- The paper introduces a tri-agent deep research system that leverages modular specialization to achieve competitive performance with moderate 30B LLMs.
- It employs a four-stage curriculum with reinforcement learning strategies to optimize multi-step reasoning, evidence synthesis, and report generation.
- The system demonstrates robust empirical results across benchmarks, significantly reducing resource consumption compared to larger, proprietary models.
MindDR: Efficient Multi-Agent Deep Research with Targeted Training and Evaluation
Introduction and Motivation
Mind DeepResearch (MindDR) addresses resource-efficient, high-performance agentic deep research—solving open-domain, multi-step retrieval, evidence synthesis, and report generation via a multi-agent framework with ∼30B-parameter LLMs (2604.14518). The paradigm shift from retrieval-augmented generation to autonomous multi-agent research agents has resulted in proprietary systems requiring 100B+ LLMs and expensive continual pre-training, creating cost and accessibility bottlenecks. MindDR aims to achieve competitive results with moderate-sized models, emphasizing inference efficiency, modular multi-agent division, and rigorous curriculum training.
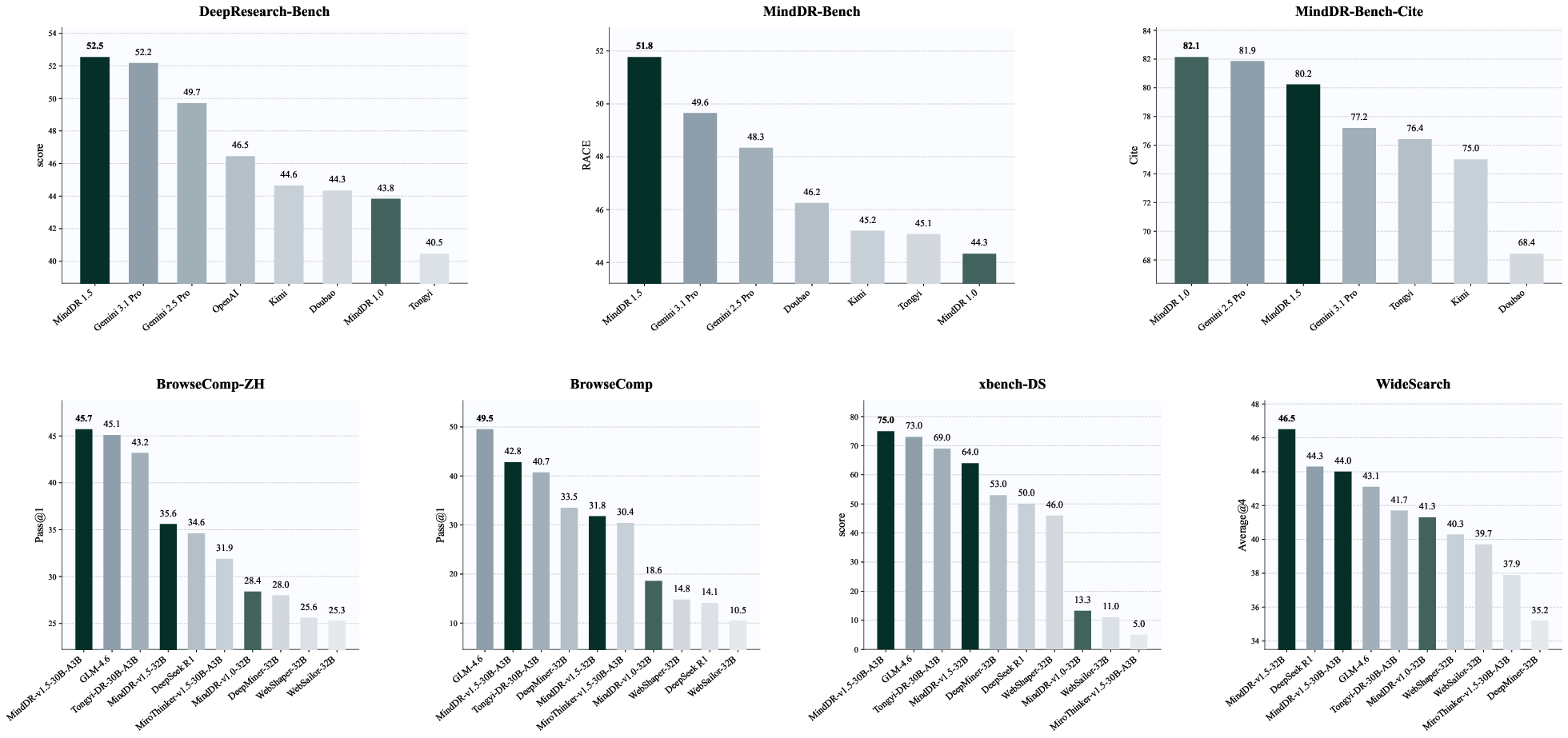
Figure 1: MindDR performance relative to mainstream deep research models at similar scale, achieving leading results across benchmarks.
System Architecture
MindDR employs a tri-agent inference pipeline: Planning Agent (intent analysis, task decomposition), DeepSearch Agents (parallel ReAct-style retrieval with Extended Chain-of-Thought memory), and a Report Agent (aggregation, conflict resolution, structured synthesis).
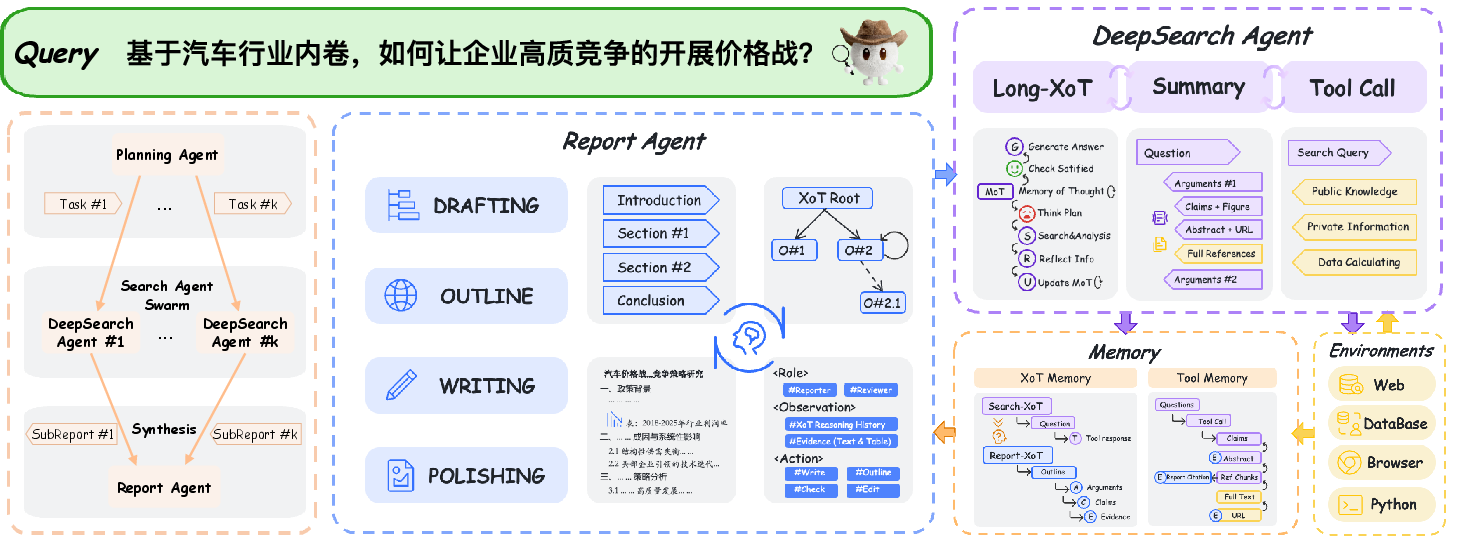
Figure 2: Schematic of the MindDR multi-agent pipeline, illustrating structured decomposition, parallel search, and unified reporting.
Critical innovations include agent specialization, XoT cross-agent memory, context isolation for efficient long-horizon reasoning, and explicit provenance tracking for citation-grounded synthesis.
Data and Evaluation Frameworks
The data strategy comprises a knowledge-graph-driven pipeline (graph construction, multi-hop QA generation, obfuscation, validity filtering) and blending with distribution-calibrated real-world queries mined from user interaction logs. Rigorous, modular multi-dimensional evaluation is conducted using both DeepResearch Bench (RACE rubric) and the newly proposed MindDR Bench, which systematizes error detection at multiple process stages (trajectory, tool call, outline, and report).
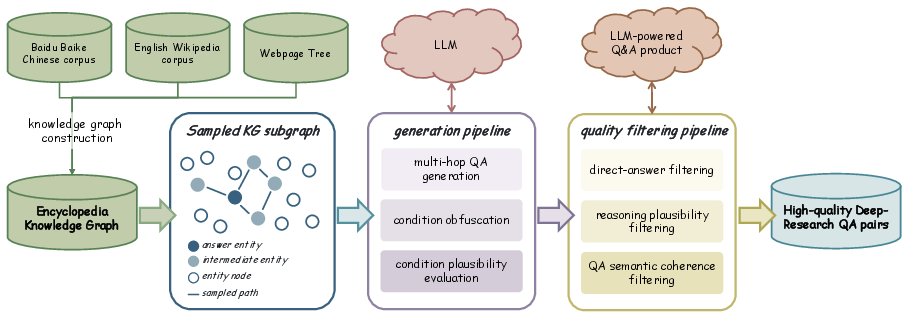
Figure 3: The knowledge-graph-grounded data synthesis process for generating high-quality multi-hop reasoning tasks.
Multi-Stage Agent Training Pipeline
MindDR's pipeline is a four-stage agent-specialized curriculum:
- SFT: Behavioral initialization using ReAct-structured, mixed-complexity expert trajectories with progressive context augmentation up to 128K tokens.
- Search-RL: Online RL on DeepSearch agents optimizing tool invocation, stepwise reasoning, and output accuracy via GRPO/GSPO. A dynamic reward schedule transitions emphasis from tool correctness→intermediate reasoning→end answer, with dynamic difficulty regulation to concentrate RL signal, achieving explicit step-level credit assignment (no critic).
- Report-RL: Report agent is refined with RACE rubric-targeted reinforcement using group policy optimization (GSPO, DAPO) and auxiliary rewards (citation, output format). Mixed long-form and short-form report training improves both fidelity and supervisor density.
- Preference Alignment: Output is calibrated via DPO and Self-SFT on self-sampled and LLM-scored trajectories, correcting residual errors undetectable by dense reward (table formatting, temporal alignment, stylistic consistency).
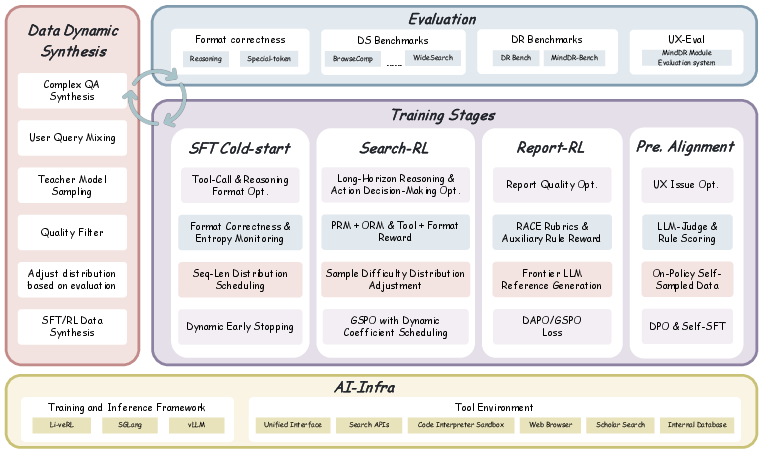
Figure 4: Overview of MindDR's four-stage modular training pipeline, linking specialized agent optimization to staged curriculum.
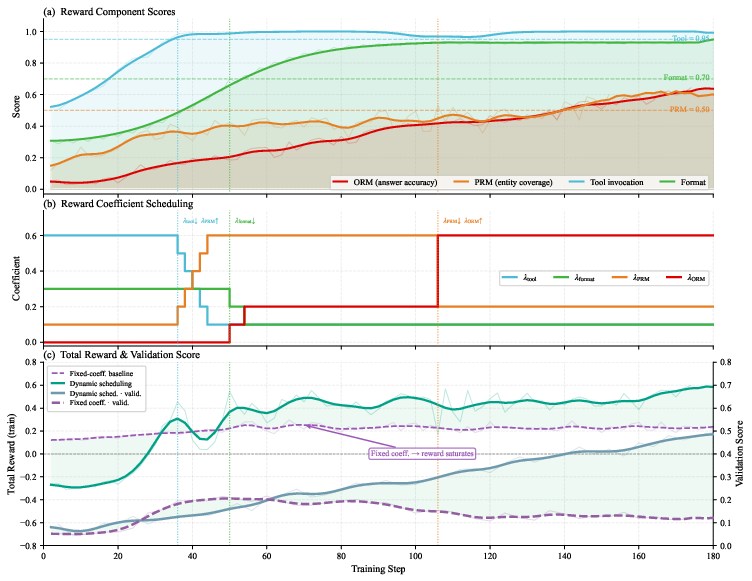
Figure 5: Dynamics of Search-RL—reward scheduling, coefficient transitions, and corresponding performance trajectories in RL.
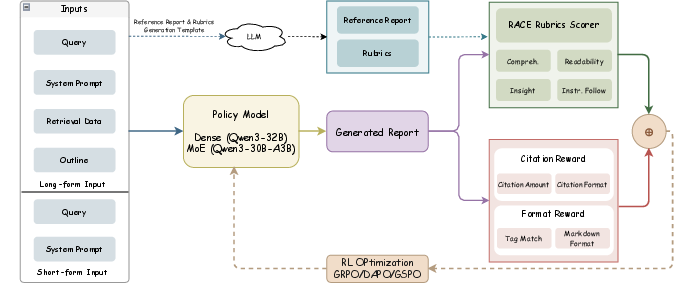
Figure 6: Report-RL framework: report generation, LLM-based rubric evaluation, and downstream performance surpassing distilled frontier LLMs.
Empirical Results
MindDR-v1.5-30B-A3B achieves 45.7% on BrowseComp-ZH, 42.8% on BrowseComp, 75.0% on xbench-DS, 70.9% on GAIA-DS, and 44.0% on WideSearch, consistently outperforming all comparable-scale open-source agentic systems and rivaling closed-source larger models.
On MindDR Bench (500 real-world queries, multidimensional rubric), MindDR-v1.5 attains a RACE score of 51.8, leading in comprehensiveness, insight, instruction-following, and readability.
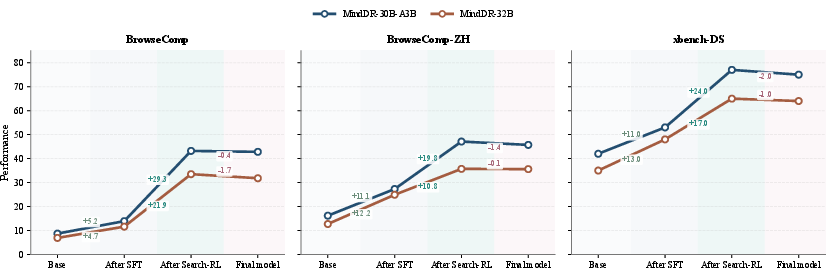
Figure 7: DS benchmark performance evolution across training phases—Search-RL delivers major gains, preference alignment introduces minor regressions.
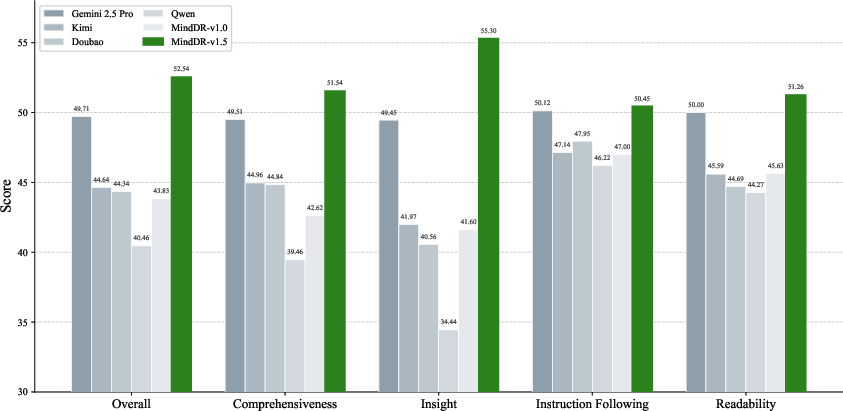
Figure 8: MindDR-v1.5 leads all evaluation dimensions on the public DeepResearch-Benchmark leaderboard.
Efficiency analysis shows MindDR-v1.5-30B-A3B occupies the top left (Pareto frontier) in accuracy/tool-calls and accuracy/context-token space. Under context (16k–128k) and tool-call (8–64) constraints, MindDR sustains leading performance, confirming both resource-effectiveness and robustness.
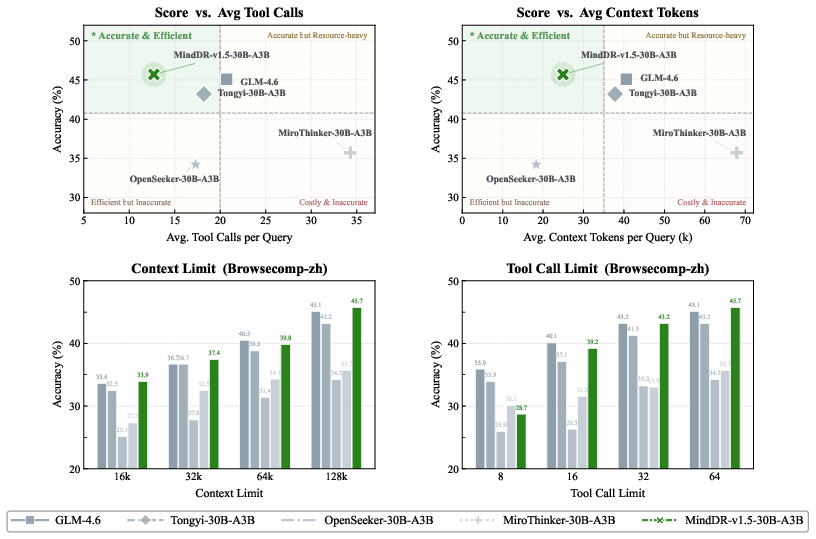
Figure 9: MindDR-v1.5-30B-A3B achieves maximal accuracy with minimal tool/context consumption among 30B-scale agents across budget settings.
Ablation studies show:
- GSPO and DAPO yield balanced gains in report quality and DS retention, compared to sequence-level GRPO which sacrifices search strengths.
- Mixed long-form/short-form data further improves RACE and insight scores.
- Preference alignment—DPO plus Self-SFT—reduces table and temporal errors, pushing temporal error rates to 2.0% (vs. 10%+ for other models).
Implications and Future Directions
MindDR demonstrates that meticulous multi-agent modularization, fine-grained data/reward design, and staged RL optimization enable ∼30B LLMs to match or surpass prior methods that depend on substantially higher capacities and cost. The architectural decomposition facilitates efficient parallel inference and mitigates long-context burdens typical in deep agentic research. The dynamic, modular reward/descent pipeline ensures targeted, dense supervision for each capability frontier, while preference alignment efficiently bridges objective/subjective evaluation gaps.
Remaining limitations include memory scalability (beyond 128K context), full-scope rubric evaluation (e.g., argument novelty, methodological critique), and further generalization to novel tasks/domains. Progress will likely involve adaptive context management (dynamic focus/compression), hierarchical/heterogeneous memory structures, and hybrid human-in-the-loop evaluation protocols.
Conclusion
MindDR establishes a new standard for scalable, cost-effective deep research agents, systematically closing the performance gap with proprietary models through tri-agent inference, knowledge-rich data synthesis, staged agent RL, and rigorous process-level evaluation. The work outlines a clear recipe for moving beyond brute-force scaling—designing curriculum, reward, and evaluation that precisely target each capability frontier of deep research automation.
(2604.14518)