- The paper introduces a test-time self-supervised recalibration method that refines feed-forward 3D reconstruction using reliable multi-view geometric consistency.
- It employs LoRA-based adaptation in transformer backbones to align full-view teacher and masked-view student representations through intra-frame and relational losses.
- Empirical results demonstrate improved pose accuracy and reconstruction quality across benchmarks with minimal compute overhead.
Free Geometry: Test-Time Self-Supervised Geometric Recalibration for Feed-Forward 3D Reconstruction
Introduction
Feed-forward multi-view 3D reconstruction models have achieved compelling real-time performance by directly regressing depth, pose, and point cloud representations from sets of input images. However, the predominant paradigm is train-then-freeze: after large-scale supervised training, models remain static during deployment. This rigid inference leads to a mismatch when handling novel test domains, manifesting as geometric errors, especially in the presence of occlusions, specular surfaces, or ambiguous cues due to limited observational coverage.
Free Geometry introduces a parameter-efficient and label-free framework for in-situ test-time recalibration of state-of-the-art feed-forward models, without any 3D ground truth. The core insight is monotonic geometric improvement with increasing input views: reconstructions from more views are consistently more reliable and geometrically consistent than those from masked input subsets. Free Geometry exploits this structural property to construct an intra-sequence self-supervision signal, aligning internal representations from masked and full-view versions of the scene at test time, and performing fast, lightweight LoRA-based adaptation.
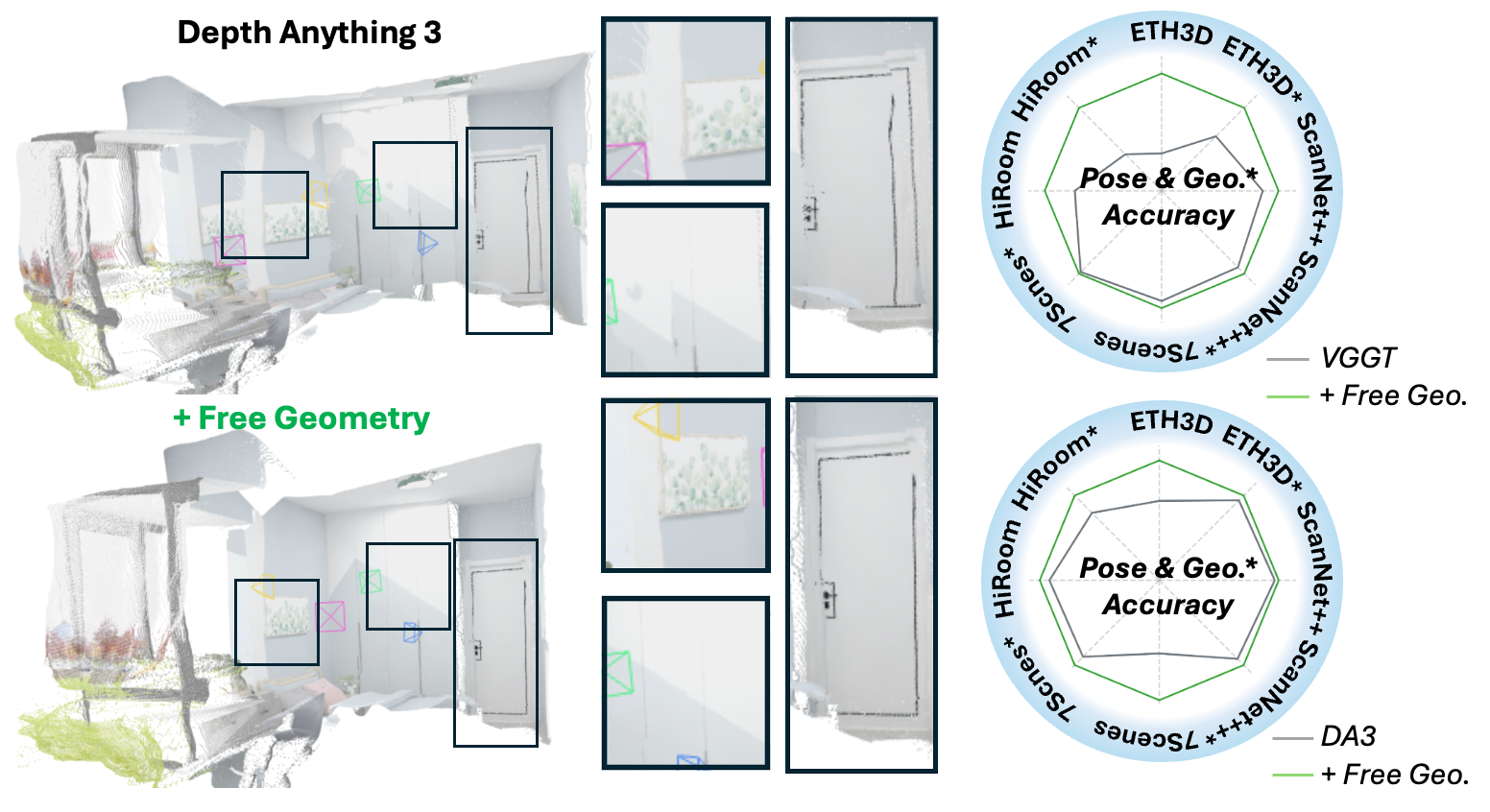
Figure 1: Free Geometry enables feed-forward 3D reconstruction models to self-evolve at test time without any 3D ground truth and generalize on models and datasets.
Theoretical Motivation and Methodology
Feed-forward backbones such as VGGT and Depth Anything 3 aggregate cross-view information via transformer-based modules, followed by independent per-view decoders. This compositional structure is critical: cross-view interactions and the resulting geometric feature consistency are bottlenecked in the shared encoder. Free Geometry’s self-supervised adaptation thus operates at the feature level in the backbone, not the final outputs, ensuring efficient optimization and strong geometric effect.
Given a sequence of images, Free Geometry processes two parallel branches:
- Teacher branch: The frozen backbone receives the full observation, producing high-fidelity geometric features.
- Student branch: The same backbone, augmented with LoRA adapters, receives a partial (masked) input subset and adapts its parameters to align features to the teacher.
Self-supervision comprises two loss terms:
- Intra-frame Consistency: Unmasked features from the student branch are directly aligned with the teacher, using both Huber and cosine embedding losses. This enforces value and directional consistency at the token level.
- Cross-frame Relational Loss: The student’s relational geometry (angles and pairwise feature relations) between unmasked and selected masked anchors is matched to the teacher. This ensures that the partial-view representation preserves topological relations induced by otherwise unseen frames.
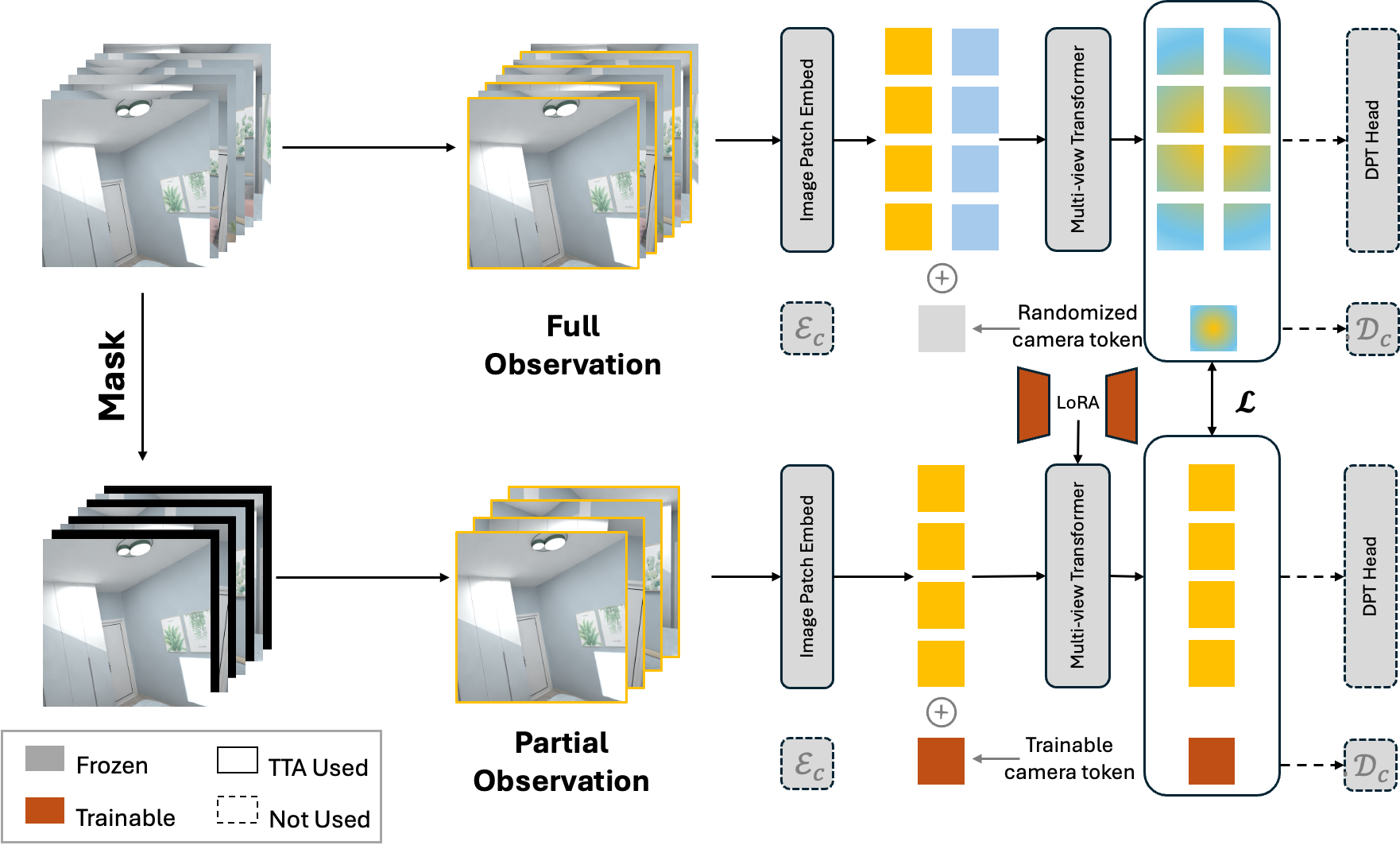
Figure 3: Architecture of Free Geometry, highlighting the use of LoRA adaptation in the student backbone.
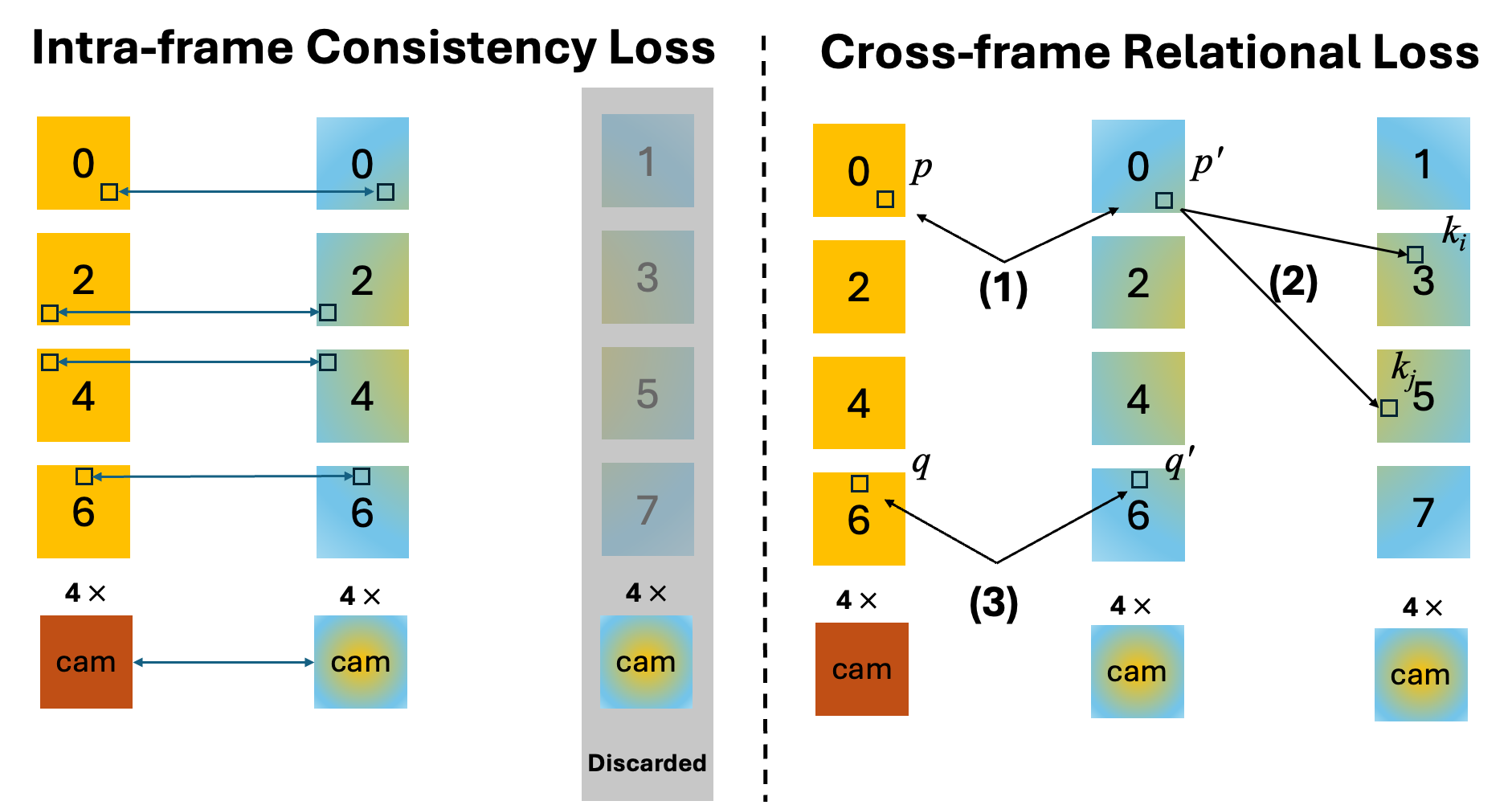
Figure 2: Self-supervised losses: intra-frame consistency (left) and cross-frame relational constraint (right) ensure feature transfer and geometric structure preservation.
LoRA adaptation is restricted to the transformer layers' multi-head attention weights and camera tokens, optimizing less than 0.2% of parameters and converging in less than two minutes per dataset on a single GPU. This parameter efficiency enables deployment-ready recalibration without memory or latency overhead.
Empirical Analysis
Free Geometry undergoes rigorous evaluation on four challenging 3D benchmarks: ETH3D, ScanNet++, 7-Scenes, and HiRoom—covering diverse scene geometry, occlusion regimes, and illumination conditions. Quantitative metrics include pose accuracy (AUC under strict and relaxed angular thresholds), F1-score for point-based reconstruction, and Chamfer Distance. Consistent improvements are measured across both strong baselines (VGGT, DA3) and view regimes (4–100 views):
- Camera Pose Accuracy: On average, 3.73% relative improvement in AUC@3 over frozen models.
- 3D Reconstruction Quality: 2.88% higher point F1-score and reduced Chamfer Distance across benchmarks.
- Cross-view Robustness: Gains persist as the number of input views increases, but are most pronounced in sparse-view settings, precisely where prior-based geometric ambiguity is greatest.
The error analysis via depth and reconstruction maps reveals not only reduction in outlier regions but also improvement in local surface consistency and boundary recovery.

Figure 4: Reconstruction improves as the number of input views increases, confirming the “longer is better” geometric regime.
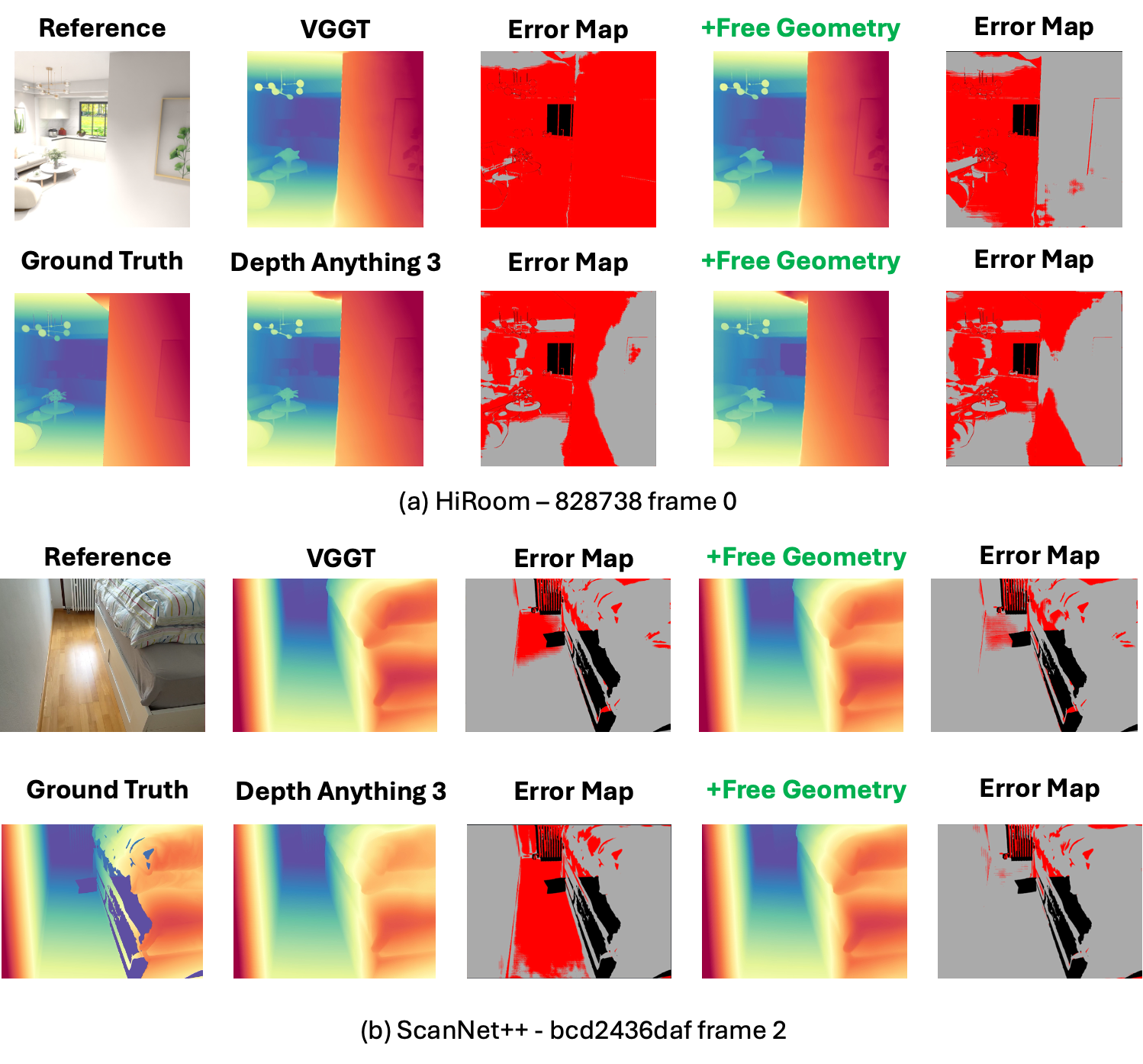
Figure 5: Qualitative results on multi-view depth; error maps show Free Geometry reduces large deviations, especially at discontinuities.
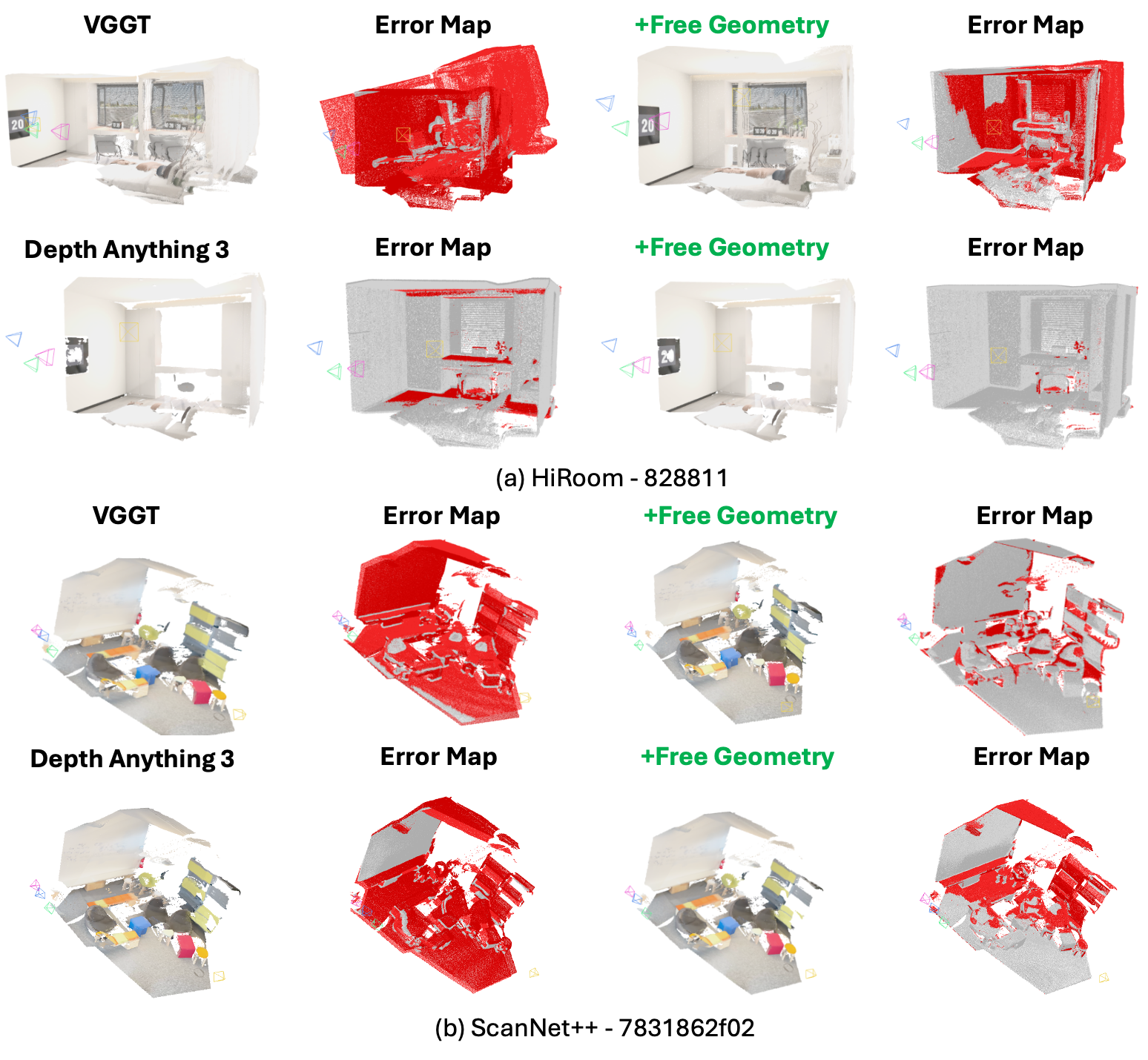
Figure 6: 3D reconstruction error maps; Free Geometry yields fewer outliers and improved surface regularity compared to baseline.
Ablation Studies and Feature Calibration
Loss ablations confirm that both intra-frame consistency and relational loss are critical: removing relational terms degrades F1 by over 10%, while dropping consistency loss destabilizes pose and degrades alignment. Feature-space analysis demonstrates that adaptation consistently reduces the MSE and increases cosine similarity between partial and full-view tokens, directly calibrating the student representation toward the higher-quality geometric regime.
Comparison between LoRA rank and adaptation effectiveness demonstrates that moderate-rank (e.g., 32) adapters optimally trade off expressivity and stability; excessive capacity leads to over-parameterization and performance degradation.
Discussion and Implications
The architectural monotonicity inherent in feed-forward multi-view transformers provides a unique avenue for constructing high-quality, label-free self-supervision at test time—a stronger signal than prior symmetric output consistency or entropy regularization applied in standard TTA. By operating at the bottleneck representation level, Free Geometry circumvents the computational and annotation bottlenecks of full output-level adaptation or large-scale retraining. These properties strongly suggest that self-evolving geometric priors are feasible for a broad class of 3D vision architectures, and could generalize to other perception modalities where input coverage directly correlates with precision (e.g., SLAM, neurally rendered view synthesis).
From a practical standpoint, the method achieves efficient online deployment, enabling robust adaptation to out-of-distribution or domain-shifted test sequences—a key desideratum for real-world robotics, AR/VR, and remote sensing applications.
Conclusion
Free Geometry advances test-time adaptation for feed-forward 3D reconstruction by translating the "longer is better" geometric monotonicity into an actionable, label-free training signal. Its dual-level, feature-space self-distillation leverages full-to-masked observation consistency and relational structure, efficiently adapting the model backbone via LoRA with negligible compute and memory cost. Empirical evidence across benchmarks and baselines validates the effectiveness and generality of the approach. Future research directions include extending this self-evolving paradigm to more complex scene priors, tighter integration into life-long learning settings, and application to unsupervised domain adaptation tasks in 3D computer vision.

