Qwen3-Omni Technical Report
Abstract: We present Qwen3-Omni, a single multimodal model that, for the first time, maintains state-of-the-art performance across text, image, audio, and video without any degradation relative to single-modal counterparts. Qwen3-Omni matches the performance of same-sized single-modal models within the Qwen series and excels particularly on audio tasks. Across 36 audio and audio-visual benchmarks, Qwen3-Omni achieves open-source SOTA on 32 benchmarks and overall SOTA on 22, outperforming strong closed-source models such as Gemini-2.5-Pro, Seed-ASR, and GPT-4o-Transcribe. Qwen3-Omni adopts a Thinker-Talker MoE architecture that unifies perception and generation across text, images, audio, and video, yielding fluent text and natural real-time speech. It supports text interaction in 119 languages, speech understanding in 19 languages, and speech generation in 10 languages. To reduce first-packet latency in streaming synthesis, Talker autoregressively predicts discrete speech codecs using a multi-codebook scheme. Leveraging the representational capacity of these codebooks, we replace computationally intensive block-wise diffusion with a lightweight causal ConvNet, enabling streaming from the first codec frame. In cold-start settings, Qwen3-Omni achieves a theoretical end-to-end first-packet latency of 234 ms. To further strengthen multimodal reasoning, we introduce a Thinking model that explicitly reasons over inputs from any modality. Since the research community currently lacks a general-purpose audio captioning model, we fine-tuned Qwen3-Omni-30B-A3B to obtain Qwen3-Omni-30B-A3B-Captioner, which produces detailed, low-hallucination captions for arbitrary audio inputs. Qwen3-Omni-30B-A3B, Qwen3-Omni-30B-A3B-Thinking, and Qwen3-Omni-30B-A3B-Captioner are publicly released under the Apache 2.0 license.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Qwen3-Omni Technical Report — Explained Simply
Overview
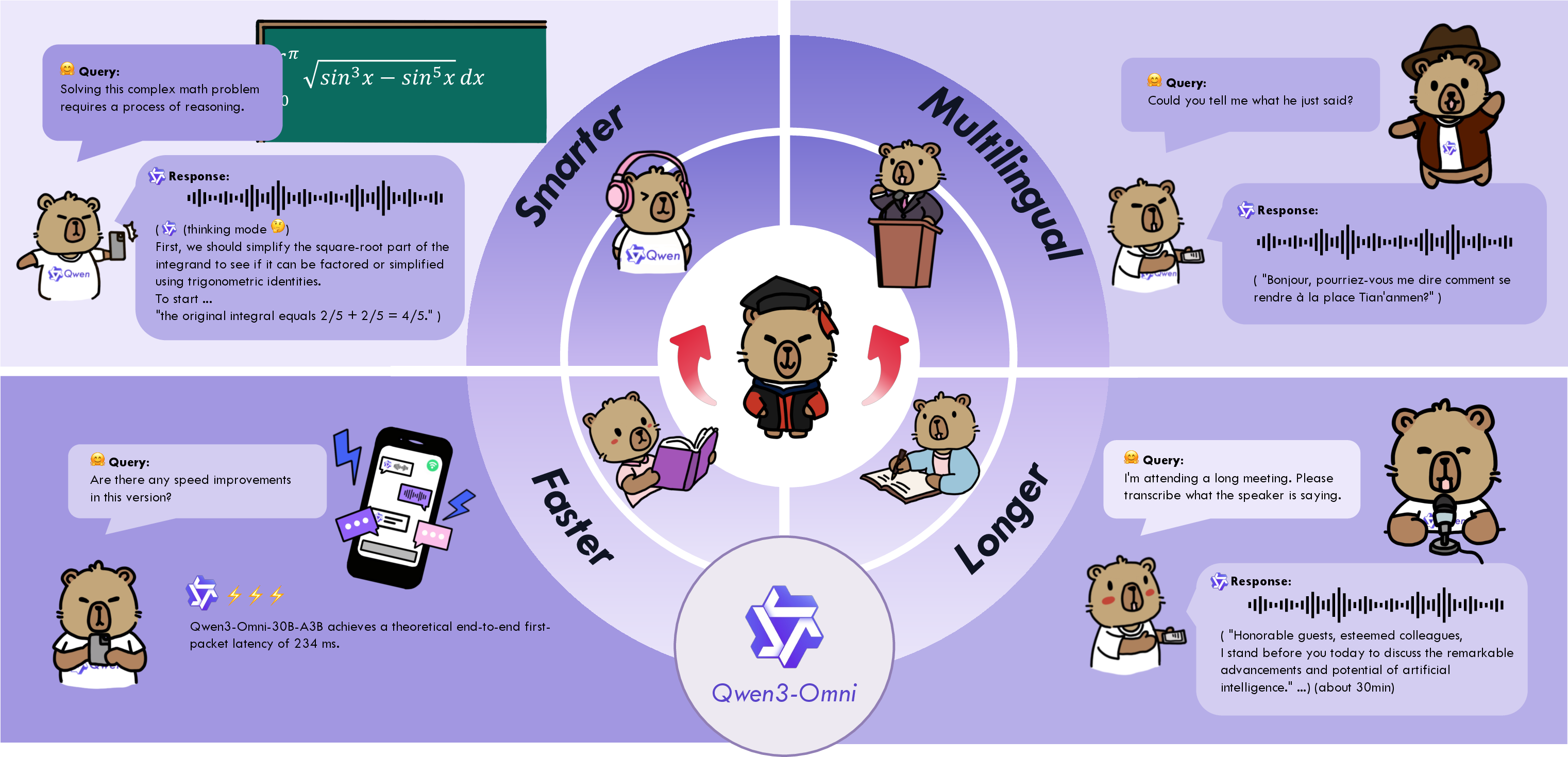
This paper introduces Qwen3-Omni, a single AI model that can understand and respond using text, images, audio, and video. The big idea is that one model can do all these things really well at the same time—without getting worse at any one of them. It also talks about how Qwen3-Omni can speak naturally in real time, understand long audio recordings, and support many languages.
Key Objectives
In simple terms, the researchers wanted to:
- Build one “all-in-one” model that’s great at text, images, audio, and video—without sacrificing quality in any area.
- Make the model good at cross-modal tasks (like understanding a video with sound and then explaining it).
- Make voice interactions feel fast and natural, like talking to a person.
- Support many languages for reading, listening, and speaking.
- Share strong open-source versions for the community to use and improve.
Methods and Approach
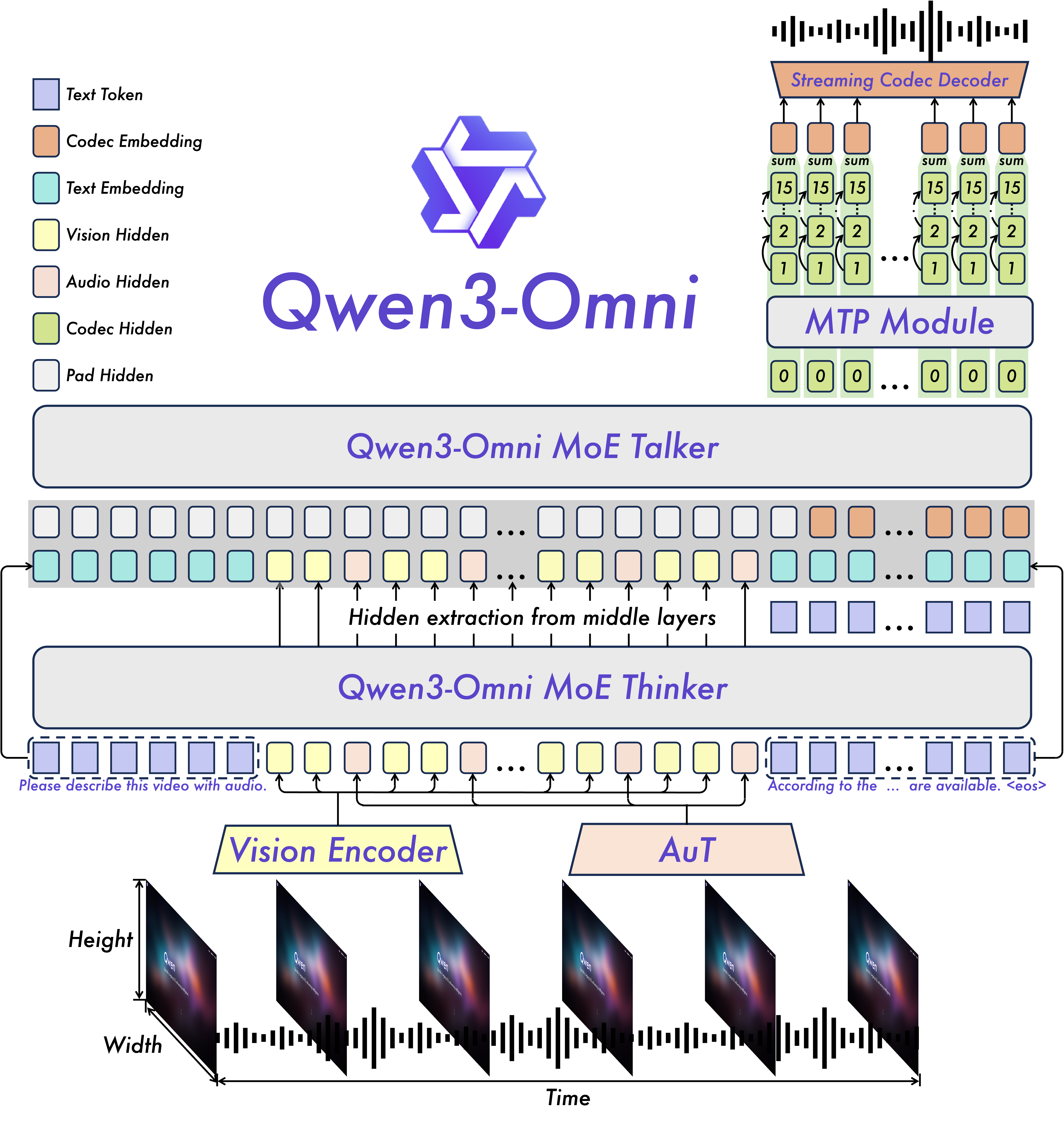
Think of Qwen3-Omni like a person with a brain and a mouth:
- The “Thinker” is the brain. It understands inputs (text, pictures, audio, video), reasons about them, and decides what to say.
- The “Talker” is the mouth. It turns the Thinker’s ideas into speech that sounds natural, expressive, and quick to start.
To make this work, they used several clever designs:
- Mixture-of-Experts (MoE): Imagine a team of specialists inside the model. Depending on the task, the model picks the right “experts” to think or speak efficiently. This helps speed and scalability.
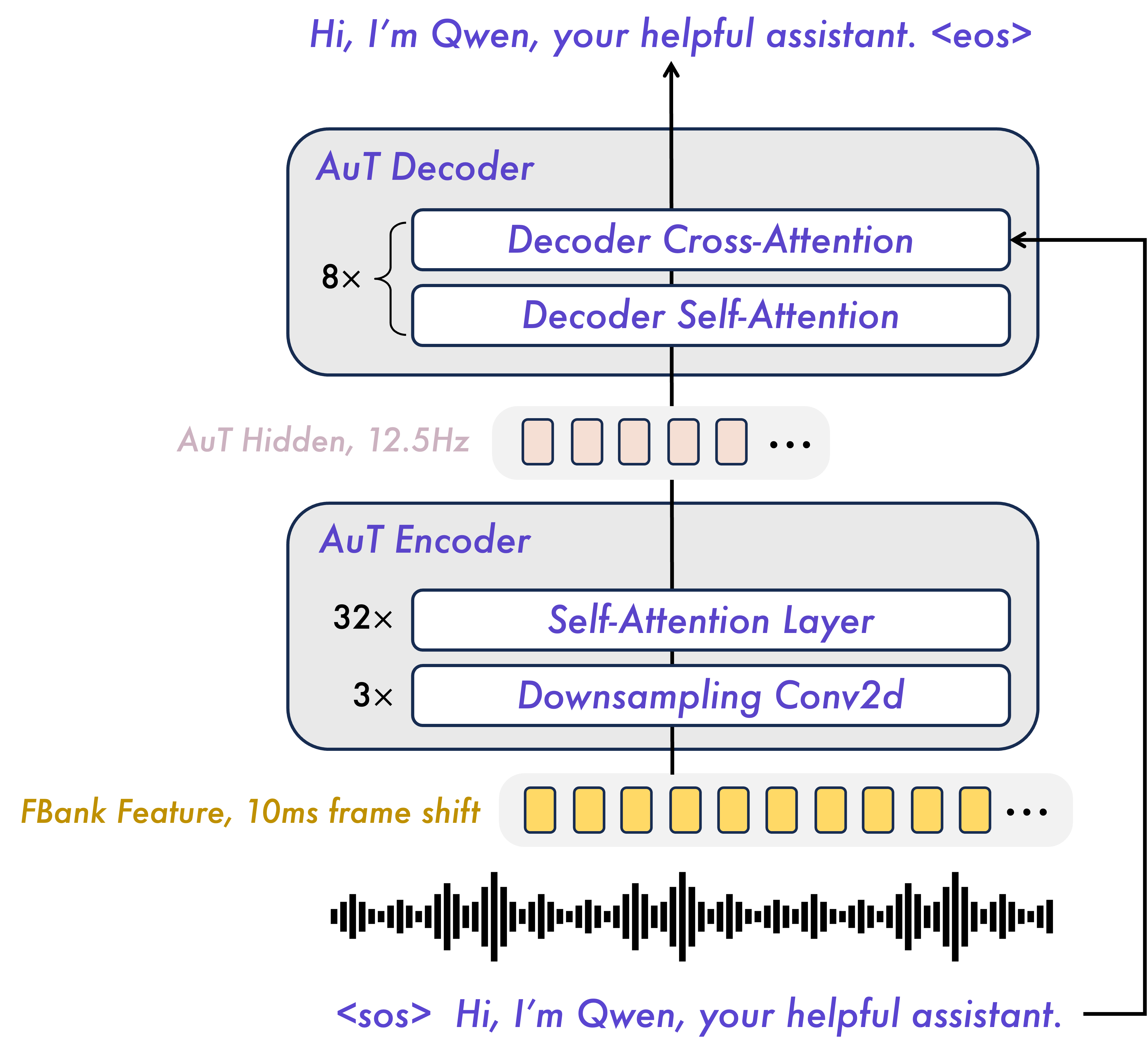
- AuT (Audio Transformer) encoder: This is a special “ear” for audio, trained on a huge amount of data (20 million hours). It turns sound into compact, meaningful signals the model can understand. It works at a timing rate of 12.5 steps per second—meaning it represents every ~80 milliseconds of sound with one token.
- Time-aligned position system (TM-RoPE): For videos with sound, the model uses timestamps so audio and video line up in time. Think of it like labeling each audio snippet and video frame with the exact moment they happened, so the model can match them correctly.
- Fast speech generation with “codebooks”: Instead of drawing every sound wave from scratch (which is slow), the Talker predicts small “codes,” like compressed instructions for speech. These codes are then quickly turned into a waveform using a lightweight ConvNet (a fast type of neural network). This allows the model to start speaking in about a quarter of a second (roughly 234 milliseconds) from a cold start.
- Streaming design and chunked processing: The Thinker and Talker work in parallel and process inputs in chunks (like reading and speaking paragraph by paragraph), which speeds up the first spoken word and keeps the conversation smooth even with many users at once.
- Training strategy:
- Stage 1: Align the “ears” (audio encoder) and “eyes” (vision encoder) with the LLM, without changing the LLM yet.
- Stage 2: Train the whole system together on huge mixed datasets (text, images, audio, video) so it learns to work across all modalities.
- Stage 3: Train it to handle long inputs (up to 32,768 tokens) so it can understand long videos or audio.
- Post-training (fine-tuning): The team used instruction tuning, distillation from stronger models, and reinforcement-style training with rewards to make the model follow instructions better and be more reliable. For speech, they used preference tuning to improve naturalness and multilingual quality, and they fine-tuned specific voices.
They also built a special “Captioner” version for audio-only descriptions, because there weren’t good general-purpose audio captioning models available. It produces detailed, accurate captions for sounds.
Main Findings and Why They Matter
Here are the highlights:
- Strong across all modalities: Qwen3-Omni matches the performance of specialized text-only and vision-only models of similar size, while being excellent at audio tasks.
- Audio and audio-visual leadership: On 36 audio and audio-visual benchmarks, it achieved state-of-the-art results on most of them (open-source SOTA on 32; overall SOTA on 22), beating powerful closed models like Gemini-2.5-Pro, Seed-ASR, and GPT-4o-Transcribe.
- Real-time speech with low delay: It can start speaking in around 234 milliseconds in cold-start situations, making voice chat feel responsive.
- Long audio understanding: It can process audio recordings up to 40 minutes, which is great for transcribing meetings, lectures, or podcasts.
- Language coverage: It supports text in 119 languages, understands speech in 19 languages, and can speak in 10 languages.
- Flexible personality and tone: The Thinker and Talker can be controlled separately, so you can set different styles for the text and the voice (for example, friendly words with a calm voice).
- Open-source releases: Multiple versions, including the Thinking model and the audio Captioner, are publicly released under Apache 2.0, which helps researchers and developers build on this work.
Implications and Impact
This research shows that one model can be excellent at text, images, audio, and video simultaneously, without trade-offs. That unlocks:
- Better assistants: Real-time voice and video understanding can make digital assistants more helpful, natural, and fast.
- Accessibility: High-quality transcription and translation across many languages can help people communicate and learn more easily.
- Rich media understanding: Tasks like analyzing a video with speech, describing music, or captioning audio-only content become more accurate and detailed.
- Lower latency and better scaling: The design supports many users at the same time with quick responses, making it practical for apps and services.
- Open progress: By sharing strong open-source models, the community can improve safety, reduce bias, and build new features more quickly.
In short, Qwen3-Omni points toward a future where AI can fluidly listen, watch, read, and speak—making interactions with technology feel more like interacting with a helpful, fast, multilingual human.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Data provenance and licensing: The paper does not disclose sources, licensing status, demographics, or domain composition of the 20M hours used for AuT and the ~2T-token multimodal corpus, impeding reproducibility, bias analysis, and compliance assessment.
- Bias and fairness: No systematic evaluation of fairness across accents, dialects, genders, ages, sociolects, recording conditions, or low-resource languages for either ASR or TTS; code-switching and multilingual robustness remain untested.
- Safety and misuse of voice generation: No discussion of anti-spoofing, watermarking, speaker-protection mechanisms, voice-cloning consent controls, or defenses against audio deepfakes and voice fraud.
- Privacy and security: Absent treatment of privacy-preserving training/inference for 40-minute audio inputs, PII handling, on-device vs. server processing, or compliance with regional privacy regulations.
- Adversarial robustness: No analysis of adversarial audio attacks (e.g., perturbations, ultrasonic triggers), prompt injection via audio/text, or defenses under worst-case input manipulations.
- Long-context reliability: While supporting 40-minute audio and 32k tokens, the paper lacks evaluations of failure modes, drift, memory/latency scaling, and robustness under long, noisy, multi-speaker streams.
- Multispeaker and diarization: No explicit evaluation on overlapping speech, speaker diarization, turn-taking, or speaker-change handling in real-world conversational audio.
- Noisy/far-field robustness: Missing tests on challenging ASR corpora (e.g., CHiME, AMI), reverberant/low-SNR environments, or device/channel mismatch for both understanding and TTS conditioning.
- Streaming lip-sync and AV alignment: The Talker conditions on multimodal features, but there is no quantitative lip-sync or AVSync evaluation, nor analysis of clock drift, frame-rate jitter, or asynchronous inputs.
- TTS quality and naturalness: No MOS/MUSHRA or intelligibility (CER via ASR-loop) measurements, language-wise cross-evaluations, or comparisons of prosody/expressiveness under streaming constraints.
- Streaming artifacts: No characterization of artifacts introduced by 12.5 Hz code rate, immediate single-frame synthesis, or frame-level latency trade-offs on prosody continuity and perceived smoothness.
- Multi-codebook codec design: Lacks ablations isolating gains from multi-codebook vs. single-codebook, MTP depth vs. quality/latency, and Code2Wav ConvNet vs. DiT vocoders on fidelity and latency.
- TM-RoPE choices: No ablation on temporal/height/width angle allocation, long-range extrapolation properties, or comparisons with alternative positional schemes for audio-video fusion.
- Thinker–Talker decoupling: Claims that text embeddings are information-equivalent to tokens are untested; potential misalignment between textual content and acoustic rendering (pronunciation, emphasis, disfluencies) is not analyzed.
- Tool/RAG integration in streaming: Decoupling enables external interventions, but the paper does not evaluate end-to-end latency spikes, error propagation, or consistency when tool outputs arrive mid-utterance.
- Concurrency and latency in real deployments: Reported first-packet latency is “theoretical” under vLLM; no end-to-end user-perceived latency under real network jitter, device heterogeneity, or mixed workloads.
- Throughput/cost and energy footprint: No reporting of compute budgets, hardware utilization, energy/carbon costs for training/inference, or cost-per-minute estimates under high concurrency.
- MoE routing stability: No details on expert load balancing, routing collapse avoidance, token dropping, or performance under distribution shift; no ablation versus dense counterparts.
- Memory footprint and KV cache scalability: Lacks quantified KV cache memory usage and its scaling with long audio/video and high concurrency; no guidance on memory-optimized deployment.
- Safety alignment across modalities: GSPO is described, but there is no modality-specific safety evaluation for audio/video outputs (toxicity, harassment, sensitive content) or multilingual safety consistency.
- Benchmark contamination: No measures to detect or mitigate training–test leakage across text, audio, image, and video benchmarks given the massive pretraining mixture.
- Comparative evaluation controls: SOTA claims lack controls for decoding strategies, test-time compute, context length, and prompt formatting; no significance testing or variance across seeds.
- Audio captioner validation: The audio captioner lacks standardized quantitative evaluation (e.g., CIDEr/SPIDEr, SPICE) on public audio-caption benchmarks; training data composition and quality control are unspecified.
- Music understanding scope: Strong results reported, but no robustness checks across genres beyond benchmark sets, nor evaluations on segmentation, polyphonic mixtures, or rare/non-Western instruments.
- Cross-modal reasoning depth: Audiovisual “thinking” is assessed on a few benchmarks; higher-order tasks (temporal commonsense, causal inference, multi-hop across modalities, counterfactual AV reasoning) remain underexplored.
- Long video understanding: No stress tests on truly long, multi-hour videos, memory-accuracy trade-offs, or streaming video comprehension with dropped/irregular frames.
- Multilingual TTS coverage: Only 10 output languages supported; no assessment of low-resource speech synthesis, code-switch TTS, or cross-lingual prosody transfer.
- Safety for singing/lyric generation: Lyric ASR is evaluated, but TTS for singing, lyric generation, copyright handling, and melody–prosody alignment are not discussed.
- Voice style control and ethics: Speaker fine-tuning is supported, but there are no guardrails or audits for impersonation risk, and no transparency mechanisms for voice provenance.
- Reproducibility: While some models are released under Apache 2.0, training recipes, exact data mixtures, AuT pretraining specifics, and the multi-codebook tokenizer availability are unclear, limiting replicability.
- Hardware and quantization: No analysis of quantization, mixed precision, or on-device acceleration trade-offs for AuT/Thinker/Talker/MTP/Code2Wav under mobile or edge constraints.
- Error analysis: No qualitative/quantitative breakdown of typical failure modes in ASR, S2TT, AV reasoning, or TTS (e.g., hallucinations, mis-segmentation, homophone errors, AV mismatch).
- Evaluation of dialog behaviors: No tests on turn-taking, interruption handling, barge-in responsiveness, or full-duplex echo cancellation for real-time voice assistants.
- Continual learning/catastrophic forgetting: Unclear how the system behaves under domain updates (new languages, accents, acoustic conditions) without degrading previously learned modalities.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging Qwen3-Omni’s unified multimodal capabilities (text, image, audio, video), low-latency streaming speech (theoretical first packet ≈234 ms), long-context audio processing (up to 40 minutes), multilingual coverage (119 text, 19 speech input, 10 speech output languages), and open-source releases under Apache 2.0 (Qwen3-Omni-30B-A3B, -Thinking, -Captioner).
- Real-time multilingual voice assistants for customer support and operations (sectors: software, telecom, finance, retail, travel)
- Use cases: natural voice bots for hotlines, sales, tier-1 support triage, appointment booking, IVR replacement.
- Tools/products/workflows: “Omni Voice Agent” stack—audio capture → AuT encoder → Thinker (tool use/RAG/safety) → Talker (codec streaming) → Code2Wav; persona control via system prompts; function calling for CRM/ERP actions; guardrails injected between Thinker and Talker.
- Assumptions/dependencies: GPU inference capacity (MoE + KV-cache), vLLM or equivalent serving, privacy/compliance (PII, call recording consent), supported languages (19 input/10 output).
- Meeting, lecture, and interview transcription with action-item summarization (sectors: enterprise software, productivity, HR, media)
- Use cases: accurate ASR for long recordings, structured summaries, decision logs, task extraction.
- Tools/products/workflows: “Omni Meeting Scribe”—ingest up to 40 minutes audio/video; diarization and summarization; export to project trackers via function calls.
- Assumptions/dependencies: audio quality, speaker separation/diarization pipeline, organizational data access and consent, security (HIPAA/GDPR if applicable).
- Live captioning and low-latency dubbing for broadcasts and events (sectors: media, education, accessibility)
- Use cases: multilingual subtitles for livestreams, classroom lectures, corporate webinars; real-time dubbing into 10 output languages.
- Tools/products/workflows: “Omni Live Captioner/Dubber”—AV ingestion → ASR/S2TT → Talker streaming synthesis; dynamic voice style via Talker prompt; batching for high concurrency.
- Assumptions/dependencies: network jitter/latency budgets, A/V sync, speaker voice rights for dubbing, captioning accuracy thresholds.
- Content moderation, brand safety, and compliance on A/V streams (sectors: social platforms, advertising, enterprise compliance)
- Use cases: automated detection of policy violations in spoken/video content; age-appropriateness checks; ad placement suitability.
- Tools/products/workflows: “Omni A/V Safety Filter”—Thinker applies rule/model-based checks on multimodal inputs; moderation decisions logged; Talker gated for speech output.
- Assumptions/dependencies: policy definition and localization, false-positive/negative management, auditability requirements.
- Video understanding and dynamic scene QA for operations (sectors: logistics, manufacturing, security)
- Use cases: video question answering on procedures, incident analysis, tool usage verification; long video comprehension for inspections.
- Tools/products/workflows: “Omni Video Analyst”—frame sampling aligned at 80 ms via TM-RoPE; integrate with VMS/IoT dashboards for queries and reports.
- Assumptions/dependencies: camera placement and quality, privacy constraints (workplace monitoring), domain-specific fine-tuning for edge cases.
- Music tagging and recommendation (sectors: streaming media, rights management, advertising)
- Use cases: genre/instrument/mood labeling; playlist curation; discovery; rights monitoring (lyric ASR).
- Tools/products/workflows: “Omni Music Tagger”—batch tag catalogs (MTG-Jamendo/MagnaTagATune-style labels); “Lyric Transcriber” for karaoke/lyrics search; feed tags into recommenders.
- Assumptions/dependencies: domain drift across catalogs, licensing and fair use, thresholding for micro-F1 vs production rankings.
- Audio captioning for dataset creation and retrieval (sectors: academia, media archives, surveillance with ethics review)
- Use cases: low-hallucination audio descriptions for large corpora; searchable audio archives; benchmarking new tasks.
- Tools/products/workflows: Qwen3-Omni-30B-A3B-Captioner API for batch labeling; human-in-the-loop verification; index captions for retrieval.
- Assumptions/dependencies: annotation quality oversight, ethical review for surveillance use, domain adaptation for non-speech audio.
- Multimodal RAG copilots for enterprise knowledge (sectors: legal, consulting, engineering)
- Use cases: ask questions about documents, charts, videos; retrieve relevant materials; generate tailored briefings.
- Tools/products/workflows: “Omni Multimodal Copilot”—Thinker decoupling enables external RAG and function calling insertion; chart/document QA; video evidence extraction.
- Assumptions/dependencies: data connectors, permissioning and governance, calibration of “LLM-as-a-judge” rewards not needed in deployment but evaluation practices should be clear.
- Accessibility tools for deaf/hard-of-hearing and visually impaired users (sectors: public services, education, consumer apps)
- Use cases: real-time speech-to-text captions; audio descriptions of environments and videos; multilingual support.
- Tools/products/workflows: mobile or kiosk apps using AuT encoder and Captioner; Talker for natural speech outputs when needed.
- Assumptions/dependencies: device compute vs cloud latency, cultural/linguistic localization, consent for recording in public spaces.
- Call analytics and QA (sectors: finance, insurance, healthcare)
- Use cases: automated summarization; compliance phrase detection; sentiment, intent, risk markers; multilingual support.
- Tools/products/workflows: “Omni Call Auditor”—tag risk mentions; escalate via function calls; archive with transcripts.
- Assumptions/dependencies: sector regulations (HIPAA/FINRA/GDPR), false positives on compliance markers, secure storage.
- Robotics and IoT voice interfaces (sectors: robotics, smart home, automotive)
- Use cases: conversational control; situational QA from camera/audio feeds; quick voice responses with low latency.
- Tools/products/workflows: “Omni Edge Voice”—cloud inference with local capture; Thinker-Talker prompts for safety; function calling to device APIs.
- Assumptions/dependencies: connectivity budgets, edge vs cloud compute trade-offs, safety interlocks for physical actuation.
- Language learning and tutoring (sectors: education, consumer apps)
- Use cases: conversation practice in 10 output languages; pronunciation feedback; audiovisual explanations of content.
- Tools/products/workflows: “Omni Tutor”—voice chat; visual aids; custom persona; persistent progress tracking via function calls.
- Assumptions/dependencies: supported language coverage for speech output, accuracy in grammar/culture nuances, age-appropriate content filters.
- Public-sector transcription and summarization for hearings and broadcasts (sectors: government, public media)
- Use cases: real-time captions of council meetings; multilingual summaries of public announcements.
- Tools/products/workflows: “Omni Civic Transcriber”—ASR + topic summarization + publishing pipeline.
- Assumptions/dependencies: procurement standards, data retention policies, accessibility compliance.
Long-Term Applications
These opportunities benefit from targeted research, scaling, or productization (e.g., expanded language support, on-device deployment, domain specialization, safety tooling).
- Fully embodied multimodal agents for operations and assistance (sectors: robotics, industrial automation, healthcare)
- Vision–audio–text reasoning for real-time decision support and verbal interaction during tasks (e.g., operating machinery, bedside assistance).
- Dependencies: reliable perception in noisy/complex scenes, robust cross-modal reasoning under distribution shifts, strong safety layers for physical actuation.
- On-device or edge deployment of unified multimodal models (sectors: mobile, automotive, wearables)
- Use cases: privacy-preserving voice assistants, in-car copilots, smart glasses with audiovisual understanding.
- Dependencies: model compression/distillation and efficient MoE routing on constrained hardware, hardware accelerators for ConvNet/attention, optimized KV-cache management.
- High-fidelity speech translation preserving timbre/prosody across many languages (sectors: media localization, conferencing, education)
- Use cases: instant “voice dubs” with speaker identity and emotion intact; cross-lingual meetings without loss of expressivity.
- Dependencies: expanded speech output language coverage beyond 10, licensing/consent for voice cloning, improved prosody transfer under varied acoustics.
- Continuous ambient AI for homes and workplaces (sectors: consumer, enterprise)
- Use cases: proactive assistance that listens, understands, and speaks in natural contexts (safety alerts, reminders, meeting prep).
- Dependencies: privacy-by-design (opt-in, local processing), long-duration streaming beyond 32k tokens, robust event detection and false alarm mitigation.
- Multimodal safety, attribution, and provenance tools (sectors: platforms, regulators, policy)
- Use cases: standardized A/V content labeling, misinformation detection across audio/video, provenance tracking of synthetic speech.
- Dependencies: policy frameworks for detection thresholds and disclosures, watermarking for speech synthesis, interoperable audit logs.
- Clinical voice scribe and cross-lingual telemedicine (sectors: healthcare)
- Use cases: real-time transcription, coding suggestions, summaries, multilingual consultations.
- Dependencies: medical-domain fine-tuning, high accuracy requirements, HIPAA-grade security, bias audits on multilingual performance.
- Urban sound analytics and public safety monitoring (sectors: smart cities, transportation)
- Use cases: audio captioning at scale for event detection (alarms, accidents, crowd dynamics), noise mapping.
- Dependencies: large-scale streaming infrastructure, community consent and oversight, domain adaptation for city-specific sounds.
- Advanced educational media co-creation (sectors: EdTech, publishing)
- Use cases: multimodal lesson builders that analyze videos and produce interactive voice explanations, exercises, and localized content.
- Dependencies: curriculum alignment, pedagogical evaluation, content licensing, scaling for diverse subjects and languages.
- Research infrastructure for audio-centric LMMs (sectors: academia)
- Use cases: bootstrapping new audio datasets with Captioner; benchmarking audio reasoning and music understanding; exploring TM-RoPE temporal alignment.
- Dependencies: human verification pipelines for labels, shared benchmarks with ground-truth, reproducible training recipes.
- Enterprise-grade multimodal copilots with domain-compliant tooling (sectors: legal, finance, manufacturing)
- Use cases: end-to-end workflows spanning document, chart, video, and voice; enforceable guardrails and audit policies.
- Dependencies: integrated governance (role-based access, logging), tool ecosystems for function calling and RAG, sector-specific fine-tuning.
- Scalable multilingual emergency services translation and coordination (sectors: public safety)
- Use cases: real-time translation in the field, dispatch assistance, situation summaries from bodycams/audios.
- Dependencies: ruggedized deployments, failover strategies, consistent accuracy under stress/noise, policy and training for operators.
- Personalized voice brands and synthetic presenters (sectors: marketing, broadcasting)
- Use cases: brand-aligned voices for ads, events, and interactive kiosks; localized synthetic presenters.
- Dependencies: ethical and legal frameworks for voice cloning, speaker consent and rights management, high-fidelity prosody modeling.
Notes on cross-cutting assumptions and dependencies:
- Serving: MoE routing, KV-cache management, batching for concurrency (vLLM or similar), CUDA Graph/torch.compile optimizations materially affect latency and throughput.
- Safety: Thinker–Talker decoupling enables insertion of RAG, function calls, and safety filters; robust prompt governance and post-generation checks are essential.
- Coverage: 19 input and 10 output speech languages may require extension for specific markets; text coverage at 119 languages is broader.
- Data quality and bias: AuT trained on 20M hours (incl. pseudo-labeled ASR) may carry distributional biases; domain audits recommended.
- Licensing: Apache 2.0 applies to released variants (30B-A3B, -Thinking, -Captioner); confirm license terms for other sizes or “Flash” models before commercial use.
Glossary
- Absolute temporal encodings: Explicit time-stamp embeddings that anchor tokens to real time to aid temporal alignment across modalities. Example: "audio inputs utilize shared position IDs but are further augmented with absolute temporal encodings, where each temporal ID corresponds to a duration of 80 ms."
- Adapter: A lightweight module that bridges encoders and the LLM, often trained first to align modalities before full finetuning. Example: "with both initially focusing on training their respective adapters before training the encoders."
- ASR (Automatic Speech Recognition): The task of transcribing spoken audio into text. Example: "for ASR and spoken-language understanding"
- Audio Transformer (AuT): An attention-based encoder-decoder architecture specialized for audio representation learning. Example: "we replace Whisper audio encoder with our AuT (Audio Transformer) encoder, trained from scratch on 20 million hours of supervised audio"
- Autoregressive: A generation process that predicts the next token conditioned on previously generated tokens. Example: "the Talker autoregressively predicts discrete speech codecs using a multi-codebook scheme."
- Batched inference: Running multiple inputs through a model simultaneously for higher throughput. Example: "support batched inference"
- BLEU: A metric for evaluating text generation quality, especially in translation. Example: "S2TT (BLEU)"
- Block-wise diffusion: A diffusion-based generation process operating on blocks that can be computationally heavy. Example: "we replace computationally intensive block-wise diffusion with a lightweight causal ConvNet"
- Byte-pair encoding (BPE): A subword tokenization algorithm that merges frequent byte pairs to form a vocabulary. Example: "which applies byte-level byte-pair encoding with a vocabulary of 151,643 regular tokens."
- Causal ConvNet: A convolutional neural network constrained to use only past context, suitable for streaming generation. Example: "a lightweight causal ConvNet, enabling streaming from the first codec frame."
- ChatML: A message formatting schema for multi-turn conversational training data. Example: "The dataset, designed in the ChatML format, includes pure text-based dialogue data, visual modality conversation data, audio modality conversation data, and mixed-modality conversation data."
- Chunked-prefilling: A streaming technique where encoders and decoders prefill and process data in temporal chunks to reduce latency. Example: "we retain the chunked-prefilling mechanism as implemented in Qwen2.5-Omni"
- Code2Wav: The waveform rendering module that converts codec tokens into audio. Example: "after which the Code2Wav renderer incrementally synthesizes the corresponding waveform"
- Codebook (multi-codebook): Discrete quantization tables used to represent audio tokens; multi-codebook increases representational capacity. Example: "we adopt a multi-codebook representation"
- Codec: A discrete representation (and corresponding decoder) for compressing and reconstructing audio waveforms. Example: "the Talker autoregressively predicts discrete speech codecs"
- CUDA Graph: A GPU execution optimization that captures and replays computation graphs for lower overhead. Example: "with optimizations applied via torch.compile and CUDA Graph acceleration to the MTP Module and codec decoder."
- DiT (Diffusion Transformer): A diffusion-model architecture based on transformers, often used as a vocoder or generator. Example: "achieving superior audio fidelity compared to more complex DiT-based vocoders."
- Direct Preference Optimization (DPO): A training method that aligns model outputs with human or preference data without reinforcement learning. Example: "optimize the model using Direct Preference Optimization (DPO)"
- Flash attention: A memory- and speed-optimized attention implementation for long sequences. Example: "AuT utilizes flash attention with dynamic attention window sizes"
- First-packet latency: The time from request to the emission of the first output packet in streaming. Example: "To reduce first-packet latency in streaming synthesis"
- GSPO: A post-training optimization method to improve capability and stability using rewards. Example: "we leverage GSPO to comprehensively enhance the model's capabilities and stability"
- KL divergence: A measure of difference between probability distributions used for aligning student and teacher outputs. Example: "by minimizing the KL divergence."
- KV cache: Cached key-value tensors for transformer attention to accelerate autoregressive decoding. Example: "decreases IO consumption arising from KV cache during processing of long sequences"
- LLM-as-a-judge: An evaluation protocol where a LLM scores outputs as an automated judge. Example: "we adopt an LLM-as-a-judge protocol."
- Mel-spectrogram: A time-frequency representation of audio using Mel-scaled filter banks. Example: "convert the raw waveform into a 128 channel mel-spectrogram with a 25 ms window and a 10 ms hop."
- Mixture-of-Experts (MoE): A model architecture that routes tokens to specialized expert subnetworks to boost capacity and efficiency. Example: "Qwen3-Omni adopts a ThinkerâTalker Mixture-of-Experts (MoE) architecture"
- Multi-token prediction (MTP): A module that predicts multiple tokens (e.g., residual codebooks) at once per step. Example: "a multi-token prediction (MTP) module generates all residual codebooks."
- Multimodal Rotary Position Embedding (M-RoPE): A RoPE variant for vision-language alignment extended across spatial dimensions. Example: "which extends the Multimodal Rotary Position Embedding (M-RoPE) by incorporating absolute temporal information."
- Prefill caching: Caching encoder or attention states during prefill to accelerate subsequent decoding. Example: "AuT employs block-wise window attention to enable real-time prefill caching"
- Real Time Factor (RTF): The ratio of processing time to audio duration; below 1 indicates faster-than-real-time synthesis. Example: "Generation RTF(Real Time Factor)"
- Residual Vector Quantization (RVQ) tokens: Discrete tokens obtained via layered quantization to represent audio features compactly. Example: "operating directly on RVQ tokens."
- Retrieval-Augmented Generation (RAG): Incorporating retrieved external knowledge into generation. Example: "external modules (e.g., RAG, function calling, safety filters)"
- Rotary Position Embedding (RoPE): A positional encoding technique that applies rotations in attention for better extrapolation. Example: "rendering TM-RoPE functionally equivalent to a one-dimensional RoPE"
- S2TT (Speech-to-Text Translation): Translating speech in one language into text in another language. Example: "S2TT (BLEU)"
- Streaming synthesis: Generating audio or speech incrementally and emitting it as it is produced. Example: "To reduce first-packet latency in streaming synthesis"
- Strong-to-Weak Distillation: Training a smaller (weak) model by matching outputs/logits from a stronger teacher model. Example: "The second stage adopts the Strong-to-Weak Distillation pipeline"
- Supervised Fine-Tuning (SFT): Finetuning a pretrained model on labeled instruction data to improve alignment. Example: "we introduce a lightweight Supervised Fine-Tuning (SFT)"
- Thinker–Talker architecture: A two-part design where a Thinker handles language reasoning and a Talker handles speech generation. Example: "Qwen3-Omni adopts the Thinker-Talker architecture."
- Time-To-First-Token (TTFT): The latency until the first generated token is produced. Example: "This approach significantly reduces the Time-To-First-Token (TTFT) for both the Thinker and the Talker."
- Time-to-First-Token (TTPT): A reported latency metric per module (used in the paper’s table) for when the first token appears. Example: "Thinker Time-to-First-Token (TTPT)"
- TM-RoPE (Time-aligned Multimodal Rotary Position Embedding): A RoPE variant that factorizes temporal, height, and width components and aligns modalities in time. Example: "Drawing inspiration from Qwen2.5-Omni, we employs a Time-aligned Multimodal Rotary Position Embedding (TM-RoPE)"
- Tokens per second (TPS): Throughput metric for token generation speed. Example: "thereby increasing tokens per second (TPS) during generation"
- vLLM: A high-throughput inference framework for serving LLMs efficiently. Example: "Experiments are conducted on the vLLM framework"
- Vocoder: A model that converts discrete or latent representations into waveforms. Example: "compared to more complex DiT-based vocoders."
- Window attention: Attention constrained to a temporal window to reduce cost and enable streaming. Example: "AuT employs block-wise window attention"
- Word Error Rate (WER): An ASR metric measuring the rate of insertions, deletions, and substitutions. Example: "ASR (wer)"
Collections
Sign up for free to add this paper to one or more collections.

