- The paper demonstrates that mixed-difficulty data regimes can achieve up to 5× sample efficiency over easy-only training, significantly enhancing model generalization.
- The methodology employs procedurally generated datasets in counting, graph, and spatial reasoning to systematically evaluate data complexity and scaling effects.
- Experimental results reveal that token and compute constraints critically impact performance, challenging traditional scaling laws in RLVR.
Measuring the Effectiveness of RLVR in Low Data and Compute Regimes
Introduction
This paper investigates the efficiency and generalization of Reinforcement Learning with Verifiable Rewards (RLVR) for Small LLMs (SLMs) in low-resource settings, where both annotated data and computation are constrained. The premise is motivated by the limitations of recent large-scale RLVR research, which typically relies on abundant ground-truth data and substantial compute, conditions that are infeasible for many practical applications. The study is methodologically distinguished by its use of procedurally generated datasets covering numerical, graph, and spatial reasoning, enabling isolation of the relationship between dataset scale, diversity, complexity, and RLVR performance. The implications for efficient fine-tuning, sample efficiency, and data-centric scaling laws are systematically explored.
Methodology
Procedural Dataset Construction
The study leverages three procedurally-generated domains:
- Counting Problems: Evaluates numerical reasoning by requiring multi-step aggregation and filtering over integer sequences. Problem complexity is controlled via the number and diversity of counting/aggregation operators and the depth of compositional operations.
- Graph Reasoning: Focuses on solving classic graph-theoretic problems (e.g., independent set, minimum vertex cover) specified over text-encoded graphs of configurable size, density, and structural diversity.
- Spatial Reasoning: Tests the ability to infer absolute and relative positions/orientations of objects in 2D grid environments across varying action and query types, as adopted from recent spatial cognition taxonomies.
These datasets allow for direct manipulation and stratification of task complexity and facilitate verifiable, noise-free evaluation through programmatically computed ground-truth.
Data Regimes and Experimental Design
Datasets are curated into “easy” and “mixed” (spanning easy/medium/hard) stratifications using empirical correctness rates from a diverse panel of ten foundation models. Training sets include 100, 200, and 500-example subsamples from each stratification, while test sets are kept distinct and evenly distributed across difficulty levels.
RLVR Fine-Tuning Protocol
All experiments use Qwen3-4B as the base SLM, with adaptation via LoRA (rank 64, α=16), enabling fine-tuning within ~100M effective parameters. The RLVR training objective uses Group Relative Policy Optimization (GRPO), with dense, domain-specific reward functions combining correctness, response format bonuses/penalties, and, in some cases, explanation quality. Training budgets (steps), learning rates, and token/context limits are fixed across datasets and configurations to ensure comparability.
Experimental Results
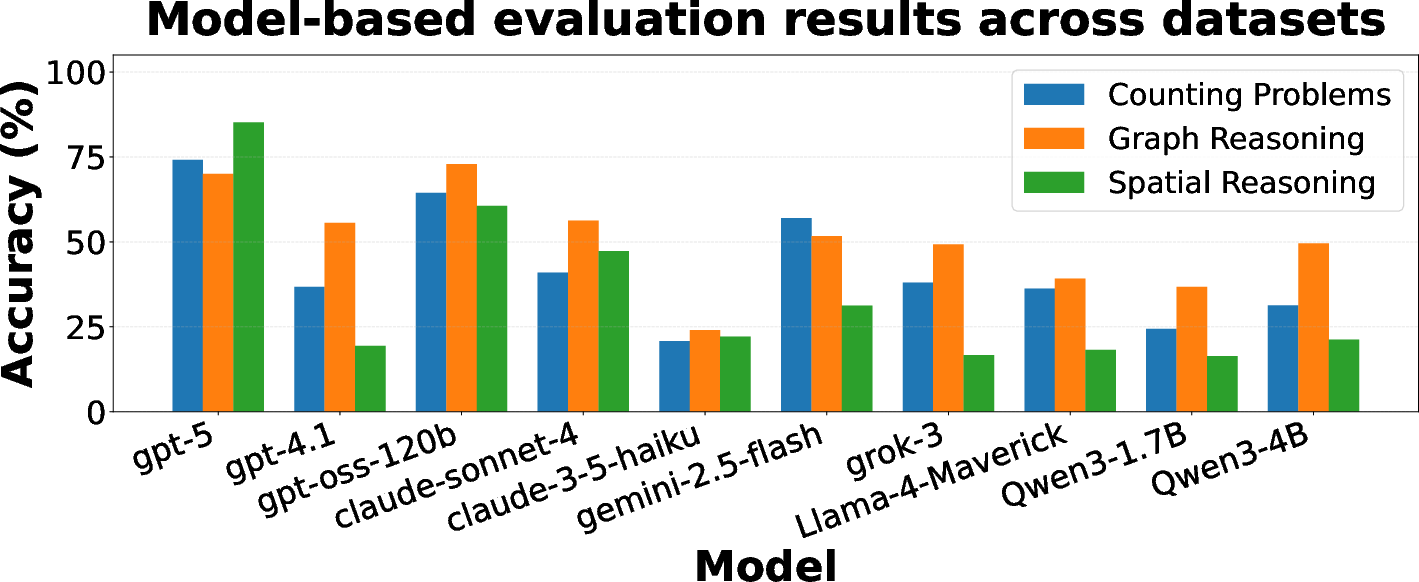
Figure 1: Cross-model evaluation accuracy for Counting, Graph Reasoning, and Spatial Reasoning datasets.
Figure 1 presents the base test performances across the ten baseline LLMs, highlighting significant headroom for improvement in all domains and validating the datasets’ discriminative power.
Counting Problems
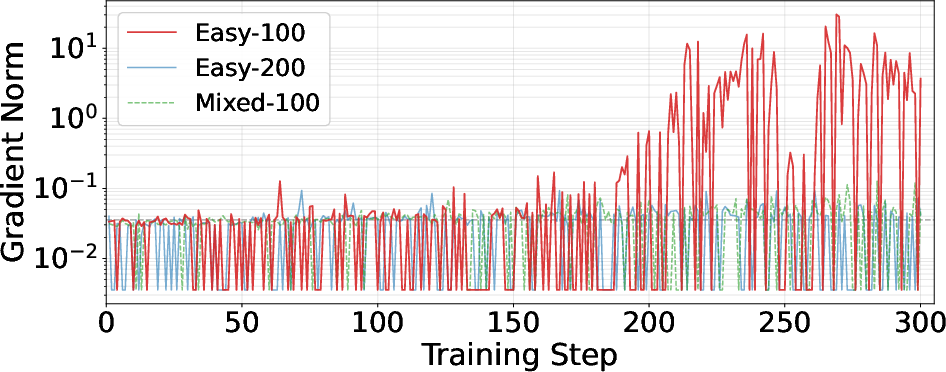
- Training Dynamics: Easy-100 exhibits pronounced instability, with a collapse in validation performance and abnormally high gradient norms after step 150.
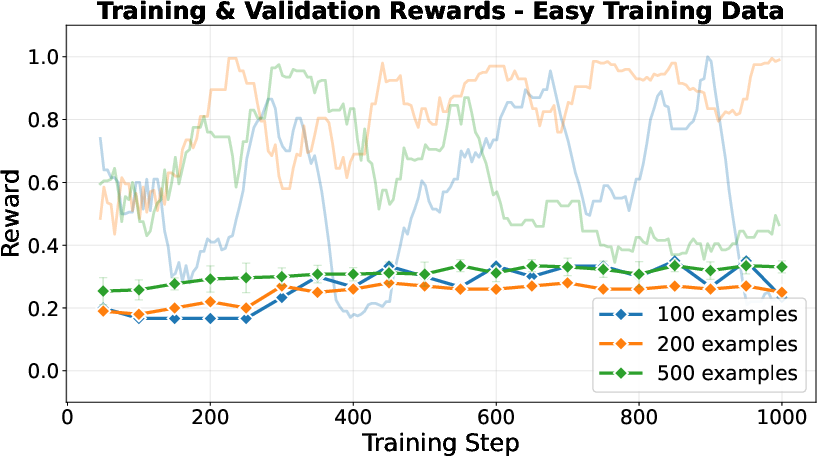
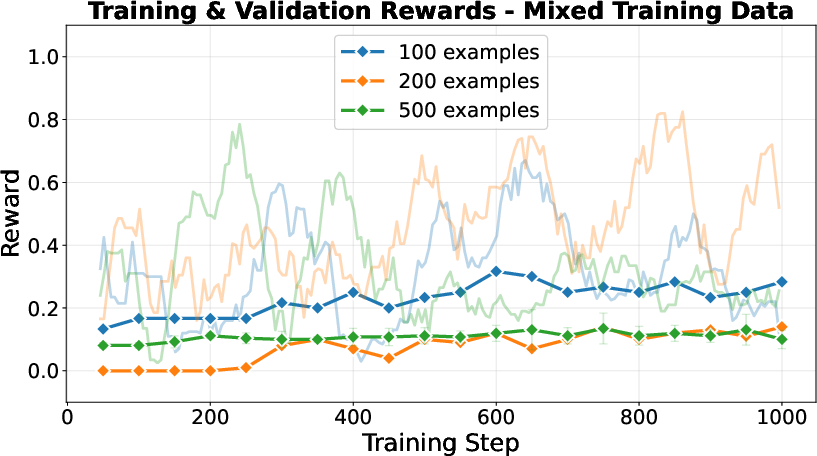
Figure 2: Counting—Training and validation reward curves for easy and mixed training. Easy-100 shows post-150 step collapse.
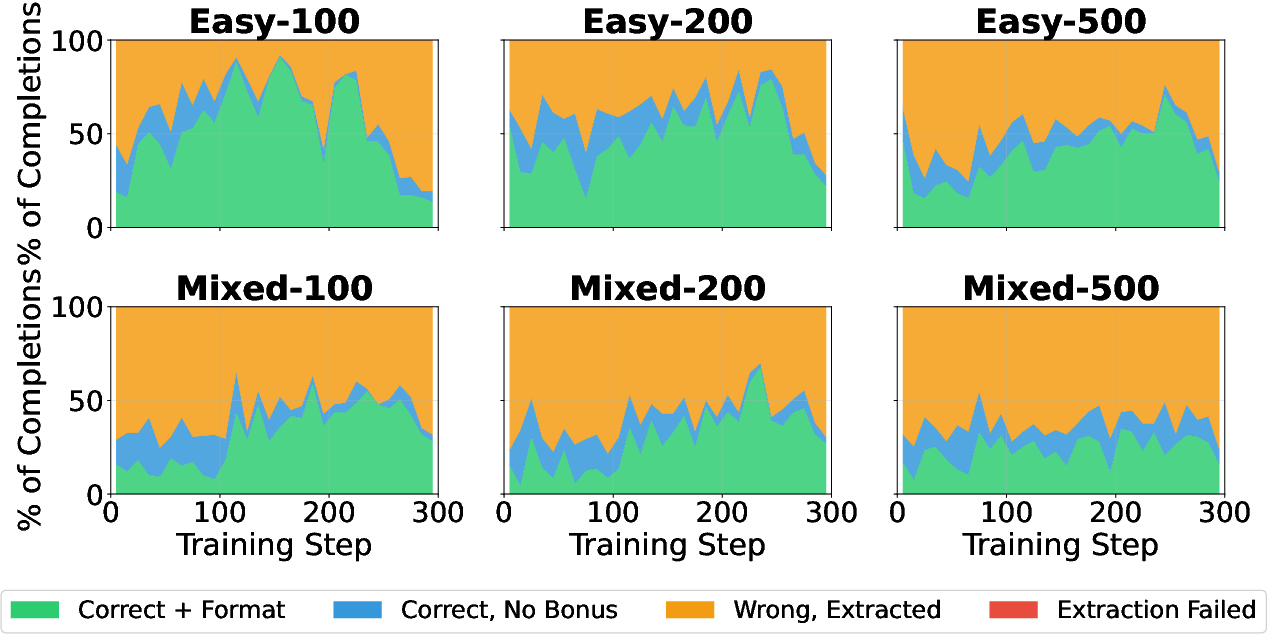
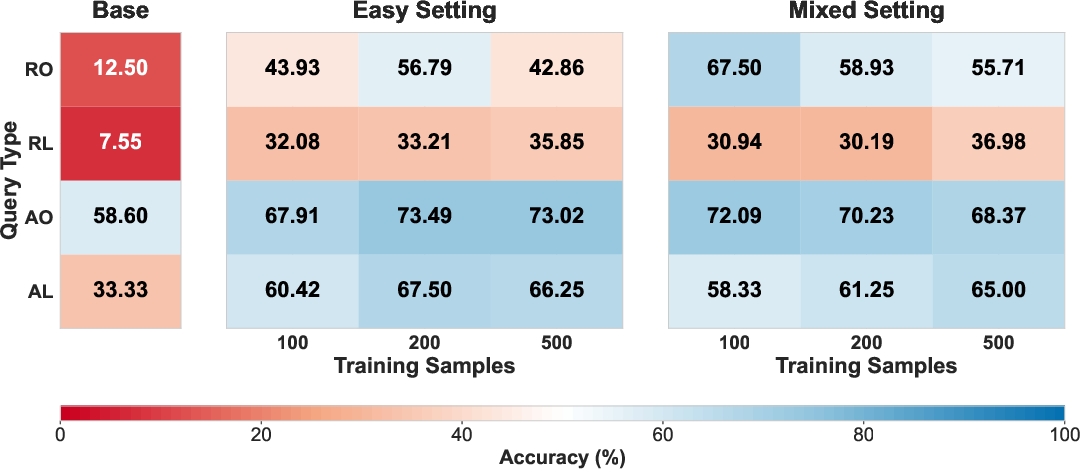
- Generalization: Easy-trained models specialize on easy test items but fail to generalize; mixed-trained models deliver balanced performance across all difficulty levels.
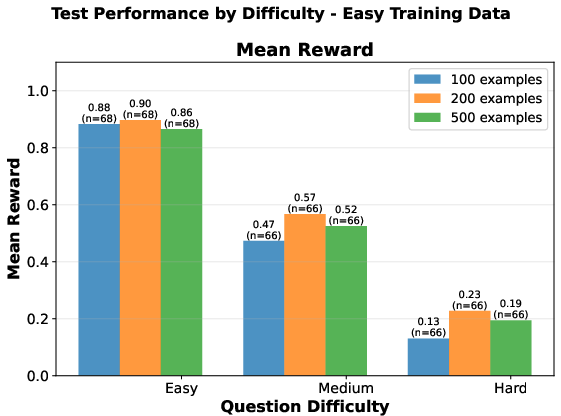
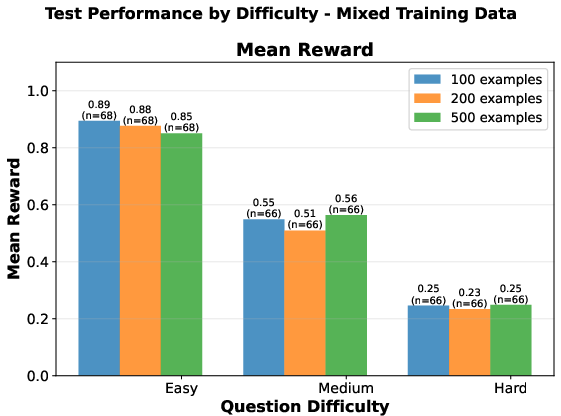
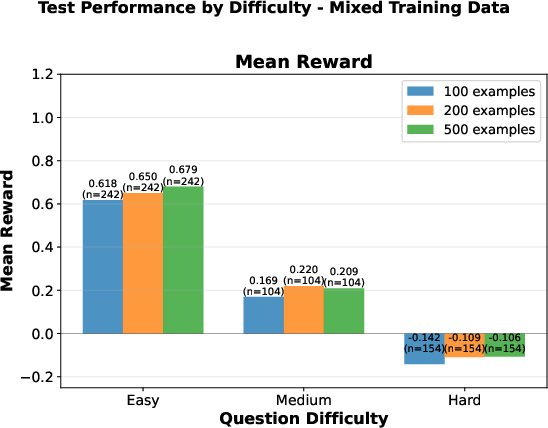
Figure 3: Counting—Easy-trained models (left) lack generalization; mixed-trained models (right) maintain stable cross-difficulty accuracy.
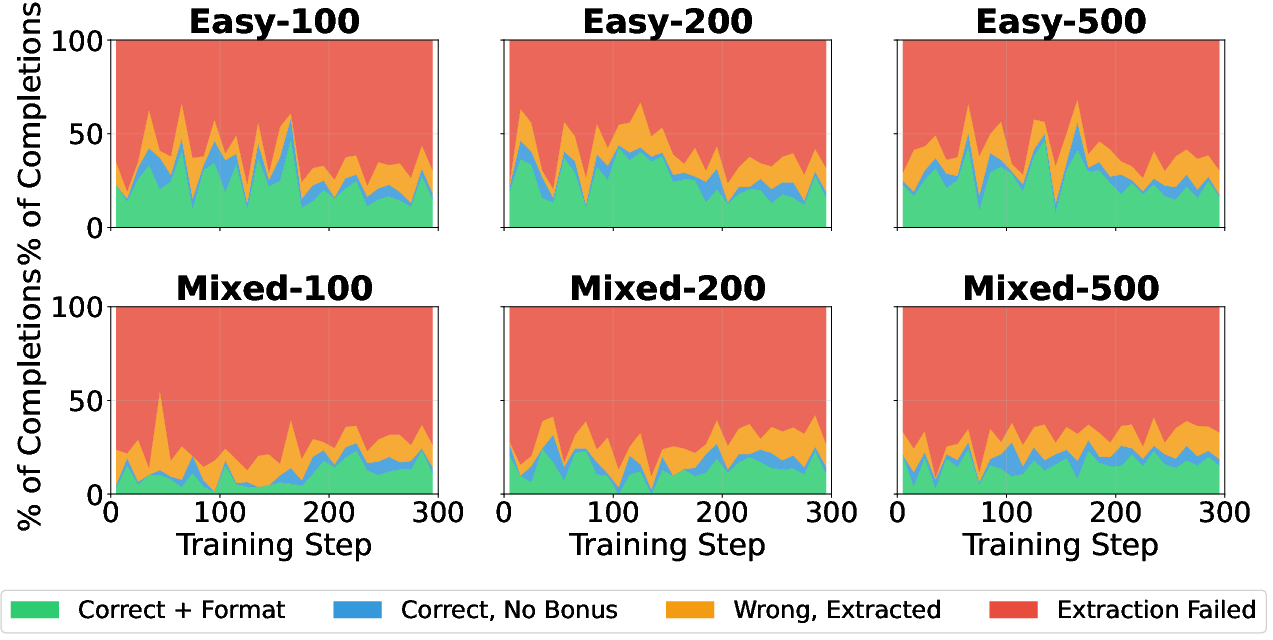
Figure 5: Reward component breakdown. Correctness drives reward collapse in Easy-100.
- Sample Efficiency: Training on 100 mixed-difficulty samples rivals or exceeds the test accuracy of 500 easy-only samples, demonstrating up to 5× greater sample efficiency. This contradicts monotonic scaling laws observed in classical supervised fine-tuning, implying that data composition is more critical than simple volume in low-resource RLVR.
Graph Reasoning
- Optimization Limits: Both easy and mixed models make modest accuracy gains but are severely constrained on medium/hard problems. Mixed sets with larger and more complex graphs are prone to incomplete rollouts and output truncation due to token limits, suppressing positive reward learning. Extraction failures dominate unsuccessful attempts.
- Scaling Trends: No strong accuracy gains from scaling dataset size; stable improvement is seen only for easy-mode runs at larger sizes. This suggests token budget and sequence length are dominant constraining factors, outweighing the effect of data scale or diversity.
Spatial Reasoning
Practical Implications and Theoretical Insights
Data Regime Engineering
The results consistently show that, in low-resource RLVR, diversity in data composition (spanning empirical difficulty tiers) is substantially more impactful than sheer data volume. Strategic curation of small but diverse datasets can deliver disproportionate gains in sample efficiency and generalization.
Compute and Token Budget Bottlenecks
Performance gains from dataset scaling sharply diminish when training steps and generation lengths are limited. This is strongly evidenced in Graph Reasoning, where incomplete rollouts due to sequence truncation eclipse any advantage from broader data exposure.
Scaling Laws Deviations
Observed non-monotonic or inverted-U scaling with respect to data size (under fixed compute) stand in stark contrast with canonical scaling laws derived for supervised LLM training. This suggests the need for theory explicitly modeling the interaction of optimization budget, reward structure, token/context limits, and difficulty diversity, possibly guiding a future taxonomy of “budget-aware” RLVR scaling.
Future Directions
A formalization of empirical scaling laws relating RLVR performance to data regime, model size, reward sparsity, and optimization budget is warranted. Techniques to adaptively allocate token and optimization resources, as well as exploration of transfer from procedural to naturalistic data, are promising avenues. Validation at larger LLM scales and broader investigation of curriculum and selection heuristics informed by the findings here are merited.
Conclusion
This work systematically characterizes RLVR efficiency for SLMs under strictly limited data and compute, via controlled experiments on procedurally varied reasoning benchmarks. The core findings are: (i) in low-data regimes, diverse (mixed-difficulty) data unlocks substantial sample efficiency, strongly outperforming easy-only data of far greater size; (ii) classical scaling assumptions break down under RLVR and low compute; and (iii) practical limits are often imposed not only by data, but by optimization budget and token constraints. The paper’s results and datasets inform both immediate practice for low-resource RL modelers and the design of principled scaling laws for RLVR post-training.
References:
“Learning from Less: Measuring the Effectiveness of RLVR in Low Data and Compute Regimes” (2604.18381).