- The paper introduces a comprehensive benchmark, WebCompass, for evaluating web coding agents using multimodal inputs covering generation, editing, and repair tasks.
- It employs novel evaluation protocols—LLM-as-a-Judge and Agent-as-a-Judge—for evidence-based scoring across functional and visual dimensions.
- Experimental findings reveal closed-source models outperform open-source ones, while visual quality and complex operations remain challenging.
Comprehensive Evaluation of Web Coding Agents with WebCompass
Motivation and Scope
WebCompass addresses the evaluation gap in web coding agents by providing a unified multimodal benchmark covering generation, editing, and repair tasks across three input modalities: text, image, and video. Unlike code-centric benchmarks, WebCompass models the full lifecycle of web engineering, emphasizing nuanced user intent understanding, fine-grained cross-modal reasoning, repository-level context awareness, and diagnostic problem-solving. Real-world web coding involves iterative workflows where functional correctness, visual fidelity, and interaction quality are critical, and WebCompass rigorously measures all dimensions.

Figure 1: WebCompass overview, illustrating support for text, image, and video inputs and generation, editing, repair tasks—yielding seven task categories reflecting professional development cycles.
Task Taxonomy and Data Construction
WebCompass defines three core task types—generation, editing, and repair—resulting in seven multimodal categories: text-guided generation, vision-guided generation, video-guided generation, text-guided editing, vision-guided editing, diagnostic repair, and visual-diagnostic repair. These tasks are informed by 15 generation domains, 16 editing operations, and 11 repair defect types, each annotated as Easy/Medium/Hard.
The data construction pipeline utilizes multi-stage filtering, human curation, and LLM-based expansion to ensure ecological validity and deterministic task construction. Editing and repair prototypes are systematically selected, expanded, and transformed into task instances with exact search/replace annotation for repair, enabling reproducible evaluation and precise error localization.
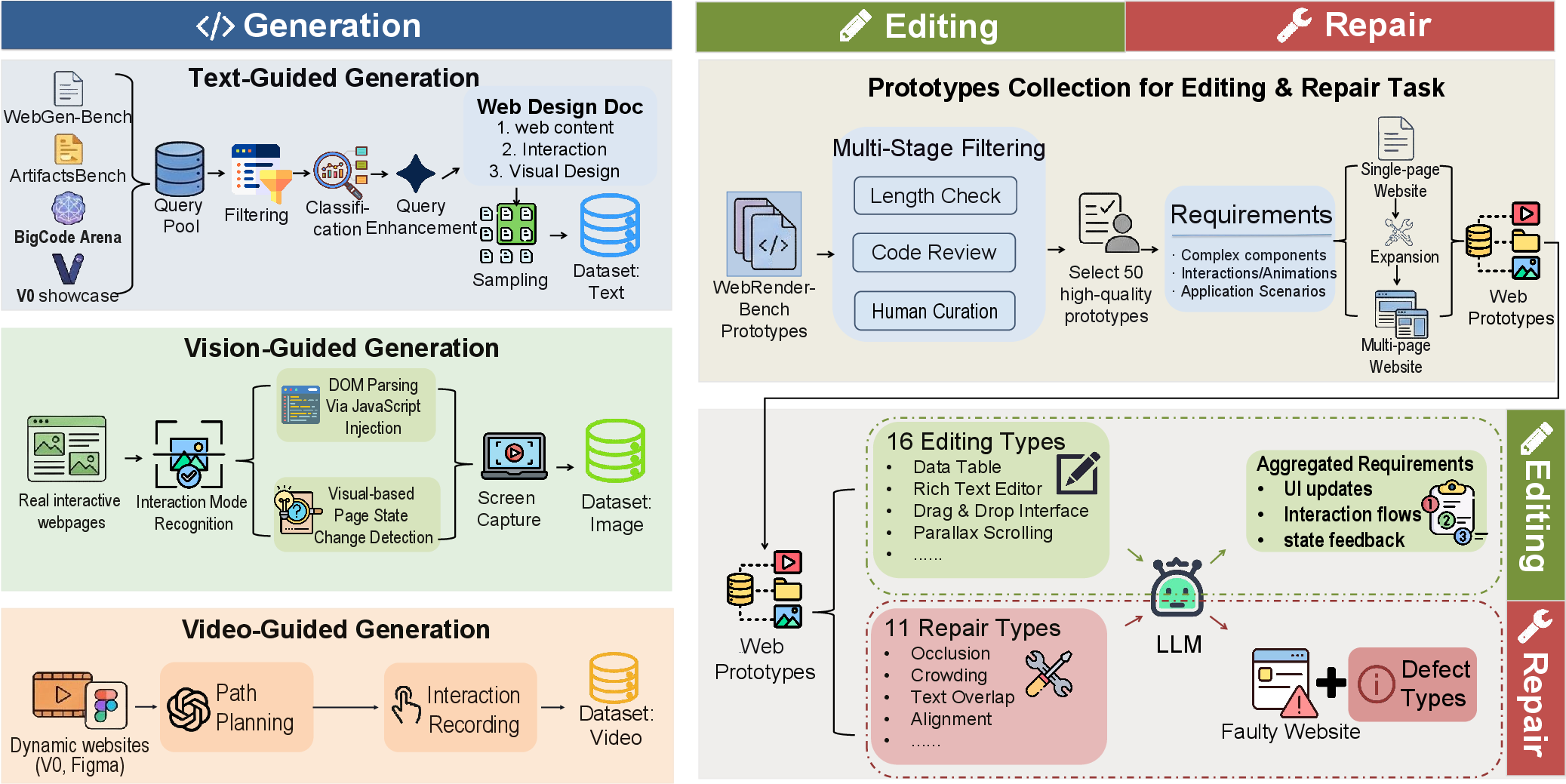
Figure 2: WebCompass data pipeline, showing prototype selection, stratified domain coverage, and task-type–specific conversion for editing (green) and repair (red).
Evaluation Protocols
WebCompass employs two task-aware protocols:
- LLM-as-a-Judge: Used for editing and repair tasks. A checklist-guided protocol leverages annotated requirements, before/after screenshots, patch application logs, and defect descriptions. Scores are produced per dimension—Instruction Targeting, Feature Integrity, and Style Conformance for editing; Root-Cause Targeting, Interaction Integrity, and Reference Fidelity for repair.
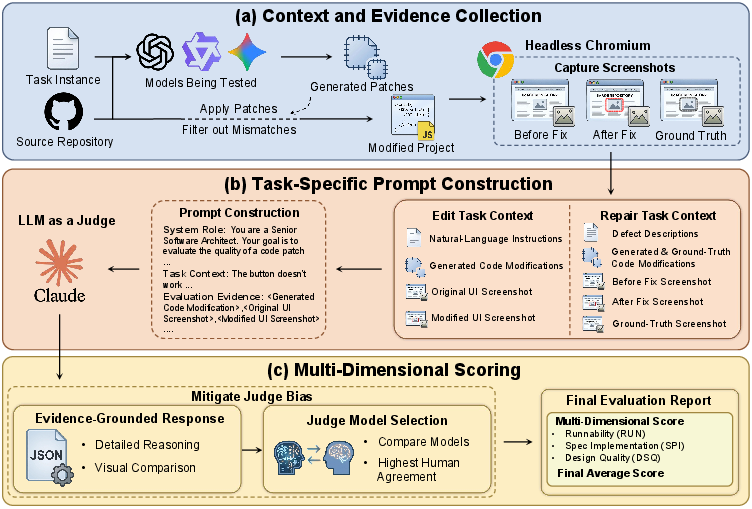
Figure 3: LLM-as-a-Judge workflow: receives requirements, patches, code, runtime logs, and screenshots for evidence-based scoring.
- Agent-as-a-Judge: Used for generation tasks. An autonomous agent, orchestrated via MCP and Claude Code, launches generated sites in a real browser, synthesizes test cases, and executes multi-step interaction sequences. Scores are assigned for Runnability, Spec Implementation, and Design Quality, grounded in both deterministic code tests and visual evidence.
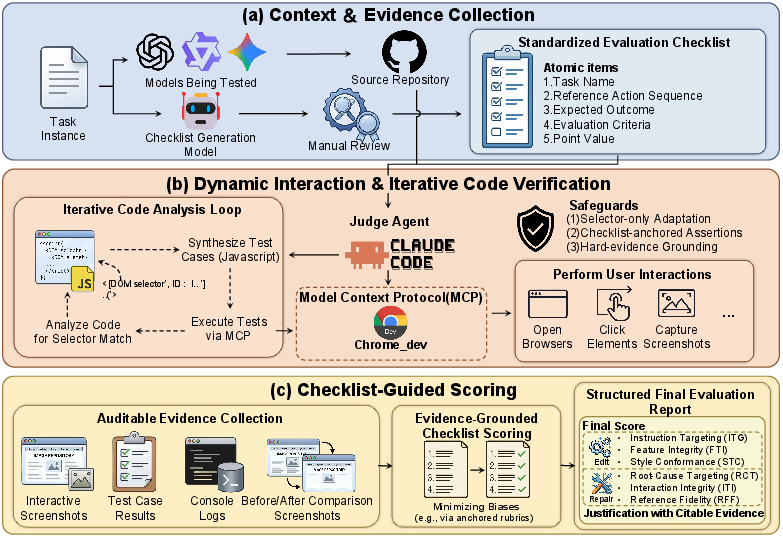
Figure 4: Agent-as-a-Judge pipeline for web generation: agent controls browser, synthesizes interaction/test cases, and collects evidence for scoring.
These approaches emphasize evidence-based, execution-grounded assessment, mitigating evaluation bias through checklist immutability and mandatory artifact justification.
Experimental Findings
A comprehensive comparison reveals consistent model ranking: closed-source LLMs deliver substantially higher and more balanced scores than open-source models, with the largest gap on editing tasks and visual dimensions. Claude-Opus-4.5 and Gemini-3-Pro-Preview achieve high overall scores (67.40, 66.68), while Qwen3-VL-235B-A22B-Instruct, the strongest open-source baseline, trails by >26 points.
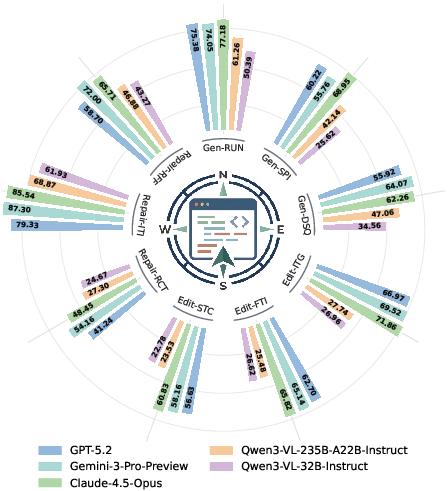
Figure 5: Radar chart summarizing model performance across all seven WebCompass task categories.
Editing and repair tasks present distinct difficulty profiles. Advanced animation operations in editing are the hardest (Figure 6), while semantic defects dominate repair bottlenecks (Figure 7). Visual quality is a persistent challenge, with Design Quality and Style Conformance consistently scoring lowest.
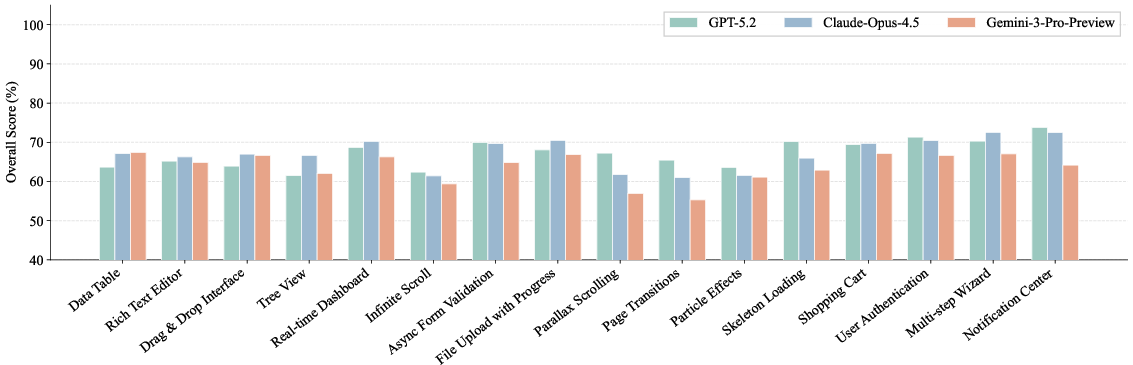
Figure 6: Editing score breakdown across 16 operation types; business scenarios are easiest, advanced animations hardest.
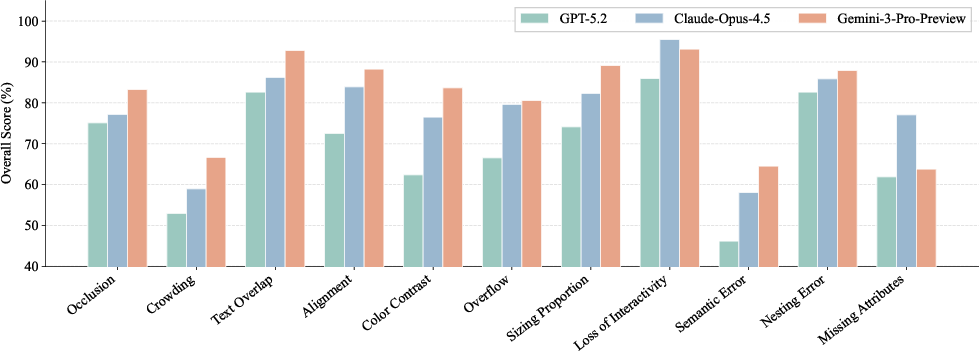
Figure 7: Repair scores across 11 defect categories; semantic errors exhibit lowest fix rates.
Evaluation Reliability and Framework Sensitivity
Automated evaluation correlates strongly with human judgment (Pearson r 0.93–0.96), validating judge protocol reliability (Figure 8).
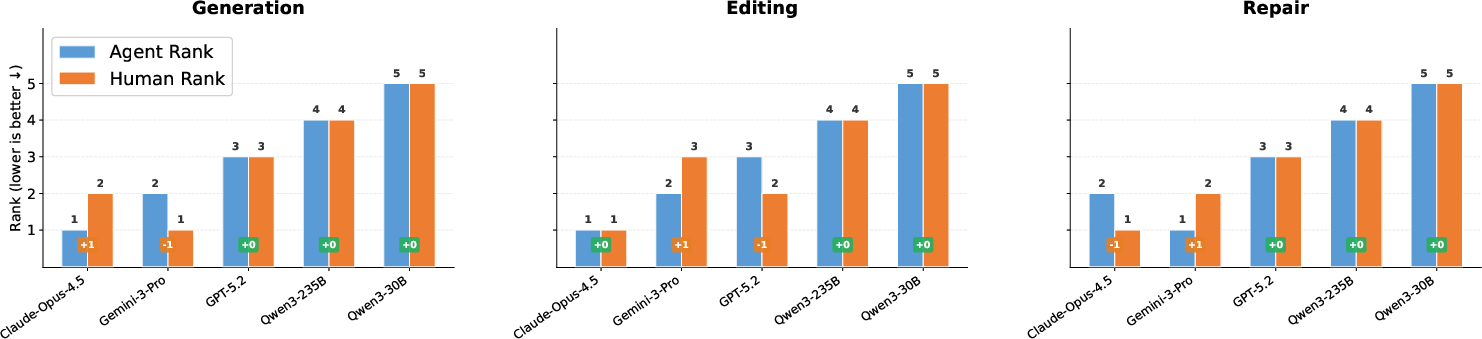
Figure 8: Concordance between agent-based evaluator and human annotators; rank difference is typically zero or one.
Framework sensitivity analysis indicates that Vanilla HTML/CSS/JS yields highest scores for generation and editing, while React supports superior repair outcomes. Vue consistently underperforms, attributed to SFC complexity and increased syntax coordination. Framework preference is stable across closed and open models (Figure 9).
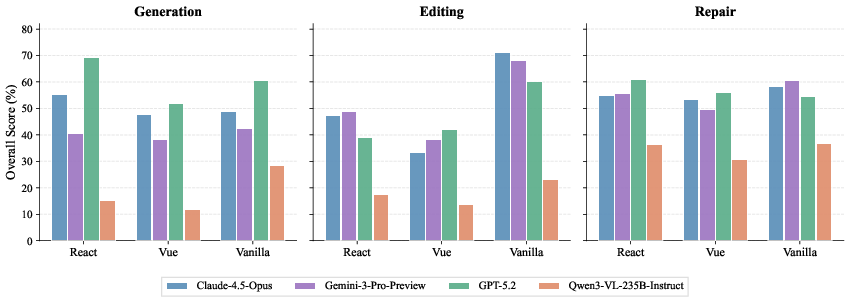
Figure 9: Framework-dependent scores for four models; Vanilla leads generation/editing, React aids repair.
Difficulty and Consistency
Performance degrades as task complexity increases. Hard tasks reduce functional and visual fidelity, especially in Spec Implementation (Figure 10, Figure 11). Consistency analysis with Worst-of-N sampling reveals that top closed-source models retain high scores under adversarial sampling, while open-source models exhibit steeper degradation.
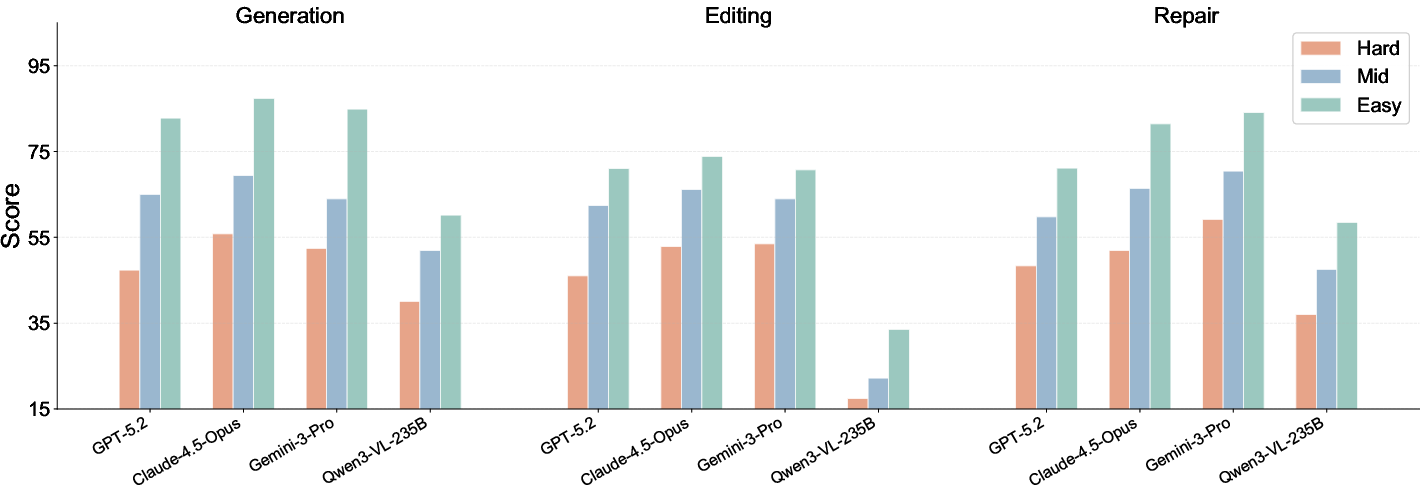
Figure 10: Generation, editing, and repair scores by difficulty; strongest models maintain better performance at increasing complexity.
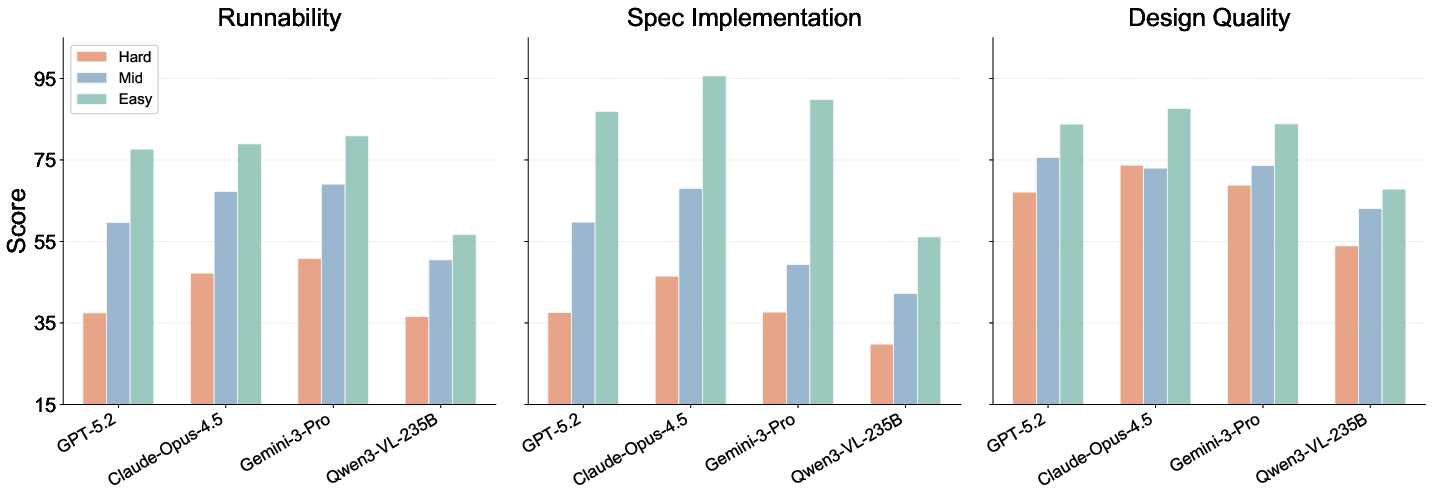
Figure 11: Generation per-dimension scores; Hard prompts lead to largest drops, especially in Spec Implementation.
Patch Complexity and Error Analysis
Edit and repair patches differ markedly in size: editing patches are larger due to new feature introduction, while repair patches target localized defects. Over-editing is penalized in repair tasks, correlating with new-defect errors.
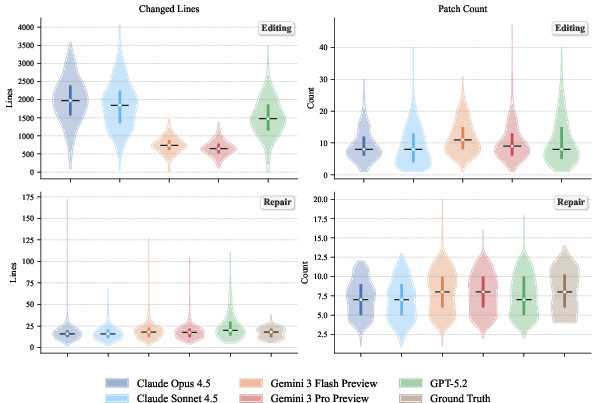
Figure 12: Patch complexity distributions; editing patches are substantially larger than repair patches, which closely match ground-truth.
Error taxonomy reveals functional omissions (“Feature Missing”), partial implementations, visual fidelity gaps, and defect non-addressing as the main failure modes. Modality affects error distribution: text input stresses requirement comprehension, image input exposes visual errors, and video input requires temporal reasoning and appearance matching (Figure 13, Figure 14).
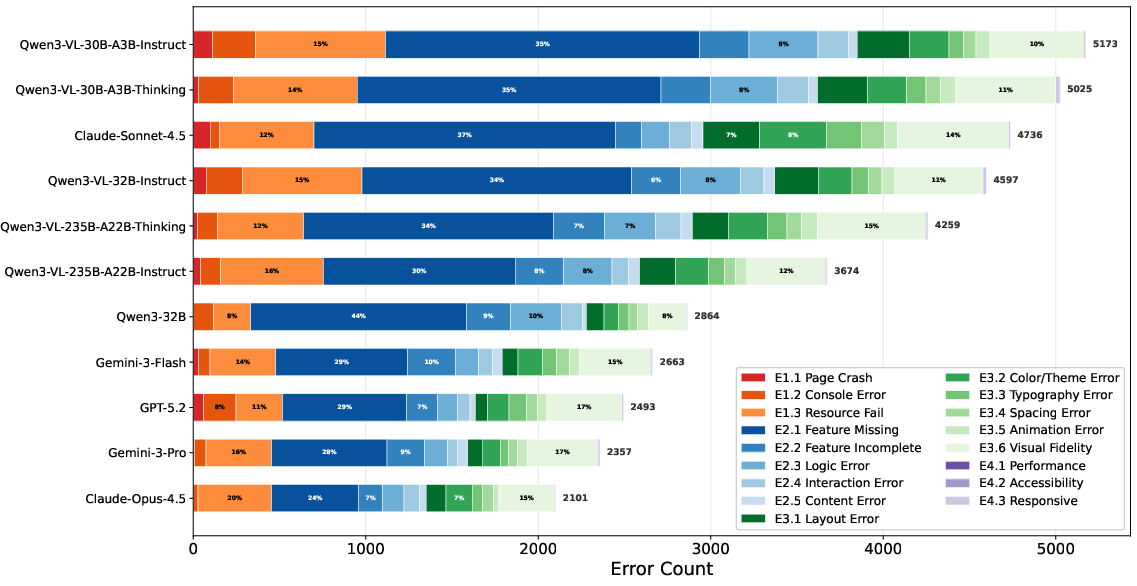
Figure 13: Dominant error types in web generation; Feature Missing and Resource Fail are most frequent.
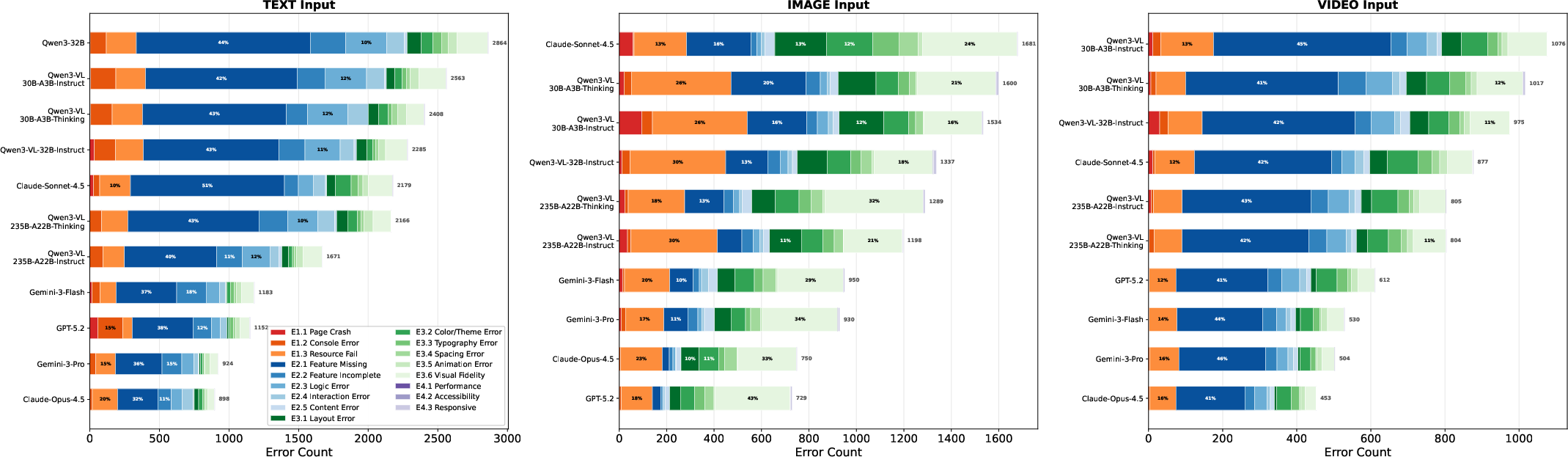
Figure 14: Modality-conditioned error patterns; text leads to functional omissions, image to layout/fidelity errors, and video a balanced mix.
Implications and Future Directions
WebCompass demonstrates that assessing web coding agents demands multimodal, task-aware benchmarks with execution-grounded evaluation. Closed-source models materially outperform open alternatives, but all models struggle with visual quality and complex editing/repair operations. These findings indicate that advancing web coding models requires synergistic improvements in both code reasoning and visual design understanding.
The Agent-as-a-Judge paradigm and search/replace–grounded patch evaluation enable scalable, reproducible assessment, yet incur significant computational cost. Incorporating more dynamic, real-time evaluation protocols could better capture nuanced behaviors in highly interactive applications.
Further, the pronounced difficulty gradients and error taxonomy suggest targeted research opportunities: enhancing LLMs’ semantic reasoning for repair, improving chain-of-thought for editing, and developing stronger visual grounding in multimodal architectures. Integrating benchmarks like WebCompass into iterative training and RL optimization cycles is likely to drive practical progress in agentic coding.
Conclusion
WebCompass establishes a comprehensive, multimodal standard for evaluating web coding agents, unifying text, image, and video-conditioned workflows across generation, editing, and repair with rigorous, execution-driven protocols. Experimental results underscore major gaps between frontier closed-source and open-source models, reveal visual fidelity as the main bottleneck, and delineate task-specific failure modes. Theoretical and practical advances will depend on holistic training and evaluation of coding agents as builders of user-facing artifacts, not mere code generators.

