- The paper introduces SynAgent, a unified framework that transfers skills from solo human-object interaction (HOI) to multi-agent human-object-human interaction (HOHI) for cooperative humanoid manipulation, addressing data scarcity and generalization challenges.
- SynAgent utilizes an interaction-preserving motion retargeting method and a three-stage solo-to-cooperative agent synergy paradigm, including multi-agent policy optimization and distillation, to build robust motion imitation priors.
- The framework develops a generalizable trajectory-conditioned generative policy using a conditional Variational Autoencoder (CVAE) with multi-teacher distillation, outperforming baselines in cooperative imitation and trajectory control with robust generalization across 25 diverse object geometries.
- SynAgent demonstrates a 45.00% success rate in cooperative imitation, significantly higher than InterMimic's 7.26%, and achieves superior trajectory-conditioned manipulation with an overall success rate of 19.16%, compared to CooHOI's 7.28%.
SynAgent: Bridging Unconstrained Single-Agent Dexterity to Robust Cooperative Humanoid Manipulation
The development of embodied intelligence systems capable of intricate and generalized cooperative manipulation remains a significant challenge due to inherent data scarcity in human-object-human interaction (HOHI) datasets, the complexities of multi-agent coordination, and limited generalization across diverse object geometries. SynAgent, a unified framework presented in "SynAgent: Generalizable Cooperative Humanoid Manipulation via Solo-to-Cooperative Agent Synergy" (2604.18557), directly addresses these limitations by establishing a synergistic skill transfer mechanism from solo human-object interaction (HOI) to multi-agent HOHI scenarios. The framework introduces a methodological pipeline encompassing data refinement, progressive skill acquisition, and a trajectory-conditioned generative policy, demonstrating advancements in physically plausible and controllable cooperative manipulation.
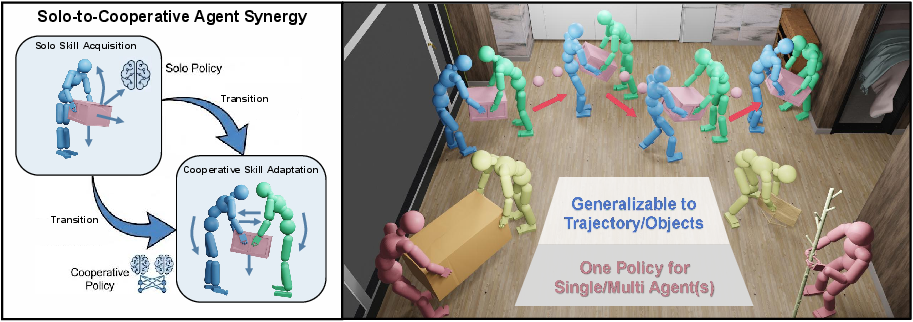
Figure 1: Features of SynAgent. As the first model to address trajectory-following object manipulation with multiple humanoid agents, SynAgent generalizes across diverse object geometries and supports cooperative manipulation.
Interaction-Preserving Motion Retargeting
A foundational aspect of SynAgent is its novel interaction-preserving retargeting method. The inherent skeletal discrepancies between human motion capture (MoCap) actors and simulated humanoid agents typically lead to physically implausible interactions when motions are directly transferred. SynAgent mitigates this through a four-step process. Initially, shape fitting is performed using a differentiable SMPL-X proxy to bridge the morphological gap, converting the retargeting into a differentiable mesh-to-mesh alignment problem. This circumvents the non-differentiability of the agent's native forward kinematics.
Subsequently, an Interact Mesh, constructed via Delaunay tetrahedralization, explicitly preserves the local spatial structure and contact relationships between agent joints and object vertices. The retargeting objective minimizes the Laplacian deformation energy of these Interact Meshes, thereby maintaining semantic topological integrity and contact coherence during motion transfer. Post-processing involves Sobolev norm regularization for root translation and a pre-trained SmoothNet (2412.6980) filter for joint rotations, ensuring both positional and orientational smoothness. Finally, a train-to-filter strategy iteratively purges low-quality motion clips with consistently early termination, enhancing data quality for stable policy training.
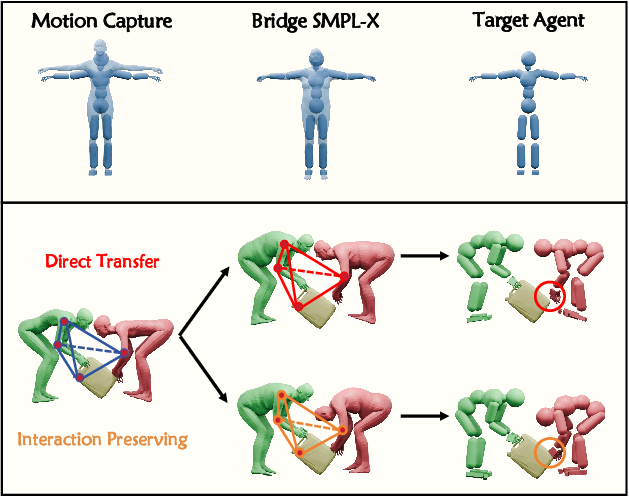
Figure 2: Interaction-Preserving Retargeting. (1) The upper part shows the difference between the MoCap actor and the actual agent's skeletons. And we bridge this difference using shape fitting. (2) In the lower part, the red shows the result of directly retargeting motion capture joints onto the agent, leading to incorrect interaction relationships. The brown area shows how we constructed tetrahedrons to describe the interaction relationships, maintaining the tetrahedron's invariance to ensure the interaction relationships remained unchanged after retargeting.
Solo-to-Cooperative Agent Synergy Paradigm
SynAgent re-conceptualizes cooperative manipulation as a single-agent control problem subjected to external disturbances. This perspective enables the bootstrapping of robust motion imitation priors from abundant single-human HOI data. The training pipeline consists of three stages, maintaining consistent network architecture, hyperparameters, and reward functions throughout.
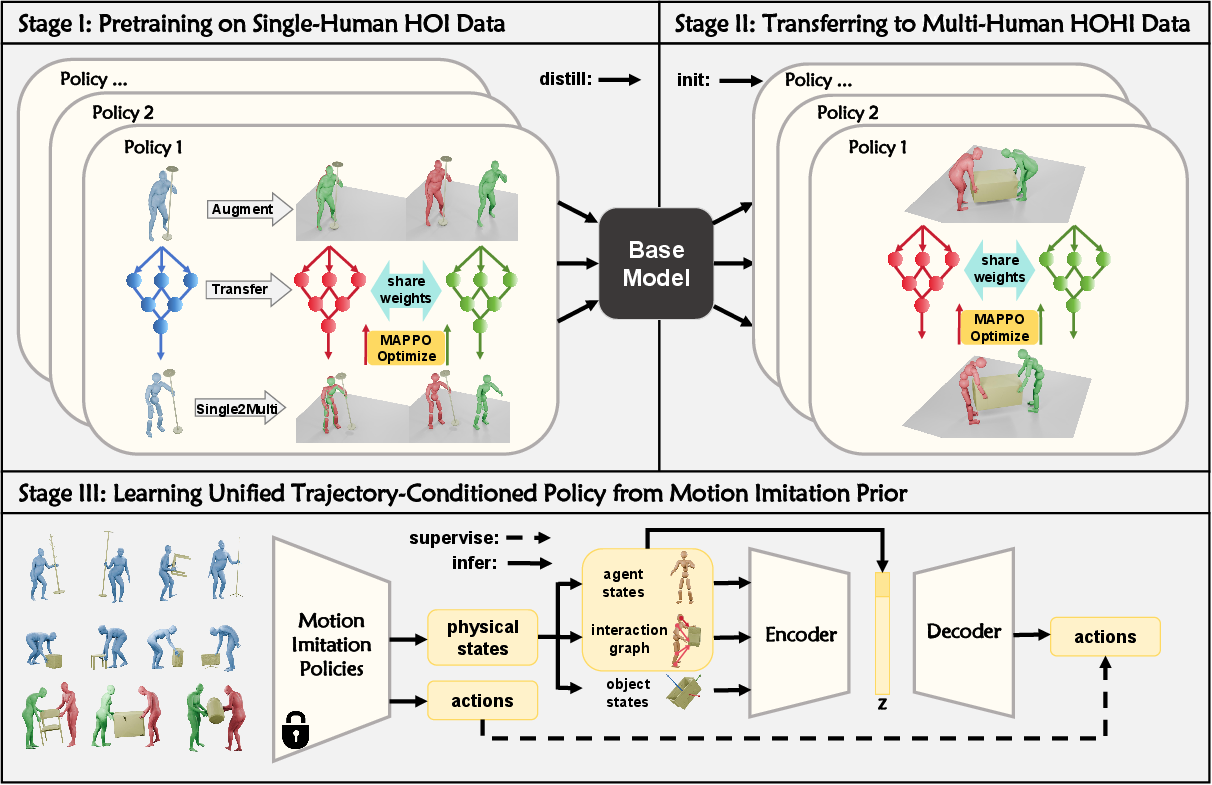
Figure 3: Overview of SynAgent Training Pipeline. (1) Stage I pre-trains imitation policies {πis}i=0N on single-human HOI data, then adapts them to multi-agent scenarios with MAPPO algorithm. (2) After distilling {πis}i=0N into a unified Base Model, Stage II adapts the Base Model to multi-human HOHI data and get policies {πim}i=0M. (3) Stage III learns a trajectory-conditioned cVAE policy. Motion imitation policies {πis}i=0N and {πim}i=0M are used to provide physical states as refined training data, and actions used to supervise learning, which stabilize and boost the model training.
In Stage I, single-human data is partitioned to train individual policies. This data is then augmented by duplicating the human, and a multi-agent policy with shared weights, initialized from the single-agent policies, is trained using Multi-Agent Proximal Policy Optimization (MAPPO) (Szajowski, 2022). This decentralized training paradigm allows agents to perceive each other's presence through object dynamics while initially disabling inter-agent collisions, facilitating the learning of cooperative skills without forgetting single-agent proficiencies.
Stage II unifies these diverse single-human policies into a shared Base Model through distillation. This well-initialized model is then further adapted to multi-human HOHI data, forming a set of policies crucial for the subsequent stage. Experiments demonstrated that this initialization significantly accelerates and stabilizes multi-agent cooperative skill learning compared to training from scratch.
Generalizable Trajectory-Conditioned Policy
The final stage, Stage III, develops a trajectory-conditioned generative policy using a conditional Variational Autoencoder (CVAE). This CVAE is stripped of reference state observations, receiving current agent states, interaction graphs, and object states, with the object states still incorporating reference object trajectories as control signals. The condition for the model is a T×3 sequence denoting the object's 3D position over time. The encoder outputs a latent vector z, which, concatenated with oo, drives the decoder to generate actions.
To address the ill-posed nature of trajectory-conditioned control, SynAgent leverages a Multi-Teacher Distillation framework. Pre-trained imitation policies πimit are used to generate physically consistent state-action pairs (se,ae) from reference data. These pairs provide direct supervision, converting the under-constrained problem into a well-defined one. A progressive skill acquisition schedule, incorporating DAgger-style hyperparameters {πis}i=0N0 and {πis}i=0N1, ensures stable training and a gradual transition from imitation to autonomous action generation. A critical aspect is the switch from a comprehensive imitation reward to a sparse object trajectory tracking error reward after {πis}i=0N2 epochs, encouraging autonomous exploration and enhanced generalization to novel trajectories.
Experimental Validation and Implications
SynAgent's efficacy is demonstrated through extensive experiments on a curated dataset comprising 2,960 physically validated motion sequences from OMOMO (single-human HOI) and CORE4D (multi-human HOHI) datasets, covering 25 distinct object geometries across 9 categories (Figure 4). The interaction-preserving retargeting, posterior smoothing, and train-to-filter data refinement yield substantial improvements in motion quality.

Figure 4: Overview of 25 Objects. Our model can ultimately cover these 25 objects.
In comparative evaluations, SynAgent significantly outperforms existing baselines such as InterMimic (Ranasinghe et al., 13 Jan 2025) in imitation tasks and CooHOI (Zhuang et al., 2024) in trajectory-conditioned control. For instance, in cooperative imitation, SynAgent achieved a 45.00% success rate and an average episode length of 78.74, considerably higher than InterMimic's 7.26% success rate and 51.92 average episode length. For trajectory-conditioned manipulation, CooHOI struggled with generalization, exhibiting success rates as low as 0.00% for complex objects like clothes stands, monitors, and tripods, due to its object abstraction and over-engineered reward system. In contrast, SynAgent demonstrates superior control capabilities and robust geometric generalization, with 'Ours-2' (utilizing interaction graphs) achieving an overall success rate of 19.16% and an average distance of 0.7939, substantially exceeding CooHOI's 7.28% success rate and 1.3074 average distance. The qualitative results further highlight SynAgent's capacities (Figure 5).

Figure 5: Qualitative Results. In the comparison between Ours and existing comparable baselines, the blue and green agents are the test results from Ours. In Comparison of Control, the green ball represents the trajectory control signal. In Performance of Retargeting, “direct" indicates that MoCap data is directly transferred to the agent, “orig" represents the raw MoCap data, and “retarget" represents the effect of using our Interaction-preserving retargeting.
Ablation studies confirm the criticality of the integrated components. Training without initialization from the Base Model resulted in a sharp performance degradation (3.33% success rate vs. 21.82% for the full model), emphasizing the importance of solo-to-cooperative skill transition. Similarly, disabling interaction-preserving retargeting or the train-to-filter strategy led to significant performance drops (2.42% and 1.43% success rates, respectively), underscoring the necessity of a rigorous data refinement pipeline. The architectural choice of a decentralized policy with shared weights for multi-agent tasks also proved superior to a centralized approach, offering better empirical performance and scalability.
The theoretical implications of SynAgent are substantial. By demonstrating the effective transfer of skills from abundant single-agent data to challenging multi-agent cooperative settings, it provides a principled approach to overcoming data scarcity in complex embodied intelligence tasks. The explicit modeling of interaction semantics via Interact Meshes and the integration of geometric cues through interaction graphs offer a robust framework for handling diverse real-world object geometries. The multi-teacher distillation process for trajectory-conditioned generative policies represents an advancement in learning precise and stable object-level control.
Practically, SynAgent offers a scalable foundation for developing humanoid robots capable of complex cooperative tasks. Its ability to generalize across objects and maintain physical plausibility under varied interaction patterns has direct relevance for applications ranging from industrial robotics to assisted care and interactive virtual environments. While the current work focuses on 0-to-1 exploration of physics-based dual-agent cooperative manipulation, its modular design suggests future developments could involve scaling to more diverse and complex interaction behaviors, potentially integrating with higher-level planning systems and more sophisticated sensor modalities as larger, higher-quality HOHI datasets become available.
Conclusion
SynAgent introduces a comprehensive framework for generalizable cooperative humanoid manipulation, addressing critical challenges in data quality, multi-agent coordination, and trajectory-conditioned control. Through its innovative interaction-preserving retargeting, solo-to-cooperative agent synergy paradigm, and trajectory-conditioned generative policy, SynAgent significantly advances the state-of-the-art in physics-based, multi-humanoid interaction. The demonstrated superior performance and robust generalization capabilities establish a strong foundation for future research in embodied AI, facilitating the progression towards more sophisticated and scalable multi-agent systems.

