- The paper presents a modular system that automates claim verification in scientific peer reviews using a four-step IR and NLP pipeline.
- It employs data acquisition, claim extraction, evidence retrieval, and claim verification, validated on both controlled and real-world benchmarks.
- Empirical results show that dense retrieval paired with large language models improves accuracy in handling ambiguous reviewer language.
Peerispect: Automated Verification of Claims in Scientific Peer Review
Motivation and Context
The integrity of the peer review process is compromised when reviewers make claims that are unsubstantiated, subjective, or misaligned with the content of the submitted manuscript. With the exponential growth in the volume of submissions to top-tier conferences and journals, the manual validation of such claims becomes infeasible. Existing methodologies in factuality assessment and claim verification predominantly focus on open-domain or scientific fact-checking against external corpora but fail to address the unique scenario of verifying reviewer statements grounded solely within a single submission.
Peerispect operationalizes claim-level verification in peer review settings by decomposing the verification task into four modular IR and NLP components: data acquisition, claim extraction, evidence retrieval, and claim verification. This methodological reframing shifts the paradigm from holistic or sentiment-based analysis of reviews to fine-grained, document-grounded validation of individual review claims.
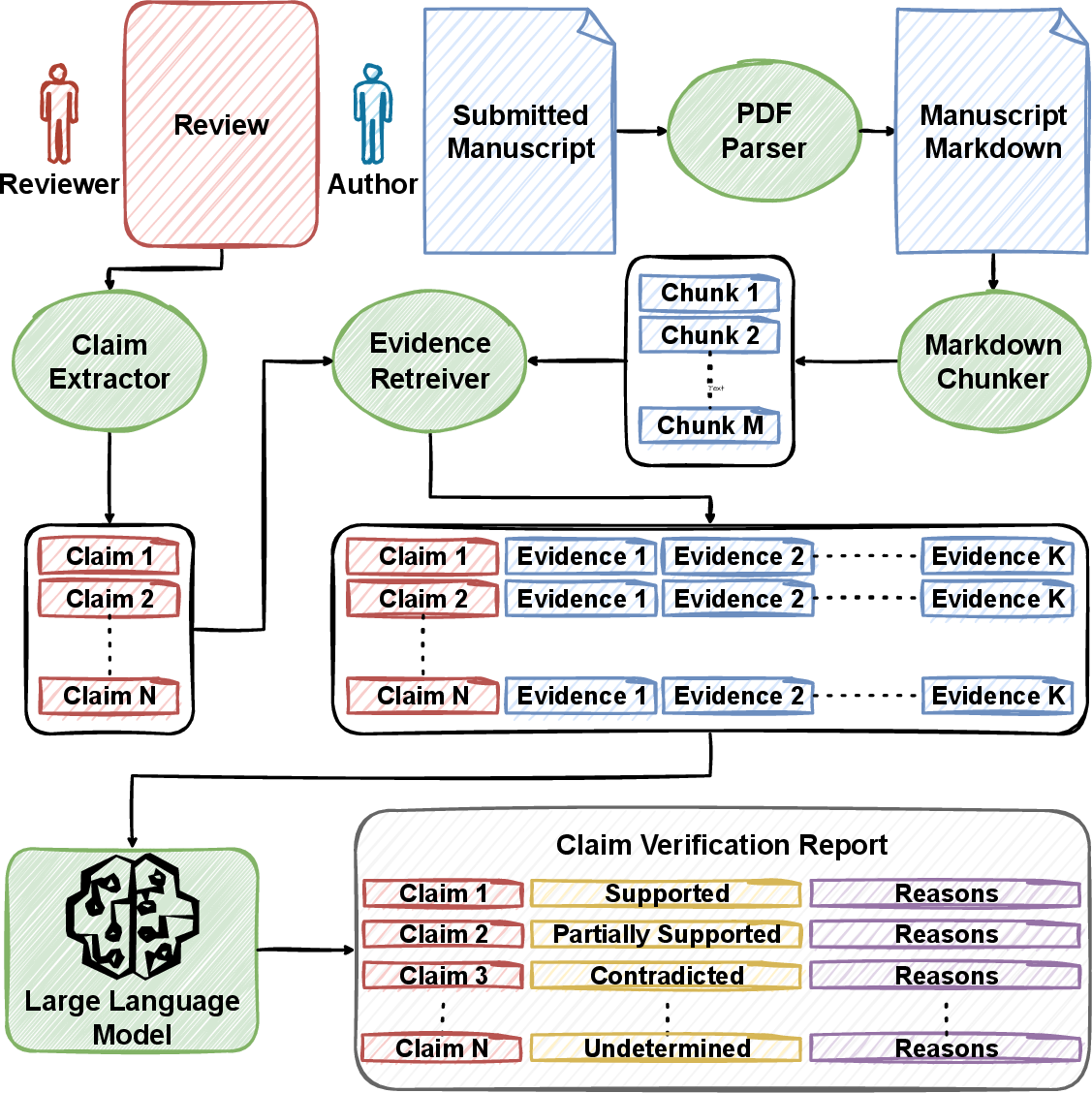
Figure 1: Peerispect architecture and processing pipeline, encompassing data acquisition, claim extraction, evidence retrieval, and claim verification.
System Architecture and Pipeline
Peerispect consists of a modular, extensible processing pipeline that systematically transforms raw manuscript and peer review text into structured, interpretable annotations denoting the grounding of review claims.
- Data Acquisition: Manuscripts are segmented into semantically coherent units serving as retrievable passages, while reviewer comments are normalized to sentence-level representations. Multiple ingestion pathways are supported, including integration with platforms such as OpenReview.net.
- Claim Extraction: Leveraging a classifier trained to discern factual, check-worthy spans from subjective or rhetorical language, review sentences are decomposed into atomic, verifiable claims through coreference resolution and hedging removal.
- Evidence Retrieval: Each claim is treated as a query over the indexed manuscript. The retrieval pipeline supports various strategies (sparse, dense, hybrid). The reference implementation employs MiniLM-L6-v2 dense embeddings with FAISS nearest neighbor search, followed by cross-encoder reranking for enhanced alignment between claims and passage-level evidence.
- Claim Verification: A LLM-based NLI verifier labels each claim-evidence pair as supported, partially supported, contradicted, or undetermined. This framework encapsulates reviewer factuality as a structured NLI problem with an interpretable output space.
The Peerispect interface enables interactive inspection, visualizing claims, evidence highlights, and NLI judgments, facilitating rapid human interpretation for reviewers, authors, and program committees.
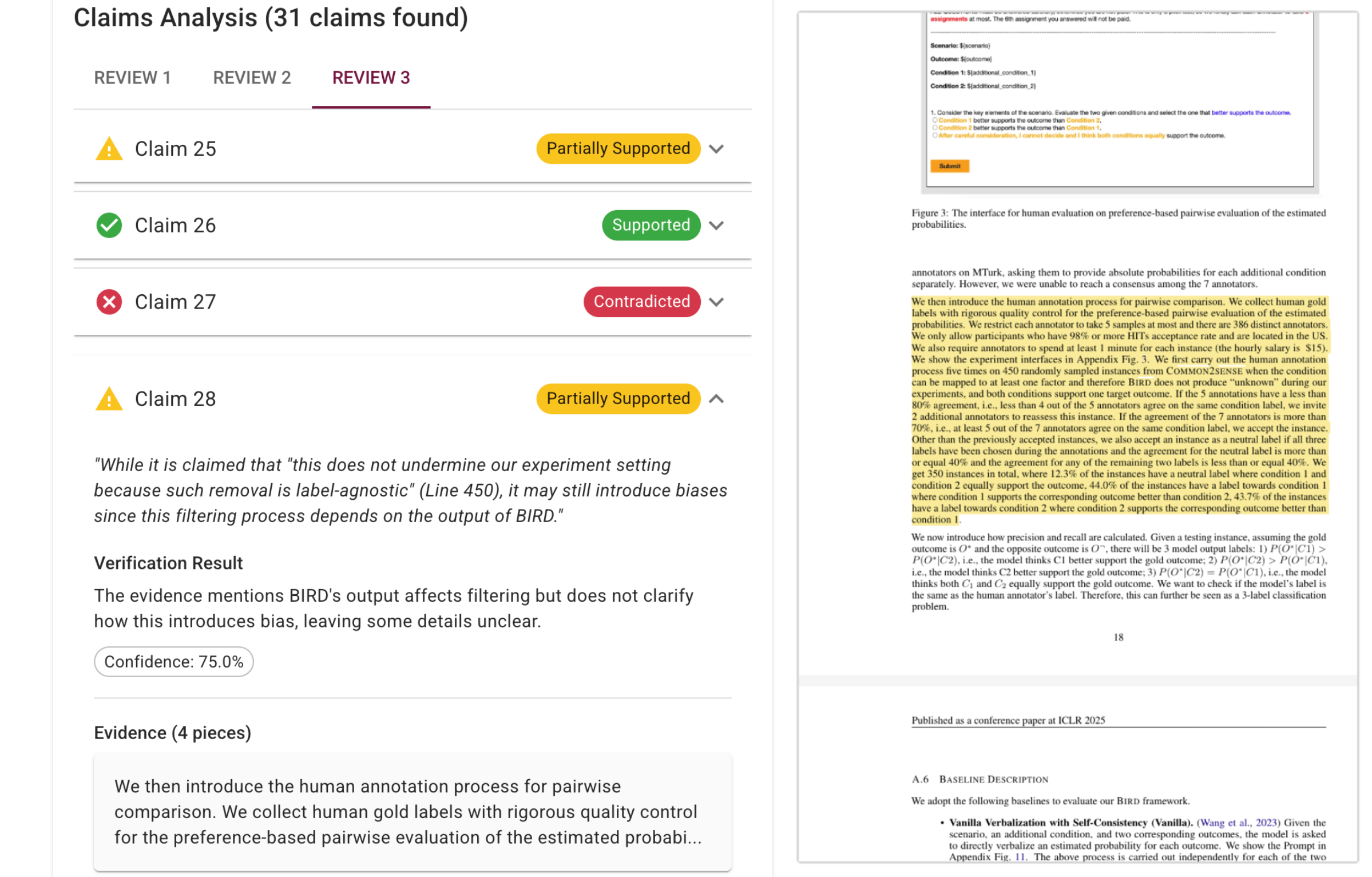
Figure 2: User interface of Peerispect, showing claim verification outputs with manuscript evidence highlights.
Empirical Validation
Peerispect was evaluated using two complementary benchmarks derived from ICLR 2024 submissions and their OpenReview review-rebuttal threads:
- Controlled Manuscript Claims (CMC): Consists of 500 atomic claims directly extracted from 50 manuscripts, all supportable by construction.
- Real-World Review Claims (RRC): Comprises 150 reviewer claims with manual annotation (supported, contradicted, partially supported, undetermined) from 25 papers, reflecting discourse-level ambiguity and paraphrasing typical of actual peer review language.
Key experimental observations include:
- On CMC, larger verifier models (Qwen-2.5-7B) yield substantially higher accuracy (up to 0.905 with BM25 retrieval), validating that model capacity enhances nuanced NLI classification when claims are lexically similar to manuscript text.
- On RRC, accuracy is uniformly lower across retriever-verifier combinations due to increased ambiguity and paraphrasing. Dense retrieval with reranking—paired with the Qwen-2.5-7B verifier—achieves superior accuracy (0.287), indicating that dense semantic representations better accommodate paraphrase and conceptual drift prevalent in free-form reviewer language.
The benchmarks highlight that Peerispect's reliability is highest in controlled, lexically aligned scenarios, while robust retrieval and larger verifiers substantially mitigate, but do not eliminate, the challenges inherent in noisy, real-world review discourse.
Implementation and Interface
The backend is implemented with FastAPI and orchestrates all data and model services, supporting modular retriever/reranker/verifier replacement and cloud-scalable deployment via Dockerized containers. The frontend, constructed with React and react-pdf-highlighter, overlays evidence highlights directly onto manuscript PDFs. Inference relies on VLLM, defaulting to Qwen-2.5-7B, with easy model interchangeability. Peerispect thus satisfies the requirements for local deployment, privacy, and extensibility, making it suitable for integration in live reviewing workflows at scale.
Theoretical and Practical Implications
- Theoretical Significance: Peerispect reframes peer review analysis as a document-grounded IR and NLI task, operationalizing claim verification at the sentence level. It exposes limitations in both current retrieval and NLI techniques under high ambiguity, and provides a platform for exploring improved methods in retrieval robustness, claim decomposition, and evidence alignment.
- Practical Impact: The system increases transparency and accountability in peer review by rendering the evidence-claim relationship explicit for all stakeholders. For review transparency initiatives, Peerispect provides an actionable mechanism to flag unsupported or contradictory statements, thereby improving review quality control at scale.
- Future Developments: Advances in retrieval over highly paraphrased or imprecise reviewer language, context-aware claim normalization, and multi-claim discourse modeling are likely directions. The modularity of Peerispect allows for straightforward integration of new retrievers, rerankers, and verifiers, including next-generation LLMs or hybrid symbolic-neural methods. Automated rebuttal suggestion or argumentative dialogue management could be layered atop Peerispect’s outputs.
Conclusion
Peerispect advances the state of automated peer-review analysis by distilling review text into verifiable claims, retrieving manuscript-grounded evidence, and assigning fine-grained NLI judgments, all presented in an interpretable visual environment. Empirical validation demonstrates that accuracy is high when claims closely match manuscript text, and that dense retrieval paired with large verifiers offers greater resilience to the inherent ambiguity of real reviewer discourse. This work establishes claim-level verification as a central technical subproblem for future research in automated scholarly communication and IR, encouraging further exploration of retrieval-inference synergies and their application to large-scale, human-in-the-loop review processes.