HumanX: Toward Agile and Generalizable Humanoid Interaction Skills from Human Videos
Abstract: Enabling humanoid robots to perform agile and adaptive interactive tasks has long been a core challenge in robotics. Current approaches are bottlenecked by either the scarcity of realistic interaction data or the need for meticulous, task-specific reward engineering, which limits their scalability. To narrow this gap, we present HumanX, a full-stack framework that compiles human video into generalizable, real-world interaction skills for humanoids, without task-specific rewards. HumanX integrates two co-designed components: XGen, a data generation pipeline that synthesizes diverse and physically plausible robot interaction data from video while supporting scalable data augmentation; and XMimic, a unified imitation learning framework that learns generalizable interaction skills. Evaluated across five distinct domains--basketball, football, badminton, cargo pickup, and reactive fighting--HumanX successfully acquires 10 different skills and transfers them zero-shot to a physical Unitree G1 humanoid. The learned capabilities include complex maneuvers such as pump-fake turnaround fadeaway jumpshots without any external perception, as well as interactive tasks like sustained human-robot passing sequences over 10 consecutive cycles--learned from a single video demonstration. Our experiments show that HumanX achieves over 8 times higher generalization success than prior methods, demonstrating a scalable and task-agnostic pathway for learning versatile, real-world robot interactive skills.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview of the Paper
This paper is about teaching humanoid robots (robots shaped like people) to do fast, smooth, and adaptable actions with objects and people—things like dribbling and shooting a basketball, kicking a football, picking up boxes, hitting a badminton shuttlecock, and even reacting to a human in a playful “sparring” scenario. The key idea is to let robots learn these skills by watching short human videos, rather than needing lots of special training or hand-crafted rules for each task.
Goals and Big Questions
The paper tries to answer simple but important questions:
- Can a robot learn complex interaction skills (like catching and passing a ball) from just one short video of a human doing it?
- Can these learned skills work in many slightly different situations (for example, the ball is thrown from a different angle or the box is in a new place)?
- Can we avoid writing detailed “reward rules” for each task and instead use a general way for the robot to learn by imitation?
- Can the learned skills be used on a real humanoid robot, not just in simulation?
How It Works (Methods Explained Simply)
The system is called HumanX, and it has two main parts that work together:
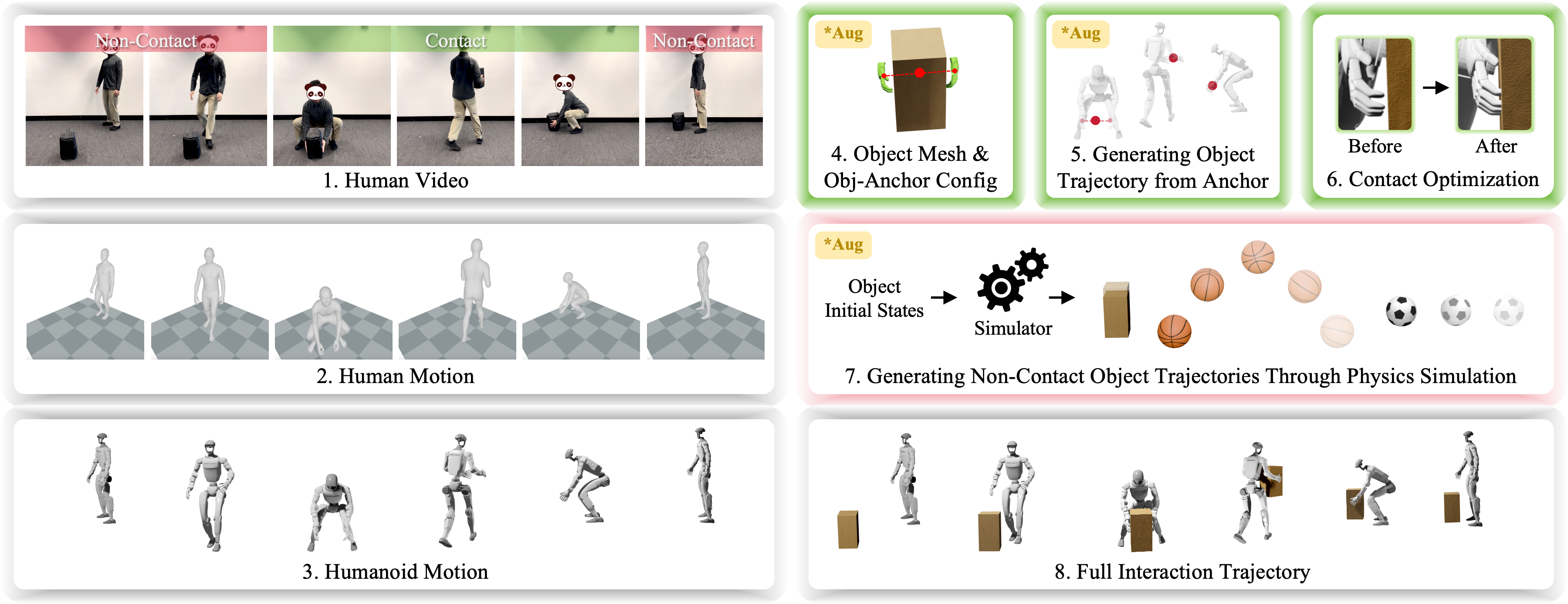
XGen: Making Good Practice Data from Human Videos
Think of XGen like a smart “video-to-practice” machine:
- It watches a human video of a skill (for example, someone lifting a box or doing a basketball layup).
- It converts the human’s movement into a version a robot can use (like matching human arms to robot arms).
- It focuses on making the interaction physically believable, not just visually perfect. For example, if the hands hold a box, XGen ensures the box stays in the right place between the hands without magically popping or sliding through fingers.
- It separates the action into “contact” (hands touching the object) and “non-contact” (object flying or resting) parts:
- Contact part: It uses simple “anchor points” (like the midpoint between two palms) to keep the object correctly attached to the hands and tweaks the robot’s pose so the grip is physically stable.
- Non-contact part: It uses a physics simulator (like a digital sandbox that obeys gravity and collisions) to create realistic object motion, such as the arc of a thrown ball.
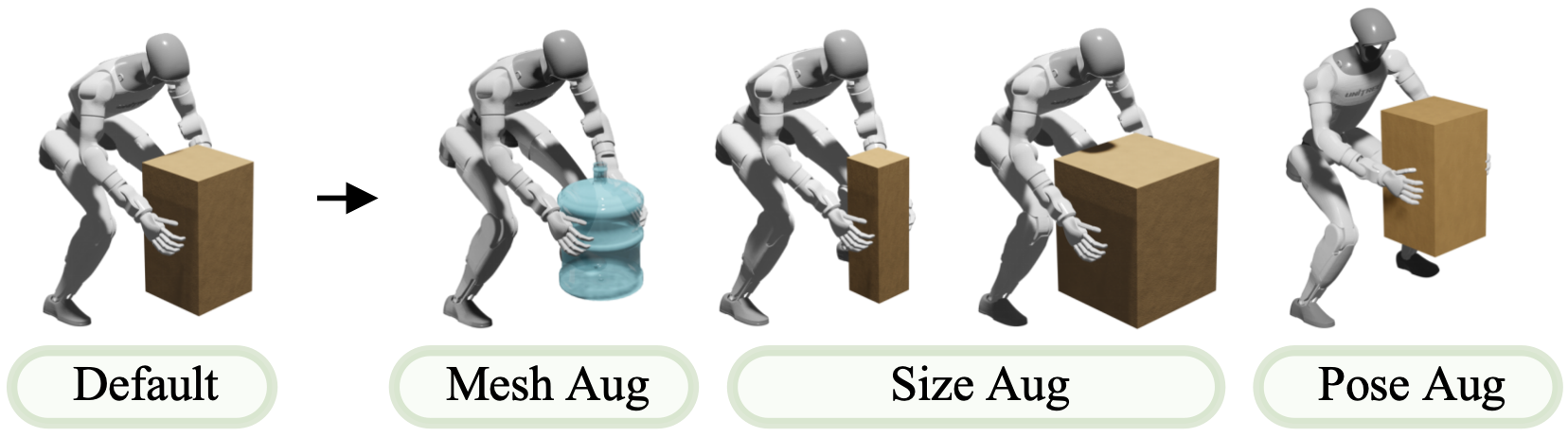
- It augments (varies) the data to create more practice examples from just one video:
- Changes object size or shape (a bigger box, a different ball).
- Shifts paths (the ball comes from a slightly different place or speed).
- Adjusts positions (the box starts on a higher or lower shelf).
This is like turning one training clip into a big set of realistic practice drills, so the robot doesn’t just memorize—it learns to handle variations.
XMimic: Teaching the Robot to Imitate and Generalize
XMimic is the learning part—how the robot’s “brain” learns the skill:
- It uses a “teacher–student” approach:
- The teacher policy learns first with extra information (like precise object positions) in simulation, so it can master the skill accurately.
- Then the student policy learns from the teacher, but with more realistic, limited information—like a real robot would have. This makes the student ready for the real world.
- Two ways the robot perceives the world:
- No External Perception (NEP): The robot doesn’t get camera/object tracking. Instead, it “feels” what’s happening through its own joints and forces (similar to how you can feel a ball in your hands without looking). This mode is great for skills where the robot keeps contact (like dribbling or layups) but not for catching flying objects.
- MoCap mode: A motion-capture system gives the robot the position of objects (like the ball). Because tracking can hiccup (occlusions), XMimic trains with fake data dropouts so the robot stays stable even when sensor data briefly disappears.
- A unified imitation reward: Rather than writing a different “score formula” for each task, XMimic uses a general setup that:
- Encourages the robot’s body to move like the human.
- Tracks the object’s motion correctly.
- Keeps the right relationship between body parts and the object (e.g., hands aligned with a ball).
- Matches contact timing (e.g., when to grab or release).
- Stays smooth and natural.
To boost generalization (handling new variations), they also:
- Randomly perturb starting positions and poses during training (like practicing from different starting stances).
- Randomize physics (object weight, bounciness, friction) and add random pushes so the robot can cope with surprises.
- Use “interaction termination” so the robot doesn’t cheat by only moving nicely—it must actually complete the interaction (e.g., catch and shoot).
Main Results and Why They Matter
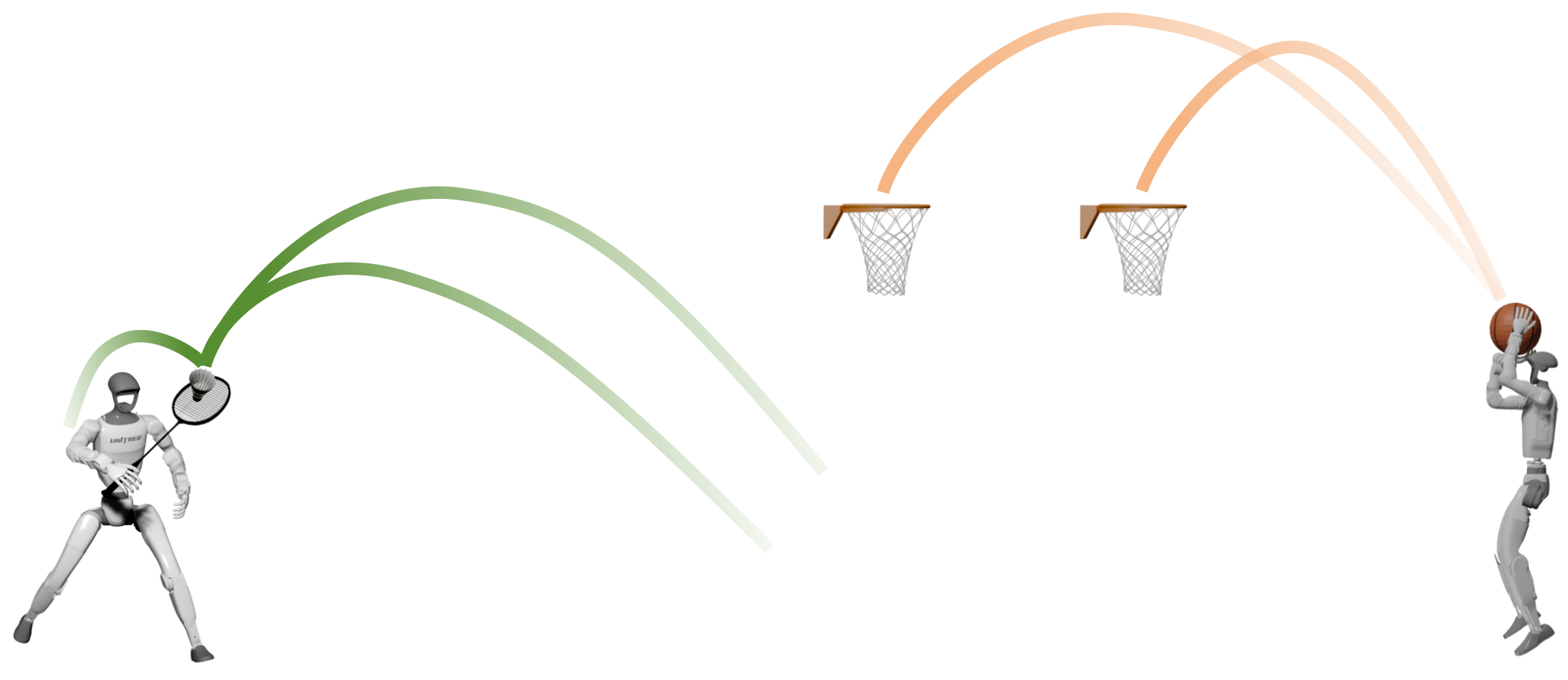
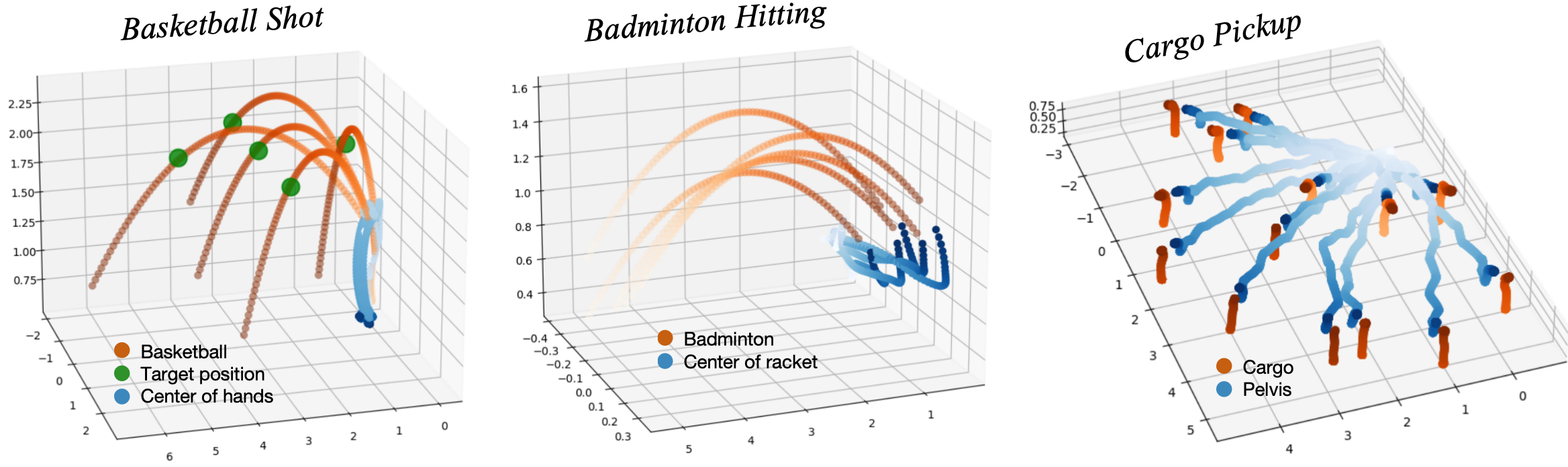
The team tested HumanX on a real Unitree G1 humanoid robot and in simulation, across five areas: basketball, football, badminton, cargo pickup, and reactive fighting. They taught 10 different skills using only single human videos per skill. Key highlights:
- Strong generalization (about 8× better than previous methods): The robot didn’t just copy a single demonstration—it adapted when the ball’s path, target location, or object position changed.
- Real robot success:
- NEP mode (no object sensing): The robot performed basketball skills like dribbling, layups, jumpshots, and even complex pump-fake turnaround fadeaway moves, with high success rates (around 80% on average for many moves).
- MoCap mode (with object tracking): The robot did closed-loop interactions with a person, like over 10 back-and-forth basketball passes and more than 14 consecutive football returns.
- Learned from single videos: Each skill came from just one human demonstration, then XGen created lots of realistic practice variations.
- Emergent adaptive behaviors:
- If someone took a box from the robot and set it down elsewhere, the robot walked over and picked it up again.
- In the “fighting” demo, the robot reacted differently to feints versus real punches, showing basic interactive judgment.
Why this matters:
- It proves robots can learn rich, human-like interactions with little data and without hand-writing specific reward rules for each task.
- It shows a scalable path toward robots that can learn new skills from everyday videos and work in real homes, warehouses, or sports training scenarios.
Implications and Potential Impact
This research points to a future where:
- Robots learn new skills as easily as watching YouTube clips—great for fast training without expensive, time-consuming setups.
- Humanoid robots become more natural partners in human environments, handling objects, playing sports, assisting with chores, or cooperating with people.
- Developers can build versatile robot skills without crafting detailed rules for every single task, saving time and making progress faster.
In short, HumanX shows that “learning by watching” can give humanoid robots agile, generalizable interaction skills, taking a big step toward robots that adapt smoothly to the messy, varied real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research:
- Automatic contact-phase segmentation is not addressed; XGen’s contact/non-contact phases are annotated by timestamps, leaving open robust, automatic detection of contact events from video under occlusions and motion blur.
- The anchor-based interaction representation assumes a fixed relative pose during contact (e.g., midpoint between palms), which may fail for complex interactions involving sliding contacts, regrasping, multi-point contacts, or compliance; methods for learning or adapting anchors and handling time-varying relative poses are unstudied.
- Object geometry and pose often require manual definition when not visible; there is no validated pipeline for reliable object reconstruction from monocular video under heavy occlusion, fast motion, or challenging textures.
- XGen’s physics synthesis relies on simplified rigid-body models and “inverted damping” for reverse simulation; the physical fidelity and stability of this approach for fast-moving, spinning, or aerodynamically affected objects (e.g., shuttlecocks, balls with spin) remains unquantified.
- Force-closure optimization is applied frame-by-frame without trajectory-level consistency; long-horizon grasp stability, contact switching, and slip modeling are not optimized jointly, risking jitter and suboptimal contact realism.
- Deformable and articulated objects (e.g., cloth, bags, doors, tools with joints) are not considered; extending XGen/XMimic to non-rigid or articulated interactions is unexplored.
- Data augmentation in XGen is limited to object scaling, translations, and initial-velocity randomization; richer variations (surface friction, compliance, shape changes, textures, lighting, environmental obstacles) and their impact on generalization are not examined.
- XMimic primarily operates with proprioception (NEP) or MoCap-based object/human poses; there is no integration of onboard vision (RGB/RGB-D) for perception, limiting deployability beyond controlled MoCap environments.
- NEP mode cannot handle non-contact interactions requiring exteroception (e.g., catching a flying object); how to bridge that gap with onboard sensing, predictive models, or learned haptics remains open.
- MoCap-based deployment is demonstrated in a small, controlled capture volume; robustness to larger spaces, occlusions, ID switches, latency, and multi-object tracking beyond simulated frame loss is not systematically evaluated.
- Policies are trained and deployed on a single embodiment (Unitree G1); despite cross-embodiment claims, zero-shot or few-shot transfer to different humanoid morphologies is not tested.
- Real-world experiments cover a limited set of object types and environments (flat floors, few obstacles); performance in cluttered, outdoor, or uneven terrains is not assessed.
- Badminton is only evaluated in simulation; real-world validation for very high-speed interactions (e.g., shuttlecock hitting) and limits of 100 Hz control are untested.
- The unified reward uses a reference contact graph and fixed weights; sensitivity to weight choices, failure modes when contact timing/locations deviate from demonstrations, and automatic reward tuning are not reported.
- The student policy architecture appears to be a feedforward MLP; no use of recurrent memory for POMDP settings (e.g., occlusions, delayed MoCap), and no comparison to memory-augmented policies.
- External force inference from proprioception is theoretically motivated but not empirically ablated; the incremental benefit versus explicit force/torque sensing and the effect of actuator model errors or unmodeled friction are unknown.
- Domain randomization ranges (e.g., friction, restitution, CoM offsets) are not detailed or stress-tested; the contribution of each DR component to sim-to-real performance and failure modes remains unclear.
- Generalization tests use relatively narrow perturbation ranges (e.g., ±0.3 m) and single-object settings; scalability to wider state distributions, multi-object interactions, and multi-agent scenarios is not evaluated.
- Interaction safety with humans (e.g., fighting task) lacks formal analysis or guarantees; safe-force limits, collision detection, compliance strategies, and emergency behaviors are not specified.
- The framework relies on single-video demonstrations per skill plus augmentation; how performance scales with more demonstrations, noisy/low-quality videos, or semantic diversity is unexamined.
- Multi-pattern learning is shown with 3 patterns per sop; scalability to dozens of patterns, pattern compositionality, and conflict resolution among patterns are open questions.
- High-level sequencing, task composition, and goal conditioning (e.g., via language or symbolic instructions) are not explored; skills are trained and evaluated as stand-alone behaviors.
- XGen’s reliance on monocular pose estimators (GVHMR) inherits scale and depth ambiguities; the impact of these errors on downstream learning and how to mitigate them (multi-view, IMUs, SLAM) is not addressed.
- Real-time latency handling (policy, MoCap, control loop) and its effect on fast interactions are not quantified; controllers for latency compensation or predictive control are absent.
- Reproducibility details (reward weights, network sizes, optimizer settings, full DR ranges) are sparse; standardized benchmarks and public datasets for fair comparison are not provided.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging HumanX’s demonstrated pipeline (XGen + XMimic), NEP/MoCap perception modes, and sim-to-real results on a Unitree G1.
- Video-to-skill compilation for warehouse material handling
- Sectors: robotics, logistics, manufacturing
- Tools/products/workflows: “Video-to-skill” compiler that turns smartphone clips of lifts/carries into deployable policies; XGen augmentation for object size/pose variability; XMimic teacher–student training; MoCap mode for object localization; DI/DR/IT in training for robustness
- Assumptions/dependencies: Humanoid hardware with comparable DoFs and strength to G1; task objects within trained geometry/mass ranges; safe workspace and supervision; access to GPUs and Isaac Gym (or equivalent) for training; object mesh estimation (SAM-3D) or manual specification
- Sports/entertainment humanoids for interactive demos
- Sectors: entertainment, sports marketing, retail experiences
- Tools/products/workflows: NEP mode for ball-in-hand skills (dribble, layup, jumpshot, pump-fake fadeaway); MoCap mode for sustained pass/kick interactions with visitors; multi-pattern policies (teacher–student) for varied moves
- Assumptions/dependencies: Safety perimeter and compliant control; balls and prop dynamics within trained DR ranges; venue support for MoCap (when needed) and occlusion handling
- Proprioception-only interaction controllers for perception-degraded settings
- Sectors: industrial robotics, field robotics
- Tools/products/workflows: Deploy NEP student policies that infer external forces from proprioception for contact-rich tasks (e.g., carrying, dribbling, stable grasp recovery); integration with existing PD controllers
- Assumptions/dependencies: Tasks that don’t require pre-contact object tracking; adequate coverage of contact dynamics during training; platform-specific PD gains and torque limits
- MoCap-augmented human–robot interaction (HRI) installations
- Sectors: museums, theme parks, showrooms, live events
- Tools/products/workflows: MoCap-driven tracking of props/partners for closed-loop catching/passing/kicking; training with simulated MoCap frame loss for real-world robustness; scripted multi-cycle engagements
- Assumptions/dependencies: MoCap infrastructure and calibration; clear line of sight for markers; policies trained with dropout to handle occlusions; staff trained for safe operation
- Rapid prototyping of new humanoid behaviors in R&D
- Sectors: robotics startups, product engineering, academia
- Tools/products/workflows: Internal pipeline to capture a single video, auto-synthesize interaction data with XGen (including anchor definitions and force-closure refinement), and train XMimic with DI/DR/IT; A/B testing across augmentation settings; skill regression tests
- Assumptions/dependencies: Retargeting quality (GMR) for target morphology; GPU compute; reproducible simulation setup; safety review for deployment
- Synthetic interaction dataset generation for imitation learning
- Sectors: AI/ML data providers, robotics research
- Tools/products/workflows: Use XGen to expand a single demo into large, physically plausible HOI datasets (scaled meshes, diverse trajectories, contact/non-contact segments); publish benchmark splits with generalization ranges
- Assumptions/dependencies: Reliability of human pose estimation (GVHMR) and contact segmentation; physics parameters calibrated to target platforms; licensing/consent for source videos
- Safety and robustness testing workflows for HRI
- Sectors: certification, QA, safety consulting, standards bodies
- Tools/products/workflows: Test plans leveraging interaction termination (IT), domain randomization, and sustained external force injections to quantify stability and recovery; generalization success metrics (GSR) as acceptance criteria
- Assumptions/dependencies: Agreement on metrics and thresholds with regulators; reproducibility of simulation conditions; standardized reporting
- Educational labs and courses on video-based skill learning
- Sectors: academia, workforce upskilling
- Tools/products/workflows: Teaching modules that walk through XGen synthesis, anchor selection, force-closure optimization, XMimic’s unified reward, and teacher–student distillation; Isaac Gym labs; evaluation on generalization
- Assumptions/dependencies: Access to GPUs and simulators; compatible open-source implementations or licenses; institution safety policies for real-robot demos
Long-Term Applications
These applications are plausible extensions but require further research, scaling, or infrastructure (e.g., broader perception, dexterous hands, regulatory clearances).
- Consumer humanoids learning household skills from user videos
- Sectors: consumer robotics, smart home
- Tools/products/workflows: Cloud/on-device “video-to-skill” services for chores (tidying, carrying, simple tool use); anchor-based authoring for diverse objects; multi-pattern policies for variability
- Assumptions/dependencies: Robust perception in clutter (beyond MoCap), dexterous grippers/hands, stronger generalization to household objects, privacy-preserving training, safety certification
- On-the-fly factory upskilling by filming expert operators
- Sectors: manufacturing, logistics
- Tools/products/workflows: Floor supervisors record one video per task; pipeline compiles policies and augments object/tool geometries; centralized skill library and deployment tooling; easy retargeting across plant robots
- Assumptions/dependencies: Precise non-contact perception for pre-grasp phases (vision, depth, markers); variability in fixtures and tools; end-effector standardization; line integration and safety approvals
- Assistive and rehabilitation robots learning from clinician demonstrations
- Sectors: healthcare, eldercare
- Tools/products/workflows: Policies for gentle hand-overs, object delivery, mobility aid assistance; multi-pattern teacher–student to adapt to patient variability; human-state perception beyond props
- Assumptions/dependencies: High-fidelity compliance and tactile sensing; rigorous safety/ethics oversight; regulatory clearance (FDA/CE); caregiver-in-the-loop validation; low-impact failure modes
- Skill marketplaces and standardized libraries for humanoids
- Sectors: software platforms, robotics ecosystems
- Tools/products/workflows: Distribution of pre-trained XMimic policies and associated XGen datasets with metadata on domain randomization ranges and supported morphologies; ROS2 packages and CI for skill regression
- Assumptions/dependencies: Cross-embodiment compatibility (high-quality retargeting); IP/licensing for human-derived skills; versioning, benchmarking, and governance
- Policy and governance frameworks for training from human video
- Sectors: policy, legal, standards
- Tools/products/workflows: Guidelines on consent, provenance, and IP for video-sourced skills; bias and safety audits; standardized generalization/safety metrics (e.g., GSR, IT-trigger rates) for certification
- Assumptions/dependencies: Multi-jurisdiction legal harmonization; enforceable audit requirements; stakeholder buy-in (industry, academia, consumer advocates)
- Collaborative multi-agent interaction (humans + multiple robots)
- Sectors: robotics, entertainment, advanced manufacturing
- Tools/products/workflows: Extend XGen to synthesize multi-object and multi-actor interactions; student policies coordinating patterns; shared perception (multi-camera, VIO) and communication to handle occlusions/latency
- Assumptions/dependencies: Scalable perception and time synchronization; conflict-free role assignment; safety envelopes; formal verification of coordination
- Embodied foundation models pre-trained from human video
- Sectors: AI research, platform robotics
- Tools/products/workflows: Use XGen to curate massive, physically plausible HOI datasets; pretrain generalist policies or world models; align with vision-LLMs for instruction following; RLHF for safety
- Assumptions/dependencies: Large-scale compute; curation to avoid unsafe behaviors; evaluation suites for interaction generalization and alignment
- Disaster response and public safety robots with proprioceptive fallback
- Sectors: emergency services, public safety
- Tools/products/workflows: Train safe interaction policies from rescue task videos; NEP fallback when vision fails (dust/smoke); object handling and debris clearing with interaction termination safeguards
- Assumptions/dependencies: Ruggedized hardware; expanded DR for extreme terrains; teleop override; ethical and legal frameworks for deployment
- Sports coaching and training aids that mimic pro moves
- Sectors: sports science, education
- Tools/products/workflows: Compile skills from professional footage for consistent demonstrations; interactive drills (passes, returns); analytics on movement and object trajectories
- Assumptions/dependencies: Legal rights to use footage; field-scale perception and localization; safety around athletes and spectators
- AR authoring tools for non-technical users to specify anchors/objects
- Sectors: creative tools, HRI, education
- Tools/products/workflows: AR apps to annotate anchors and object poses in captured videos, preview physics-based synthesis, and export trainable interaction clips
- Assumptions/dependencies: Robust mobile SLAM; intuitive UX for contact phase specification; automatic plausibility checks; device performance constraints
- Robot self-improvement via continuous learning from in-situ video
- Sectors: operations, maintenance
- Tools/products/workflows: Robots (or supervisors) capture in-situ clips of near-misses or failures; XGen synthesizes corrective interactions; XMimic updates student policy with new patterns while preserving safety
- Assumptions/dependencies: Reliable on-site video capture; safe on-policy updates (offline or supervised online); drift monitoring and rollback mechanisms
These applications rely on HumanX’s core innovations—physics-governed interaction synthesis (XGen), unified interaction-imitation rewards, teacher–student distillation, proprioception-based force inference, and robust training strategies (DI/DR/IT)—and are bounded by dependencies such as platform capability, perception availability, data rights, and safety constraints.
Glossary
- 6D pose: A six-parameter representation combining 3D position and 3D orientation of a rigid body. "represents the 6D pose (3D position and 3D orientation) of the human root,"
- Adversarial Motion Prior (AMP): A learned prior using adversarial training to encourage natural-looking motions during imitation. "and includes an adversarial motion prior (AMP) term for naturalness"
- Anchor: A predefined reference point on the body used to maintain relative pose with an object during contact. "a predefined anchor (e.g., the midpoint between the two palms) is used."
- Behavior Cloning (BC): A supervised learning approach that imitates expert demonstrations by directly mapping observations to actions. "While behavior cloning (BC) offers a unified training paradigm,"
- Center of Mass (CoM) offsets: Variations in the location of a robot’s center of mass used to improve robustness via randomization. "as well as robot friction coefficients, center of mass offsets, and perception noise."
- Coefficient of restitution: A measure of how bouncy a collision is, influencing post-impact velocities of objects. "including object size, mass, and coefficient of restitution,"
- Contact-aware refinement: Optimization that adjusts poses considering contact constraints to improve physical plausibility. "coupled with contact-aware refinement"
- Contact graph: A representation specifying which body parts should be in contact with objects at specific times. "deviations from the reference contact graph"
- Coriolis: Forces arising from rotational motion that affect the dynamics of moving bodies. "the sum of inertial, Coriolis, gravitational, and frictional components."
- Cross-embodiment: Properties or representations that transfer consistently across different robot or human morphologies. "exhibits favorable crossâembodiment properties,"
- Damping coefficients: Parameters that model velocity-dependent resistive forces, used to adjust simulation behavior. "object damping coefficients are inverted."
- Degrees of Freedom (DoF): The number of independent parameters that define a robot’s configuration. "(where is the number of robot DoFs)"
- Domain Randomization (DR): Training technique that randomizes environment and physical parameters to improve sim-to-real robustness. "We apply domain randomization (DR) to various physical properties"
- Force-aware interaction: Interaction behaviors that infer and respond to external forces using proprioceptive signals. "enabling force-aware interaction without dedicated force/torque sensors."
- Force-closure constraints: Conditions ensuring that grips can resist external disturbances and maintain stable contact. "optimized under forceâclosure constraints to ensure physical plausibility during contact."
- Gaussian distribution (policy): A common stochastic policy parameterization where actions are sampled from a Gaussian. "the policy output is parameterized as a Gaussian distribution:"
- GVHMR: A method for estimating human 3D pose and shape from video. "using GVHMR \cite{shen2024gvhmr}."
- Human-Object Interaction (HOI): Tasks and behaviors involving coordinated motion and contact between a human/robot and objects. "introduced Human-Object Interaction (HOI) imitation,"
- Isaac Gym: A high-performance GPU-based physics simulation platform for training robot policies. "All training and simulation were conducted on the Isaac Gym platform"
- Interaction Termination (IT): An episode termination strategy that prioritizes interaction success by ending runs when key interaction errors grow. "we propose Interaction Termination (IT)."
- Inverse Kinematics (IK): A method to compute joint configurations that achieve desired end-effector positions/orientations. "IK-based optimization."
- MoCap (Motion Capture): A sensing system that tracks object or human motion using cameras and markers. "object observations are provided by a MoCap system."
- No External Perception (NEP) mode: A deployment setting where the policy operates without external object sensing, relying on proprioception. "a No External Perception (NEP) mode"
- Object mesh: The polygonal 3D geometry representing an object’s shape used in simulation and pose estimation. "The object mesh and its relative pose to the anchor are estimated"
- PD controller: A proportional-derivative control law that converts desired actions into joint torques. "via a PD controller."
- Privileged state observation: An observation that includes extra, non-deployable information (e.g., full object state) for training teacher policies. "the policy receives a privileged state observation"
- Proprioception: Internal sensing of the robot’s own states like joint positions and velocities. "comprises proprioception "
- Proximal Policy Optimization (PPO): A reinforcement learning algorithm that optimizes policies with clipped objective functions for stability. "optimized using PPO \cite{schulman2017proximal}"
- Relative motion reward: A reward term encouraging correct spatial relationships between the robot and object during interaction. "The relative motion reward $r_{t}^{\text{rel}$ encourages correct bodyâobject relative spatial relationships,"
- Retargeting: Mapping human motion data onto a robot’s kinematics while preserving task semantics. "Retargeting human motion to humanoids and applying reinforcement learning for imitation has shown significant promise"
- SAM-3D: A tool for estimating 3D object meshes and poses from images or video. "using SAM-3D \cite{chen2025sam}."
- Sim-to-real gap: Differences between simulation and real-world dynamics that hinder direct policy transfer. "the complex simâtoâreal gap introduced by object dynamics,"
- SMPL: A parametric human body model used to represent 3D human pose and shape. "SMPL \cite{Loper2023SMPLAS} joints."
- Teacher-Student paradigm: A training setup where a teacher policy with privileged information is distilled into a deployable student policy. "two-stage teacher-student paradigm"
- Unitree G1 humanoid: A specific commercially available humanoid robot used for real-world deployment. "Unitree G1 humanoid."
- Zero-shot: Transferring or deploying learned skills to new settings without additional task-specific training. "transfers them zeroâshot to a physical Unitree G1 humanoid."
Collections
Sign up for free to add this paper to one or more collections.