PaperOrchestra: A Multi-Agent Framework for Automated AI Research Paper Writing
Abstract: Synthesizing unstructured research materials into manuscripts is an essential yet under-explored challenge in AI-driven scientific discovery. Existing autonomous writers are rigidly coupled to specific experimental pipelines, and produce superficial literature reviews. We introduce PaperOrchestra, a multi-agent framework for automated AI research paper writing. It flexibly transforms unconstrained pre-writing materials into submission-ready LaTeX manuscripts, including comprehensive literature synthesis and generated visuals, such as plots and conceptual diagrams. To evaluate performance, we present PaperWritingBench, the first standardized benchmark of reverse-engineered raw materials from 200 top-tier AI conference papers, alongside a comprehensive suite of automated evaluators. In side-by-side human evaluations, PaperOrchestra significantly outperforms autonomous baselines, achieving an absolute win rate margin of 50%-68% in literature review quality, and 14%-38% in overall manuscript quality.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces PaperOrchestra, an AI “team” that can turn messy pre-writing materials (like rough ideas and experiment notes) into a complete, polished research paper—figures, references, and all. The authors also built a new test set, called PaperWritingBench, to fairly measure how well different AI systems can write papers from scratch.
What questions were the researchers trying to answer?
The paper focuses on three simple questions:
- Can an AI write a full research paper—not just a summary—starting from rough notes and logs?
- Can it create a strong literature review (the part that explains how this work fits into previous research) with accurate, verified citations?
- Does this multi-step, team-of-AIs approach actually beat simpler systems, both in automatic checks and in what human reviewers prefer?
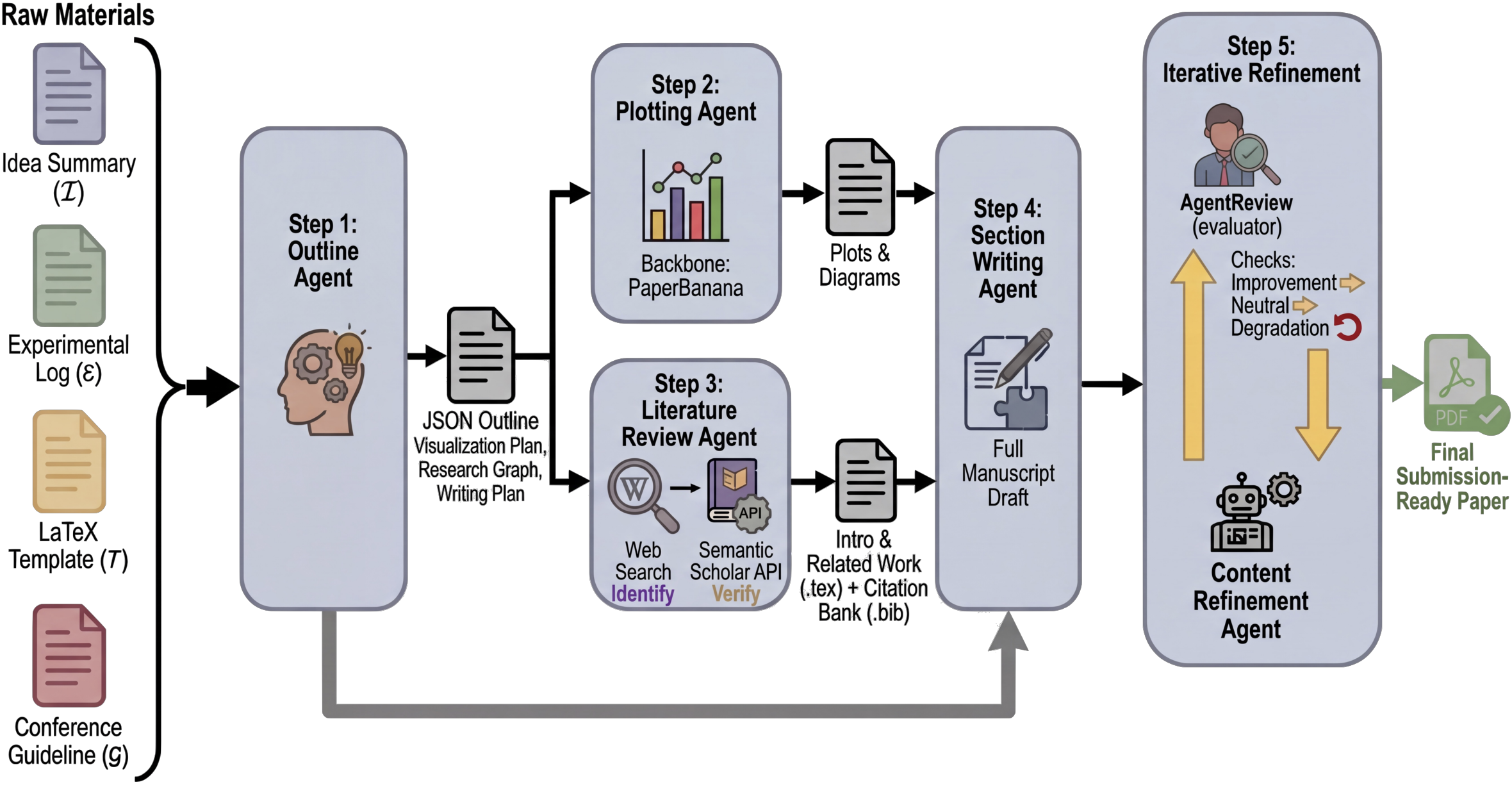
How does PaperOrchestra work?
Think of PaperOrchestra like a group project where each AI “student” has a role, and together they produce a finished paper. It takes in:
- an Idea Summary (what the research is about),
- an Experimental Log (what was tested and what happened),
- the conference template and rules,
- and any existing figures (if none are provided, it makes them).
Here’s the five-part “team” and what each does:
- Outline Agent: Like a project planner. It reads the idea and experiments, makes a section-by-section plan, decides what figures to make, and maps out what related papers to look for.
- Plotting Agent: Like a graphic designer. It creates plots and diagrams from the plan. If a picture looks off, it gets critiqued and improved in a loop until it’s clear and matches the goals.
- Literature Review Agent: Like a research librarian. It searches for relevant papers online, checks they’re real using a trusted database (e.g., Semantic Scholar), filters out outdated or wrong ones, and builds a verified reference list. Then it drafts the Introduction and Related Work using those real citations.
- Section Writing Agent: Like the main writer. It writes the rest of the paper (methods, experiments, conclusion), turns numbers into tables, and fits everything into the correct conference format.
- Content Refinement Agent: Like a peer reviewer and editor. It simulates review feedback, makes improvements, and only keeps changes that actually make the paper better.
In everyday terms: it’s like turning your messy science fair notes into a well-structured report, complete with charts, background research with proper sources, and neat formatting—by having different AI helpers specialize and then combine their work.
How did they test it?
They built PaperWritingBench, a benchmark made from 200 accepted AI papers (from CVPR 2025 and ICLR 2025). Because real lab notes weren’t available, they “reverse-engineered” two things from each final paper:
- a cleaned-up Idea Summary (with no citations or author info),
- an Experimental Log (results and settings, also scrubbed of references).
This lets them fairly test: starting from only an idea and raw results, can an AI write a comparable paper? They compared PaperOrchestra to two baselines:
- a Single Agent (one-shot writer),
- AI Scientist-v2 (a strong existing multi-step system).
They measured performance using:
- automated “judges” that rate quality and acceptance likelihood,
- citation checks (did the system cite important, correct sources?),
- and human side-by-side evaluations by AI researchers.
What did they find?
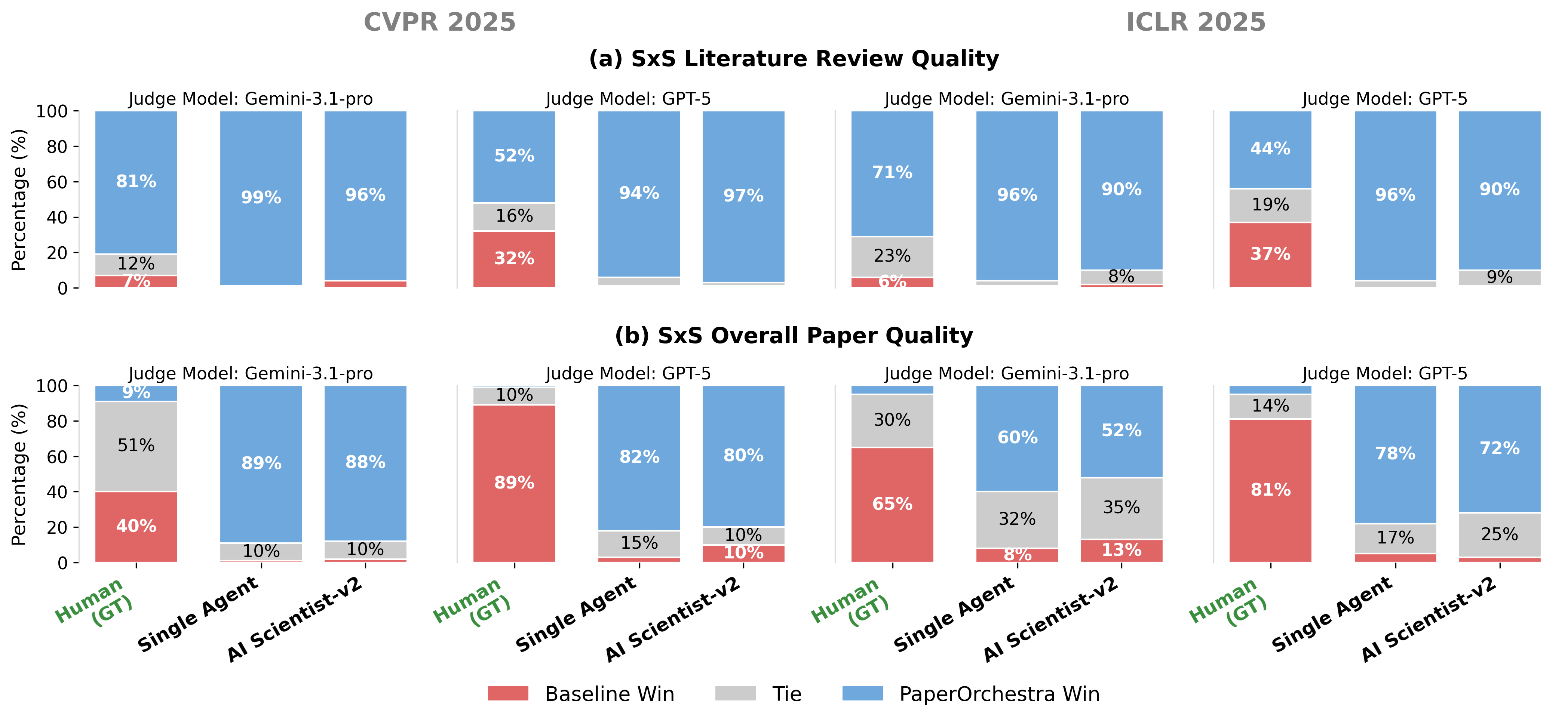
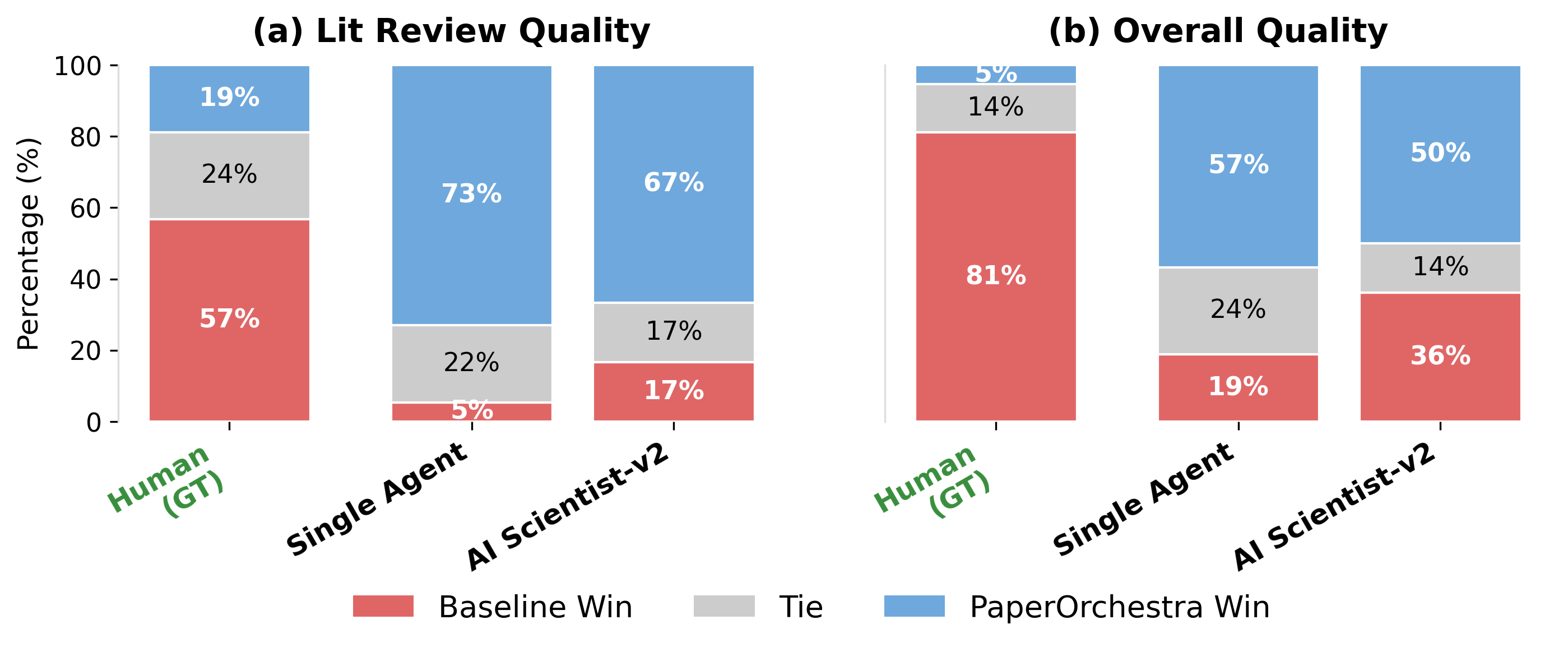
PaperOrchestra performed much better than the baselines in several ways:
- Stronger literature reviews: Human evaluators preferred PaperOrchestra’s literature sections by large margins. It covered the field more deeply and tied prior work to the new idea more clearly.
- Better overall papers: In side-by-side comparisons, PaperOrchestra’s full papers were preferred over the baselines, often by wide margins.
- More and better citations: Instead of citing only a few obvious papers, PaperOrchestra gathered a much richer, verified set of references—closer to what real accepted papers have. It improved both “must-cite” coverage (key baselines, datasets, metrics) and broader background coverage.
- Useful figures: Even when it had to create plots and diagrams from scratch, its visuals were competitive with using human-made figures.
- Refinement matters: The editing-and-feedback loop made a big difference, boosting simulated acceptance rates and overall quality.
Why this is important: Good scientific writing isn’t just correct—it needs to be clear, well-supported by prior work, and easy to follow. PaperOrchestra’s teamwork approach helps with all of that.
What could this mean going forward?
- Faster, better drafting: Researchers could start with rough notes and get a solid first draft, complete with figures and references, much more quickly.
- Better literature coverage: The system actively searches, verifies, and includes relevant prior work, which can reduce accidental under-citation.
- More accessible writing: Students and early-career researchers may find it easier to structure a strong paper with this kind of assistive tool.
Important caution: The authors stress this is an assistant, not an author. Humans must check facts, confirm originality, and take responsibility for what gets submitted. Used wisely, tools like PaperOrchestra could make scientific writing clearer and more reliable, while still keeping humans in charge.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain, missing, or unexplored in the paper.
- Representativeness of inputs: The benchmark’s “pre-writing materials” are LLM–reverse-engineered from accepted papers, not real lab notes or messy early-stage artifacts; it is unclear how well PaperOrchestra handles genuine, noisy, incomplete, or contradictory pre-writing inputs encountered in practice.
- Domain and venue scope: Evaluation is limited to AI papers from two venues (CVPR/ICLR, 2025); generalization to other fields (e.g., biomedical, materials, HCI), journals, workshops, thesis formats, and non-English venues remains untested.
- Dataset biases from parsing: Discarding misparsed PDFs likely biases PaperWritingBench toward well-formatted, formula-light papers; the impact of this selection bias on system performance is not quantified.
- Temporal/data leakage risk: An “anti-leakage prompt” is used, but there is no systematic measurement of model memorization or leakage from pretraining data (e.g., recognition of specific CVPR/ICLR papers), nor an audit of citation discovery overlap with training corpora.
- Evaluation external validity: Heavy reliance on LLM-as-judge autoraters persists; despite a small human study (11 raters, 40 papers), broader human validation, inter-rater reliability, and expert panel replication across institutions are missing.
- Literature-review evaluator bias: The paper notes LLM judges reward “structural” cues (e.g., explicit problem-gap-solution), but does not provide a calibrated rubric or human adjudication procedure that penalizes structural overfitting and rewards nuanced synthesis.
- Limited robustness tests: Only sparse vs. dense idea inputs are studied; robustness to adversarial, contradictory, or incomplete logs, noisy measurements, or mis-specified baselines/datasets is not evaluated.
- Claim–citation grounding: The citation pipeline verifies paper existence via Semantic Scholar but does not check whether cited works actually support specific claims; no claim–evidence linking or fact verification is performed.
- Citation quality vs. quantity: Metrics emphasize P0/P1 recall and F1 against ground-truth references from the original paper; the framework does not assess whether additional (non-GT) citations are substantively relevant or if legitimate novel citations are penalized by the metric.
- Visual correctness and provenance: Generated plots/diagrams are assessed for presentation quality, not factual fidelity; no checks ensure that figures faithfully reflect the provided experimental logs or that conceptual diagrams avoid misrepresentation of methods.
- Plotting ethics and integrity: There is no mechanism for figure provenance tracking, data-to-figure traceability, or detection of fabricated visuals; policies or tooling for preventing visual misconduct are absent.
- Numerical fidelity: The Section Writing Agent extracts numbers from logs to build tables, but there is no automated auditing of extraction accuracy, unit consistency, or aggregation logic; error rates and failure modes are not reported.
- Cross-paper reproducibility and variance: The system’s stochasticity (seeds, agent ordering, retries) and run-to-run variance in outputs, citations, and scores are not quantified.
- Agent ablations: While refinement and plotting are ablated, there is no detailed ablation isolating the Outline Agent or Literature Review Agent to quantify their independent contributions and interactions.
- Failure analysis: The paper lacks systematic qualitative error analysis (e.g., typical failure patterns in literature synthesis, table construction, or LaTeX compilation) and actionable mitigation strategies.
- Security and safety: Retrieval and web search expose the system to prompt injection and malicious content; no defenses (e.g., content sandboxing, domain allowlists, sanitization, or trust scoring) are described or evaluated.
- Compliance beyond templates: Adherence to detailed venue policies (e.g., anonymization pitfalls, dual submission statements, broader impact requirements, page limits, font/contrast rules for accessibility) is not automatically enforced or checked.
- Mathematical content handling: Despite claims of handling equations, there is no evaluation of mathematical correctness, derivation consistency, or theorem-proof integrity in method-heavy manuscripts.
- Multilingual and cross-cultural writing: Capability to generate papers in languages other than English or adapt literature searches and citation norms across language communities is not explored.
- Real-world utility: No longitudinal user studies quantify time saved, editing effort, satisfaction, downstream acceptance in actual submissions, or cognitive load for human collaborators.
- Human-in-the-loop workflows: While future work is suggested, there is no prototype or evaluation of interactive modes (e.g., iterative human edits, preference learning, or co-writing interfaces) and their effect on quality and trust.
- Scalability and cost transparency: Cost/runtime are referenced in the appendix, but not analyzed by agent stage, venue format, or citation depth; cost-quality trade-offs and scaling behavior (e.g., to long journal articles) are not characterized.
- Generalization to novel ideas: Bench papers are accepted works with known, well-scoped contexts; the system’s ability to position truly novel ideas (without a clear GT reference set) and responsibly hypothesize gaps remains untested.
- Plagiarism risks and textual originality: Beyond ethical disclaimers, there is no automated plagiarism detection, similarity reporting, or mechanisms to ensure paraphrasing does not unintentionally replicate phrasing from training data or retrieved sources.
- Dataset release and reproducibility: Concrete release details (licensing, exact prompts, model versions, seeds, scripts for evaluation and citation resolution) are not fully specified in the main text; reproducibility across different foundation models is not demonstrated.
- Template generality: Only two LaTeX formats are used; behavior on complex templates (journal class files, ACM/IEEE, Springer LNCS) and edge cases (custom packages, TikZ-heavy figures, bibliography styles) is unknown.
- Optimization to autoraters: The refinement loop leverages LLM-based peer review; risk of overfitting to these evaluators (“reward hacking”) is not studied, nor are guardrails to preserve scientific correctness over stylistic score gains.
- Ethical governance: There are no built-in guardrails for responsible content (e.g., undisclosed dual use, prohibited topics), authorship disclosure templates, or provenance metadata to signal AI assistance to venues and readers.
- Retrieval coverage and paywalls: The system relies on web search and Semantic Scholar metadata; coverage limitations (preprints vs. paywalled content), handling of inaccessible PDFs, and their impact on citation recall are not quantified.
- Non-text artifacts: Integration of code repositories, appendices with proofs, supplementary videos, or executable notebooks is out of scope; how these artifacts could be ingested and referenced coherently is an open question.
- Long-term maintenance: How PaperOrchestra updates its retrieval strategies, venue rules, and toolchains (e.g., when conference templates change) and how this affects stability over time is not addressed.
- Ethical deployment and misuse: Beyond disclaimers, mechanisms to discourage generating deceptive manuscripts, detect fabricated results, or enforce human accountability in collaborative settings are not implemented or evaluated.
Practical Applications
Immediate Applications
The following use cases can be deployed today by leveraging PaperOrchestra’s multi-agent workflow (outline, plotting, literature verification, section drafting, refinement) and/or the PaperWritingBench benchmark and autoraters.
- AI-assisted manuscript drafting from lab notes
- Sectors: academia, R&D in software/AI, robotics, materials, energy
- Tools/products/workflows: “Lab-to-manuscript” assistants that ingest idea summaries and experiment logs (from ELNs, Jupyter, Git repos) and produce LaTeX drafts with verified citations, tables, and auto-generated conceptual diagrams; Overleaf/VS Code plugins using the Outline/Section Writing/Content Refinement agents; GitHub Actions that turn experiment logs into internal reports
- Assumptions/dependencies: access to an LLM/VLM stack, Semantic Scholar API/web search, conference/journal LaTeX templates, human review for factual/ethical accountability
- Targeted Related Work and citation bank construction with verification
- Sectors: academia, enterprise research groups, publishing
- Tools/products/workflows: a “Related-Work Copilot” that creates .bib files via Semantic Scholar ID resolution, enforces temporal cutoffs, and drafts Introduction/Related Work; Zotero/EndNote connectors for must-cite vs. good-to-cite coverage audits; reviewer checklists powered by Citation F1
- Assumptions/dependencies: reliable metadata APIs, permissioned search access, domain adaptation beyond AI may require custom retrieval
- Conference/journal compliance and formatting copilot
- Sectors: academic publishing, corporate technical communications
- Tools/products/workflows: agents that map content to venue guidelines/templates (length, section order, reference style, figure placement), with iterative refinement to pass desk-checks
- Assumptions/dependencies: up-to-date templates/guidelines; venue acceptance of AI-assisted formatting
- Automated visual asset generation for scientific writing
- Sectors: academia, R&D marketing/communications, education
- Tools/products/workflows: a “Plotting Agent” service that turns metrics/ablation logs into plots and conceptual diagrams (PaperBanana-style closed-loop generation + captions); integration with Matplotlib/Plotly/Pandoc renderers
- Assumptions/dependencies: VLM-based image critique; design QA by humans to avoid misleading visuals
- Internal whitepapers and technical briefs from heterogeneous notes
- Sectors: software/AI companies, robotics, energy, biotech
- Tools/products/workflows: pipelines to transform meeting notes, Slack threads, and experiment dashboards into publishable whitepapers with literature-grounded positioning
- Assumptions/dependencies: secure handling of proprietary data; legal/IP review; provenance tracking
- Reviewer triage and self-assessment using autoraters
- Sectors: conferences/journals, corporate R&D review boards
- Tools/products/workflows: “preflight” scoring for clarity/soundness and must-cite coverage (Citation F1, SxS evaluators), used for desk-reject triage or internal go/no-go gates before submission
- Assumptions/dependencies: human oversight to prevent overreliance on automated scores; guardrails against LLM bias
- Grant proposal scaffolding and background section drafting
- Sectors: academia, national labs, nonprofits
- Tools/products/workflows: tools that turn project ideas and preliminary results into proposal-ready drafts with verified state-of-the-art coverage and required formatting
- Assumptions/dependencies: sponsor-specific templates and compliance rules; careful human validation of claims/impact
- Course and thesis writing support
- Sectors: education
- Tools/products/workflows: classroom “writing studios” that use PaperWritingBench excerpts to teach structure, citation rigor, and gap analysis; thesis-drafting assistants that emphasize P0 must-cite coverage and critical synthesis
- Assumptions/dependencies: academic integrity policies; instructor-defined usage boundaries
- Knowledge-base enrichment with literature synthesis
- Sectors: enterprise knowledge management, consulting, pharma
- Tools/products/workflows: scheduled agents that monitor topics, add verified citations, and maintain “living” related-work pages for internal wikis/portals
- Assumptions/dependencies: change detection and temporal cutoff enforcement; access control and audit logs
- Consumer-facing long-form content generation (with citations)
- Sectors: daily life, professional blogging, tech journalism
- Tools/products/workflows: blogging assistants that generate explainer articles with verified references and diagrams; “explain my experiment” tools for citizen science
- Assumptions/dependencies: simplified templates; emphasis on readability and accurate citation attribution; risk of over-automation without expert review
Long-Term Applications
These opportunities require further research, scaling, policy development, or domain adaptation beyond the current AI-paper focus.
- End-to-end automated scientific reporting across domains
- Sectors: healthcare/biomed (clinical study reports), materials, climate science, energy
- Tools/products/workflows: adapters for domain-specific ontologies and regulatory formats (e.g., CDISC for clinical, MIAME for genomics) to turn lab/ELN logs into compliant reports and manuscripts
- Assumptions/dependencies: domain ontologies, strict provenance, data privacy (HIPAA/GDPR), rigorous human oversight and validation studies
- “Living papers” that auto-update literature sections
- Sectors: academia, open science platforms, preprint servers
- Tools/products/workflows: agents that periodically refresh Related Work with new verified citations and mark changes; versioned, DOI-linked updates
- Assumptions/dependencies: publisher policies for dynamic updates; reproducibility and version control standards
- Conference/journal editorial automation and policy tooling
- Sectors: academic publishing, research funders
- Tools/products/workflows: standardized desk-review modules (citation coverage audits, structure/clarity checks), reviewer-assist dashboards with verified citation maps and gap summaries
- Assumptions/dependencies: community consensus on acceptable AI use; transparency and auditability requirements
- Grant and policy document evaluation assistants
- Sectors: government agencies, foundations, standards bodies
- Tools/products/workflows: evaluators that check proposal novelty claims against verified literature; detect missing must-cite references; synthesize prior art for standards/policy drafts
- Assumptions/dependencies: fairness, anti-bias calibration; explainability of decisions; procurement/security compliance
- Code/experiment-to-publication pipelines integrated with lab automation
- Sectors: robotics, autonomous labs, pharma
- Tools/products/workflows: closed-loop systems where experiment execution triggers drafting, visualization, and refinement; integration with LIMS/ELN and robotic platforms
- Assumptions/dependencies: robust data schemas; fail-safes to prevent premature claims; human-in-the-loop sign-off
- Patent and standards drafting with verified prior art
- Sectors: IP law, industry consortia, telecom/ICT
- Tools/products/workflows: “prior-art copilot” that assembles background sections, figures, and citations for patents or standards proposals, with traceable evidence
- Assumptions/dependencies: legal review, jurisdiction-specific requirements, liability considerations
- Multilingual, cross-domain scientific writing support
- Sectors: global academia and industry
- Tools/products/workflows: localized templates and retrieval for non-English literature; cross-lingual citation verification and translation-aware drafting
- Assumptions/dependencies: multilingual LLM/RAG quality; region-specific metadata APIs
- Integrity, provenance, and authorship governance
- Sectors: policy, academic governance, research ethics
- Tools/products/workflows: provenance tagging for AI-assisted content, disclosure frameworks, and automated checks for hallucinations or citation padding; integration with ORCID/DOI
- Assumptions/dependencies: community standards for disclosure; tamper-evident logs; alignment with publisher policies
- Benchmarking and evaluation ecosystem for AI writing tools
- Sectors: AI industry, edtech, publishers
- Tools/products/workflows: expanded versions of PaperWritingBench across disciplines to compare tools on standardized tasks; third-party certification of writing assistants
- Assumptions/dependencies: dataset licensing and de-identification; reproducible evaluation harnesses; continued model improvement
- Enterprise-wide knowledge synthesis and risk/compliance reporting
- Sectors: finance, insurance, energy
- Tools/products/workflows: agents that consolidate research, regulations, and internal metrics into audit-ready reports with verified references and visualizations
- Assumptions/dependencies: secure data access; compliance review; explainability and audit trails
Notes on feasibility across applications:
- Dependencies common to most use cases: reliable LLMs/VLMs, web search and metadata APIs (e.g., Semantic Scholar), access to templates/guidelines, compute budget, and human QA.
- Key risks/assumptions: domain transfer beyond AI requires curated retrieval and ontologies; publisher and regulator acceptance of AI assistance varies; robust provenance and disclosure are essential to maintain trust and accountability.
Glossary
- Ablation studies: Targeted experiments that systematically remove or vary components of a system to assess their impact on performance. "covering raw data points, ablation studies, and performance metrics."
- Agentic framework: An AI system design where autonomous agents plan, reason, and act with tools to accomplish complex tasks. "couples an agentic framework with structured knowledge and tool-based reasoning."
- Agentic tree-search: A planning method where agent actions are explored in a branching search structure to improve autonomy and decision quality. "increases autonomy using agentic tree-search."
- Anti-leakage prompt: A control instruction used to minimize training-data leakage or memorization effects in evaluations. "a universal anti-leakage prompt (App.~\ref{appendix:info_leakage})."
- Backward traceability: The ability to trace generated text back to the specific data and analyses that support it. "translating structured analytical results into text with backward traceability."
- BibTeX: A bibliography format and toolchain for managing references in LaTeX documents. "auto-generates a BibTeX (.bib) file."
- BibTeX reference list: A structured list of citations formatted for LaTeX, typically stored in .bib files. "require a structured BibTeX reference list as input"
- Citation F1: The F1 score applied to citation matching, balancing precision and recall of references. "Citation F1."
- Citation map: A structured representation linking topics or sections to relevant prior work to guide writing. "constructing a citation map, which is subsequently leveraged to draft the Introduction and Related Work sections;"
- Citation padding: Adding superfluous or irrelevant citations to inflate apparent coverage. "or citation padding"
- Citation registry: A consolidated, verified list of citations used across a manuscript. "compiles a citation registry and auto-generates a BibTeX (.bib) file."
- Closed-loop refinement: An iterative generation-evaluation cycle that repeatedly improves outputs based on feedback. "employs a closed-loop refinement system where a VLM critic evaluates rendered images against design objectives"
- Content Refinement Agent: A specialized agent that iteratively revises a manuscript using structured feedback to improve clarity and quality. "The Content Refinement Agent iteratively optimizes the manuscript using simulated peer-review feedback."
- De-contextualization: The process of removing original context so information can stand alone without external references. "The LLM further de-contextualizes this data by converting visual insights into standalone factual observations"
- Deduplication: The removal of duplicate entries, often by unique identifiers, to ensure clean citation or data lists. "Following deduplication via Semantic Scholar IDs"
- Entity relation graphs: Structured representations of entities and their relationships, used to condition text generation. "generated incremental text sequences conditioned on entity relation graphs"
- Human-in-the-loop: A design pattern where human oversight or intervention is integrated into automated workflows. "support human-in-the-loop collaboration in domain-specific applications."
- LLM-as-a-Judge: Using a LLM to evaluate and score text according to specified rubrics. "assessed by LLM-as-a-Judge (0--100 scale, Sparse Idea Setting)."
- LLM evaluator: A LLM configured to assess quality along predefined criteria. "we employ an LLM evaluator (App.~\ref{appendix:autorater_prompts}) to score the generated text"
- Parametric memory: Knowledge encoded in the learned parameters of a model rather than in external documents or tools. "relied on the parametric memory of LLMs, often leading to factual hallucinations."
- P0 (Must-Cite): References deemed essential for contextualizing a work, such as direct baselines and core dependencies. "P0 (Must-Cite) comprises core citations strictly necessary for contextualizing the work"
- P1 (Good-to-Cite): Non-essential but helpful references that provide background or complementary context. "P1 (Good-to-Cite) includes all remaining GT citations"
- Reverse-engineered raw materials: Inputs reconstructed from final papers (e.g., ideas, logs) to simulate pre-writing artifacts without leakage. "the first standardized benchmark of reverse-engineered raw materials from 200 top-tier AI conference papers"
- Retrieval-augmented generation (RAG): A method that combines information retrieval with text generation to reduce hallucinations and ground outputs. "recent frameworks employ retrieval-augmented generation (RAG) methods."
- Semantic Scholar API: A programmatic interface to query and verify scholarly metadata and paper identities. "then uses the Semantic Scholar API to authenticate their existence"
- Side-by-Side (SxS): A comparative evaluation methodology where two outputs are judged head-to-head. "Side-by-Side (SxS) Comparison."
- Temporal cutoffs: Time-based constraints that restrict retrieved or considered literature to a specified date range. "while enforcing temporal cutoffs (App.~\ref{appendix:model_details})"
- Tool-based reasoning: Augmenting model reasoning with external tools (e.g., search, code, APIs) for grounded problem solving. "structured knowledge and tool-based reasoning."
- VLM critic: A vision-LLM used to assess and guide improvements to generated visuals. "a VLM critic evaluates rendered images against design objectives"
- VLM-guided plot refinement: Iteratively improving plots using feedback from a vision-LLM. "VLM-guided plot refinement"
Collections
Sign up for free to add this paper to one or more collections.

