- The paper introduces WISE, which decouples detailed training reasoning from concise inference to achieve up to 10.6× token compression and improved accuracy.
- It employs an autoregressive formulation with a self-distillation objective that optimizes semantic fidelity and penalizes verbosity.
- Experimental results demonstrate state-of-the-art IoU scores, lower latency, and robust performance across multiple benchmarks.
Efficient Reasoning via Thought Compression for Language Segmentation
Introduction: Motivations and Challenges
Language-guided segmentation has advanced from grounding simple referring expressions to executing complex, compositional visual reasoning. In this setting, recent methods incorporating Chain-of-Thought (CoT) prompting within Large Multimodal Models (LMMs) have demonstrated superior reasoning and zero-shot generalization capacity. However, such improvements are coupled with prohibitively high inference costs due to verbose rationalization, creating a bottleneck for real-world deployment in latency-sensitive applications.
This paper introduces WISE (Wisdom from Internal Self-Exploration) as a systematic approach to efficient reasoning for language segmentation. WISE explicitly decouples the learning phase—where detailed explanations may drive policy improvement—from the inference phase, where concise reasoning chains are critical for scalability and rapid response.
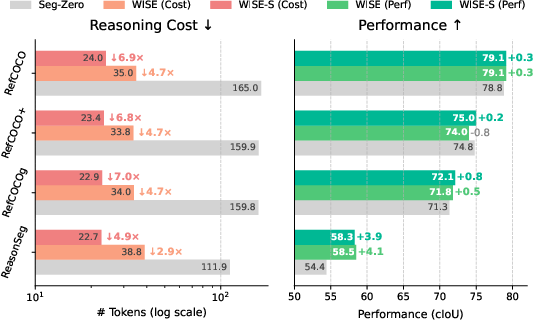
Figure 1: WISE achieves a superior cost-performance trade-off by decoupling reasoning for learning and inference. The base model reduces reasoning cost by 4.7× yet outperforms the baseline; WISE-S achieves up to 10.6× compression and state-of-the-art accuracy.
Methodology: Structured Generation and Thought Compression
The key innovation lies in restructuring the reasoning policy to generate sequential output as (τc,A,τd), where τc is a concise rationale, A the answer (e.g., geometric prompt), and τd a detailed explanation. The sequence ordering is deliberately chosen to ensure autoregressive dependence: the detailed chain is strictly conditioned on the concise rationale, enforcing τc as a sufficient and information-rich statistic.
A pivotal aspect of WISE is the self-distillation objective, which includes (1) a semantic fidelity term (cosine similarity between embeddings of τc and τd), and (2) a conciseness penalty (normalized token reduction). This reward shaping is only activated when the policy achieves correct grounding (IoU > 0.5), preventing distillation of erroneous chains.
During inference, the model omits τd and, for robust activation of concise policies, leverages WISE-S: a brevity-focused prompting strategy that explicitly requests short rationales. This simple modification mitigates the conditional distribution mismatch between training and inference.
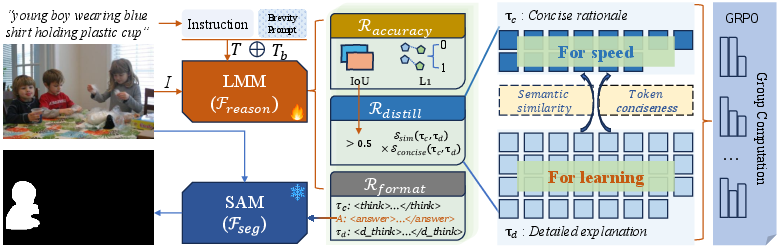
Figure 2: Overview of WISE; concise rationale is generated first, followed by answer and detailed rationale during training but omitted at inference time.

Figure 3: The prompting strategy specifies how different combinations of rationale instructions control the output form across training and inference.
Experimental Results: Efficiency, Accuracy, and Robustness
WISE and WISE-S report state-of-the-art performance on ReasonSeg, obtaining 60.3 gIoU / 58.5 cIoU and 60.3 gIoU / 58.3 cIoU on the test set, surpassing all prior methods—while concurrently reducing average reasoning lengths by nearly 5× (23 tokens vs. 112 for Seg-Zero). The gains persist across multiple benchmarks (RefCOCO, RefCOCO+, RefCOCOg), confirming robustness to task shift and annotation sparsity.
WISE-S reduces wall-clock latency by 5τc0 compared to RL-based baselines. Notably, control experiments show that simplistic brevity prompts applied to non-distilled baselines yield marginal improvements, underscoring that the improvement derives from the distilled concise policy rather than mere prompt engineering.
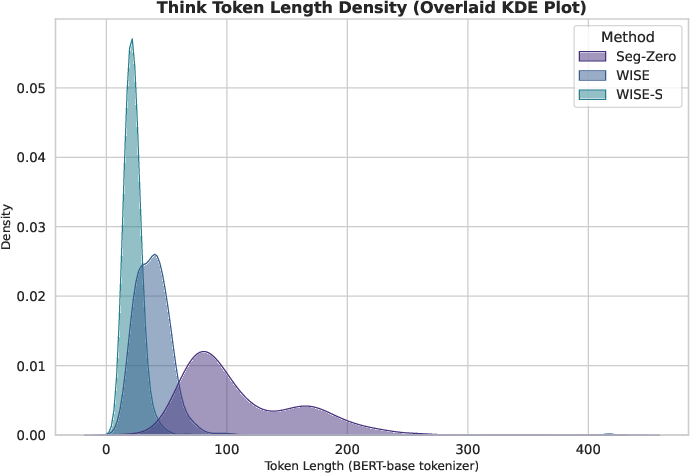
Figure 4: The reasoning token length distribution; WISE-S (green) is tightly concentrated and concise, while Seg-Zero (purple) is long-tailed and variable.

Figure 5: Qualitative comparison on a complex instruction—WISE-S achieves successful concise reasoning and target prediction, contrasting with baseline's verbose and ultimately incorrect chain.
Analysis: Ablation, Generalization, and Limitation
Ablation studies verify that generation order τc1 is essential for effective compression; reversing this order fails to induce abstraction and does not yield token savings. Both the similarity and compression components of the self-distillation reward are indispensable for robust, high-fidelity summarization.
In generalization experiments (VisionReasoner suite: detection, segmentation, counting), WISE-S consistently compresses rationales and, in most cases, increases accuracy, demonstrating cross-task scalability. Compression does not induce additional reasoning failures; rather, when errors occur, concise rationales faithfully summarize the chain's core logic, with limitations attributed to backbone grounding, not the distillation mechanism per se.


Figure 6: WISE-S acts as a sufficient summary for successful identification (left: affordance-based; right: discriminative attribute), whereas verbose baselines incur reasoning drift or redundancy.
Theoretical and Practical Implications
The results establish that deep chain-of-thought reasoning and inference efficiency are not inherently opposed. By enforcing a “concise-first” generation order with autoregressive conditioning and hierarchical self-distillation, LMM-based segmentation policies can internalize effective yet substantially compressed reasoning. The findings indicate that explicit reasoning remains beneficial for generalization, yet its computational burden is not a fixed cost—sufficient and lossless compression is achievable through structured learning objectives.
Practical implications span sustainable AI (reduced energy per inference), deployment scalability (lower latency for robotics and interactive agents), and improved alignment with reinforcement learning-based optimization where verbose rationales are a debugging nuisance rather than benefit.
Conclusion
WISE addresses the high inference cost of CoT-based segmentation by reordering the generation sequence and introducing a self-distillation objective that efficiently compresses the reasoning process. The concise rationales learned under this paradigm achieve superior accuracy and drastically reduced token budgets, eliminating the perceived trade-off between reasoning depth and computational efficiency. This paradigm poses a promising template for broader adoption in structured multi-step reasoning tasks across vision-language and other multimodal domains.

