Memory Sharing for Large Language Model based Agents
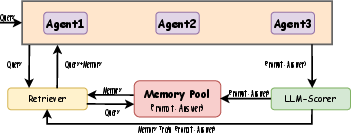
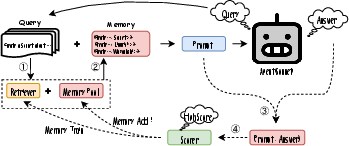
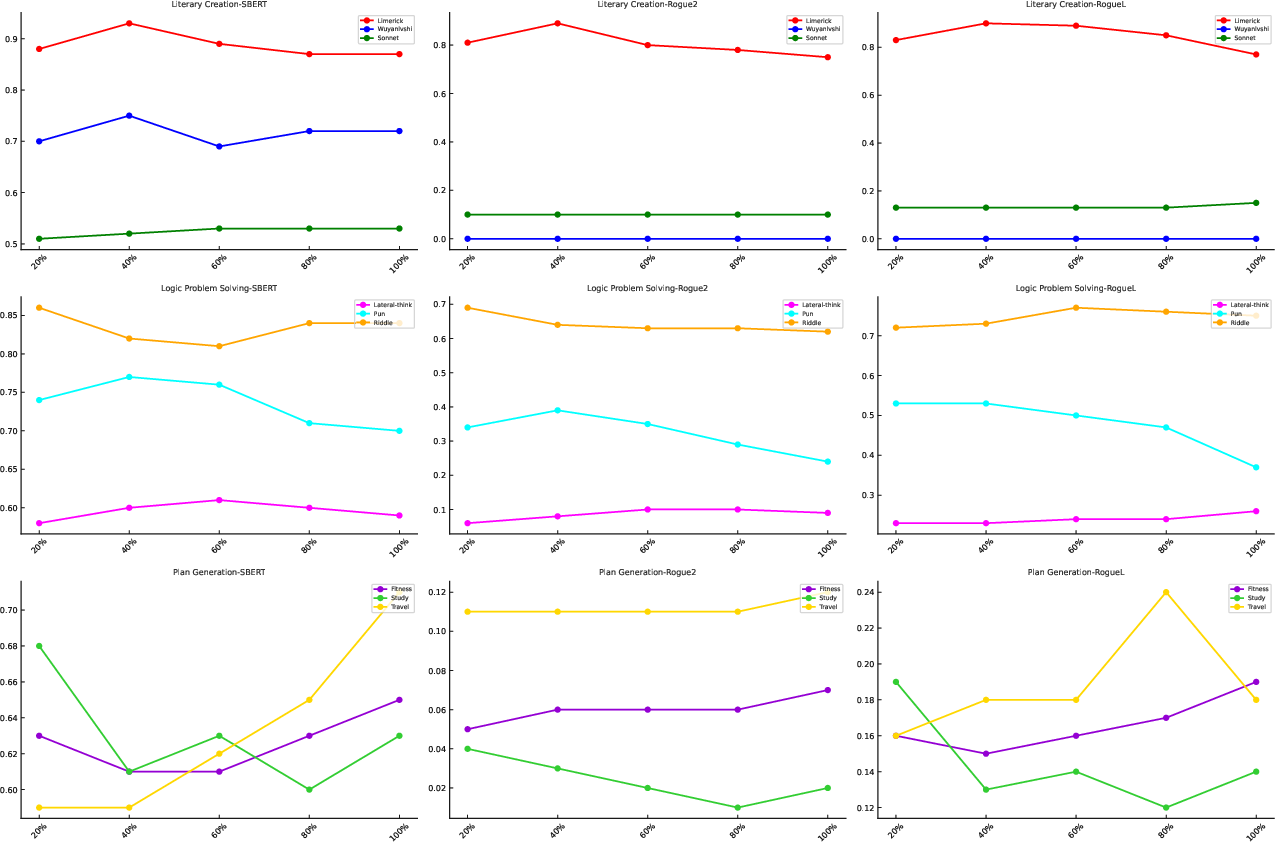
Abstract: The adaptation of LLM-based agents to execute tasks via natural language prompts represents a significant advancement, notably eliminating the need for explicit retraining or fine tuning, but are constrained by the comprehensiveness and diversity of the provided examples, leading to outputs that often diverge significantly from expected results, especially when it comes to the open-ended questions. This paper introduces the Memory Sharing, a framework which integrates the real-time memory filter, storage and retrieval to enhance the In-Context Learning process. This framework allows for the sharing of memories among multiple agents, whereby the interactions and shared memories between different agents effectively enhance the diversity of the memories. The collective self-enhancement through interactive learning among multiple agents facilitates the evolution from individual intelligence to collective intelligence. Besides, the dynamically growing memory pool is utilized not only to improve the quality of responses but also to train and enhance the retriever. We evaluated our framework across three distinct domains involving specialized tasks of agents. The experimental results demonstrate that the MS framework significantly improves the agents' performance in addressing open-ended questions.
- Few-shot training llms for project-specific code-summarization. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, pp. 1–5, 2022.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Pal: Program-aided language models. In International Conference on Machine Learning, pp. 10764–10799. PMLR, 2023.
- Solving math word problems by combining language models with symbolic solvers. arXiv preprint arXiv:2304.09102, 2023.
- Atlas: Few-shot learning with retrieval augmented language models. arXiv preprint arXiv:2208.03299, 2022.
- Can language models learn from explanations in context? arXiv preprint arXiv:2204.02329, 2022.
- The inductive bias of in-context learning: Rethinking pretraining example design. arXiv preprint arXiv:2110.04541, 2021.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pp. 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/W04-1013.
- What makes good in-context examples for GPT-3? In Eneko Agirre, Marianna Apidianaki, and Ivan Vulić (eds.), Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, pp. 100–114, Dublin, Ireland and Online, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.deelio-1.10. URL https://aclanthology.org/2022.deelio-1.10.
- Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35, 2023.
- Dr. icl: Demonstration-retrieved in-context learning. arXiv preprint arXiv:2305.14128, 2023.
- Generation-augmented retrieval for open-domain question answering. arXiv preprint arXiv:2009.08553, 2020.
- Cross-task generalization via natural language crowdsourcing instructions. arXiv preprint arXiv:2104.08773, 2021.
- In-context retrieval-augmented language models. Transactions of the Association for Computational Linguistics, 11:1316–1331, 2023.
- Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084, 2019.
- Learning to retrieve prompts for in-context learning. arXiv preprint arXiv:2112.08633, 2021.
- Replug: Retrieval-augmented black-box language models. arXiv preprint arXiv:2301.12652, 2023.
- Story centaur: Large language model few shot learning as a creative writing tool. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, pp. 244–256, 2021.
- Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023a.
- Learning to retrieve in-context examples for large language models. arXiv preprint arXiv:2307.07164, 2023b.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- A prompt pattern catalog to enhance prompt engineering with chatgpt. arXiv preprint arXiv:2302.11382, 2023.
- Reframing human-ai collaboration for generating free-text explanations. arXiv preprint arXiv:2112.08674, 2021.
- Ai chains: Transparent and controllable human-ai interaction by chaining large language model prompts. In Proceedings of the 2022 CHI conference on human factors in computing systems, pp. 1–22, 2022.
- Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=SkeHuCVFDr.
- Large language models are human-level prompt engineers. arXiv preprint arXiv:2211.01910, 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

