: Overview of the DRSeg construction pipeline, illustrating manual curation, mask generation, GPT-5-driven annotation, and human verification steps for UAV reasoning segmentation.
Detailed analysis demonstrates a preponderance of small-object targets (approximately 58% occupy less than 2% of the image area), strong geometric diversity (multiple flight altitudes), and variable context (day/night, object density). Balanced distribution of reasoning types is maintained, facilitating systematic comparison of multimodal models regarding inferential scope.
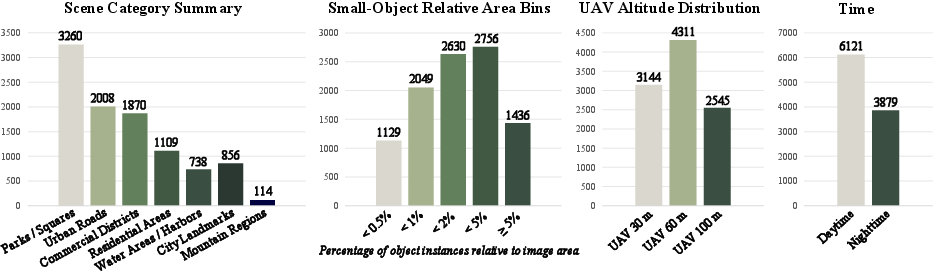
Figure 2: Dataset statistics of DRSeg, highlighting small-object prevalence, scene categories, flight altitudes, and diurnal variation.
Instruction templates enforce consistent annotation structure, with strict JSON output and multi-step reasoning design, enhancing the reliability and interpretability of target definition.

Figure 3: Instruction template for generating spatial, attribute, and scene-level reasoning chains, questions, and answers in unified supervision format.
Method: PixDLM Architecture
PixDLM is a lightweight, pixel-level multimodal LLM integrating dual-path visual encoders and an LLM backbone, culminating in a hierarchical reasoning decoder. This design is explicitly tailored for UAV imagery's complexity and leverages high-resolution detail without incurring prohibitive computational cost. The architecture consists of three principal modules:
- Dual-Path Vision Encoder: Simultaneously extracts coarse global semantics (via a CLIP-based pathway) and fine-grained high-resolution structure (using a SAM-based pathway), with information exchanged through MultiPath Alignment. Feature fusion occurs both intermediately (across encoder stages) and terminally, guided by learnable gating and projection functions, ensuring effective integration of fine details with semantic abstraction.
- LLM Backbone: Receives encoded image features, text embeddings, and a trainable Mask Token, propelling instruction-conditioned reasoning. LLM outputs encapsulate contextually aligned multimodal representations.
- Hierarchical Reasoning Decoder: Recovers pixel-level masks from LLM outputs using multi-scale refinement. Progressive injection of visual features at multiple spatial resolutions allows the decoder to maintain spatial accuracy and semantic integrity, crucial for the heterogeneous object scale and contextual complexity in UAV imagery.
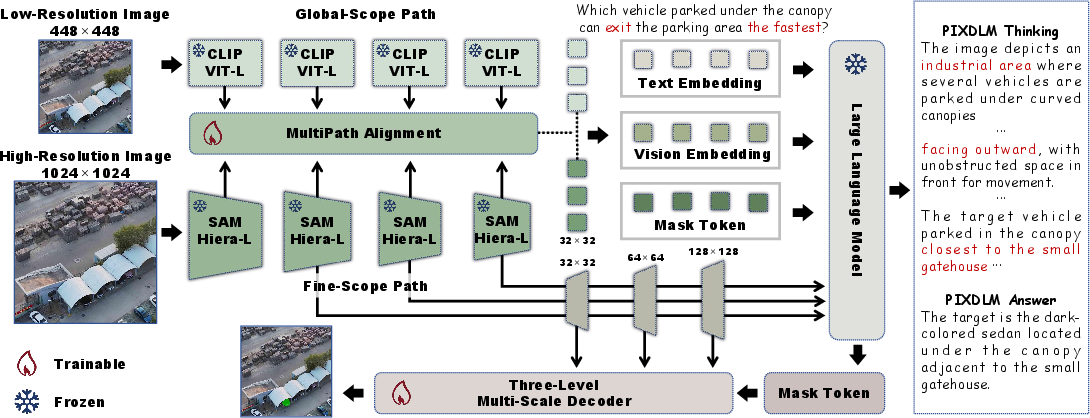
Figure 4: Overview of the PixDLM system architecture, highlighting dual-path encoding, multimodal LLM fusion, and hierarchical decoding for instruction-driven UAV segmentation.
Experimental Results and Analysis
Quantitative and Visual Benchmarking
Comprehensive evaluation against state-of-the-art multimodal models—including LISA, PixelLM, GeoPix, and Seg-Zero—was conducted under zero-shot and supervised fine-tuning (SFT) paradigms. Zero-shot performance of all baselines is sub-optimal, reinforcing the necessity for targeted data and architecture. After SFT, PixDLM achieves pronounced improvements. Specifically, on DRSeg, PixDLM attains 62.80% gIoU / 62.84% cIoU (attribute), 61.75% / 64.03% (scene), and 62.51% / 62.80% (spatial)—exceeding all competitors in each reasoning dimension. Gains are consistent across both local and cumulative measures, reflecting robust segmentation quality and generalization across diverse reasoning tasks.

Figure 5: Visual comparison of segmentation results for LISA, fine-tuned LISA, GeoPix, and PixDLM, demonstrating improved delineation and localization by PixDLM, particularly for complex and small-object cases.

Figure 6: PixDLM segmentation masks across reasoning sets (attribute, scene, spatial), capturing increasing reasoning complexity and localization fidelity under varied UAV imagery conditions.
Cross-domain transfer was validated on the RefCOCO, RefCOCO+, and RefCOCOg datasets, where PixDLM matches or surpasses the best-performing baselines, confirming that the dual-path and hierarchical design generalizes beyond UAV-specific scenarios.
Ablation Studies
Systematic ablations validate PixDLM’s architecture:
- MultiPath Alignment: Progressive activation of fusion layers (1st–4th) yields monotonic gains; full four-layer integration improves gIoU on all reasoning dimensions by 4–7% over non-fused settings, confirming the criticality of cross-level semantic–structural alignment.
- Hierarchical Decoder Depth: Extension from two to three layers in the decoder provides a 5–6% absolute improvement in gIoU and cIoU, substantiating the significance of multi-level refinement in handling diverse spatial scales and context.
- Training Signals: Introduction of chain-of-thought supervision, and mixed-task training, both enhance reasoning robustness and mask alignment, reflecting the need for explicit, interpretable linguistic reasoning in supervision.
Implications and Future Directions
PixDLM and DRSeg fill a substantial gap in the multimodal segmentation landscape by providing appropriate datasets and architectural innovations for challenging UAV perception tasks. The dominance of the dual-path, deeply fused encoder stratagem and hierarchical decoder paves the way for future work on more efficient or dynamic resolution control, multi-instruction or multi-object UAV reasoning, continual adaptation, and robust deployment under real-time or on-board UAV constraints.
Practically, PixDLM offers a foundation for aerial decision-support applications—search-and-rescue, survey, inspection, or navigation—where both fine localization and broad semantic reasoning are mission-critical and must function under severe resource and data annotation constraints.
Theoretically, this line of research exemplifies the value of architectural and supervision choices tuned to data characteristics and task semantics, suggesting broader applicability for instruction-driven multi-object or compositional reasoning in complex visual regimes beyond UAVs, such as medical or autonomous driving imagery.
Conclusion
This work introduces UAV Reasoning Segmentation as a structured, instruction-driven, pixel-level visual reasoning problem, supported by the comprehensive DRSeg dataset and the PixDLM multimodal model. Through dual-path visual encoding, intricate multimodal fusion, and hierarchical decoding, PixDLM establishes new state-of-the-art benchmarks for both semantic comprehension and spatial accuracy on UAV imagery. The empirical and architectural insights set a new trajectory for subsequent research in instruction-conditioned segmentation, high-resolution multimodal alignment, and real-world aerial scene understanding.

