- The paper demonstrates that diffusion LLMs (CoDA 1.7B) exhibit robust coding task performance under aggressive PTQ, with an accuracy drop of ~8% at 4-bit precision.
- It compares quantization strategies, showing that GPTQ and modified HAWQ enable effective precision allocation and improved latency tradeoffs over AR LLMs.
- The study highlights potential for efficient edge deployments and motivates further research into the interplay of architecture, training data, and quantization dynamics.
Quantization Robustness of Diffusion LLMs in Coding Benchmarks
Introduction
The paper "On the Quantization Robustness of Diffusion LLMs in Coding Benchmarks" (2604.20079) presents an empirical study of quantization robustness in diffusion-based LLMs (d-LLMs) as compared to autoregressive (AR) LLMs, specifically within the context of post-training quantization (PTQ) strategies for deployment in coding tasks. The investigation focuses on Salesforce's CoDA 1.7B (a diffusion LLM) and Qwen3-1.7B (an AR model) to assess accuracy, latency, and memory tradeoffs under various quantization schemes, including GPTQ and a modified Hessian-Aware Quantization (HAWQ), across HumanEval and MBPP coding benchmarks.
Background: Quantization in LLMs
Quantization remains a vital tool for LLM deployment, aiming to minimize memory and inference costs by reducing numerical precision of network weights and activations. Existing research in the AR LLM space has established the viability of aggressive quantization (e.g., 4-bit weight-only formats via GPTQ) while maintaining performance [gptq]. Mixed-precision approaches—such as HAWQ—exploit second-order sensitivity to allocate precision across layers, producing stronger accuracy-compression tradeoffs. However, quantization for d-LLMs is less explored, with recent work (e.g., DLLMQuant) targeting diffusion-specific training dynamics but offering limited perspective on mixed-precision and direct AR vs. d-LLM comparison.
Methodology
The authors execute a controlled empirical comparison using CoDA 1.7B and Qwen3-1.7B, holding architecture and evaluation pipeline fixed as much as possible but noting that training data divergence remains (Qwen3 trained on 36T tokens, CoDA on 180B). Quantization is performed via:
- GPTQ: Per-group, Hessian-compensated weight quantization at 2/3/4/8 bits; model calibration with WikiText.
- Modified HAWQ: Mixed-precision allocation to weights based on estimated sensitivity via power iteration, with substantial scalability adaptations to support billion-parameter models.
Benchmarks include HumanEval and MBPP (regular and "Plus" versions), evaluating pass@1, alongside per-step/token inference latency on NVIDIA L40S.
Results
Accuracy and Quantization Robustness
Across all quantization regimes, CoDA demonstrates superior robustness to accuracy loss at low precision as compared to Qwen3. At 4-bit precision, CoDA exhibits an average decrease of ~8% in coding task accuracy—contrasting sharply with Qwen3, whose performance collapses with average drops of ~40% or more across benchmarks.
This resilience persists at 3-bit quantization: Qwen3 accuracy falls catastrophically, while CoDA retains partial benchmark functionality. At 2-bit quantization, both architectures lose all function.
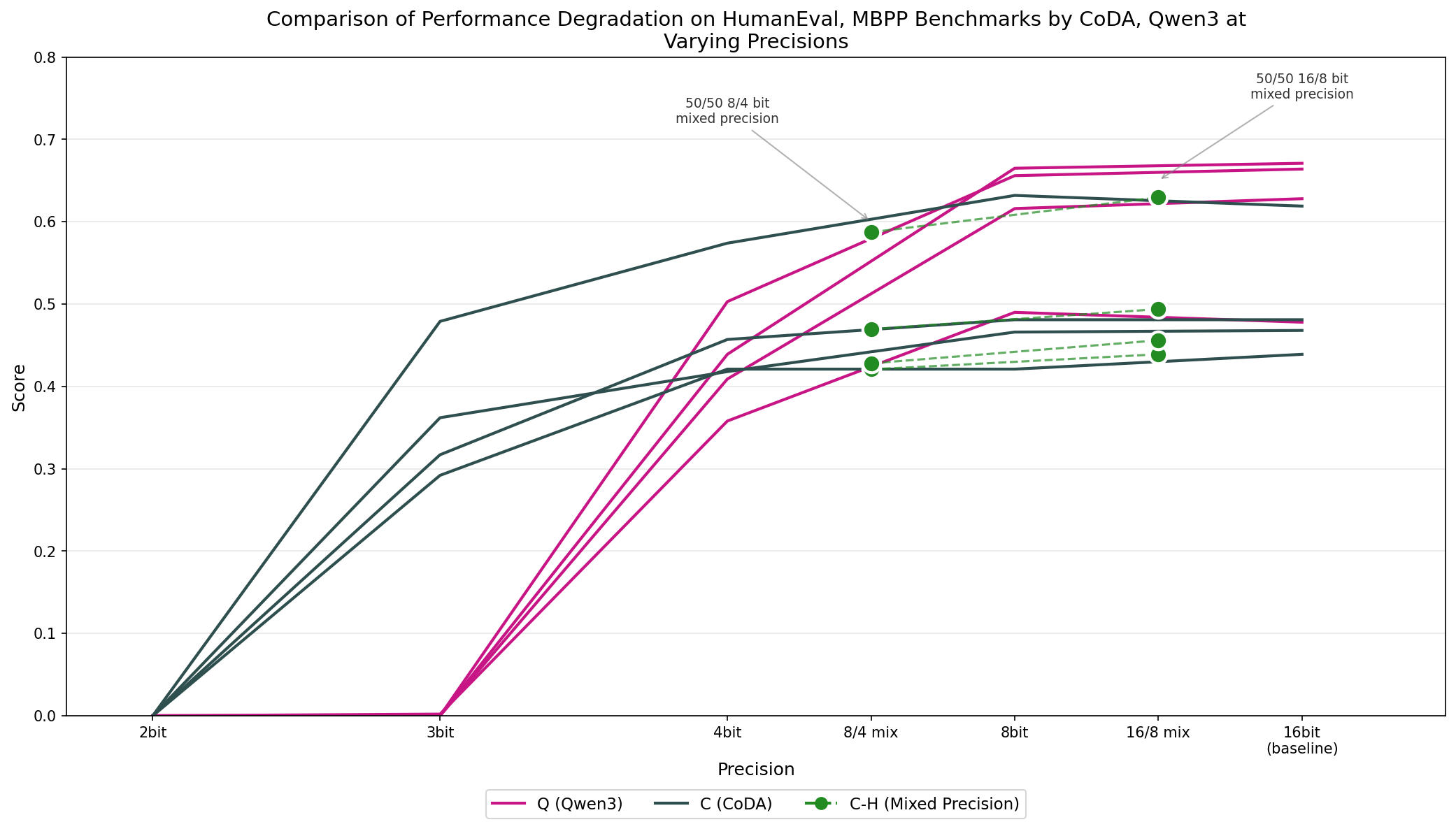
Figure 1: Graphic of Performance-Precision Tradeoff with HAWQ Performance Labeled; d-LLMs display graceful performance degradation across quantization settings compared to AR LLMs.
The discrepancy corresponds with observations in scaling law literature, suggesting that over-trained models (high data:parameter ratio, as in Qwen3) show larger degradation under PTQ [scaling_laws_for_precision], which could partially explain Qwen3's collapse independent of generation paradigm.
Latency, Memory, and Pareto Tradeoffs
Baseline Qwen3 exhibits slightly lower forward latency than CoDA (26.8 ms vs. 28.3 ms on L40S), likely due to optimized AR kernels and architectural differences. After quantization, especially at 4- and 8-bit with GPTQ, CoDA matches and even outperforms Qwen3 in generation latency due to differences in system and framework-level overheads.
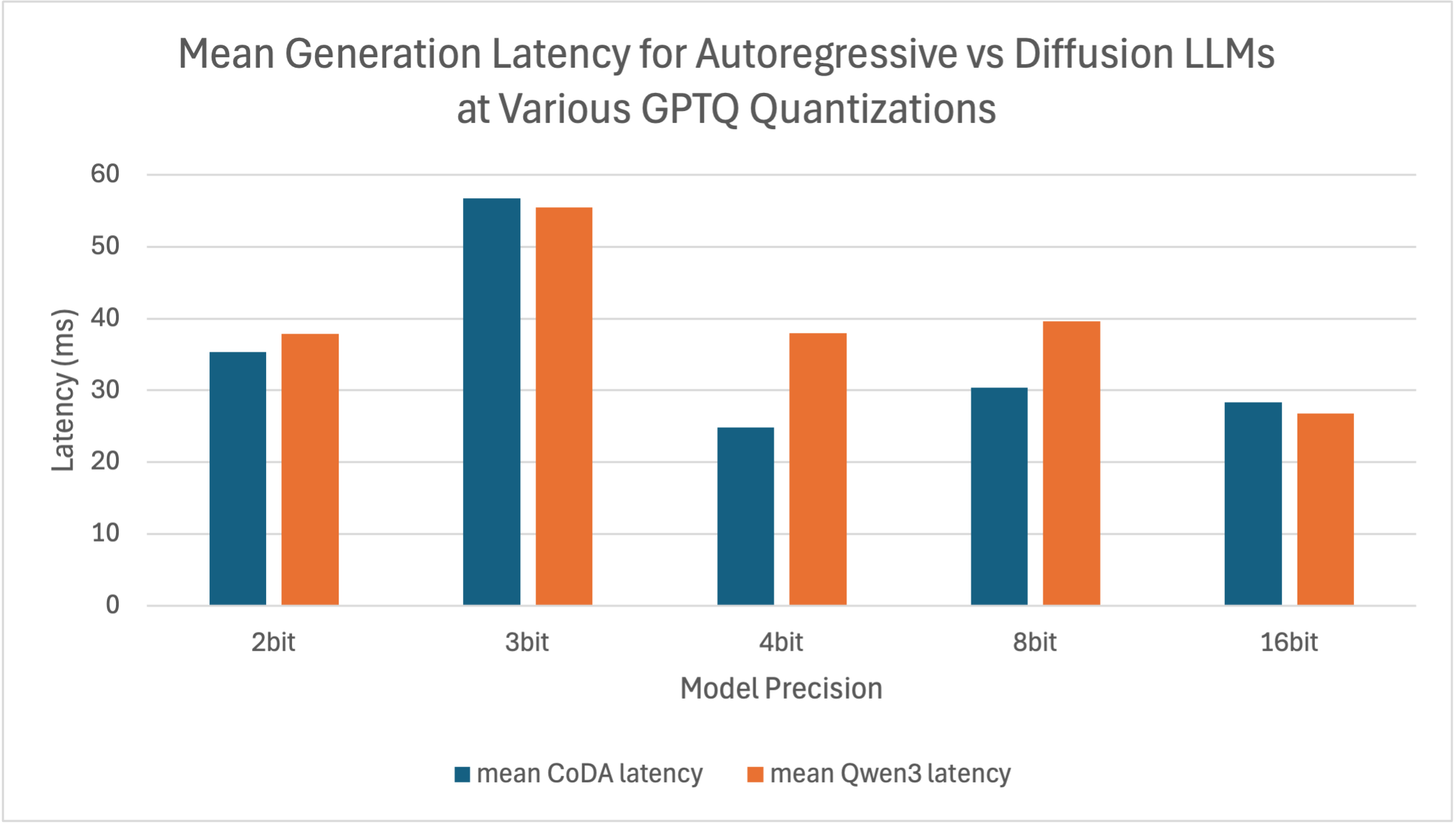
Figure 2: Graphic of Latency-Precision Tradeoff between CoDA and Qwen3 GPTQ Models, illustrating latency convergence and eventual inversion at lower bitwidths.
Notably, CoDA's denoising forward computation—though initially denser—becomes relatively more efficient as arithmetic cost drops, while AR path overheads dominate Qwen3's runtime.
Mixed Precision with HAWQ
The modified HAWQ algorithm enables effective allocation of higher precision to sensitivity-critical weights, yielding very smooth accuracy-memory tradeoffs. Pareto frontier experiments indicate that, with two-precision splits (e.g., 50% of blocks at 16-bit, remainder 8-bit or 8/4-bit), CoDA demonstrates minimal performance loss even with substantially reduced memory footprints. Attempts at more complex multi-precision splits led to performance collapse, indicating the need for further post-quantization fine-tuning or QAT to stabilize low-precision models.
Implications and Future Work
The finding that diffusion-based LLMs (as exemplified by CoDA) maintain task performance at much lower precision than equivalent AR models under aggressive PTQ has concrete implications for deployment:
- Efficient Edge and Resource-Constrained Deployment: Diffusion LLMs are promising candidates where aggressive quantization is needed, e.g., for on-device inference or cost-sensitive settings.
- Design of Quantization Pipelines: HAWQ-style sensitivity-guided precision allocation is highly effective in d-LLMs; exploring automatic precision allocation and robustness recovery via QAT or supervised fine-tuning is indicated.
- Isolation of Generation Paradigm Effects: Since differences in robustness may partially arise from training data (Qwen3's massive over-training), future controlled comparisons—identical data/task/architecture, varying only decoding paradigm—are necessary to verify whether the observed quantization resilience is a true function of the diffusion process.
Further, evaluation of quantization effects with code-focused calibration datasets (such as OpenCoder), and larger-scale mixed-precision HAWQ evaluations, could extend understanding of how model and task properties interact with quantization dynamics.
Conclusion
This work provides systematic evidence that diffusion-based LLMs, here represented by CoDA 1.7B, are significantly more robust to post-training quantization than their autoregressive counterparts on coding benchmarks. Quantized CoDA models retain high accuracy at 4-bit and even 3-bit precision, exhibit superior latency scaling under quantization, and achieve smooth accuracy-memory Pareto tradeoffs when optimized with HAWQ-derived mixed-precision. These results position d-LLMs as attractive targets for memory- and latency-constrained deployments. Theoretical implications call for further disambiguation of architecture, data, and algorithmic effects on quantization robustness, motivating future research in both empirical and foundational directions.

