- The paper introduces a novel online reasoning video segmentation setting that enforces strict causality and adaptively handles referent shifts.
- It proposes a memory-enhanced multimodal architecture with adaptive fusion and a structured token reservoir, enabling real-time, history-aware segmentation.
- The approach achieves a 61.3% overall performance on the ORVOSB benchmark, outperforming traditional offline methods in dynamic, event-driven scenarios.
Online Reasoning Video Object Segmentation: A Causality-Grounded Framework and Benchmark
Introduction and Motivation
The task of reasoning video object segmentation (RVOS) aims to temporally localize target objects in videos from natural language queries, requiring models to resolve implicit, event-driven references often dependent on context and temporal cues. Prevailing methods, however, operate under an offline regime: the full video is available at inference, enabling retrospective disambiguation where future frames clarify ambiguous referents. This protocol diverges from real-world applications—such as robotics or streaming analytics—where predictions must be made online, causally, and incrementally as frames are observed, without revisiting prior outputs or accessing future information.
This paper introduces the Online Reasoning Video Object Segmentation (ORVOS) setting: at each time step, the model must produce mask predictions using only the prefix of observed frames and the current frame, adhering to strict causal inference. This regime introduces two crucial challenges:
- Strict Causality: Objects should only be segmented when unambiguously grounded by observed evidence, prohibiting premature assignment prior to event manifestation.
- Referent Shifts: The identity of the target object can change as events unfold, making it necessary for the model to adapt its segmentation target dynamically and track evolving context.
The work identifies that existing benchmarks and methodologies are predominantly offline and lack the necessary protocols and annotations to meaningfully evaluate online, shifting referent scenarios.
ORVOSB Benchmark: Construction, Properties, and Protocol
Responding to these limitations, the authors construct ORVOSB—an Online Reasoning Video Object Segmentation Benchmark specifically designed for causal, referent-altering video understanding.
The ORVOSB benchmark comprises:
- 210 diverse, naturally occurring video sequences, culled with a two-stage MLLM-LLM pipeline for complex event selection.
- 12,907 annotated frames (dense, frame-level masks), covering 512 natural language queries across five reasoning categories: attribute, spatial relation, state/action change, interaction, and external knowledge.
Distinctly, the benchmark annotates temporal referent shifts: for each query and video, precise intervals are marked where the referent object changes, as dictated by the query semantics.
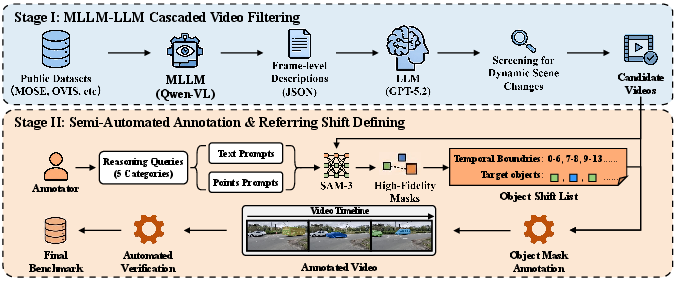
Figure 1: Overview of the data construction and annotation pipeline for ORVOSB, featuring automated video event selection, MLLM-assisted description extraction, and dynamic, human-in-the-loop mask annotation across referent boundaries.
This results in an average of 3.66 referent shifts per query, with over half of the queries requiring segmentation of non-continuous, event-driven referent intervals—a highly challenging scenario for both memory and reasoning in causal models.

Figure 2: Examples of the five reasoning query types in ORVOSB, emphasizing the diversity of causal and event-based expressions that induce referent ambiguity and temporal changes.
The evaluation protocol enforces strict causality: at each frame, models must predict segmentation masks conditioned solely on the past and current context, without post hoc access to future evidence.
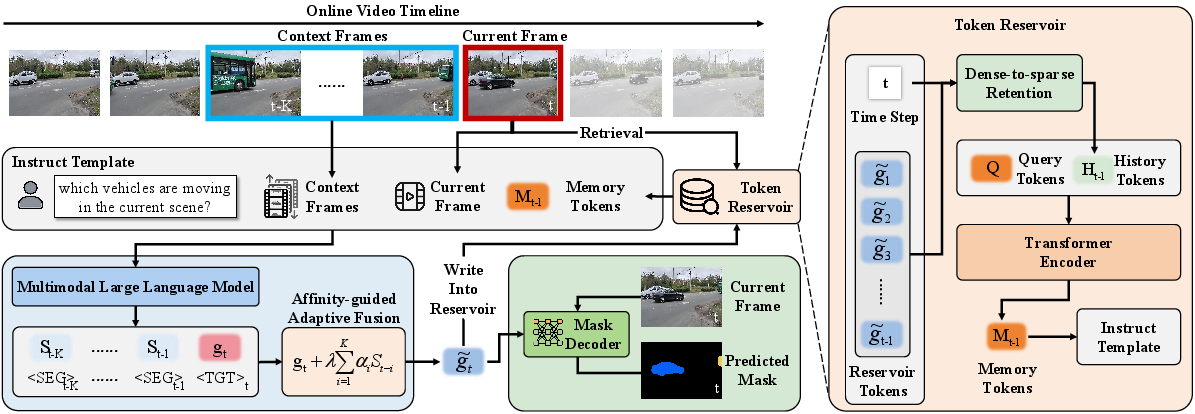
Online Reasoning Video Object Segmentation Framework
To address ORVOS, the paper proposes a memory-enhanced multimodal architecture integrating Multimodal LLM (MLLM)-based token encoding, a structured token reservoir for long-term memory, and a continually-updating segmentation prompt.
At each time step:
The mask prediction head receives the evolving prompt and current visual features, ensuring all reasoning is frame-synchronous and causality-preserving.
Experimental Results and Analysis
The proposed method establishes a strong baseline under the online regime. Existing offline RVOS frameworks degrade substantially when evaluated on ORVOSB, particularly on referent-shift cases, confirming their inability to causally disambiguate temporal queries. Specifically:
- Video-based methods such as VISA and VRS-HQ attain only 33–43% J, primarily due to a fixed referent paradigm and reliance on segment-then-track, which cannot adapt to changing event contexts.
- Image-based methods like LISA and READ, which reconstruct prompts per frame, perform better (46–51%), but lack structured temporal memory or causal aggregation.
- The proposed framework surpasses all baselines, achieving 61.3% overall J, demonstrating robust handling of referent shifts and long-term disambiguation.
Ablation Studies
The addition of continually-updating segmentation prompts and the structured token reservoir are shown to be mutually reinforcing:
- Removing affinity-guided adaptive fusion dampens gains, highlighting the criticality of context-adaptive prompt fusion.
- Token reservoir with dense-to-sparse retention further boosts performance, validating the importance of long-term memory under bounded computation.
Generalization to Offline Benchmarks
Despite being trained and evaluated under the strict online regime, the method remains competitive with top-performing offline methods on conventional benchmarks (e.g., ReVOS), confirming that causality-grounded memory mechanisms transfer effectively when future access is available.
Qualitative Analysis

Figure 4: Qualitative comparison of segmentation predictions on ORVOSB and ReVOS. The online approach maintains temporal consistency and adapts to referent evolution, unlike offline/tracking-driven methods which suffer from drift and inconsistent target assignment.
In challenging event-driven scenarios, the online framework maintains accurate segmentation in the face of referent changes and ambiguous cues—whereas offline/tracking-based methods often misassign masks, exhibit identity drift, or fail to adapt when the query semantics evolve.
Implications and Future Directions
The introduction of ORVOS and ORVOSB reframes video object segmentation towards practical, deployable systems requiring strict online, causal reasoning and adaptation to dynamic, event-driven query semantics. This has immediate implications for real-world applications such as real-time robotics, on-device analytics, and embodied agents, where incremental frame-by-frame mask prediction is essential.
The formulation of referent shifts and causality constraints foregrounds the need for structured temporal memory, progressive interpretation, and semantic context aggregation under computation and latency constraints. Future research may explore:
- More efficient or hierarchical memory representations for unbounded video streams
- Joint event understanding and segmentation tasks leveraging event boundaries and temporal logic
- Continual or life-long adaptation mechanisms robust to shifting query grounding across arbitrarily long time horizons
Conclusion
This work inaugurates the Online Reasoning Video Object Segmentation problem, pairing it with a rigorous, causality-enforcing benchmark (ORVOSB) and a memory-augmented multimodal baseline. Experimental evidence reveals the significant gap between offline and causally-constrained settings, and positions continually-updating prompts and structured memory as essential for robust, adaptive video understanding under realistic streaming conditions.