Qwen3.5-Omni Technical Report
Abstract: In this work, we present Qwen3.5-Omni, the latest advancement in the Qwen-Omni model family. Representing a significant evolution over its predecessor, Qwen3.5-Omni scales to hundreds of billions of parameters and supports a 256k context length. By leveraging a massive dataset comprising heterogeneous text-vision pairs and over 100 million hours of audio-visual content, the model demonstrates robust omni-modality capabilities. Qwen3.5-Omni-plus achieves SOTA results across 215 audio and audio-visual understanding, reasoning, and interaction subtasks and benchmarks, surpassing Gemini-3.1 Pro in key audio tasks and matching it in comprehensive audio-visual understanding. Architecturally, Qwen3.5-Omni employs a Hybrid Attention Mixture-of-Experts (MoE) framework for both Thinker and Talker, enabling efficient long-sequence inference. The model facilitates sophisticated interaction, supporting over 10 hours of audio understanding and 400 seconds of 720P video (at 1 FPS). To address the inherent instability and unnaturalness in streaming speech synthesis, often caused by encoding efficiency discrepancies between text and speech tokenizers, we introduce ARIA. ARIA dynamically aligns text and speech units, significantly enhancing the stability and prosody of conversational speech with minimal latency impact. Furthermore, Qwen3.5-Omni expands linguistic boundaries, supporting multilingual understanding and speech generation across 10 languages with human-like emotional nuance. Finally, Qwen3.5-Omni exhibits superior audio-visual grounding capabilities, generating script-level structured captions with precise temporal synchronization and automated scene segmentation. Remarkably, we observed the emergence of a new capability in omnimodal models: directly performing coding based on audio-visual instructions, which we call Audio-Visual Vibe Coding.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Qwen3.5‑Omni Technical Report — A simple explanation
1) What is this paper about?
This paper introduces Qwen3.5‑Omni, a new kind of AI model that can understand and respond using many types of information at once—text, images, audio, and video. Think of it as a smart assistant with multiple senses that can read, listen, watch, talk back in real time, and even use tools like web search. It’s built to handle very long inputs (like hours of audio or long videos) and to speak naturally in many languages.
2) What questions were the researchers asking?
The team set out to solve a few big problems:
- How can a single AI handle text, images, audio, and video together, in real time, without getting confused?
- How can it remember and reason over very long inputs (like long recordings or long documents)?
- How can it speak more naturally during live conversations without sounding choppy or skipping words?
- How can it understand and speak across many languages and even copy a user’s voice style from just a sample?
- How well can it compare to other leading models (like Gemini) on many tests across listening, understanding, reasoning, and talking?
3) How did they build and test it?
Here’s the approach in everyday language:
- A “Thinker & Talker” team:
- Thinker = the brain that reads text, sees pictures/videos, listens to audio, and decides what to say or do.
- Talker = the voice box that turns the Thinker’s ideas into smooth, realistic speech in real time.
- A team-of-experts inside:
- The model uses something called “Mixture‑of‑Experts (MoE).” Imagine a classroom of specialists—only the best few for each task speak up, which makes the system faster and smarter for long, complicated inputs.
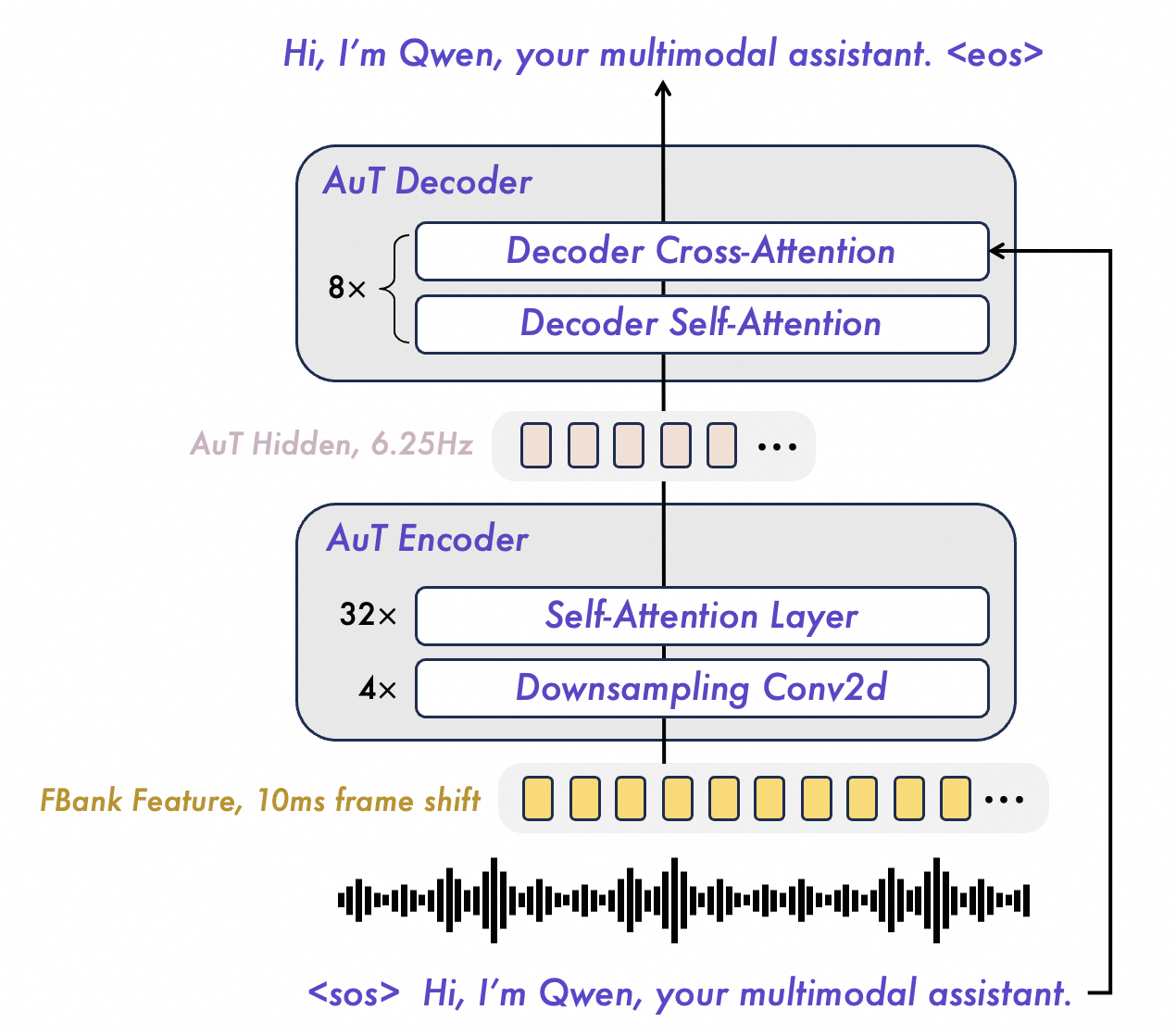
- Listening with a dedicated audio brain (AuT):
- The Audio Transformer (AuT) is trained on a huge amount of speech (about 40 million hours) in many languages. It turns sound into compact “audio tokens,” like notes on a music sheet, so the Thinker can understand it.
- Keeping time across video and audio:
- Videos and audio are marked with timestamps (like the timecodes in a movie). This helps the model keep everything in sync so it knows which sound belongs to which moment in the video.
- Speaking clearly with ARIA:
- ARIA (Adaptive Rate Interleave Alignment) is like a metronome that keeps text and speech in sync during live talking. It prevents the voice from speeding up, skipping words, or misreading numbers—especially important when the model is streaming speech as it thinks.
- Made for real-time:
- The system processes inputs in chunks, rather than all at once. That’s like reading a page at a time instead of the whole book before answering—so it starts responding in under a second and keeps the conversation flowing.
- Trained in stages with lots of data:
- Pretraining: The model learns from massive amounts of text, images, videos, and audio (including 100+ million hours of audio‑video).
- Post‑training for Thinker: It learns from specialist teacher models, aligns its behavior so audio and text queries get equally good answers, and then gets fine‑tuned with reinforcement learning to behave better in long, multi‑turn chats.
- Post‑training for Talker: It learns to generate smoother, more expressive speech, gets better at long contexts, is tuned to match human preferences, and can adapt to specific voices.
4) What did they find, and why is it important?
- Handles very long inputs:
- Can work with up to 256k “tokens” (a lot of text), over 10 hours of audio, and several minutes of video—letting it follow long stories, lectures, or meetings.
- Fast, natural speech:
- Thanks to ARIA and a frame‑by‑frame speech system, it speaks smoothly in real time with low delay. It also supports emotional tone, speed, and volume control—like talking to a person.
- Stronger than top competitors on many audio tasks:
- On 215 tests covering audio and audio‑visual understanding and conversation, Qwen3.5‑Omni‑Plus achieves state‑of‑the‑art performance. It beats Gemini‑3.1 Pro on many audio tasks and matches it on overall audio‑visual understanding.
- Multilingual and voice‑flexible:
- Understands speech in over 100 languages and dialects, and can speak in dozens. It can also clone a user’s voice from a sample (zero‑shot), making responses sound like a chosen voice.
- Better video‑audio grounding and captioning:
- It can create detailed, structured captions for videos, including automatic scene breaks and timestamps—useful for summarizing or indexing content.
- A new skill: Audio‑Visual Vibe Coding:
- The model can watch or listen to instructions in a video/audio and directly write code—an emergent behavior that could help automate tasks from demonstrations.
5) Why does this matter?
- More helpful assistants:
- An assistant that can watch, listen, read, and talk—all at once—can help with meetings, classes, tutorials, or troubleshooting videos and respond naturally in real time.
- Better accessibility:
- Multilingual understanding and natural, expressive speech can support people who speak different languages or rely on speech for communication.
- Smarter media tools:
- Detailed, timestamped captions and scene segmentation can help creators, educators, and platforms organize and summarize long videos.
- Learning and coding from demos:
- “Vibe coding” hints at AI that learns tasks from audio‑visual examples and produces working code, potentially speeding up how people prototype or automate workflows.
- Scalable, efficient design:
- The expert‑based architecture and chunked streaming help keep it fast and affordable to run, which is important for real‑world apps.
In short, Qwen3.5‑Omni brings together seeing, listening, reading, reasoning, and speaking—quickly and across many languages—while performing at or above the level of top models on many tests. That makes it a strong step toward AI that interacts more like a helpful, real‑time human assistant.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and unresolved questions that future work could address:
- ARIA specification and ablations are missing: no formal algorithmic description, hyperparameters, or comparisons to alternative alignment schemes (e.g., MFA, fixed interleave, learned aligners) across languages and speaking rates.
- ARIA’s “adaptive rate constraint” is under-specified: how is the “item-level global ratio” determined in streaming when the full utterance length is unknown, and how does the constraint behave under code-switching or extremely fast/slow speech?
- Lack of quantitative analyses of ARIA’s failure modes (e.g., number reading errors, word skipping, prosody drift) and robustness to interruptions, barge-in, and long-running dialogues.
- No human MOS or objective TTS quality metrics (e.g., MOSNet, DNSMOS, CER from ASR on TTS output) reported across the 36 output languages and voices; prosody/emotion claims are not empirically substantiated.
- No ablation studies for key architectural choices (Hybrid MoE, GDN, MTP, RVQ codebook depth/width) to isolate their contributions to latency, quality, and long-context stability.
- Expert routing in Hybrid MoE lacks transparency: no statistics on expert utilization, load balancing, gating stability across modalities, or effects on capacity under long-context decoding.
- Long-context claims (256k tokens, >10 hours audio, 400s video at 1 FPS) are not validated with targeted long-sequence multimodal benchmarks; only text long-context is reported, leaving degradation over very long audio/video unquantified.
- Memory footprint and KV-cache scaling at 256k for Thinker/Talker are not reported (e.g., VRAM usage per concurrency level, cache eviction strategies, compute cost per hour of context).
- The AuT temporal downsampling to ~6.25 Hz (~160 ms steps) may blur short acoustic events; impact on fast speech, speaker overlap, VAD/diarization, and fine-grained AV sync is not evaluated.
- Video sampling at 1 FPS for long clips risks missing fast actions; the dynamic frame-rate policy and its trade-offs (accuracy vs. compute) are unspecified and unevaluated across motion-heavy tasks.
- Timestamp-as-text injection for temporal grounding increases context length; its overhead, susceptibility to “prompt injection” via spoken/visual timestamps, and robustness to A/V drift are not assessed.
- Data transparency is limited: the composition, provenance, licensing, and demographic distribution of the 100M+ hours audiovisual corpus and 40M hours for AuT are not disclosed, impeding reproducibility and bias assessment.
- AuT is trained on labels “generated by Qwen3-ASR,” introducing self-training feedback loops; the impact of label noise and error propagation is not analyzed.
- Multilingual coverage is broad but uneven: per-language performance, low-resource language behavior, and dialect/accent robustness (especially for TTS) lack granular reporting and error breakdowns.
- Code-switching performance (ASR, S2TT, TTS, and dialogue) is not explicitly evaluated despite being common in multilingual use; ARIA’s behavior under code-switching remains unknown.
- Theoretical latency numbers lack comprehensive hardware and deployment details (GPU type/count, precision, batch sizes, context lengths, token generation settings) and do not include variance or confidence intervals; real-world end-to-end measurements are missing.
- Concurrency scaling is characterized as “theoretical”; the impact of heterogeneous user workloads, bursty traffic, and long-context sessions on throughput, fairness, and tail latencies is not reported.
- Tool use (WebSearch, FunctionCall) is only lightly evaluated (e.g., a single OmniGAIA score); no error analysis on tool selection accuracy, grounding failures, or hallucinated tool invocations, nor latency/cost accounting for tool calls.
- The emergent “Audio-Visual Vibe Coding” is not operationalized: no task taxonomy, datasets, baselines, or reliability metrics (e.g., pass@k, unit tests), and no safety analysis for code generation from A/V prompts.
- Safety, security, and robustness evaluations are absent: no adversarial tests (e.g., ASR-targeted perturbations, visual prompt attacks), toxicity/toxic speech benchmarking, or mitigation audits for tool-enabled actions.
- Voice cloning raises impersonation risks; no guardrails (consent verification, watermarking/detection, anti-spoofing, speaker-ID protections) or policy/compliance mechanisms are described.
- Fairness and bias analysis is missing: no demographic breakdowns (gender, age, accent, region) for ASR/S2TT/TTS or audiovisual understanding; no assessment of harmful stereotypes in generated speech.
- Privacy posture is unclear: how user audio/voice samples are stored/used, whether voice embeddings can be extracted, and what safeguards prevent speaker identity leakage.
- Benchmark reproducibility risks: prompting protocols, temperatures, seeds, normalization rules (e.g., punctuation, casing) and evaluation scripts for WER/S2TT are not detailed, and significance testing is absent.
- Risk of benchmark contamination is unaddressed given massive pretraining; no steps are described to ensure test set isolation for MMLU(-Redux), MMMU, etc.
- The claim of “on par with text-only models” lacks statistical testing and shows drops in several tasks for the Flash variant; conditions under which multimodal co-training degrades single-modality performance are not identified.
- Real-time interaction features (turn-taking, barge-in, interruption control) are asserted without quantitative metrics (e.g., intent-detection accuracy, barge-in latency, false-interruption rate) or ablations.
- No on-device feasibility analysis (quantization, streaming footprint, codec bandwidth, CPU-only scenarios) for edge deployment; RVQ codebook sizes/bitrates and end-to-end bandwidth needs are unspecified.
- Failure handling in streaming (e.g., packet loss, jitter, mid-utterance policy changes) is not discussed; how ARIA and the codec recover from dropped frames or re-synchronization is unknown.
- Interaction-Aligned RL and DPO/GSPO stages lack reward definitions, stability analyses, and cross-objective trade-offs (e.g., instruction-following vs. persona consistency) with quantitative evidence.
- Structured, controllable audiovisual captioning claims (scene segmentation, timestamps, character relations) lack standardized metrics, datasets, and baselines (e.g., boundary F1, temporal IoU, caption factuality).
- Security for tool-enabled agents is not specified (e.g., default-deny policies, sandboxing constraints, prompt-injection defenses from A/V inputs, audit logs for actions).
- Public availability is via API only; absence of model weights, training code, and data cards hinders independent verification, ablation, and community auditing.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging Qwen3.5-Omni’s real-time, omnimodal (text–image–audio–video) understanding, long-context processing (up to 256k tokens), low-latency streaming TTS with ARIA, multilingual ASR/S2TT/TTS, structured audiovisual captioning, and native tool-use (WebSearch/FunctionCall) capabilities.
- Real-time multilingual voice assistants for contact centers
- Sectors: Customer support, finance, e-commerce, telecom
- What this enables: Sub‑second turn-taking voicebots that understand and respond in 113+ input languages and speak in 36+ output languages with controllable prosody/emotion; agent-assist (live transcription, summarization, suggested actions); brand voice via zero-shot voice cloning; stable streaming TTS via ARIA.
- Tools/workflows: “Omni Voicebot” API integration with CRM/ITSM; call routing, QA summaries, after-call notes; auto redaction of PII; on-policy distillation improves parity between audio- and text-conditioned responses.
- Assumptions/dependencies: Data privacy/compliance (e.g., GDPR/CCPA/GLBA), consent for voice cloning, telephony integration, guardrails for tool-use, sufficient GPU capacity for concurrency.
- Meeting intelligence at scale (10h audio, long-context notes)
- Sectors: Enterprise, education, legal, R&D
- What this enables: Accurate ASR on long meetings, multilingual translation, topic clustering, action-item extraction, speaker-style-aware TTS summaries; handles long recordings and large document/video attachments.
- Tools/workflows: “Meeting AI” pipeline—ingest audio/video + slides, produce timestamped transcripts, summaries, follow-ups.
- Assumptions/dependencies: Organizational privacy policies, optional diarization integration if per-speaker output is required, human-in-the-loop for critical decisions.
- Structured audiovisual captioning and indexing with timestamps
- Sectors: Media/streaming, e-learning, news, archives
- What this enables: Script-level captions with temporal synchronization, auto scene segmentation, character/scene descriptions; facilitates search, QA, and accessibility.
- Tools/workflows: SRT/VTT caption generator, timeline-based media indexer, scene/shot breakdown API.
- Assumptions/dependencies: Rights to process content, accurate timecode alignment (enabled by explicit timestamps), compute for batch processing large catalogs.
- Live captioning, interpretation, and AI dubbing
- Sectors: Events, education, broadcast, government services
- What this enables: Real-time subtitles and S2TT; expressive TTS for multilingual dubbing; near real-time delivery with ARIA-stabilized prosody; zero-shot brand/speaker voice.
- Tools/workflows: Live interpreter service (ASR → translation → TTS), on-the-fly alternate-language audio tracks, classroom accessibility.
- Assumptions/dependencies: Latency budgets (~200–650 ms first packet per paper), rights for voice cloning, lip-sync constraints for broadcast-quality dubbing may require post-process alignment.
- Accessibility: audio description and assistive narration
- Sectors: Public sector, media, education, corporate communications
- What this enables: Detailed audio descriptions for visually impaired users; structured video narration with timestamps and scene semantics; multilingual outputs.
- Tools/workflows: “Describe Video” API integrated into CMS/players; automated conformance to accessibility policies.
- Assumptions/dependencies: Editorial QA for sensitive content; adherence to accessibility standards (e.g., WCAG).
- Language learning and pronunciation coaching
- Sectors: Edtech, tutoring, corporate L&D
- What this enables: Interactive voice dialogue in many languages/dialects; immediate coaching, pronunciation feedback, and role-play; expressive TTS for prosody modeling.
- Tools/workflows: Conversation practice agent, lesson-tailored TTS, video Q&A on lectures/tutorials.
- Assumptions/dependencies: Curriculum alignment; privacy controls for student audio.
- Healthcare dictation and multilingual patient communication
- Sectors: Healthcare, telemedicine
- What this enables: High-accuracy ASR for clinician notes; summaries of long consults; patient instruction translation; conversational triage via voice.
- Tools/workflows: Clinical dictation tool, visit-summary generator, intake/triage voicebots.
- Assumptions/dependencies: HIPAA/local medical privacy compliance; clinical validation; minimize hallucinations for clinical content; human oversight.
- Enterprise compliance and conversation analytics
- Sectors: Finance, insurance, healthcare, public sector
- What this enables: Risk/compliance flagging from calls/videos; multilingual monitoring; sentiment and behavior analysis; searchable recordings with timestamped evidence.
- Tools/workflows: QA dashboards, escalation triggers, case-building timelines.
- Assumptions/dependencies: High-recall requirements for risk detection; secure data handling; policy-aligned retention.
- Media post-production: script breakdown and subtitle workflows
- Sectors: Film/TV, digital content studios, advertising
- What this enables: Automated scene/shot lists, character/prop mentions, SRT creation, multilingual captions, rough-cut narration.
- Tools/workflows: “Script Breakdown” batch tool; integration with NLEs and MAMs.
- Assumptions/dependencies: Human review for editorial quality; IP considerations for voice cloning.
- In-car and device voice assistants with expressive TTS
- Sectors: Automotive, consumer devices, smart home
- What this enables: Low-latency speech interaction, on-the-fly instruction following, multilingual commands, emotion-aware responses, cross-modal inputs (voice + images/videos from device cameras).
- Tools/workflows: Voice UI SDK using streaming ASR/TTS; tool-use for navigation, media, home automation.
- Assumptions/dependencies: Connectivity/edge compute availability; privacy-by-design; HMI safety constraints.
- Brand-aligned voice chatbots and microcontent production
- Sectors: Retail, marketing, gaming, media
- What this enables: Zero-shot cloning for brand voices; consistent persona, controllable emotion; short-form audio content generation for campaigns/support.
- Tools/workflows: “Brand Voice Studio” (ingest a few samples → deploy voice); campaign-level prompt templates.
- Assumptions/dependencies: Consent/licensing for voices; safeguards against misuse and impersonation.
- Research and dataset bootstrapping for multimodal AI
- Sectors: Academia, industrial research
- What this enables: Large-scale controllable audiovisual captions with timestamps for training/evaluation; multilingual ASR/S2TT baselines.
- Tools/workflows: “Omni Captioner” for data creation; evaluation scripts using benchmark-aligned prompts.
- Assumptions/dependencies: Data governance; benchmarking reproducibility; licensing of source media.
- Content moderation for user-generated audio/video
- Sectors: Social media, marketplaces, gaming
- What this enables: Multimodal moderation that considers visuals, speech, and sounds; timestamped evidence; multilingual policy checks.
- Tools/workflows: Moderation API integrated with trust & safety pipelines; reviewer tools linking timecodes to policy.
- Assumptions/dependencies: Policy tuning and high-precision thresholds; appeals processes; handling adversarial content.
- Voice-first software assistance and simple voice-to-code
- Sectors: Software, IT helpdesk, low-code/no-code
- What this enables: Voice-driven code snippets and tool invocation; simple automation via FunctionCall; pair-programming by voice.
- Tools/workflows: IDE plugin using ASR→reasoning→code suggestions; voice-triggered RPA for routine tasks.
- Assumptions/dependencies: Scope limits for safe code generation; CI/unit tests; human review of critical code changes.
- Cross-lingual government and public service hotlines
- Sectors: Public sector, NGOs
- What this enables: Real-time translation and voice response for diverse populations; multilingual intake and information services.
- Tools/workflows: Hotline augmentation with streaming S2TT/TTS; knowledge-grounded answers via WebSearch/FunctionCall.
- Assumptions/dependencies: Accuracy for high-stakes inquiries; cultural/linguistic sensitivity; data protection.
Long-Term Applications
These use cases are plausible extensions but may require additional research, scaling, productization, safety validation, or ecosystem integration.
- Audio-Visual Vibe Coding for complex RPA and “program-from-demo”
- Sectors: Enterprise IT, SaaS automation, QA
- Vision: Generate robust, multi-step automations or code directly from narrated screen recordings or real-world video instructions (e.g., “watch this workflow and build the script”).
- Dependencies: Reliability on arbitrary UIs, robust grounding to UI elements, security/permission modeling, sandboxed execution, evaluation frameworks.
- Multimodal household and industrial robotics control
- Sectors: Robotics, manufacturing, logistics
- Vision: Voice + video-in-the-loop instruction following, tool-use, and environment-aware actions (agentic behavior with function/tool calls).
- Dependencies: Real-time perception-action loops, safety guarantees, alignment, integration with robot control stacks; regulatory/safety approvals.
- On-device, privacy-preserving omni assistant
- Sectors: Mobile, automotive, wearables, AR glasses
- Vision: Fully local inference with low power and sustained streaming audio/video; fallback to cloud for heavy tasks.
- Dependencies: Model compression/distillation, edge accelerators, memory footprint constraints, thermal limits, offline speech/vocab adaptation.
- Broadcast-grade dubbing with precise lip sync and emotion transfer
- Sectors: Media localization, entertainment
- Vision: Cross-lingual TTS that matches timing, lip movements, and nuanced emotion while preserving target identity.
- Dependencies: Visual phoneme alignment, lip-sync adaptation, high-fidelity voice/style transfer; legal frameworks for voice likeness.
- Proactive safety monitoring from AV streams
- Sectors: Industrial safety, transportation, security
- Vision: Detect hazardous events or anomalies by jointly modeling sounds and visuals (alarms, spills, machinery faults).
- Dependencies: High recall/precision, edge processing for latency, privacy constraints, well-calibrated false-positive handling.
- Clinical decision support from multimodal signals
- Sectors: Healthcare
- Vision: Triage or screening assistance using speech (e.g., cough, breath) and video (e.g., gait, tremor) plus language understanding.
- Dependencies: Clinical trials, regulatory clearance, robust bias evaluation, integration with EHRs; model interpretability.
- Legal-grade transcription and evidence timelines
- Sectors: Legal, compliance, law enforcement
- Vision: Certified, chain-of-custody transcripts, reliable speaker attribution, timestamped event timelines from long-form AV evidence.
- Dependencies: Speaker diarization and verification at high accuracy, secure audit trails, jurisdictional admissibility standards.
- Adaptive education with multimodal engagement analysis
- Sectors: Edtech, corporate training
- Vision: Real-time adjustments to teaching based on voice and visual signals of engagement; personalized pacing and support.
- Dependencies: Privacy/consent, fairness/bias controls, rigorous efficacy studies, opt-in analytics.
- Driver and cabin co-pilots with scene understanding
- Sectors: Automotive
- Vision: Voice co-pilot that understands external scene audio/visual inputs (e.g., sirens, road signs) and assists with navigation and safety checks.
- Dependencies: Integration with vehicle sensors, functional safety standards (ISO 26262), offline mode resilience, certification.
- Multimodal enterprise search and reasoning across long corpora
- Sectors: Enterprise knowledge management, media archives
- Vision: Query and reason over hours-long AV assets and large document sets, with timestamped citations and scene references.
- Dependencies: Scalable vector stores for multimodal embeddings, robust grounding/citation, access control and tenancy.
- Music intelligence for production and rights management
- Sectors: Music tech, media rights
- Vision: Structure analysis (sections, form) to drive editing, remix assistance, rights identification, and synchronization.
- Dependencies: Coverage across genres/recording styles, rights and licensing frameworks, integration with DAWs and rights databases.
- Personalized speech prosthetics and voice restoration
- Sectors: Healthcare, assistive tech
- Vision: Patient-specific TTS with emotional nuance and low-latency interaction; zero-shot cloning from limited samples.
- Dependencies: Medical device regulation, ethical consent, safety and robustness in varied environments.
Notes on feasibility and deployment
- Model access: The paper indicates API availability via Alibaba Cloud; production deployments depend on SLA, throughput, and regional availability.
- Latency and concurrency: Reported first-packet latency (≈235–651 ms) and stable generation RTF support live experiences; actual performance depends on deployment stack and workload.
- Safety and governance: Voice cloning, autonomous tool-use, and cross-modal reasoning require strong consent, guardrails, auditability, and abuse prevention.
- Accuracy and QA: High-stakes domains (healthcare, legal, finance) require human-in-the-loop validation, domain fine-tuning, and monitoring for hallucinations.
- Integration: Real value emerges when coupled with CRMs, contact-center platforms, LMS/CMS, MAM/NLE, IDEs/RPA tools, and enterprise data systems via FunctionCall/WebSearch.
- Compute and cost: Long-context and AV workloads are compute-intensive; cost-effective batching/concurrency and selective modality use are important for ROI.
Glossary
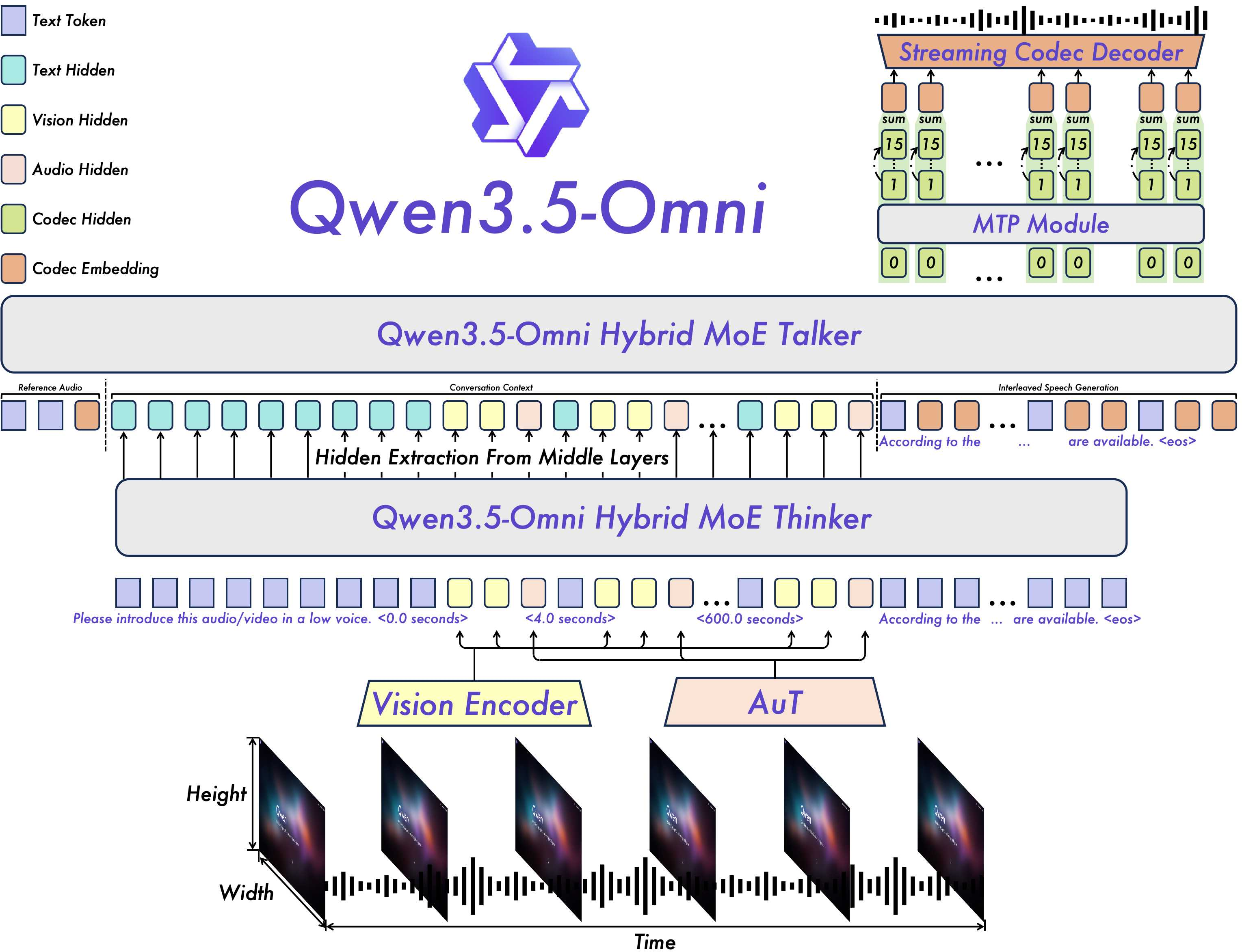
- Adaptive Rate Interleave Alignment (ARIA): A decoding scheme that adaptively aligns text and speech token rates to stabilize streaming TTS. "we introduce ARIA (Adaptive Rate Interleave Alignment)."
- Agentic behavior: The model’s capacity to act autonomously, invoke tools, and make decisions beyond passive response. "limited capacity for scalable agentic behavior"
- ASR (Automatic Speech Recognition): Converting spoken audio into text. "ASR performance is measured"
- Audio Transformer (AuT): A transformer-based audio encoder used to tokenize and represent audio inputs. "Audio Transformer~(AuT)"
- Audio-visual grounding: Linking sounds and visuals to specific events/objects with precise temporal alignment. "superior audio-visual grounding capabilities"
- Audio-Visual Vibe Coding: An emergent capability where the model writes code directly from audiovisual instructions. "which we call Audio-Visual Vibe Coding."
- Autoregressive prediction: Generating each output token conditioned on previously generated tokens. "Talker autoregressively predicts a multi-codebook sequence."
- Byte-level Byte-Pair Encoding (BPE): A subword tokenization method operating at the byte level to handle multilingual text efficiently. "which adopts byte-level byte-pair encoding with a vocabulary size of 250k"
- Causal ConvNet: A convolutional network constrained to use only past context, suitable for streaming generation. "Coupled with a causal ConvNet for waveform reconstruction"
- ChatML: A conversational data format organizing multi-turn, multimodal training examples. "structured in the ChatML format"
- Chunked-prefilling: Processing long inputs in chunks to reduce initial token latency for streaming. "we retain the chunked-prefilling mechanism"
- Code-switching: Unintended switching between languages within a conversation. "unintended language code-switching"
- Code2Wav: A neural codec decoder that converts discrete codec tokens into waveform audio. "the Code2Wav renderer incrementally synthesizes the corresponding waveform"
- Concurrency (serving): The ability to handle many simultaneous requests efficiently during inference. "the model's concurrency capability is key"
- Continual Pre-Training (CPT): Further pre-training on curated data to refine capabilities after initial pre-training. "conduct continual pre-training (CPT)"
- Conv2D: Two-dimensional convolutional layers used here for audio feature downsampling. "using 4 Conv2D blocks"
- Direct Preference Optimization (DPO): A preference-learning method to align model outputs with human choices without RL rollouts. "through Direct Preference Optimization (DPO)"
- First-packet latency: Time from input reception to the first emitted audio packet in streaming. "the first-packet latency is a critical factor"
- FunctionCall: A tool-use mechanism where the model invokes predefined functions to act. "complex FunctionCall"
- Gated Delta Net (GDN): A module that accelerates long-sequence modeling and reduces KV-cache overhead. "includes the Gated Delta Net (GDN) module"
- GSPO: A reinforcement-learning-style optimization method leveraging rule-based rewards for stability. "adopt GSPO"
- Hybrid Mixture-of-Experts (MoE): An MoE architecture variant balancing capacity and efficiency across modalities. "Hybrid Mixture-of-Experts (MoE) design"
- Interaction-Aligned Reinforcement Learning (RL): RL procedure optimizing for real-world multi-turn conversational quality. "Interaction-Aligned Reinforcement Learning"
- KV-cache: Cached key/value tensors that speed autoregressive decoding by reusing past attention states. "reduces KV-cache I/O overhead"
- MFA-derived alignments: Alignments obtained from Montreal Forced Aligner used to map text to audio timings. "MFA-derived alignments"
- Multi-codebook (codec representation): Using multiple residual codebooks to represent high-fidelity audio tokens. "a multi-codebook codec representation enables single-frame, immediate synthesis"
- Multi-token Prediction (MTP): Predicting multiple future tokens per step to accelerate and stabilize decoding. "employs a multi-token prediction (MTP) module"
- Omnimodal: Natively handling and generating across text, audio, image, and video within a unified model. "fully omnimodal LLM"
- On-policy distillation: Distilling a model’s own stronger behavior (e.g., from text prompts) into weaker settings (e.g., audio prompts). "based on on-policy distillation"
- Paralinguistic alignment: Matching non-verbal speech aspects (e.g., emotion, intonation) to context and intent. "paralinguistic alignment"
- Prosody: The rhythm, stress, and intonation patterns of speech. "enhancing the stability and prosody of conversational speech"
- Real-Time Factor (RTF): Ratio of generation time to audio duration; lower is faster-than-real-time. "the low Generation RTF provides sufficient margin"
- Residual Vector Quantization (RVQ): A quantization method using multiple residual codebooks for compact audio tokenization. "adopts the RVQ-based speech representation"
- S2TT (Speech-to-Text Translation): Translating spoken language directly into text in another language. "speech-to-text translation (S2TT)"
- SigLIP2: A vision encoder model used for image/video representation. "Vision Encoder & SigLIP2"
- Speaker embeddings: Vector representations characterizing a speaker’s voice identity. "Compared with conventional speaker embeddings"
- Specialist Distillation: Distilling capabilities from domain-specific teacher models into a unified model. "Stage 1: Specialist Distillation"
- Streaming decoding: Incrementally generating outputs in real time as inputs arrive. "during streaming decoding"
- Supervised Fine-Tuning (SFT): Training on labeled instruction data to specialize model behavior. "via independent Supervised Fine-Tuning (SFT)"
- Temporal position IDs: Positional indices that encode absolute or relative timing for audio/video tokens. "temporal position IDs"
- Thinker–Talker architecture: A two-component design where Thinker generates text and Talker generates speech. "Qwen3.5-Omni adopts the Thinker-Talker architecture."
- Time-To-First-Chunk (TTFC): Time until the first chunk of audio is produced by the speech decoder. "Talker TTFC (Time-To-First-Chunk)"
- Time-To-First-Token (TTFT): Time until the first text token is produced by the text decoder. "Thinker TTFT (Time-To-First-Token)"
- Time-Per-Output-Token (TPOP): Average latency to generate each output token during steady-state decoding. "TPOP (Time-Per-Output-Token)"
- TM-RoPE: A temporal extension of Rotary Positional Embeddings for synchronizing audio-video sequences. "we apply TM-RoPE to endow the model with temporal awareness"
- Tokens Per Second (TPS): Throughput metric indicating how many tokens are generated per second. "TPS (Tokens Per Second) denotes generation throughput."
- vLLM: A high-performance inference engine for serving LLMs. "evaluated on internal vLLM"
- Voice cloning (zero-shot): Generating speech in a target voice from minimal or no explicit speaker training. "enabling both zero-shot voice cloning"
- WebSearch: An autonomous tool the model invokes to retrieve external information. "autonomously invoking WebSearch"
Collections
Sign up for free to add this paper to one or more collections.