TurboAngle: Near-Lossless KV Cache Compression via Uniform Angle Quantization
Abstract: We compress KV cache entries by quantizing angles in the Fast Walsh-Hadamard domain, where a random diagonal rotation makes consecutive element pairs approximately uniformly distributed on the unit circle. We extend this angular quantizer with per-layer early-boost, which independently configures K and V codebook sizes at each layer, allocating higher precision to a model-specific subset of critical layers. Across seven models (1B to 7B parameters), per-layer early-boost achieves lossless compression on four models and near-lossless quality on six of seven, at 3.28 to 3.67 angle bits per element. Asymmetric norm quantization (8-bit for keys, 4-bit log-space for values) yields 6.56 total bits per element on Mistral-7B with perplexity degradation of +0.0014 and no calibration data. A layer-group sensitivity analysis reveals model-specific bottleneck patterns, including K-dominated versus V-dominated layers and negative-transfer layers where increased precision degrades quality.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way, called TurboAngle, to compress the “KV cache” used by LLMs so they use much less memory while keeping almost the same quality. The big idea is to gently reshuffle and rotate the data so that simple, even “angle” slices on a circle can store most of the information. This lets the model remember past tokens efficiently, which is important for fast, long-context chat and writing.
What questions is it trying to answer?
- Can we compress the KV cache a lot without hurting the model’s output quality?
- Is there a simple, universal way to do this that doesn’t need special “calibration” data or per-channel fine-tuning?
- Do different layers of the model need different precision (more or fewer bits)?
- Can we split how we compress “keys” (K) and “values” (V) differently to save even more space?
How does it work? (Methods in simple terms)
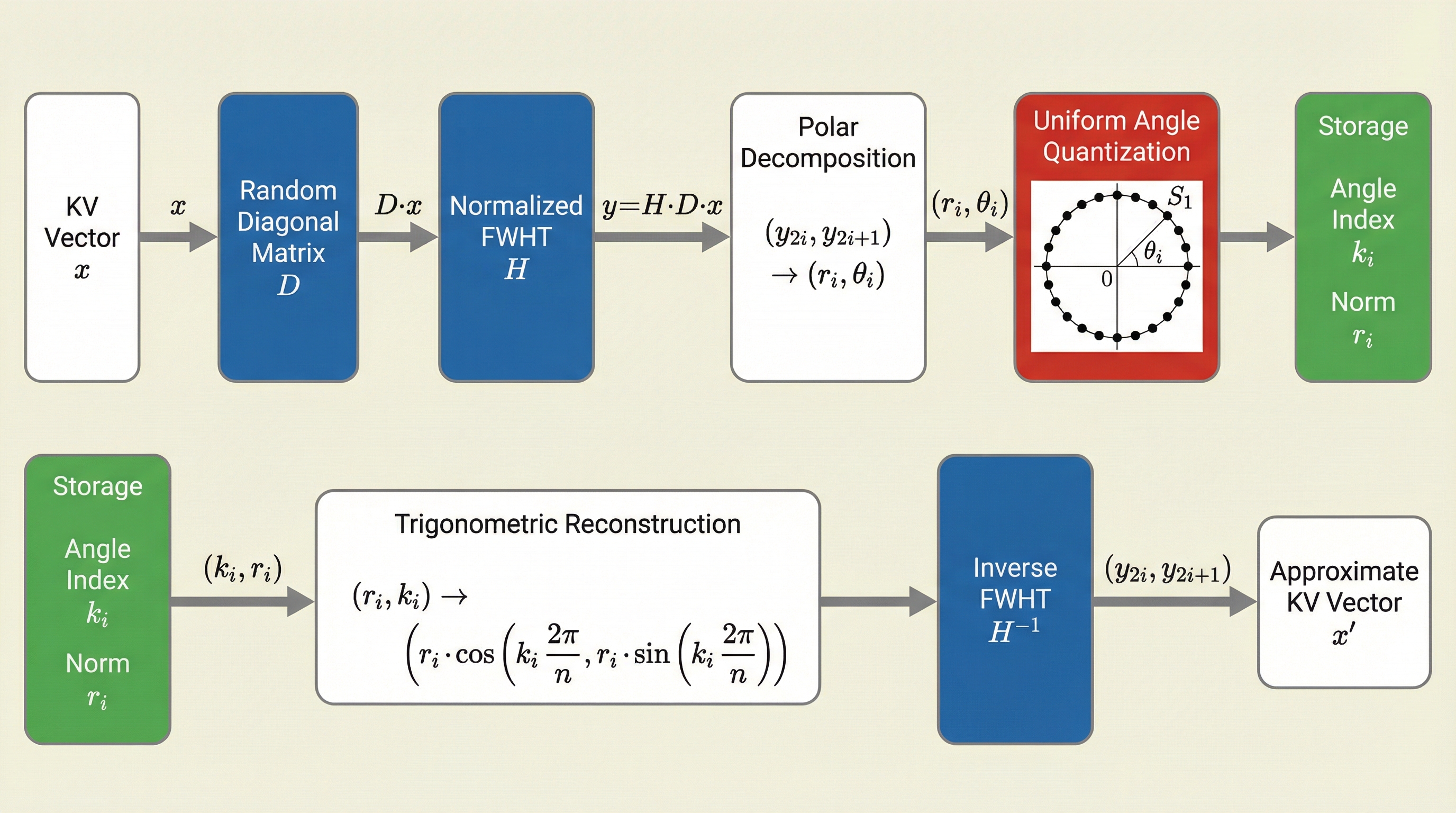
Think of each KV vector (a list of numbers the model keeps for each past token) like an arrow made from pairs of coordinates. TurboAngle does three main things:
- Mix and rotate to make the data evenly spread
- They flip random signs (+ or −) on the numbers and run a fast mixing step called the Fast Walsh–Hadamard Transform (FWHT). You can think of FWHT like a super-fast “shuffle and add/subtract” that spreads information evenly across positions.
- After this, if you look at the numbers two at a time (as x,y pairs), the points land around a circle in a way that their direction (angle) is evenly distributed. That’s great news because it means a very simple quantizer (evenly spaced angle bins) is mathematically the best choice.
- Store angles with a small number of bits
- For each pair (x, y), they convert it to a radius r (how far from the center) and an angle θ (which direction).
- They keep the angle by snapping it to the nearest slice of the circle (like rounding a compass direction to the nearest tick). This takes only a few bits per number—about 3 to 3.7 “angle bits” per element in their best settings.
- Store sizes (radii) smartly
- The radius r tells how strong the pair is. Storing it exactly is expensive, so they compress it too.
- Key idea: K radii are more sensitive than V radii. So they use 8 bits for K radii (linear scale) and only 4 bits for V radii (log scale, which is better for skewed values). This saves space while keeping quality high.
Per-layer early-boost
- Not all layers are equally sensitive. Early layers (closer to the input) often need more precision.
- They give early layers slightly more angle precision and keep later layers at a baseline. Which layers to “boost” depends on the model, and they provide a simple try-and-check recipe that needs only a few test runs.
No calibration needed
- Unlike many other methods, TurboAngle doesn’t need special sample data to tune parameters. The uniform angle trick makes the quantizer “just work.”
What did they find, and why does it matter?
Here are the main results (quality is measured by perplexity, a “surprise” score—lower is better; ΔPPL near 0 means almost no quality change):
- Very small quality loss at very low bitrates:
- With only the angle bits (about 3.3 bits/element), many models show “near-lossless” quality: ΔPPL around 0 or within ±0.002.
- Against a strong scalar quantizer baseline, TurboAngle had 12× to 122× less quality loss at similar or lower bitrates in tested cases.
- End-to-end compression (angles + radii) still near-lossless:
- On Mistral-7B, using about 6.56 total bits per element, the quality drop is tiny: ΔPPL ≈ +0.0014.
- Importantly, this needed zero calibration.
- Layers are not all equal:
- Early layers are usually the most sensitive, but the exact pattern is model-specific.
- Some models prefer more precision in K (keys), others in V (values). They even found “negative-transfer” layers where giving more bits actually makes things worse—so careful per-layer choices matter.
- K vs V radii behave very differently:
- K radii are 10–20× more sensitive to compression errors than V radii.
- Using 8 bits for K radii and 4 bits (log scale) for V radii gave a sweet spot of tiny quality loss and good compression.
- Simple, practical setup:
- A small number of quick tests (3–5 runs) is enough to pick a good per-layer plan on new models.
- No per-channel statistics or learned codebooks needed.
Why this matters:
- The KV cache grows huge with long contexts and many layers. Cutting it down drastically means cheaper servers, faster responses, and the ability to handle longer conversations or documents on the same hardware.
- Because it doesn’t need calibration, it’s easier to deploy across many models or frequent updates.
What could this change? (Implications and impact)
- Cheaper, faster LLM inference: Serving chatbots and long-context apps can cost less and run faster by storing KV caches in far fewer bits with almost no quality impact.
- Easier deployment: No calibration means you don’t need to collect special data or tune per-channel parameters. This helps companies update or swap models quickly, and it’s friendly to edge devices where calibration is impractical.
- Smarter compression design: The discovery that K and V behave very differently (both in angles and in radii) encourages asymmetric, per-layer compression—one-size-fits-all is suboptimal.
- Practical playbook: Start with the simple angle quantizer, boost early layers, keep K radii at 8 bits and V radii at 4 bits (log), and do a few quick tests to finalize. This gives strong results across varied model sizes (1B–7B).
In short, TurboAngle shows that a clever rotate-and-angle strategy can pack the KV cache into a tiny footprint while keeping the model’s brainpower almost unchanged—making LLMs lighter, faster, and easier to run at scale.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Finite-dimension theory: Provide non-asymptotic guarantees and error bounds for angle uniformity and pairwise independence after random ±1 diagonal rotation and FWHT, especially for typical head sizes (d=64, 128) and smaller d<32.
- Transform choice and pairing: Rigorously test and model how the choice of transform (FWHT vs other orthogonal/random transforms), diagonal rotation, and element pairing strategy affect angle uniformity and quantization error.
- Power-of-two aliasing: Validate (or refute) the conjectured aliasing at power-of-two angular bin counts; derive conditions under which bin-grid/transform structure interactions cause non-monotone behavior and propose mitigations (e.g., random pair re-mapping, dithering).
- Seed sensitivity: Quantify performance variance across multiple random D seeds; establish confidence intervals and robustness criteria for ΔPPL at the ±0.001 level.
- Negative-transfer layers: Explain why some mid/late layers exhibit “negative transfer” (precision boost hurts quality); develop predictive indicators and causal analyses rather than empirical discovery.
- Automatic layer scheduling: Devise calibration-free or lightweight-probe methods to automatically select per-layer K/V precisions (e.g., using local sensitivity proxies, Fisher information, singular value spectra, or attention score statistics).
- Generality across architectures: Evaluate on broader families (Llama-3/3.1, MoE, encoder–decoder, multimodal) and attention variants (MQA, different GQA ratios), and head dimensions beyond 64/128, including non–power-of-two d.
- Non–power-of-two head dimensions: Address FWHT’s power-of-two constraint—assess padding costs, alternative transforms, or mixed-size Hadamard variants—and their impact on rate and quality.
- Long-context robustness: Test at much longer contexts (e.g., 128k–1M) and on long-context benchmarks (LongBench, Needle-in-a-Haystack) to assess error accumulation and position-dependent effects.
- Downstream task impact: Measure effects on instruction following, coding (e.g., HumanEval), reasoning (MMLU, GPQA), and safety benchmarks; perplexity alone may underpredict downstream degradations.
- Systems performance: Quantify end-to-end throughput, latency, and energy on real hardware (GPU/CPU) with realistic batch/sequence sizes; break down overhead from FWHT, trigonometric ops, and bit packing.
- Operating directly in compressed domain: Investigate storing and operating attention computations directly in the angle–norm domain to avoid repeated encode/decode per token; characterize algorithmic changes and speedups.
- Entropy coding of indices: Although angles are approximately uniform per pair, measure across-token/layer correlations to see if entropy coding (ANS/Huffman) yields additional size reductions in practice.
- Norm quantization design space: Explore alternatives to per-vector min–max (e.g., per-group or per-layer shared scales, companding, µ-law, vector quantization, learned log bases, dithered or stochastic quantization) to reduce overhead and improve rates.
- Analytical link for K-norm sensitivity: Theorize and validate why K norms are 10–20× more sensitive than V norms (e.g., via softmax gradient sensitivity or score-scaling analysis) to guide principled bit allocation.
- Overhead reduction for min–max: The 64-bit per-vector overhead is significant for small d; explore sharing min–max across groups/tokens, predictive scaling, or compressing the min–max scalars themselves.
- Interaction with weight quantization: Evaluate combined effects with 4–8 bit weight quantization and activation quantization pipelines to ensure no compounding degradations or unexpected interactions.
- Robustness to distribution shift: Test across diverse domains/languages (code, dialogue, math, multilingual) to assess stability of per-layer schedules and K/V asymmetry under shifts.
- Error accumulation analysis: Characterize how angular and norm errors propagate across layers and long sequences; model compounding vs damping behavior.
- Numerical stability and kernels: Assess precision/approximation error from atan2/sin/cos implementations (e.g., LUTs vs intrinsic functions) and develop optimized GPU kernels (TensorCores, SIMD) for FWHT and trig.
- Online/adaptive precision: Explore dynamic bit allocation per layer/token conditioned on runtime statistics, without offline calibration, to exploit temporal variability in sensitivity.
- Fair, matched-rate comparisons: Produce standardized, matched-bit-rate rate–distortion curves against calibration-based baselines on the same models/datasets and sequence lengths to clarify trade-offs.
- Compatibility with other KV compression: Study synergy with eviction policies, KV pruning/low-rank compression, and attention sparsity methods; establish best-practice combinations.
- Implementation edge cases: Clarify handling of models with unusual head dims, different rotary/positional encodings, and encoder–decoder cross-attention caches; specify where transforms are applied in the pipeline.
- Non-monotone early-boost scaling: Develop a mechanistic understanding of why increasing the number of boosted layers can worsen quality in some models and propose constraints or regularizers to avoid harmful regimes.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s methods (TurboAngle angular quantization, per-layer MixedKV early-boost, and asymmetric norm quantization), which require zero calibration and only 3–5 evaluation runs to tune per-layer schedules.
- KV cache compression for LLM inference platforms
- Sectors: software/AI infrastructure, cloud, edge computing
- What to deploy: integrate TurboAngle’s encode/decode into inference engines (e.g., vLLM, TensorRT‑LLM, FasterTransformer, Hugging Face Transformers) with:
- FWHT + random ±1 diagonal rotation per head dimension
- Uniform angle bins (avoid power-of-two counts when possible)
- Per-layer MixedKV schedule (e.g., E4/E8 early-boost) identified by a small sweep
- Norm quantization: K8V4‑log (8‑bit linear K norms, 4‑bit log-space V norms) or norm8 as a safer fallback
- Impact: ~6.56–7.8 total bits per element (model/d-dependent), near-lossless perplexity (e.g., +0.0014 on Mistral‑7B), reduced KV memory footprint enabling larger batch sizes or contexts on the same hardware
- Assumptions/dependencies: efficient FWHT implementation; head dimension ≥64 for reliable angle uniformity; verify on target tasks beyond WikiText‑2; non-monotonic bin-count effects (avoid n=2k for some models); model-specific schedule tuning needed
- Increase concurrent users and throughput for multi-tenant LLM serving
- Sectors: cloud/enterprise SaaS
- What to deploy: apply KV compression to reduce per-request memory; use K8V4‑log or norm8 across models; add a lightweight per-model heuristic (E4/E8, K‑ or V‑dominated)
- Impact: higher QPS at fixed GPU memory, fewer out-of-memory events, improved SLA under bursty loads
- Assumptions/dependencies: ensure added compute (FWHT, trig lookup) remains amortized and does not become the bottleneck; validate on production prompts
- Longer context windows or larger effective batch sizes without model retraining
- Sectors: enterprise RAG, code search, analytics, customer support
- What to deploy: enable longer sequences by capping KV memory with TurboAngle; recompute allocation between batch size and context length in schedulers
- Impact: more retrieved documents per request, deeper in-session memory, improved result quality for RAG and code assistants
- Assumptions/dependencies: long-context quality not evaluated in the paper; run domain-specific validation (e.g., LongBench); watch per-vector overhead at d=64
- On-device and edge LLMs with reduced memory/energy footprint
- Sectors: mobile, IoT, automotive, robotics
- What to deploy: integrate TurboAngle in small/medium models (1–7B) for on-device summarization, command parsing, or offline assistance
- Impact: fit KV caches into constrained RAM; lower DRAM traffic can reduce energy per token; enables richer features locally
- Assumptions/dependencies: efficient FWHT kernels on target hardware; validate latency is acceptable; some d=64 models show larger overhead from min‑max storage
- Privacy- and compliance‑friendly deployment without calibration data
- Sectors: healthcare, finance, public sector
- What to deploy: adopt TurboAngle to avoid collecting/curating calibration sets; standardize a shared seeded diagonal D across deployments
- Impact: mitigates data-governance risks and operational overhead; consistent behavior across environments
- Assumptions/dependencies: ensure reproducibility with fixed seeds; still require task-level validation for regulated uses
- Auto-tuning workflow for per-layer MixedKV schedules
- Sectors: MLOps/DevOps
- What to deploy: a CI pipeline that runs 3–5 evaluation jobs per new model to select K/V early-boost configuration (e.g., test E4/E8 with K256V128 vs K128V256, adjust)
- Impact: near-optimal rate–quality in hours without expert intervention; reusable heuristics (early layers more sensitive; K vs V sensitivity correlates with head dimension)
- Assumptions/dependencies: small validation set suffices for ranking; handle model-specific “negative-transfer” layers by excluding mid-layer ranges if degradation appears
- Memory bandwidth reduction for distributed attention and KV offloading
- Sectors: HPC/AI infra
- What to deploy: store KV in compressed form across GPUs/hosts; decompress only on use or keep in Hadamard domain if integrating with fused attention
- Impact: lower interconnect traffic and cheaper host/NVMe offload
- Assumptions/dependencies: careful placement of encode/decode to avoid creating new bottlenecks; numerical consistency across devices
- Developer tools and libraries
- Sectors: software
- What to deploy: a “TurboAngle KV” library with:
- FWHT kernels, angle-quantization ops, K8V4‑log/norm8 modules
- Schedules per known models (Mistral‑7B, TinyLlama, etc.)
- Guardrails to avoid n=2k when harmful
- Impact: standardized adoption path; faster experimentation
- Assumptions/dependencies: maintain kernels for CUDA, ROCm, and CPU; unit tests validating near-lossless recovery on representative inputs
Long-Term Applications
These applications require further research, scaling, hardware co-design, or broader validation.
- Hardware support for angular KV compression
- Sectors: semiconductors, systems
- Vision: add FWHT/±1 rotation engines and trig LUTs in AI accelerators; expose compressed‑KV formats in memory hierarchies
- Potential products: NPUs/GPUs with native KV‑angle codecs; memory controllers with on-the-fly compression
- Dependencies/assumptions: co-design with fused attention; quantify end-to-end gains under production loads; standardize compressed‑KV formats
- Standardized compressed KV interchange for distributed and serverless inference
- Sectors: cloud, networking
- Vision: define a portable, versioned KV format (angle bins, norm scalars, seed for D) to share KV across services or cache across sessions
- Potential workflows: cross-node KV caching, CDN-like KV edges for fast warm starts
- Dependencies/assumptions: security and determinism guarantees; compatibility across model variants; evaluate serialization overheads
- Ultra-long context LLMs via compound compression and scheduling
- Sectors: enterprise analytics, scientific assistants, legal/medical assistants
- Vision: combine TurboAngle with eviction policies, sparsity, and chunked attention to push to 1M+ token contexts
- Potential tools: adaptive runtime that varies K/V precision over time, by layer and by token importance
- Dependencies/assumptions: robust long-context accuracy still untested; requires dynamic controllers and new benchmarks
- Training-time alignment for angle-friendly representations
- Sectors: AI research
- Vision: finetune or pretrain with regularizers that promote Hadamard‑domain angular uniformity; learn optimal D per layer/head
- Potential products: “quantization-ready” model checkpoints that achieve <6 bits total with negligible loss
- Dependencies/assumptions: added training cost; verify generalization; avoid overfitting to a specific transform
- Adaptive, input-aware quantization at runtime
- Sectors: software/AI infra
- Vision: controllers that select bins and norm bit-widths per request or per token budget, respecting latency targets
- Potential workflows: SLO-aware schedulers that trade precision for throughput under load
- Dependencies/assumptions: fast telemetry on quality proxies; safe fallback paths; ensure stability under non-monotonic layer effects
- Cross-modal and non-language transformer compression
- Sectors: vision, speech, multimodal, recommendation
- Vision: extend TurboAngle to ViTs, audio transformers, diffusion U‑Nets’ attention blocks
- Potential products: low‑memory on-device multimodal assistants; efficient media captioning/transcription
- Dependencies/assumptions: validate angle uniformity at different head dimensions and distributions; may need modality-specific bins or transforms
- Privacy- and sustainability-oriented procurement and standards
- Sectors: policy/public sector/ESG
- Vision: guidelines recommending calibration‑free KV compression to reduce data handling and energy per inference; include KV bitrate and compression settings in model cards
- Potential tools: compliance checklists, energy reporting tied to KV compression levels
- Dependencies/assumptions: independent audits of energy savings; broader task-level validation beyond perplexity
- OS/runtime support for compressed‑KV paging and memory tiering
- Sectors: systems software
- Vision: treat compressed KV as a first-class memory object with transparent paging to CPU/NVMe
- Potential products: schedulers that keep hot layers/tokens in high-precision, cold ones compressed on cheaper tiers
- Dependencies/assumptions: kernel/runtime integration; QoS controls to avoid latency spikes
- Robustness and safety evaluation frameworks for quantized attention
- Sectors: academia, safety
- Vision: benchmarks that link KV compression to downstream safety/robustness (e.g., hallucination, jailbreak resilience)
- Potential tools: open datasets and harnesses measuring failure modes under varying K/V precision
- Dependencies/assumptions: community consensus on metrics; reproduce across seeds and hardware
Cross-cutting assumptions and risks (affect both categories)
- Quality generalization: results are on WikiText‑2 perplexity; downstream task accuracy and long-context behavior need validation.
- Compute overhead: FWHT/trig must remain negligible relative to attention at production batch/sequence sizes; otherwise gains shrink.
- Head dimension: the uniform-angle argument is asymptotic; very small d (<32) may require caution.
- Model specificity: per-layer schedules and K/V dominance can vary; some layers show negative transfer—test before wide rollout.
- Implementation details: avoid harmful power-of-two angle bins on some models; manage per-vector min‑max overhead, especially at d=64.
Glossary
- Angle uniformity: The property that, after a specific random rotation and transform, 2D projections have uniformly distributed angles independent of radius. Example: "Angle uniformity after random rotation."
- Angular quantization: Quantizing only the angle component (on a unit circle) of transformed pairs while storing or separately quantizing norms. Example: "build TurboAngle, an angular quantizer that exploits this property"
- Asymmetric K/V bit allocation: Assigning different bit budgets to keys (K) and values (V) because their sensitivity to quantization differs. Example: "asymmetric K/V bit allocation (8-bit linear K norms, 4-bit log-space V norms)"
- Butterfly decomposition: A recursive factorization enabling fast transforms (like FWHT) in O(d log d) time. Example: "computable in via a butterfly decomposition."
- Calibration (quantization): Using representative data to tune quantizer parameters (e.g., scales) before deployment. Example: "requiring zero calibration."
- Codebook (quantization): The discrete set of representable values or bins used by a quantizer. Example: "assigns independent K and V codebook sizes to each layer"
- Coupled quantization: A scheme that jointly constrains or encodes related tensors (e.g., K and V) to exploit correlations. Example: "inference with coupled quantization."
- Early-boost: A strategy that increases precision for early layers or selected layer groups that are more sensitive to quantization. Example: "per-layer early-boost achieves lossless compression"
- Fast Walsh-Hadamard Transform (FWHT): A fast, orthogonal transform using Hadamard matrices; self-inverse and norm-preserving. Example: "Fast Walsh-Hadamard Transform."
- GQA (Grouped-Query Attention): An attention variant where multiple queries share grouped keys/values, affecting head-dimension and sensitivity. Example: "GQA 8:1"
- Hadamard matrix: An orthogonal matrix with entries ±1/√d used in the FWHT. Example: "The normalized Hadamard matrix"
- Johnson–Lindenstrauss (JL) transform: A random projection that approximately preserves distances in lower dimensions. Example: "applies a Johnson-Lindenstrauss random projection followed by 1-bit sign quantization"
- K-dominated bottleneck: A scenario where compression quality is limited primarily by the precision of the key (K) cache rather than the value (V) cache. Example: "K-dominated vs V-dominated bottlenecks"
- KV cache: The stored keys and values per token used by transformer attention during inference; memory grows with sequence length. Example: "KV cache memory scales as "
- Layer-group sensitivity analysis: An evaluation method that probes which layer groups benefit from higher precision. Example: "A layer-group sensitivity analysis reveals"
- Log-space quantization: Quantizing logarithms of positive values to better allocate levels over wide dynamic ranges. Example: "4-bit log-space quantization"
- Min-max scalar quantization: Linear quantization per vector using its minimum and maximum to map values into a fixed bit width. Example: "per-vector min-max scalar quantization"
- MixedKV: A per-layer configuration that assigns independent angle codebook sizes to K and V caches. Example: "Per-layer MixedKV assigns an independent pair"
- Negative transfer: When increasing precision for certain layers unexpectedly worsens overall model quality. Example: "negative-transfer layers where increased precision degrades quality"
- Norm quantization: Quantization of per-pair magnitudes (radii) after angular encoding to reduce storage overhead. Example: "Norm quantization results."
- Perplexity degradation (ΔPPL): The change in perplexity relative to a baseline, used to measure quality loss or gain after compression. Example: "perplexity degradation ()"
- PRNG (Pseudo-Random Number Generator): A seeded generator used to produce reproducible random rotations or signs. Example: "seeded PRNG"
- Random ±1 diagonal rotation: Preconditioning by multiplying with a random sign diagonal matrix to break correlations before FWHT. Example: "a random diagonal rotation"
- S1 (unit circle): The set of points of unit radius in 2D; the angular quantizer operates over angles on this circle. Example: "angles on are uniformly distributed"
- Scalar quantization: Quantizing each element independently using a fixed set of bins or levels. Example: "apply scalar or vector quantization to raw activations"
- Self-inverse (transform property): A transform that is its own inverse, simplifying encode-decode pipelines. Example: "it is self-inverse: ."
- Uniform angle quantization: Using equal-width angular bins on the unit circle, which is optimal under angle uniformity. Example: "uniform angle quantization on "
- Vector quantization: Quantizing blocks/vectors jointly to exploit structure beyond per-element decisions. Example: "apply scalar or vector quantization to raw activations"
- Walsh–Hadamard domain: The representation space after applying the FWHT, where angle distributions become uniform. Example: "in the Fast Walsh-Hadamard domain"
Collections
Sign up for free to add this paper to one or more collections.

