- The paper introduces PeerQA, a dataset sourced from peer reviews to enhance scientific question answering by addressing evidence retrieval and unanswerable question classification.
- It evaluates various retrieval and generation models using metrics like Rouge-L, AlignScore, and Prometheus Correctness, demonstrating that decontextualization improves retrieval performance.
- The methodology highlights PeerQA’s potential to assist academic review workflows and drive innovations in AI-assisted peer review processes.
"PeerQA: A Scientific Question Answering Dataset from Peer Reviews" (2502.13668)
Introduction
The research paper "PeerQA: A Scientific Question Answering Dataset from Peer Reviews" introduces PeerQA, a dataset specifically crafted for scientific question answering by leveraging questions derived from peer reviews. This dataset emphasizes document-level question answering and serves to advance AI systems in extracting meaningful insights from complex scientific texts. PeerQA delineates its focus into three main tasks: evidence retrieval, unanswerable question classification, and answer generation.
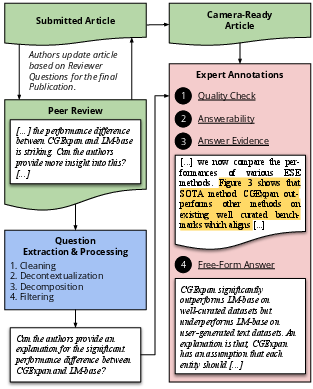
Figure 1: Overview of the PeerQA data collection process.
Dataset Characteristics
PeerQA comprises 579 question-answer pairs sourced from 208 academic articles, prominently featuring contributions from domains such as Machine Learning (ML), NLP, Geosciences, and Public Health. The dataset's construction involved extracting questions posed within peer reviews and annotating responses from the respective paper authors. A unique aspect of PeerQA is the inclusion of both labeled and unlabeled questions; it offers a set of 579 reviewed samples alongside 12,000 unlabeled questions for broader experimentation.
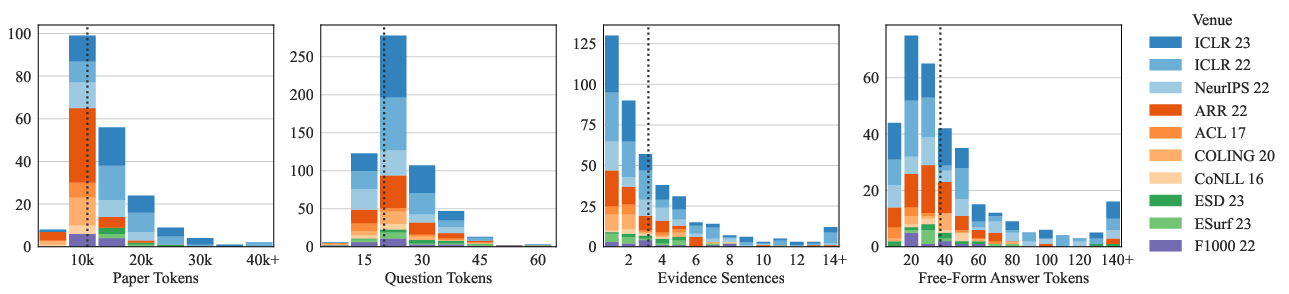
Figure 2: Statistics of the PeerQA dataset.
Experimental Setup
The authors conducted baseline experiments to evaluate systems across PeerQA's core tasks. Notably, they investigated the retrieval performance of several architectures, including crossover, dense, sparse, and multi-vector retrieval models, demonstrating that even straightforward decontextualization significantly enhances retrieval accuracy. The release also involved comparing models' effectiveness in generating answers, aided by metrics such as Rouge-L, AlignScore, and Prometheus Correctness.
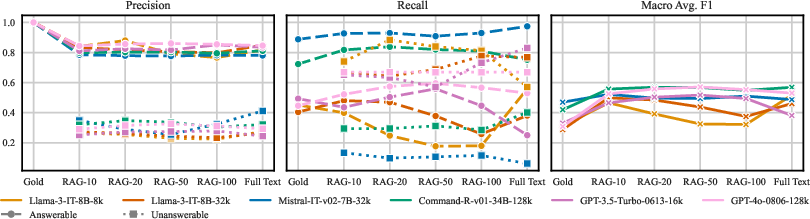
Figure 3: Answerability scores with different contexts.
Answer Generation and Evaluation
PeerQA benchmarks long-context modeling given the average paper length of approximately 12,000 tokens—a challenge for current generative models. The experiments revealed that assembling relevant contexts from high-recall retrievers notably benefits answer generation performance. The dataset serves as a valuable reference for assessing models based on their ability to generate coherent answers in the presence of diverse, evidence-driven data scenarios.
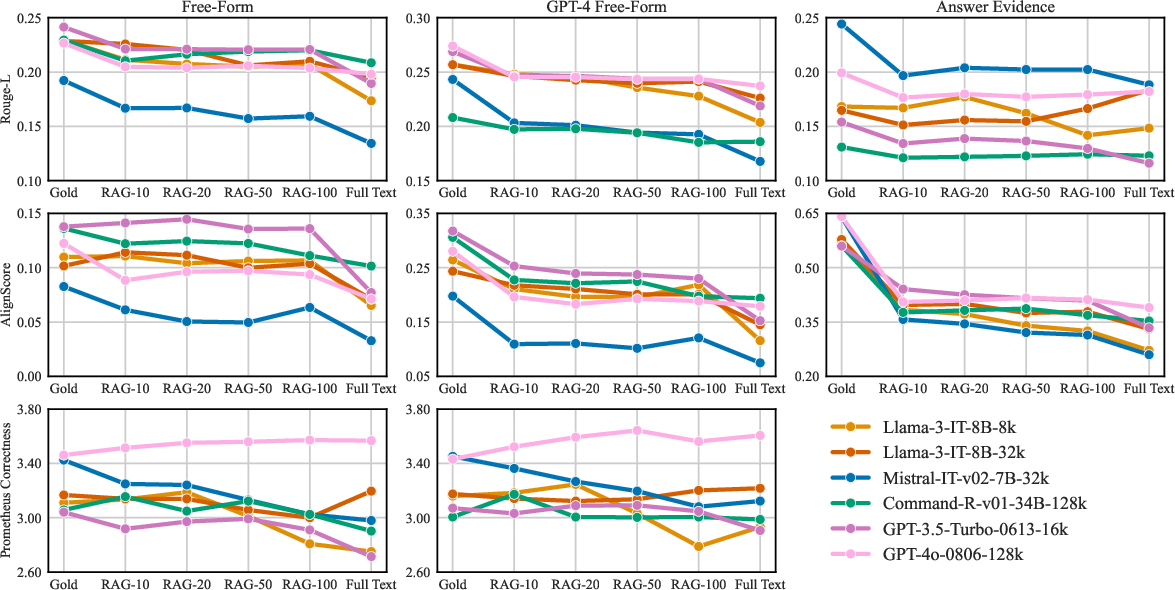
Figure 4: Evaluation metrics comparing generated and annotated responses.
Implications and Future Directions
By sourcing questions from authentic peer reviews, PeerQA ensures natural question-context alignment—a significant drawback in prior datasets sourced from less domain-expert inputs. It posits a strong case for deploying QA systems within academic review workflows, potentially aiding reviewers by illuminating overlooked sections or gently guiding them through complex, multi-faceted papers. Future directions could involve expanding PeerQA across further scientific domains, conducting cross-domain model evaluations, or utilizing unlabeled data to explore unsupervised learning techniques.
Conclusion
PeerQA stands as a substantial resource for refining scientific document-level QA systems, grounded uniquely in the context of peer reviews. It catalyzes advancement in AI-enabled peer reviewing processes, tasked with handling voluminous scientific production. Its protocols and findings open pathways for both improved AI methods and enriched academic collaboration dynamics.
The paper establishes a precedent for harmonizing AI research with scientific authoring tasks and could foreseeably drive developments where AI assists not just in reviewing but also generates supportive interpretive content directly augmenting scientific understanding.