Memory Transfer Learning: How Memories are Transferred Across Domains in Coding Agents
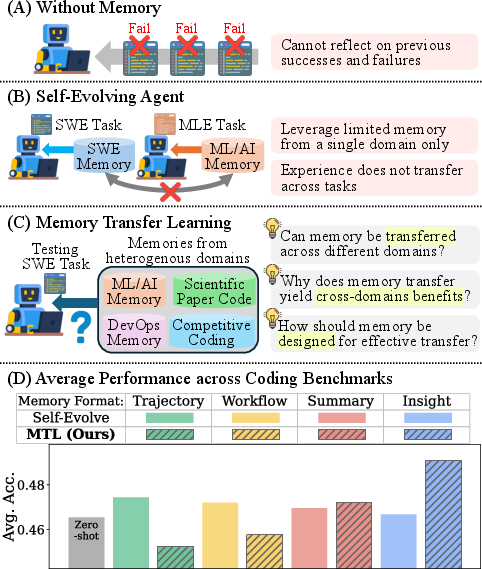
Abstract: Memory-based self-evolution has emerged as a promising paradigm for coding agents. However, existing approaches typically restrict memory utilization to homogeneous task domains, failing to leverage the shared infrastructural foundations, such as runtime environments and programming languages, that exist across diverse real-world coding problems. To address this limitation, we investigate \textbf{Memory Transfer Learning} (MTL) by harnessing a unified memory pool from heterogeneous domains. We evaluate performance across 6 coding benchmarks using four memory representations, ranging from concrete traces to abstract insights. Our experiments demonstrate that cross-domain memory improves average performance by 3.7\%, primarily by transferring meta-knowledge, such as validation routines, rather than task-specific code. Importantly, we find that abstraction dictates transferability; high-level insights generalize well, whereas low-level traces often induce negative transfer due to excessive specificity. Furthermore, we show that transfer effectiveness scales with the size of the memory pool, and memory can be transferred even between different models. Our work establishes empirical design principles for expanding memory utilization beyond single-domain silos. Project page: https://memorytransfer.github.io/

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how “coding agents” (AI tools that write and fix code) can learn from their past experiences. Instead of keeping separate memories for each kind of coding task, the authors ask: what if we put all those memories together and let the agent reuse them across different kinds of problems? They call this idea Memory Transfer Learning (MTL).
What questions did the researchers ask?
The researchers focused on three simple questions:
- Do memories from different kinds of coding tasks actually help an agent on new tasks?
- What kind of knowledge gets reused most usefully?
- What makes a memory more or less helpful when transferred to a new task?
How did they study it?
To answer these questions, they built a simple “remember and reuse” system and tested it on many kinds of coding challenges, from small functions to big projects.
Here’s how their approach worked, with everyday analogies to make it clearer:
- Coding agents: Think of a smart coding assistant that tries steps, runs code, reads error messages, and keeps notes about what worked and what didn’t.
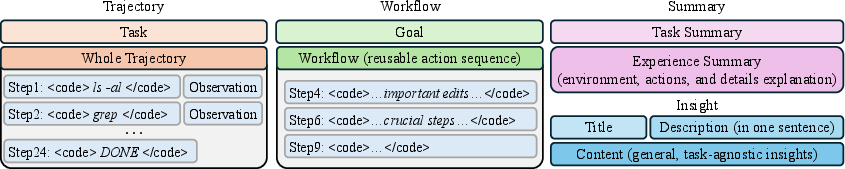
- Memory: The assistant stores notes from past attempts. The authors tried four types of notes (from most detailed to most general):
- Trajectory: A play-by-play log (like a sports commentary) of every command and result.
- Workflow: A distilled checklist of key steps (like a recipe’s steps).
- Summary: A short “what happened and what we learned” recap (like a lab report).
- Insight: High-level tips and principles that apply across many tasks (like cooking wisdom: “taste as you go”).
- Building a shared memory pool: They first solved many problems across different test sets and saved the memories. Then, for a new task, the agent searched this shared pool to find the most similar memories.
- Finding relevant memories: They turned tasks and memories into numeric “fingerprints” (embeddings) that let a computer measure similarity, then grabbed the top few matches to show the agent before it starts.
- Testing: They evaluated on six different coding benchmarks, covering function-level problems, whole codebase edits, and domain-specific tasks (like machine learning projects). They also tried different AI models to see if the results held up.
What did they find, and why does it matter?
The main takeaways are simple but powerful:
- Cross-task memories help: Using a shared memory pool from different kinds of coding tasks improved performance on average by about 3–4%. In several cases, gains were even bigger.
- High-level tips beat raw logs: The most helpful memories were the “Insight” type—general tips and best practices. The least helpful were raw “Trajectory” logs, which were too tied to specific past tasks and could mislead the agent.
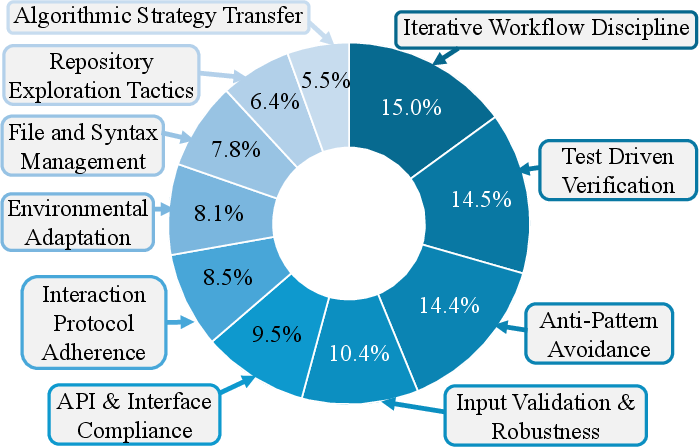
- It’s mostly “how to work,” not “what code to write”: What transferred best was “meta-knowledge”—things like good debugging routines, how to safely test changes, and how to avoid breaking things—rather than copy-pasting specific code patterns.
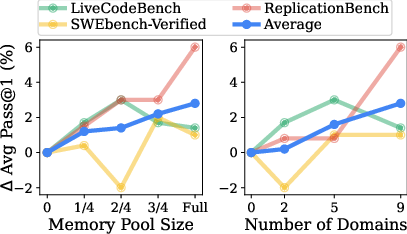
- More memories and more variety help: A larger, more diverse memory pool (more tasks and different domains) made it more likely the agent would find something useful.
- Works across different models: Memories from one model could help a different model too, because high-level tips aren’t tied to a specific AI. Still, using memories created by the same model worked best.
- Simple search worked best: Surprisingly, just using embedding similarity to pick memories beat fancier methods like reranking or rewriting with another AI step in their setup.
- Beware “negative transfer”: Sometimes memories hurt. This happened when:
- A memory looked similar but wasn’t actually relevant, distracting the agent.
- The agent trusted weak tests and thought a fix worked when it didn’t.
- The agent followed a “best practice” too rigidly in the wrong context.
These findings matter because they show how to design better, safer coding assistants: focus on general, reusable guidance rather than overwhelming them with detailed past logs.
What could this mean for the future?
This research suggests some practical rules for building stronger coding agents:
- Collect and share memories across many kinds of tasks, not just one niche.
- Emphasize high-level insights and checklists that teach good habits (like testing changes, making small edits, and verifying results).
- Keep memory pools large and diverse to increase the chance of finding relevant help.
- Use simple, robust retrieval first; be cautious with extra reranking or rewriting unless it’s clearly beneficial.
- Watch for negative transfer and design safeguards (e.g., better filters, domain-aware routing, or adapting insights to the current task).
In short, coding agents can improve by learning from a broad “library of experience,” especially when that library focuses on general strategies and careful validation. This could make future coding assistants more reliable, efficient, and adaptable across many types of programming problems.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized as targeted research directions for future work.
- Benchmark scope and representativeness
- Limited to six coding benchmarks with at most 100 samples per benchmark; unclear whether results generalize to larger, more diverse, or real-world, long-horizon software repositories and CI/CD workflows.
- No analysis of language-specific transfer patterns (e.g., Python ↔ C++/Java/JS); unclear how transferability varies by programming language families and tooling ecosystems.
- External validity to non-Linux environments (Windows/macOS, diverse shells) and atypical runtime contexts remains untested.
- Metrics and evaluation design
- Reliance on Pass@k; missing measurements of action efficiency (steps/edits), latency, tool failures, and resource usage to substantiate “reduced reasoning overhead.”
- Limited statistical robustness (only some experiments repeated three times); variance across seeds/sampling strategies is not reported.
- Success/failure attribution uses an LLM judge without human validation or inter-rater reliability; potential labeling bias/variance is unquantified.
- Memory generation quality and abstraction control
- Abstraction level is induced via prompting; there is no principled, reproducible method to generate high-abstraction, high-transfer “Insight” memories across tasks.
- No causal control for confounders such as token length, verbosity, or specificity when comparing memory formats; unclear whether abstraction or brevity drives gains.
- The proxy abstraction measures (DBI/LISI, task-inference similarity) lack validation against a ground-truth notion of abstraction; need formal definitions and gold standards.
- Retrieval and adaptation methods
- Retrieval is static and solely embedding-based; no learned retriever, domain-aware router, or hybrid code/text structure-aware matching (e.g., AST/CFG/semantic code embeddings).
- No step-wise (on-policy) retrieval during agent execution; all memories are injected once at the beginning, risking early anchoring and poor mid-trajectory adaptation.
- Reranking and rewriting were tried with simple prompts and underperformed; no systematic exploration of stronger adaptation pipelines (e.g., multi-stage retrieval, tool-aware adapters, constraint checking, or counterfactual simulation).
- No sensitivity analysis of retrieval hyperparameters (top-N, similarity metric, index type) or memory ordering/formatting effects in the prompt context.
- Negative transfer mitigation
- While causes are described (domain-mismatched anchors, false validation confidence, misapplied best practices), no algorithmic defenses are proposed or tested (e.g., uncertainty- or risk-aware gating, contradiction detection, editable memory overlays, or “shadow-mode” validation before applying memory-driven edits).
- No online detection of harmful memory influence (e.g., monitors for divergence from spec/tests, automatic rollback, or confidence calibration).
- Source–target domain analysis
- No study of which specific source domains help which target domains; lacks domain-similarity metrics, transferability predictors, and routing strategies to select helpful sources.
- Directionality of transfer (e.g., repository-level → function-level vs. the reverse) remains unquantified beyond aggregate averages.
- Cross-model transfer and model biases
- Cross-model memory transfer underperforms self-generated memories; no techniques to canonicalize, normalize, or de-bias memories across models (e.g., schema translation, style harmonization).
- No analysis of whether model-scale, instruction-tuning, or alignment style affects the usefulness of memories generated for other models.
- Memory maintenance and lifecycle
- No policies for deduplication, conflict resolution, versioning, or staleness handling as libraries/APIs evolve; absence of automated retirement or refresh of outdated guidance.
- Risk of accumulating contradictory or low-quality memories is unaddressed; no quality scoring, trust calibration, or continuous cleaning.
- Scaling properties and systems aspects
- Only modest pool sizes evaluated (hundreds to thousands); retrieval quality, latency, and cost at million-scale memory pools and across many domains are not assessed.
- Token/compute costs of memory injection (per-step and per-episode) and the performance–cost trade-off are not quantified.
- Security, safety, and privacy
- Potential leakage of sensitive code or proprietary patterns in cross-domain memory pools is not discussed; lacks privacy-preserving or policy-compliant memory sharing mechanisms.
- No safeguards against propagating insecure coding practices; security evaluation (e.g., vulnerability introduction rates) is absent.
- Licensing and data provenance concerns (e.g., reuse across different code licenses) are not addressed.
- Reproducibility and openness
- Heavy reliance on proprietary models (e.g., GPT-5-mini, OpenAI embeddings) and private prompts hinders reproducibility; no open-source replication package or release of memory pools/prompts beyond the website link.
- The LLM-judge, memory generation prompts, and retrieval pipeline lack full transparency for independent verification.
- Causal mechanisms of “meta-knowledge” transfer
- The claim that meta-knowledge drives gains is based on LLM categorization and qualitative case studies; lacks controlled experiments (e.g., injecting only validation routines vs. code patterns) to prove causality.
- No ablation isolating the effect of specific meta-knowledge types (e.g., validation routines, small-step edits, environment guardrails) to quantify their individual contributions.
- Design space of memory representations
- Only four formats (Trajectory/Workflow/Summary/Insight) are studied; hybrid or hierarchical memories (e.g., insight → workflow → snippet) and program-structure-aware memories (ASTs, patches, tests) remain unexplored.
- Combining multiple granularities adaptively (coarse insight first, finer details on demand) is not evaluated.
- Agent architecture dependence
- Results may hinge on the chosen agent (mini-swe-agent) and interaction protocol; it is unclear whether findings hold for tool-augmented, multi-agent, or planning-heavy architectures.
- No analysis of how memory interacts with different planning/verification loops (e.g., code execution sandboxes, test synthesis, repair strategies).
- Retrieval signals beyond text
- Sole reliance on text embeddings ignores rich signals (execution traces, failing test signatures, dependency graphs, API surface diffs); integrating such signals could improve retrieval precision.
- Policy for memory use within an episode
- The agent always applies retrieved memory without explicit checks; missing policies for when to ignore, defer, or override memory based on evidence (tests/specs/CI feedback).
- Data contamination and leakage checks
- No audit to ensure that memory items do not indirectly contain target benchmark solutions or training-set leakage that could inflate measured transfer.
- Human-in-the-loop considerations
- No study of how developers might curate, approve, or override shared memories; absence of UX design for memory provenance, explainability, and trust.
- Long-term continual learning
- MTL is evaluated with offline-generated memories; the dynamics of continual, on-policy memory writing, refinement, and pruning in open-ended deployment remain unexplored.
- Fine-grained transfer diagnostics
- Lack of per-instance predictors of transfer success/failure; no meta-model to estimate when memory will help or harm before injection.
- Retrieval fairness across baselines
- Comparisons to AgentKB/ReasoningBank do not control for retrieval strategies, memory quality standards, or memory length; fairness and apples-to-apples comparability are unclear.
- Parameter sensitivity
- The choice N=3 retrieved items is fixed; no exploration of how performance varies with N, item diversity, or redundancy-aware selection.
- Extension beyond coding
- The study deliberately focuses on coding; whether and how these findings extend to heterogeneous agent ecosystems (web, robotics, data analysis) is left open.
Practical Applications
Immediate Applications
The paper’s findings enable several deployable workflows and tools today by emphasizing high‑level, transferable “Insight” memories, simple embedding-based retrieval, and cross-project memory pools.
- Bold: Enterprise coding assistants with cross-project “Insight” memory (software)
- Description: Build a unified, organization-wide memory pool of high‑abstraction insights (e.g., verification routines, minimal patch strategies, interface/contract guards) extracted from past repositories, incidents, and PRs. Surface the top‑N relevant insights in IDEs and code review tools to guide edits, tests, and validation.
- Tools/Workflows: Insight extraction pipeline from PRs and CI logs; embedding index and retrieval; IDE sidebar for “insight prompts”; Git hooks that inject validation playbooks when diffs touch risky areas.
- Assumptions/Dependencies: Access to historical repos/CI logs; basic embedding retrieval; guardrails to avoid leaking sensitive code; developer opt-in to prevent negative transfer.
- Bold: CI/CD “verification-first” bots for PRs (software, DevOps/SRE)
- Description: Add a CI bot that injects meta-knowledge (e.g., “create self-contained tests via here-doc,” “validate interfaces before refactor”) into PR discussions and enforces minimal, validated patches before merge.
- Tools/Workflows: GitHub/GitLab app; policy checks that trigger when tests are missing or edits are large; auto-comment with relevant insights from the memory pool.
- Assumptions/Dependencies: Stable test infrastructure; permissions to comment on PRs; lightweight LLM inference budget.
- Bold: Terminal/automation agent guardrails (software ops, IT)
- Description: Enhance shell-based agents/scripts with cross-domain meta-knowledges (safe command usage, failure anticipation, rollback steps). Reduce brittle, one-shot commands by promoting inspect→edit→verify flows.
- Tools/Workflows: Terminal agent wrapper that retrieves insights before execution; pre-flight checklists; “dry-run-first” templates.
- Assumptions/Dependencies: Access to prior shell/script trajectories; ability to run inline tests; environment parity across hosts.
- Bold: MLOps/replication coach (academia, research, ML engineering)
- Description: Provide an assistant that guides paper replication and ML pipelines with insights like dataset/eval inspection, fixed seeds, train+val consolidation, and API-change adaptation.
- Tools/Workflows: Notebook/CLI plugin that proposes validation cells; replication checklists; integration with experiment tracking.
- Assumptions/Dependencies: Access to prior replication runs; basic LLM; team conventions for evaluation and data splits.
- Bold: Cross-model memory sharing within teams (software, platform)
- Description: Centralize an “InsightBank” that multiple LLM-backed tools (open and proprietary) can query. Leverage the paper’s cross-model transfer result to share meta-knowledge team-wide.
- Tools/Workflows: Memory service with REST API; model-agnostic prompt templates for insight consumption; access controls.
- Assumptions/Dependencies: Security and identity management; model-specific formatting adapters; ongoing curation.
- Bold: Educational coding tutors that prioritize process over code (education)
- Description: Deliver feedback emphasizing inspection, small-step edits, and systematic validation rather than providing full solutions. Improve student debugging habits and reduce fragile fixes.
- Tools/Workflows: LMS plugins; autograder that attaches relevant insights; IDE extensions for student labs.
- Assumptions/Dependencies: Institutional acceptance; curated insight pools mapped to curricula; monitoring to prevent overreliance.
- Bold: QA/test authoring aide (software quality)
- Description: Suggest creation of quick, self-contained tests to validate fixes inline, especially when official tests are sparse. Encourage “test-then-commit” behaviors.
- Tools/Workflows: IDE snippets; PR comment templates for minimal test scaffolds; here-doc generators.
- Assumptions/Dependencies: Compatible runtimes in CI; culture of adding tests with fixes.
- Bold: Secure coding hygiene coach (software security)
- Description: Surface insights about input validation, safe default settings, and API/contract enforcement during development and code review to prevent common vulnerability classes.
- Tools/Workflows: Security-focused insight tag filters; integration with SAST outputs to attach relevant guardrails.
- Assumptions/Dependencies: Access to prior security fixes and postmortems; secure handling of sensitive content; human review.
- Bold: Knowledge management for software orgs (knowledge ops)
- Description: Convert heterogeneous artifacts (PRs, postmortems, retro notes, tickets) into high-level, de-identified insights for discoverability and reuse across teams and languages.
- Tools/Workflows: Abstraction pipeline that turns trajectories/workflows into summaries and insights; insight ranking by adoption impact.
- Assumptions/Dependencies: Data ingestion permissions; de-identification policies; quality scoring and curation.
- Bold: Internal governance for memory safety (policy within orgs)
- Description: Reduce IP/privacy risk by storing only high-abstraction insights instead of raw code/trajectories; institute retention and access policies for the memory pool.
- Tools/Workflows: Memory redaction filters; approval workflows for memory insertion; audit logs.
- Assumptions/Dependencies: Legal guidance; toolchain for automated redaction and tagging; periodic audits.
Long-Term Applications
As the field matures, larger-scale, standardized, and safety-critical deployments can leverage the paper’s design principles (meta-knowledge focus, high abstraction, scalable memory pools) with improved retrieval/adaptation to minimize negative transfer.
- Bold: Adaptive, step-wise retrieval and domain routing for agents (software, robotics)
- Description: Move from static top‑N retrieval to step-wise, tool-aware memory routing that selects insights per subgoal and environment. Apply to robotics/process automation where procedural meta-knowledge is critical.
- Tools/Workflows: Domain routers; execution-aware retrievers; step-level memory APIs integrated with agent planners.
- Assumptions/Dependencies: More research on agentic retrieval; telemetry for state-aware selection; evaluation harnesses.
- Bold: Auto-abstraction pipelines with quality guarantees (software, platform)
- Description: Systematically transform raw traces/workflows into generalized insights with abstraction scoring and human-in-the-loop review to avoid task-specific anchoring and negative transfer.
- Tools/Workflows: Abstraction scorers (e.g., task-agnostic similarity tests); insight linting; reviewer UIs; feedback loops.
- Assumptions/Dependencies: New metrics and benchmarks; curation capacity; provenance tracking.
- Bold: Federated “Insight” consortia and marketplaces (cross-industry)
- Description: Privacy-preserving sharing of high-level insights across organizations to disseminate best practices (e.g., validation patterns, rollback protocols) without exposing proprietary code.
- Tools/Workflows: Standardized insight schema; differential privacy/redaction; reputation and versioning systems.
- Assumptions/Dependencies: Legal frameworks for sharing; interoperability standards; trust and certification.
- Bold: Sector-specific meta-knowledge libraries for safety-critical software (healthcare, energy, finance)
- Description: Curate validated, regulator-aligned insight banks (e.g., pre‑deployment validation, audit trails, change control) to guide updates to medical devices, SCADA, or trading systems.
- Tools/Workflows: Compliance-tagged insights; simulation-first verification checklists; change-management bots.
- Assumptions/Dependencies: Regulatory approvals; sandbox/simulation parity; rigorous audits; high reliability.
- Bold: Organization-wide agent memory governance and risk dashboards (policy, GRC)
- Description: Manage provenance, access, and risk for agent memories; detect negative transfer patterns (e.g., domain-mismatched anchors, false validation confidence) and enforce mitigation policies.
- Tools/Workflows: Memory lineage graphs; automated detectors for misleading anchors; kill-switches; periodic reviews.
- Assumptions/Dependencies: Instrumentation across tools; policy adoption; explainability of retrieval decisions.
- Bold: Cross-domain, cross-agent unified memory for enterprise automation (enterprise AI)
- Description: Share meta-knowledge among code agents, doc assistants, IT runbooks, and data pipelines to align workflows around inspect→edit→verify routines and guardrails.
- Tools/Workflows: Enterprise memory fabric with domain tags; permissions; connectors to ticketing/CI/IDEs.
- Assumptions/Dependencies: Harmonized ontologies; robust access control; change impact analysis.
- Bold: Standards for “Insight” schemas and agent-memory auditing (policy, standards bodies)
- Description: Establish open schemas and auditing norms for agent memory items (titles, descriptions, content, provenance, abstraction level) to improve portability and compliance.
- Tools/Workflows: Standard doc/spec; conformance test suites; third-party certification.
- Assumptions/Dependencies: Multi-stakeholder coordination; incentives for adoption; backward compatibility.
- Bold: Curriculum-level insight banks and pedagogy research (education)
- Description: Build cross-course, language-agnostic insight libraries that scaffold students’ problem-solving processes; evaluate learning gains from meta-knowledge transfer.
- Tools/Workflows: Curriculum-aligned tagging; adaptive retrieval tuned to learner level; analytics on process adherence.
- Assumptions/Dependencies: Institutional partnerships; ethics oversight; longitudinal studies.
- Bold: Negative-transfer mitigation via counterfactual validation (software, research)
- Description: Before using a retrieved insight, test counterfactuals (e.g., synthetic checks) to ensure relevance; auto-rewrite or discard memories that trigger misleading anchoring.
- Tools/Workflows: Pre-application “relevance tests”; LLM-based rewriting modules; fail-safe fallbacks.
- Assumptions/Dependencies: Extra inference budget; robust relevance metrics; minimal latency impact.
- Bold: Cross-model/bidirectional memory brokers with bias adaptation (platform)
- Description: Industrialize cross-model memory transfer by learning adapters that normalize differences in style and implicit assumptions between models.
- Tools/Workflows: Memory adapters; alignment scoring; A/B testing in multi-model fleets.
- Assumptions/Dependencies: Stable APIs; diverse model mix; monitoring for regressions.
- Bold: Human-in-the-loop oversight for high-stakes deployments (healthcare, finance, energy)
- Description: Require human approval for memory application in regulated contexts; track how insights influence decisions for auditability.
- Tools/Workflows: Review queues; traceability of memory usage; sign-off policies.
- Assumptions/Dependencies: Trained reviewers; clear accountability; integration with existing QA/compliance processes.
Notes on Feasibility and Dependencies
- Method-level dependencies: Access to a corpus of heterogeneous past tasks; ability to generate high-abstraction insights; simple embedding-based retrieval (shown to outperform reranking/rewriting in the paper).
- Risk factors: Negative transfer from low-abstraction trajectories or domain-mismatched anchors; false validation signals; overgeneralized “best practices.”
- Mitigations: Prefer high-abstraction insights over raw traces; curate and score memories for task-agnosticism; monitor outcomes and add human review for high-stakes changes.
- Scaling: Effectiveness increases with larger, more diverse memory pools and more source domains; cross-model transfer is viable but self-generated memories perform best.
- Governance: Apply privacy/IP policies—store generalized insights rather than code; maintain provenance, access controls, and audits.
Glossary
- Adaptive Rewriting: A method of rewriting retrieved memories to align them with a specific target task. "For task-adaptive memory rewriting, we prompt the LLM to rewrite the retrieved memories to better align with the target task."
- AgentKB: A framework for managing and leveraging a unified memory pool across multiple task domains. "AgentKB~\cite{agentkb} introduces a framework for managing and leveraging a unified memory pool across multiple task domains."
- Agentic settings: Contexts involving autonomous agents operating and reasoning through multi-step interactions. "Cross-domain memory retrieval is inherently challenging, and static retrieval methods fail to generalize in heterogeneous agentic settings."
- Cosine similarity: A similarity measure between embedding vectors based on the cosine of the angle between them. "measure the cosine similarity between task embedding feature and memory embedding features."
- Cross-model memory transfer: Transferring memories generated by one model for use with a different model. "In particular, cross-model memory transfer is effective in both directions, from a stronger model (GPT-5-mini) to weaker models (Qwen3-Coder and DeepSeek V3.2), and vice versa."
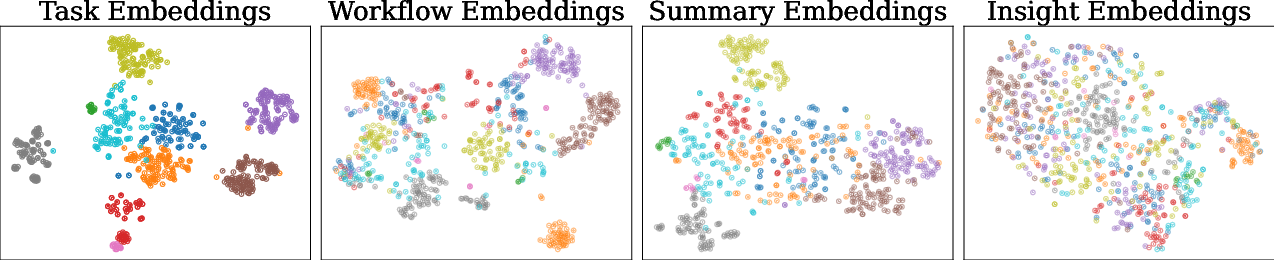
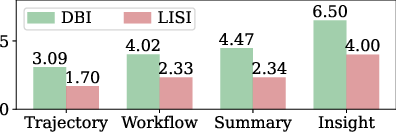
- Davies–Bouldin Index (DBI): A clustering metric that quantifies the separation and compactness of clusters. "In addition, memory embedding distributions are quantitatively characterized using the DaviesâBouldin Index (DBI) and the Local Inverse Simpsonâs Index (LISI)"
- Domain routing: A retrieval/adaptation strategy that routes queries to domain-appropriate memory sources. "such as domain routing~\cite{universalrag} and step-wise memory retrieval~\cite{reme}"
- Domain-mismatched anchoring: A negative transfer failure mode where superficially similar but irrelevant memories mislead reasoning. "Domain-mismatched anchoring: Structurally irrelevant but superficially similar memories act as misleading anchors."
- Embedding features: Vector representations of text used to index and retrieve memories. "we index each memory by extracting embedding features using a textual embedding model"
- Embedding similarity: Similarity computed between embedding vectors for retrieval ranking. "we retrieve 20 candidate memories based on embedding similarity and then prompt the LLM to select the three most helpful ones for the given task."
- Guardrails: Constraints and checks that enforce compliance with external requirements during agent operations. "guardrails for compliance with external constraints (such as output formats, function signatures, and API contracts)"
- Heterogeneous domains: Diverse task areas or benchmarks differing in environment, goals, or data. "a unified memory pool from heterogeneous domains."
- In-context learning: A non-parametric mechanism where models reuse knowledge provided in the input context at inference time. "In-context learning~\cite{icl_survey, rethinking_icl, videoicl}, as a representative paradigm, shows that LLMs can reuse knowledge provided in the context at inference time."
- Insight memory: A high-level, abstract memory format containing generalizable procedural insights. "we employ the Insight memory format."
- Local Inverse Simpson’s Index (LISI): A metric capturing local mixing across labels or domains in embedding spaces. "In addition, memory embedding distributions are quantitatively characterized using the DaviesâBouldin Index (DBI) and the Local Inverse Simpsonâs Index (LISI)"
- Memory pool: A collection of stored memories used for retrieval across tasks. "we construct the heterogeneous-domain memory pool to experiment memory transfer learning."
- Memory rewriting: Modifying retrieved memory items to better fit the target task or context. "designing advanced memory retrieval methods that retrieve truly helpful memories not semantically relevant items, and employ better memory adaptation methods, such as memory rewriting module~\cite{reme}."
- Memory Transfer Learning (MTL): Leveraging memories from source tasks/domains to improve performance on target tasks. "We investigate Memory Transfer Learning (MTL) by harnessing a unified memory pool from heterogeneous domains."
- Meta-knowledge: General procedural or operational know-how transferable across tasks and domains. "primarily by transferring meta-knowledge, such as validation routines, rather than task-specific code."
- Model-agnostic: Independent of the specific model; applicable across different models. "These findings support our hypothesis that meta-knowledge is transferable across models because it is model-agnostic."
- Negative transfer: A transfer effect where using prior knowledge degrades performance on a new task. "low-level traces often induce negative transfer due to excessive specificity."
- Non-parametric knowledge transfer: Transfer mechanisms that do not update model parameters, relying instead on external context/memory. "recent work has increasingly explored non-parametric knowledge transfer mechanisms."
- Parametric adaptation: Transfer via updating model parameters to adapt knowledge to a new domain. "Traditional approaches mainly rely on parametric adaptation through model updates"
- Pass@1: A metric reporting success probability when evaluating a single attempt per task. "Cross-Model Memory Transfer Average Pass@1 results show consistent gains over zero-shot across different model pairs."
- Pass@3: A metric reporting success when up to three attempts per task are considered. "We report Pass@3 scores across multiple benchmarks."
- Reranking: Selecting the most relevant memories from initial candidates by ranking them with additional signals. "For reranking, we first retrieve 20 candidate memories based on embedding similarity and then prompt the LLM to select the three most helpful ones for the given task."
- Step-wise memory retrieval: Retrieving and using memory iteratively across the steps of an agent’s interaction. "such as domain routing~\cite{universalrag} and step-wise memory retrieval~\cite{reme}"
- Summary memory: A memory format capturing a concise description of the task, actions, results, and analysis. "which is represented as for Summary memory ."
- Test-time scaling: Improving performance by leveraging additional computation or memory at inference time. "ReasoningBank~\cite{reasoningbank} extracts helpful insights from trajectories via test-time scaling."
- Top-N sampling: Selecting the N highest-ranked items (e.g., memories) based on a similarity score. "Finally, we select the final retrieved memories by top- sampling with the highest similarity scores."
- Trajectory memory: A low-level memory format consisting of action and observation sequences from prior runs. "Trajectory memory can defined as ."
- t-SNE: A dimensionality reduction technique used to visualize high-dimensional embeddings. "t-SNE Visualization of Memory Formats."
- Unified memory pool: A combined repository of memories from multiple domains for cross-task transfer. "We investigate Memory Transfer Learning (MTL) by harnessing a unified memory pool from heterogeneous domains."
- Workflow memory: A memory format that captures reusable, distilled sequences of actions toward a goal. "Therefore, workflow memory denotes as $M_W = (g, [a_i, a_j, \ldots, a_k])."
- Zero-shot setting: Evaluating a model/agent without task-specific fine-tuning or prior task-specific examples. "We then evaluate coding agent performance in zero-shot setting and under Memory Transfer Learning."
Collections
Sign up for free to add this paper to one or more collections.

