- The paper introduces SelfEvo, a framework that uses self-distillation to enhance 4D perception without relying on labeled data.
- It leverages a teacher-student model with spatiotemporal context asymmetry, achieving up to 36.5% improvement in depth and 20.1% in camera metrics.
- The methodology demonstrates robust generalization across diverse architectures and domains by continually refining geometric predictions in dynamic settings.
SelfEvo: A Framework for Annotation-free Self-Improving 4D Perception via Self-Distillation
Introduction and Motivation
Recent advances in large-scale, feedforward multi-view reconstruction models—such as VGGT, π3, and DUSt3R—have demonstrated strong generalization in monocular and multi-view geometry inference. However, the majority of these models are fundamentally limited by their reliance on supervised training with full 3D/4D geometric annotations. The procurement of such dense supervision is costly and frequently infeasible, especially for dynamic (4D) in-the-wild scenes. This imposes barriers to scalability and widespread applicability.
The central question addressed is whether pretrained feedforward multi-view reconstruction models can be continually improved using only unlabeled video data. The proposed solution, SelfEvo, introduces a self-distillation paradigm leveraging input context asymmetry: predictions with more spatiotemporal views (teacher) can guide a model operating on reduced views (student), enabling continuous, annotation-free self-improvement.
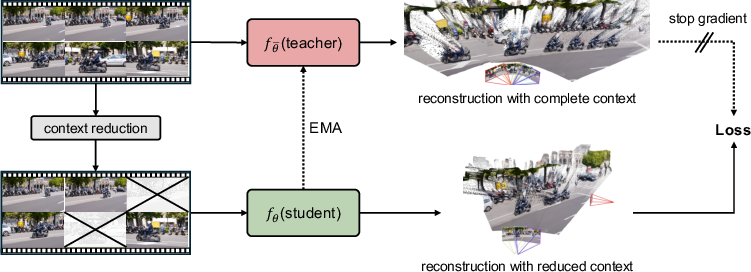
Figure 1: Overview of the SelfEvo framework; a context-rich teacher guides a reduced-context student using stop-gradient pseudo targets in a continual, EMA-updated loop.
Methodology
Spatiotemporal Context Asymmetry and Self-Distillation
SelfEvo’s key premise is that, for current multi-view networks, geometric predictions improve with increased spatial and temporal context. By casting model self-improvement as an asymmetric teacher-student distillation problem, SelfEvo produces a supervisory signal even in the absence of ground truth: the teacher network processes longer spatiotemporal clips, generating more accurate geometric pseudo-labels, which are used (with gradients stopped) to train the student on a subset of the same views.
The teacher and student share architecture and initialization; the teacher is updated as an exponential moving average (EMA) of the student to ensure stable, progressive co-evolution.
Design Axes
Ablative and comparative analyses reveal optimal choices for the framework:
- Context asymmetry induction: Frame dropping outperforms both appearance-based perturbations and spatial cropping.
- Frame selection: Randomly sampling student frames from the teacher sequence is more robust and generalizes better than attention-guided or heuristic approaches.
- Teacher updating: An online, continually updated teacher (EMA) leads to substantially better adaptation and stability than fixed-teacher or offline pseudo-labeling.
- Parameter freezing: Freezing the camera decoder while training all other modules achieves the best trade-off, mitigating camera drift due to context mismatch.
- Supervision form: Output-level distillation suffices; intermediate feature matching losses provide no consistent benefit.
Training Procedure
The default instantiation employs random frame dropping, per-step EMA teacher updates (e.g., decay 0.995), selective parameter freezing (camera decoder fixed), and purely output-level losses. The framework is applied for post-training using large unlabeled video corpora from synthetic and real-world sources, across multiple base model architectures.
Empirical Results
New-domain Adaptation and Original-domain Retention
SelfEvo achieves large absolute improvements on held-out benchmarks using only unlabeled data. On OmniGeo and OmniVideo, relative improvements reach up to 36.5% (depth, Abs Rel) and 20.1% (camera, AUC metrics) over the pretrained VGGT model, outperforming not only pseudo-labeling but also supervised fine-tuning in some out-of-domain generalization settings.
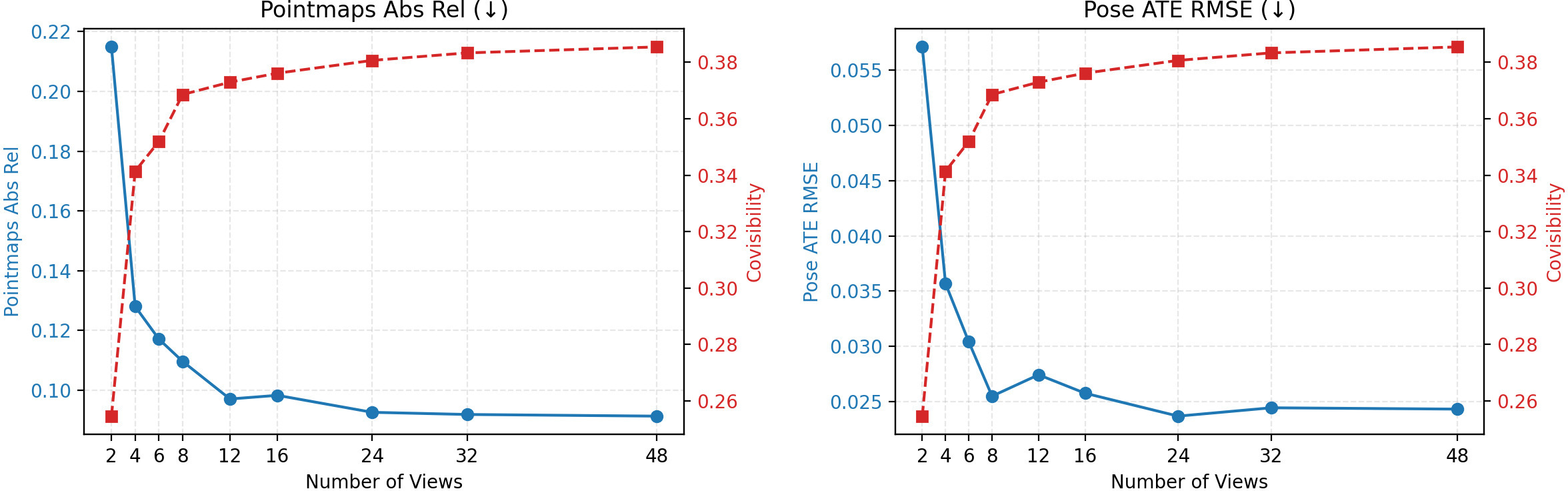
Figure 3: Performance improves for anchor frames as more intermediate context frames are added, validating the central context-asymmetry premise.
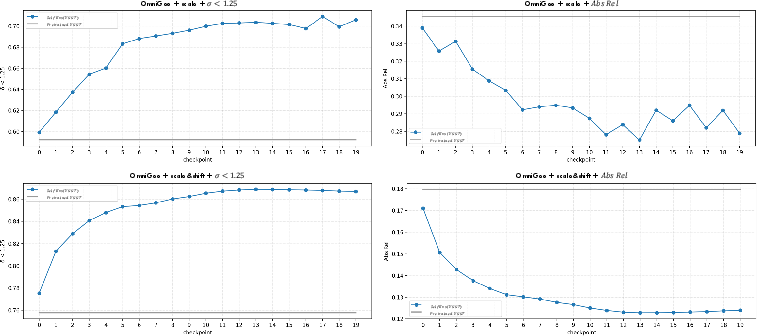
Figure 5: Checkpoint-wise depth improvements on OmniGeo throughout self-improvement training; consistently exceeds the pretrained baseline.
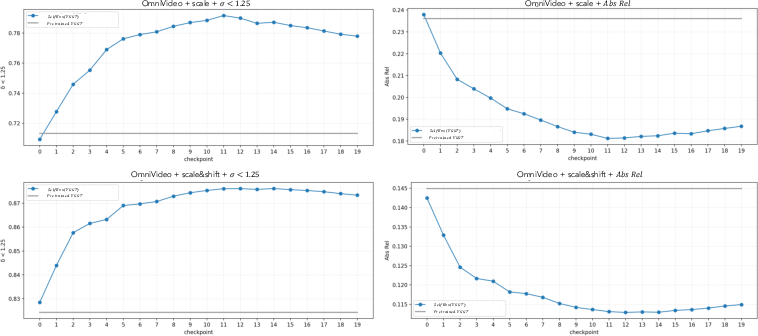
Figure 2: Similar checkpoint-wise depth improvements on OmniVideo.
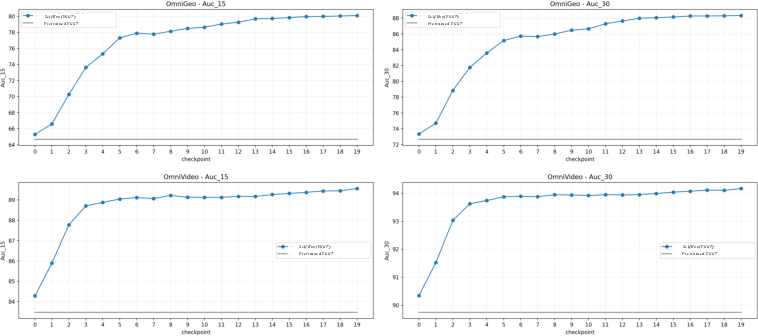
Figure 4: Checkpoint-wise camera estimation AUC improves monotonically over training on both OmniGeo and OmniVideo.
Crucially, improvements in the target domain do not degrade performance on the original domain: retention is preserved, and in several cases, prior geometric capabilities are further enhanced (e.g., Sintel, KITTI, RealEstate10K).
Generality Across Models and Data
The methodology generalizes robustly across architectures (VGGT, π3) and dataset regimes (synthetic human-centric, real-world robotics, egocentric, and Internet videos). Both depth and camera metrics improve even when trained with fully in-the-wild small video subsets.

Figure 6: Improved qualitative results after SelfEvo training on challenging unconstrained Internet and egocentric videos versus the pretrained baseline.
Out-of-domain Generalization
SelfEvo-trained models exhibit improved generalization to novel, unseen domains including robotics (DROID), animal motion, and egocentric videos (HOI4D). This is in contrast to supervised fine-tuning, which can bias models toward specific domains at the cost of transferability.

Figure 7: Visual evidence of improved generalization across diverse unseen domains post self-improvement.

Figure 8: Qualitative improvement in camera and geometry predictions on wild-capture Internet videos.
Analysis
Systematic ablations demonstrate the relative impact of all design components. Online supervision is a major driver of OOD robustness, while random frame selection and output-only losses streamline adaptation. The method’s self-improvement effect is most pronounced in the presence of significant camera motion—a limitation under static views. The process is stable in practice but, like all self-supervised schemes, is theoretically susceptible to model collapse if run unchecked; this risk has not been observed within reasonable training schedules.
Implications and Future Directions
SelfEvo suggests a paradigm shift for vision foundation models toward lifelong learning and continual adaptation in the absence of exhaustive annotation. It establishes a practical, annotation-free loop for geometry models to dynamically specialize to evolving distributions, whether from synthetic, robotics, or Internet-scale video.
Practical applications span autonomous robotics, AR/VR, embodied agents, and any scenario requiring geometric reasoning in changing or uncurated environments. Theoretically, it raises new questions about the limits of self-distillation, student-teacher co-evolution, and unsupervised geometry in dynamic settings.
Future developments may extend to:
- Token-level or patch-level context asymmetry: To supplement frame-level dropping under static camera conditions.
- Hybrid photometric-context losses: Combining with photometric consistency where suitable.
- Scaling to larger, more diverse Internet video sources: For universal geometry pretraining.
- Automated model collapse detection/mitigation: To ensure safe lifelong self-improvement.
Conclusion
SelfEvo presents a comprehensive, annotation-free self-improvement strategy for multi-view 4D perception models. Its core insight—leveraging spatiotemporal context asymmetry for continual self-distillation—enables consistent enhancement of geometric prediction capacities across models and domains, without access to labeled data. The framework achieves substantial empirical gains, robust domain generalization, and preserves original capabilities, setting a new standard for post-training adaptation of vision geometry models.

