- The paper finds that TurboQuant is a constrained instantiation of EDEN by fixing the reconstruction scalar S to 1 instead of optimizing it for minimum MSE.
- Empirical evaluations show that EDEN-biased achieves lower MSE distortion and more stable downstream retrieval performance across various dimensions and bit-widths.
- The study demonstrates that both unbiased and bias-optimized EDEN reconstructions offer superior accuracy and bit-efficiency compared to TurboQuant.
Rigorous Analysis of TurboQuant and the Earlier DRIVE/EDEN Line of Work
Background and Algorithmic Relationships
The paper systematically clarifies the relationship between TurboQuant—publicly promoted as a novel approach for AI memory efficiency—and the previously-established DRIVE and EDEN quantization frameworks. It highlights that TurboQuantmse constitutes a restrictive, suboptimal instantiation of EDEN, realized by fixing EDEN’s scalar reconstruction factor S to $1$, rather than optimizing S for minimum mean squared error (MSE) or achieving unbiasedness. The EDEN framework supports both biased and unbiased reconstructions: the optimal S for biased quantization converges to $1$ with growing dimensionality, rendering TurboQuant congruent to EDEN only in this limit. However, empirical and theoretical results throughout the displayed dimensional and bit-width ranges indicate the biased EDEN with optimal S exhibits consistently lower distortion.
Comparative Empirical Evaluation
The paper emphasizes the systematic comparative evaluation between TurboQuant and EDEN across multiple quantization regimes and downstream tasks:
- MSE Distortion: The biased EDEN approach always outperforms TurboQuantmse in terms of MSE, with percentage improvements rising with bit-width and remaining significant in moderate dimensions.
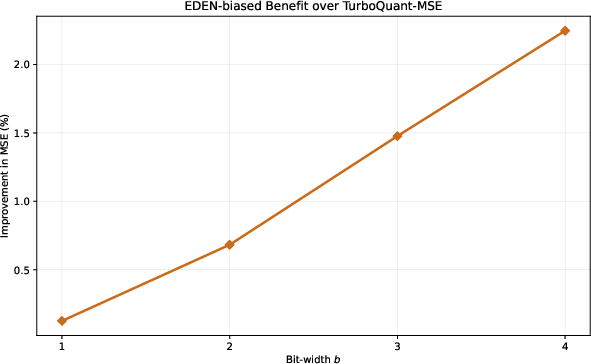
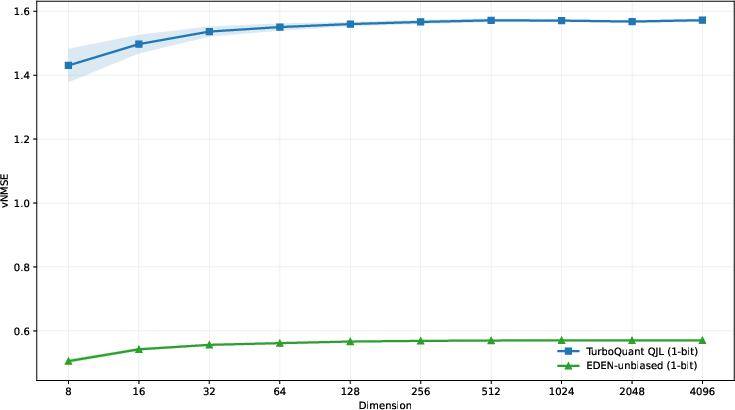
Figure 1: Percentage MSE improvement of EDEN-biased over TurboQuantmse on LogNormal(0,1) vectors at dimension S0; relative gains are S1, S2, S3, and S4 for S5 to S6 bits, respectively.
- Residual Quantization: TurboQuantS7 utilizes a QJL-based 1-bit residual quantizer that is provably and empirically weaker than EDEN-unbiased/DRIVE, with vNMSE converging to approximately S8 for DRIVE versus S9 for QJL, manifesting a clear disadvantage.
Figure 1: EDEN-unbiased significantly outperforms TurboQuant's QJL estimator in 1-bit residual quantization across all dimensions.
- Bit-Efficiency: TurboQuant$1$0’s split between biased $1$1-bit and 1-bit QJL quantization performs worse than an unbiased $1$2-bit EDEN quantizer, with EDEN matching the performance of TurboQuant using fewer bits.
- Downstream Metrics: EDEN-unbiased yields lower error and higher nearest-neighbor recall in inner-product estimation and retrieval tasks. Its error distribution is more concentrated and stable under varying signal strength.
Algorithmic Structure and Analytical Parallels
Both TurboQuant and EDEN exploit randomized rotation, Lloyd-Max quantization, and distributional analysis based on the shifted Beta distribution. The paper elaborates unified pseudocode and reconstructs the algorithmic equivalence, differing only in the selection of the reconstruction scalar $1$3. EDEN enables optimal bias and unbiased scaling, whereas TurboQuant restricts $1$4 to $1$5, missing potential accuracy improvements unless in very high-dimensional regimes.
Extended Empirical Reproduction and Analysis
The paper reproduces TurboQuant's original empirical results and presents additional figures comparing both methods in multidimensional settings, including:
- Aggregate Accuracy, Inner-Product Error, and Recall: EDEN-unbiased consistently surpasses TurboQuant$1$6 in accuracy, both in distributional error concentration and retrieval recall for real-world embedding tasks.
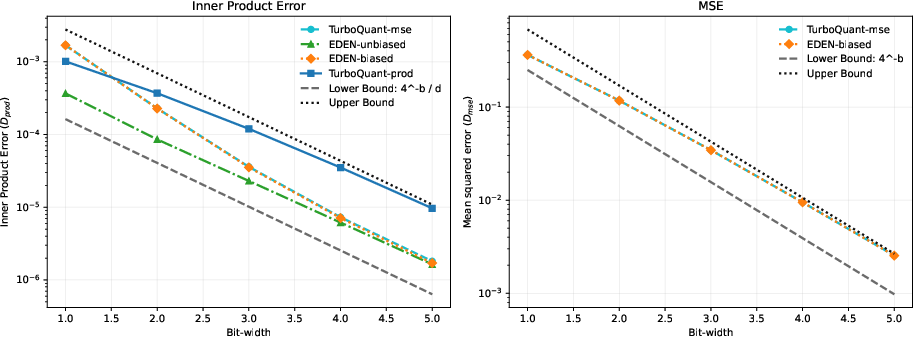
Figure 2: EDEN-unbiased yields superior accuracy curves and outperforms TurboQuant$1$7 in inner-product estimation.
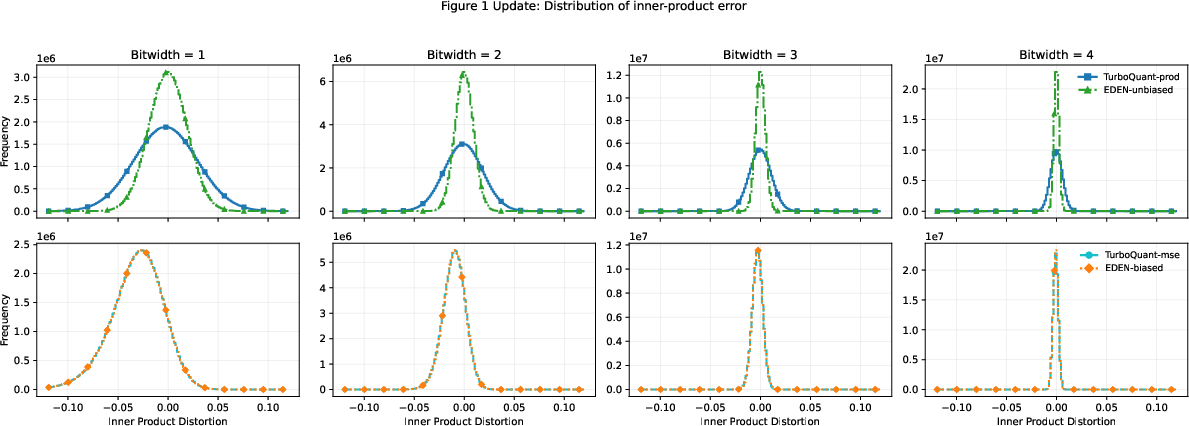
Figure 3: EDEN-unbiased displays a more concentrated inner-product error distribution than TurboQuant$1$8.
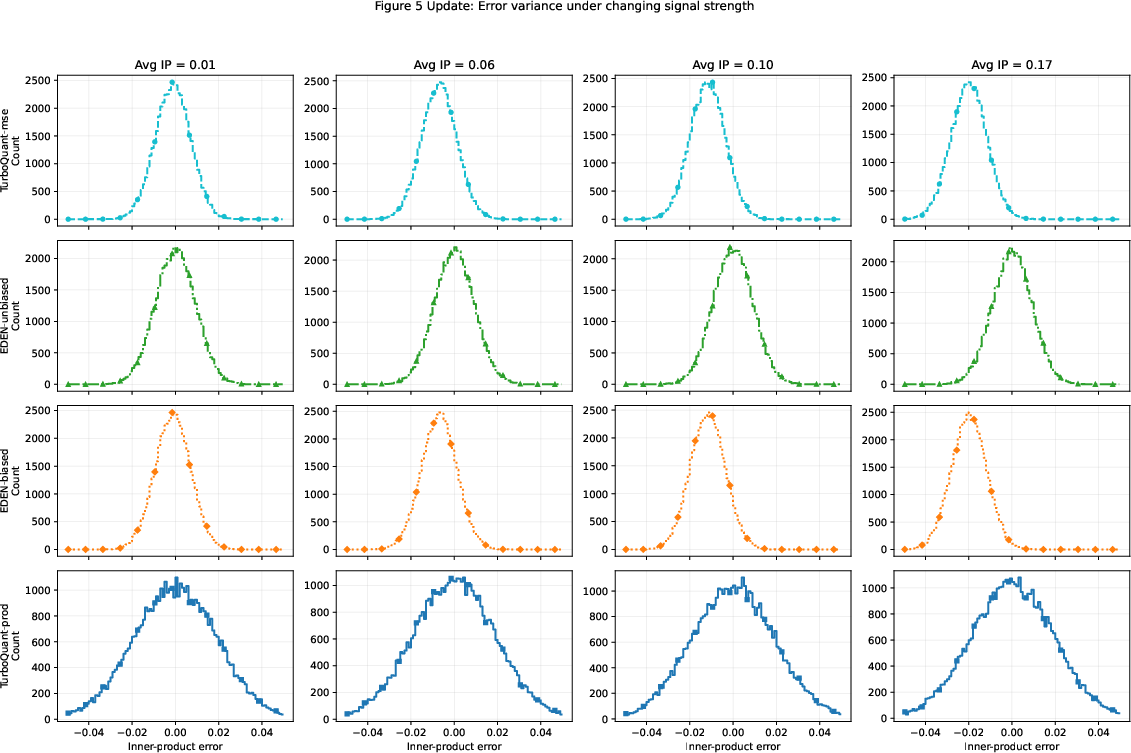
Figure 4: Inner-product error variance for EDEN-unbiased remains tightly controlled as signal strength varies, unlike TurboQuant$1$9.
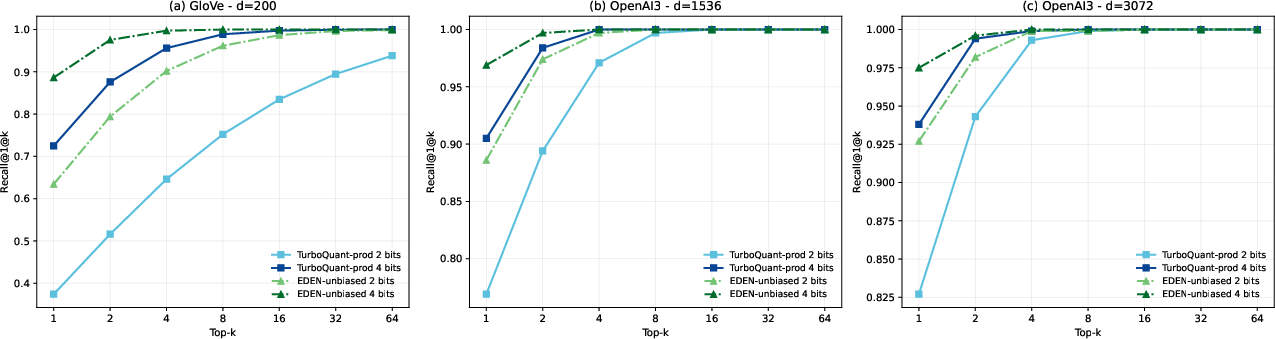
Figure 5: EDEN-unbiased achieves superior recall in downstream nearest-neighbor tasks, outperforming TurboQuantS0 across GloVe and OpenAI3 settings.
Both frameworks recommend Randomized Hadamard Transforms (RHT) as a computationally-efficient substitute for uniform random rotations. While RHT is not unbiased for adversarial inputs, practical bias remains negligible. Advances such as QUIC-FL and double RHT schemes guarantee provable near-unbiasedness, with bias vanishing polynomially in dimension.
Theoretical and Practical Implications
The analysis asserts—contradicting public claims—that TurboQuant methods are not fundamentally new and, in critical settings, strictly inferior to earlier EDEN-centric approaches. This distinction is vital for memory efficiency in large-scale AI and federated learning, as EDEN’s bias-optimized and unbiased reconstructions yield better performance-per-bit and robustness, shaping hardware requirements, distributed training, and low-precision inference. Continued adoption of EDEN-based quantization is thus warranted in emerging AI systems.
Conclusion
The paper establishes that TurboQuant is not only structurally a special case of EDEN but also empirically and theoretically suboptimal except in high-dimensional asymptotic regimes. EDEN’s generality and accuracy advantages challenge TurboQuant's promoted claims, clarifying the optimality of earlier quantization methods. This recognition is pivotal for the design and deployment of compression mechanisms in scalable AI, with substantial practical and theoretical ramifications for memory-efficient computation and distributed training in future AI developments (2604.18555).