- The paper introduces Vi-CD, an edge-centric framework that faithfully extracts minimal, causally sufficient circuits in Vision Transformers.
- It employs segmentation-inpainting and activation patching to isolate task-critical residual connections, achieving up to 10x greater sparsity while retaining over 80% accuracy.
- The method enables circuit-based steering to mitigate adversarial attacks, paving the way for robust, controllable, and interpretable vision models.
Motivation and Context
The paper "Seeing Through Circuits: Faithful Mechanistic Interpretability for Vision Transformers" (2604.14477) proposes and empirically validates Visual Circuit Discovery (Vi-CD), an edge-centric framework for uncovering mechanistically faithful computational circuits in Vision Transformers (ViTs), including OpenCLIP. Prior mechanistic interpretability work in LLMs has established edge-based circuit discovery as a gold standard for identifying minimal, causal subgraphs; however, vision models have largely relied on node-based techniques focusing on individual neurons, channels, or features. The paper closes this gap by introducing and benchmarking Vi-CD, which identifies sparse, task-aligned sets of residual-stream connections between attention heads and MLPs, elucidating not only which components are relevant but also how their activations are causally propagated.

Figure 1: Vi-CD enables circuit discovery in vision models via segmentation- and inpainting-based corruption, directed computational graph representations, and activation patching for precise causal circuit extraction.
Vi-CD formalizes the vision transformer as a directed graph G=(V,E), with nodes representing model components (attention heads, MLPs) and edges corresponding to additive residual-stream connections. The edge selection is guided by faithfulness: only those edges are retained whose inclusion suffices to maintain task performance (up to ϵ). Candidate circuits are evaluated through activation patching, substituting patch activations from clean inputs for circuit edges and corrupted activations elsewhere.
To generate effective clean-corrupted input pairs in the vision domain, the methodology employs a segmentation-inpainting pipeline that removes object-level evidence relevant to class prediction without introducing unnatural data artifacts. Circuit faithfulness is quantified by restricting computation to the discovered circuit and measuring task metrics (e.g., classification accuracy).
A key technical innovation is graph reduction: for scalability, Vi-CD aggregates incoming residuals into a unified attention-input node per block, reducing search space from O(L2H2) to O(L2H) edges, allowing tractable circuit extraction in large models.
Benchmarking Sparsity and Faithfulness
Strong numerical results demonstrate that Vi-CD achieves faithful circuit extraction with up to 10x greater sparsity compared to adapted baselines (EAP, EAP-IG) originally developed for LLMs. For ViT-B and OpenCLIP, Vi-CD maintains >80% classification accuracy while retaining less than 10% of edges—whereas EAP-IG only achieves comparable accuracy with far denser circuits. Random pruning approaches perform substantially worse, confirming that Vi-CD reliably isolates minimal, causally sufficient subgraphs.
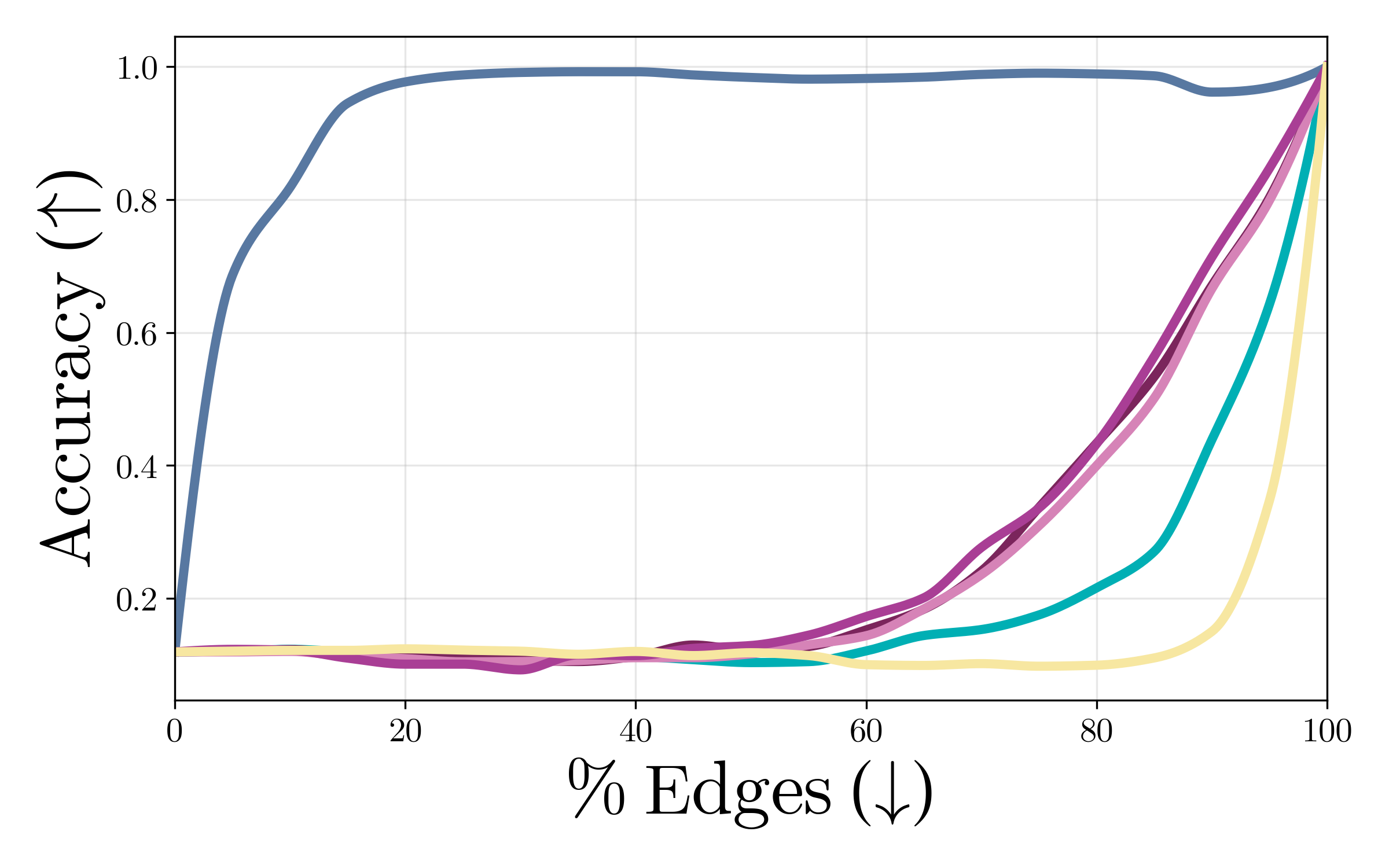

Figure 2: Vi-CD produces circuits with significantly higher faithfulness and extreme sparsity relative to adapted edge-centric baselines in ViT-B and OpenCLIP.
Semantic Structure and Circuit Overlap
In cross-class analyses, Vi-CD reveals that circuits for semantically similar classes exhibit substantial edge overlap, quantified using Jaccard similarity. Circuits for dog breeds and weapons cluster together, sharing computational pathways, whereas circuits for unrelated classes are distinct. The stability analysis discovers a robust "core" of edges present across runs for a given class, despite stochasticity in circuit mining, supporting the hypothesis that vision transformers encode behaviors in overlapping, compositional subgraphs.
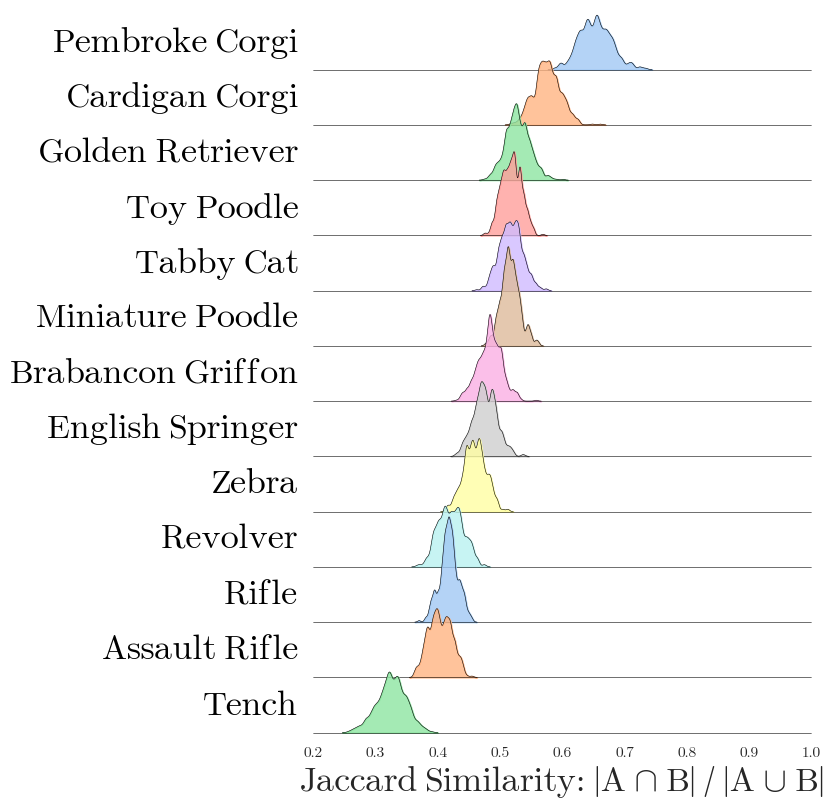
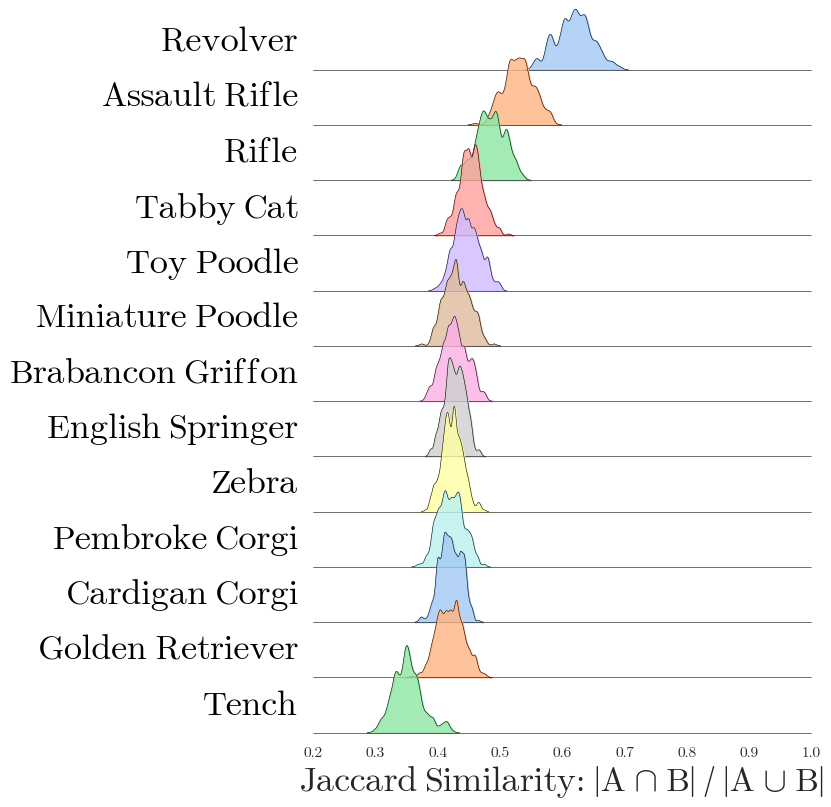
Figure 3: Pairwise Jaccard similarity between class circuits reflects semantic similarity, with high overlap among related classes such as dog breeds and weapons.

Figure 4: Hierarchical clustering of circuit core edge overlap in CLIP validates that semantically related classes share the majority of core edges.
Mechanistic Steering: Robustness and Safety Interventions
A pivotal contribution is the demonstration of circuit-based steering: extracting attack-specific circuits in CLIP models enables activation-based suppression of typographic attack pathways. By estimating corruption-aligned feature directions at circuit edges and projecting out these activations during inference, typographic attack success rates are reduced by over 90%, with only marginal drops in clean accuracy. Early layer interventions are shown to be sufficient for mitigating attacks, indicating that adversarial signals are routed through specific, identifiable computational pathways.

Figure 5: Circuit-based steering defends against typographic attacks by suppressing attack success rates without degrading performance.



Figure 6: Illustrative typographic corruptions used to stress-test CLIP circuits: bezel, multi-text, and big text overlays.
Steering approaches applied to retrieval tasks, such as the RoCOCO danger benchmark, halve the Recall Score of Manipulated Samples (RSMS) without loss of retrieval quality. Random edge steering yields substantially weaker improvements, empirically establishing that mechanistically-discovered circuits concentrate attack pathways more effectively than arbitrary sets.

Figure 7: Circuit steering in RoCOCO demonstrates a favorable safety-utility trade-off, reducing RSMS as a function of steering strength α with minimal loss in R@1.
Circuit Compositionality and Stability
The paper investigates compositionality—unions of class circuits support binary discrimination and zero-shot classification, indicating that underlying circuit structure is modular. Stability analyses reveal that circuit similarity increases with dataset size, and edges from attention heads contribute disproportionately to instability, suggesting redundancy and partial polysemanticity in transformer computations.

Figure 8: Circuit size and stability per class highlight the variability and redundancy in representation, with moderate but imperfect overlap across mined circuits for the same class.
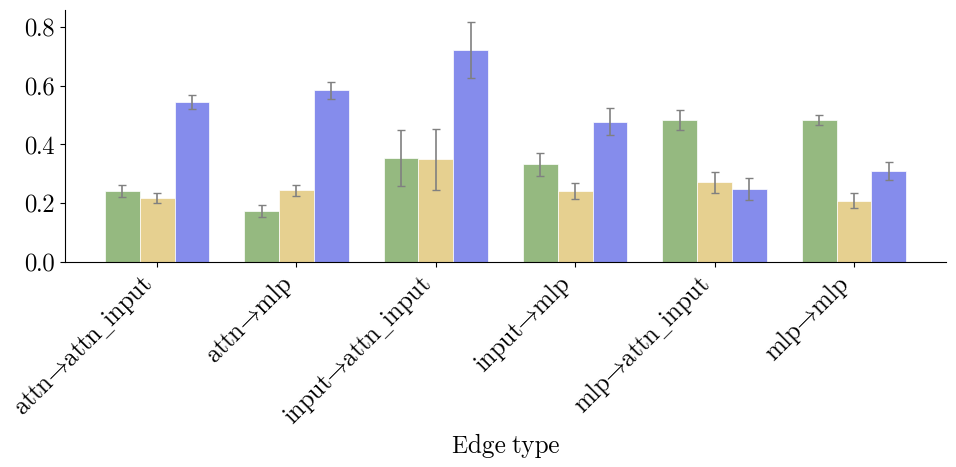

Figure 9: Edge stability analysis per edge type underscores relative instability of attention head-originated connections.

Figure 10: Zero-shot classification on unions of class circuits shows effective modularity and compositionality.
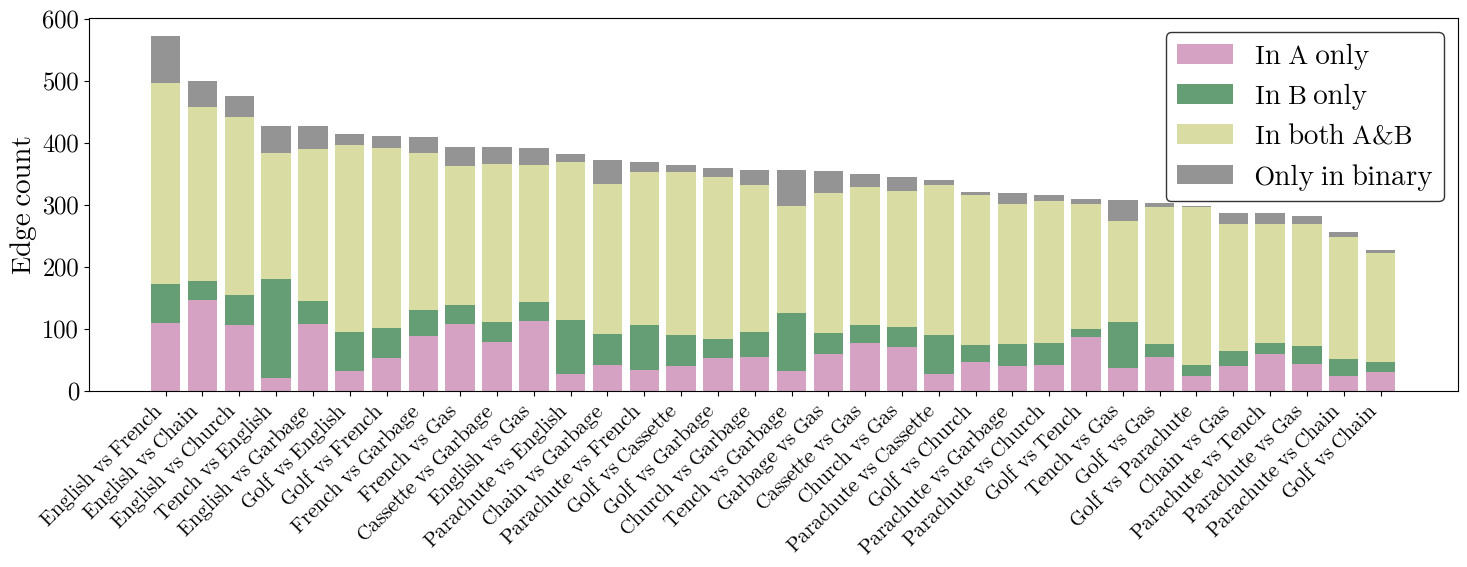
Figure 11: Analysis of class circuit specificity shows strong overlap between binary circuits and individual class circuits, reflecting discriminative mechanism reuse.
Practical and Theoretical Implications
Vi-CD establishes that vision transformers, similarly to LLMs, implement task-specific behaviors via compact, actionable subgraphs. These circuits are mechanistically faithful, and interventions based on circuit discovery enable robust defenses against adversarial attacks and provide causal control over model outputs. The strong sparsity, compositionality, and semantic clustering support the thesis that modern vision models encode functions via modular, reusable circuits rather than distributed representations.
Theoretically, the redundancy and imperfect overlap of circuits suggest that mechanistic interpretability must embrace sets or distributions of plausible circuits, echoing OR-compositionality observed in LLMs. Practically, circuit-based activation interventions pave the way for transparent and robust vision systems, enabling tailored defenses and safety analyses.
Future directions include scaling Vi-CD to larger architectures, integrating edge- and neuron-level interpretability, applying circuit mining to non-classification tasks (e.g., grounding, retrieval), leveraging circuit structure for anomaly detection, and longitudinal studies of circuit evolution throughout training.
Conclusion
Vi-CD advances the mechanistic interpretability of vision transformers by extracting edge-based circuits that are both sparse and faithfully causal for task performance. Empirical validation demonstrates significant sparsity gains, reliable faithfulness retention, semantic clustering, and effective, specific interventions for robustness against typographic and retrieval attacks. The modularity and compositional structure of circuits, along with their causal actionability, mark a critical step toward mechanistically interpretable and controllable vision architectures. Edge-centric circuit discovery thus provides a coherent framework for understanding and governing the internal computation of modern vision models.