MemCollab: Cross-Agent Memory Collaboration via Contrastive Trajectory Distillation
Abstract: LLM-based agents rely on memory mechanisms to reuse knowledge from past problem-solving experiences. Existing approaches typically construct memory in a per-agent manner, tightly coupling stored knowledge to a single model's reasoning style. In modern deployments with heterogeneous agents, a natural question arises: can a single memory system be shared across different models? We found that naively transferring memory between agents often degrades performance, as such memory entangles task-relevant knowledge with agent-specific biases. To address this challenge, we propose MemCollab, a collaborative memory framework that constructs agent-agnostic memory by contrasting reasoning trajectories generated by different agents on the same task. This contrastive process distills abstract reasoning constraints that capture shared task-level invariants while suppressing agent-specific artifacts. We further introduce a task-aware retrieval mechanism that conditions memory access on task category, ensuring that only relevant constraints are used at inference time. Experiments on mathematical reasoning and code generation benchmarks demonstrate that MemCollab consistently improves both accuracy and inference-time efficiency across diverse agents, including cross-modal-family settings. Our results show that the collaboratively constructed memory can function as a shared reasoning resource for diverse LLM-based agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Imagine several smart “AI students” (computer programs powered by LLMs) solving math and coding problems. Each one keeps a notebook of tips learned from past problems. The catch: each notebook is written in that student’s personal style, so when another student tries to use it, it often doesn’t help—and can even confuse them.
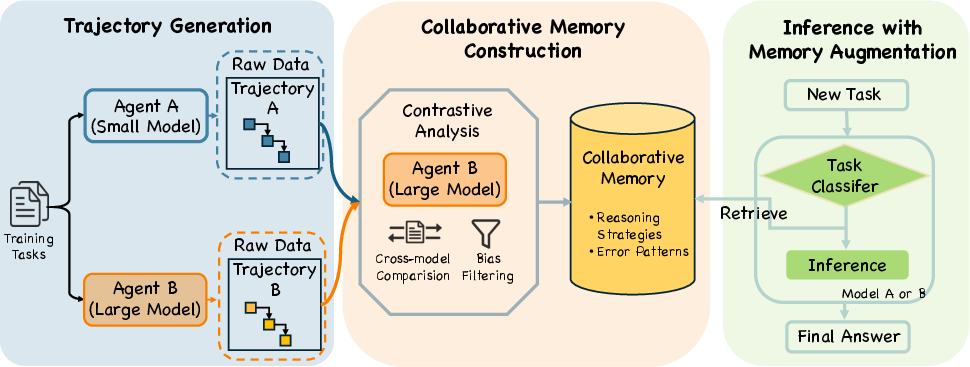
This paper introduces MemCollab, a way to build a single, shared “notebook” that any of these AI students can use. It does this by comparing how different AIs solved (or failed at) the same problem and writing down the common, reliable rules that led to success—while filtering out personal quirks.
The main questions the paper asks
- Can one shared memory (a set of reusable tips and rules) help many different AI agents, even if they’re different sizes or from different model families?
- Why does simply copying one agent’s memory to another usually fail?
- Can we build a better, more general memory by comparing correct and incorrect solution paths from different agents?
- Does this shared memory make AIs both more accurate and more efficient (fewer trial-and-error steps)?
How the approach works (explained with everyday analogies)
First, some quick, friendly definitions:
- Agent: an AI “student” that solves tasks (like math or coding).
- Trajectory: the step‑by‑step reasoning path an agent follows to get an answer (like a worked solution).
- Contrastive: comparing a good example and a bad example side by side to spot the difference.
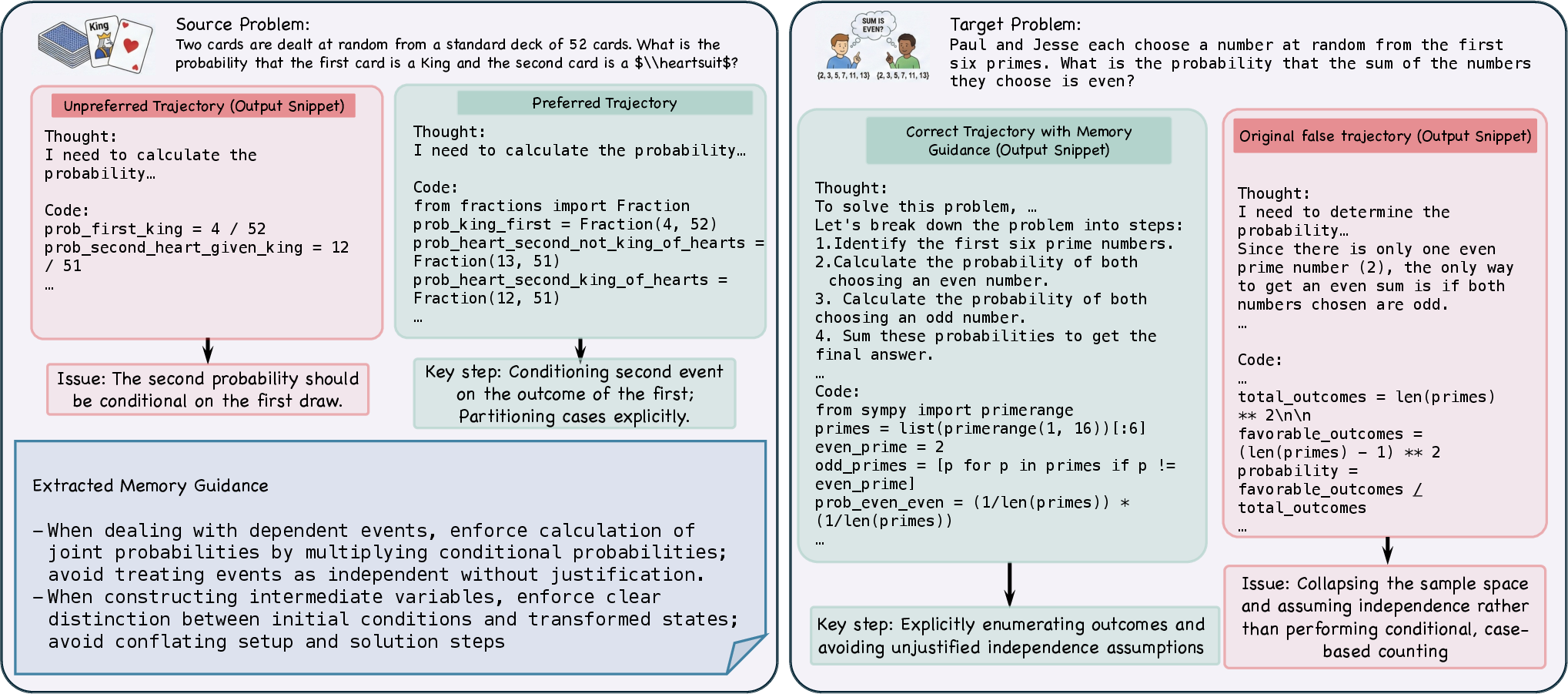
- Invariants: rules or ideas that stay useful across many problems (e.g., “check all cases in a counting problem”).
- Violations: common mistakes to avoid (e.g., “don’t assume independence in probability when events depend on each other”).
Think “spot-the-difference” puzzles or a study group:
- Two different AI students try the same problem. One gets it right; the other gets it wrong.
- MemCollab compares their solution paths to identify:
- What the right solution did that made it work (the invariant).
- What mistake the wrong solution made (the violation).
- It stores this as a compact rule like: “Enforce careful case analysis; avoid assuming independence.”
Then, it files each rule under a task category (e.g., algebra, counting, probability), like organizing a shared study notebook by subject, so it’s easy to fetch relevant tips later.
At test time:
- When a new problem arrives, MemCollab first guesses the problem’s category.
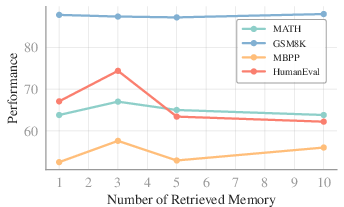
- It retrieves a small number of the most relevant rules from that category (usually about three—enough to help, not overwhelm).
- The agent uses these rules as gentle guidance while solving, reducing common mistakes and wasted steps.
In short, instead of copying one student’s style, MemCollab extracts the shared “classroom rules” that help everyone.
What the researchers did to test it
They tried MemCollab on:
- Math problems: MATH500 and GSM8K
- Coding tasks: MBPP and HumanEval
They used different AI agents:
- Smaller and larger models from the same family (Qwen2.5-7B and Qwen2.5-32B)
- Models from different families (like Llama-3-8B and Qwen2.5-32B) to see if sharing works across “schools”
They compared:
- No memory (vanilla)
- Existing memory methods (Buffer of Thoughts, Dynamic Cheatsheet)
- Naively transferring one model’s memory to another
- Self-contrast (comparing multiple attempts by the same model)
- MemCollab (contrast across different agents)
The main findings and why they matter
- Naively transferring memory hurts: Simply giving one model’s notes to another often made things worse. That’s because those notes include personal styles and habits that don’t transfer well.
- Contrast across agents works best: MemCollab, which compares a correct and an incorrect solution from different agents, produced general rules that improved accuracy across the board.
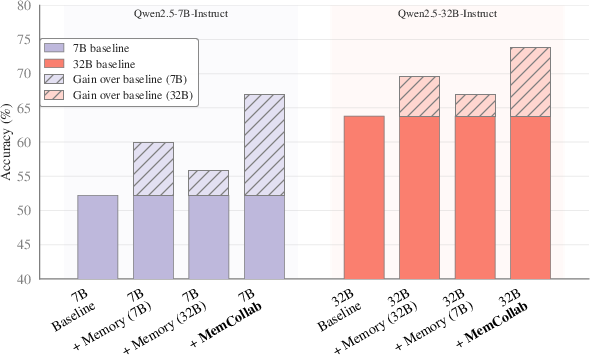
- Example: On a smaller math model (Qwen2.5-7B), accuracy on MATH500 jumped from about 52% to 67% with MemCollab. Coding accuracy also rose (e.g., MBPP from ~48% to ~58%).
- Larger models improved too, not just smaller ones. On Qwen2.5-32B, MemCollab reached top scores across several benchmarks.
- Even across different model families (like Llama3-8B), MemCollab delivered big gains (e.g., MATH500 from ~27% to ~42%).
- Faster problem solving: With MemCollab, agents needed fewer “reasoning turns” (less back-and-forth trial-and-error) to reach correct answers.
- Task-aware retrieval is key: Fetching rules from the right topic area (e.g., probability vs algebra) worked better than generic similarity searches.
- Less is more: Using a small number of retrieved rules (about three) helped most; adding too many rules added noise and hurt performance.
Why this is important: It shows how to build a “shared brain” of reusable reasoning tips that different AI systems can rely on—making them both smarter and more efficient.
What this could change in the future
- Shared memory for many AIs: As more apps use multiple AI agents together (for routing, specialization, or teamwork), a single, clean, shared memory can save time and compute while boosting quality.
- Fewer repeated mistakes: By writing down and reusing “what to do” and “what not to do,” systems can avoid relearning the same lessons over and over.
- General, not personal: The focus on universal rules (not model-specific styles) suggests better transfer across new models and tasks.
- Scalable teamwork: The method could extend from pairs of agents to larger groups, building even richer shared knowledge for reasoning.
In short, MemCollab turns mixed agent experiences into a clean, shared set of do’s and don’ts that any agent can use—much like a well-organized class study guide that helps every student, not just the one who wrote it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper.
- Dependence on verifiability: The method requires an indicator/verifier to label preferred vs. unpreferred trajectories. How does MemCollab apply to tasks without reliable ground truth or executable checks (e.g., open-ended QA, dialogue, planning, safety-critical decisions)?
- Both-correct/both-wrong cases: The paper does not specify how memory is constructed when both agents are correct (no contrast) or both are wrong (contrast may encode wrong “invariants”). What policies should govern inclusion, rejection, or adjudication in these scenarios?
- Indicator model reliability: Sensitivity to errors in the correctness indicator is unquantified. How robust is memory quality to false positives/negatives in the verifier?
- Summarizer dependence and hallucination: Memory is distilled using a specific backbone LLM. How does the choice and quality of the summarizer affect the fidelity of extracted constraints, and what safeguards prevent hallucinated or overspecified “invariants”?
- Generalization beyond math/code: Evaluation is limited to math and code benchmarks. Does the approach transfer to open-domain QA, long-form reasoning, multi-hop retrieval, planning, tool-using web agents, robotics, or multimodal tasks?
- Cross-lingual transfer: The method’s effectiveness across languages (and mixed-language prompts/code) is untested. How should categories and constraints be adapted for multilingual settings?
- Retrieval misclassification: Task-aware retrieval relies on LLM-based category classification. What is the impact of misclassification on performance, and can learned classifiers or hybrid routing (category + dense retrieval) reduce errors?
- Retrieval ranking specifics: The “Top-p” ranking mechanism within categories is not fully specified or compared (e.g., embedding models, learned retrievers, cross-encoders). Which ranking strategies yield the best precision/recall trade-offs?
- Category design and granularity: The taxonomy used for task categories/subcategories is LLM-derived and static. What is the optimal granularity, and should categories be learned/hierarchical or dynamically refined during deployment?
- Hyperparameter sensitivity: The paper sets K (constraints per task) and p (retrieved entries) empirically. How sensitive is performance to these choices, and can automatic tuning or adaptive budgets improve robustness?
- Memory growth and maintenance: There is no policy for deduplication, consolidation, conflict resolution, versioning, or pruning as the memory bank scales. How to control memory bloat and prevent contradictory or stale guidance?
- Continual learning and drift: The framework is evaluated in an offline setting. How to update memory online under domain shift, tool/API changes, or evolving error patterns without catastrophic interference?
- Multi-agent scaling: MemCollab is instantiated with two agents. How should contrast be generalized to many agents (e.g., multi-contrast aggregation, weighting by trust/competence, consensus strategies), and what are the computational costs?
- Adversarial/poisoned agents: The method assumes honest agents. What defenses prevent a malicious or faulty agent from injecting misleading constraints (e.g., trust scores, anomaly detection, cross-agent voting)?
- Error propagation from “strong” agents: If the stronger agent is systematically wrong in a subset of cases, how to detect and prevent erroneous “invariants” from being canonized into memory?
- Negative transfer and over-constraining: Abstract constraints may overfit to certain categories or suppress valid alternative strategies. How to detect and mitigate negative transfer or over-constraining that harms exploration/creativity?
- Quantifying “abstraction”: The paper claims constraints are abstract and agent-agnostic, but provides no metric for abstraction level or transferability. How to measure and optimize the generality vs. specificity of constraints?
- Efficiency accounting: Inference-time “turns” are reduced, but end-to-end costs (tokens, latency, memory retriever overhead) and amortized build-time costs (dual-agent runs, summarization) are not reported. What is the net cost-benefit?
- Data/sample efficiency: The number of tasks and trajectory pairs needed to achieve gains is not studied. What are learning curves for memory size vs. performance, and how does coverage across categories affect returns?
- Interaction with other reasoning techniques: Synergy or interference with CoT variants, self-consistency, debate, or tool-augmented planning is not explored. Can combining MemCollab with these methods yield additive gains?
- Tool-usage generality: “Tool feedback” is primarily code execution. How to model, extract, and transfer tool-usage invariants for heterogeneous tools (web search, APIs, calculators, planners) and handle tool evolution?
- Robustness to retrieval noise: The paper shows a non-monotonic effect of p but does not analyze robustness to noisy or weakly relevant entries. Can confidence-weighted selection or filtering improve stability?
- Formal guarantees: Theoretical analysis is largely intuitive. Under what conditions does contrast reliably suppress agent-specific bias and recover task-relevant invariants, and can information-theoretic or PAC-style guarantees be established?
- Evaluation breadth and rigor: Results are shown on four benchmarks with limited architectural diversity. Broader tests (more agents, frontier models, small models, different training regimes) and statistical significance analyses are needed.
- Human validation of constraints: There is no assessment of constraint correctness/utility by human experts. Can human-in-the-loop auditing improve memory quality and safety?
- Safety, privacy, and leakage: While the paper claims abstract constraints mitigate privacy risks, there is no empirical analysis of potential leakage or safety amplification (e.g., reinforcing biased/harmful patterns). How to audit and enforce safety constraints?
- Reproducibility and release: Complete prompts, code, and memory artifacts are not detailed in the main text. Releasing these would enable replication and independent assessment of constraint quality.
Practical Applications
Immediate Applications
Below are near-term, deployable applications that leverage MemCollab’s core ideas (contrastive trajectory distillation and task-aware retrieval) with today’s LLM agents and infrastructure.
- Sector: Software Engineering (DevEx, DevOps, CI/CD)
- Use case: Repository-aware, cross-agent coding memory that encodes “do/avoid” patterns (e.g., dependency initialization order, test setup invariants, security linting gotchas).
- Product/workflow:
- CI plugin “MemCollab for CI” that ingests codegen attempts, unit-test failures, and code-review feedback from multiple code assistants to build a shared “normative constraints + anti-patterns” memory per repo or service.
- IDE extension retrieves top-k constraints by task category (e.g., parsing, I/O, concurrency) and injects them into code generation prompts.
- Assumptions/dependencies: Access to multi-agent trajectories and test oracles; permission to log/model outputs; task taxonomy for code tasks; governance to avoid leaking secrets; model/version drift monitoring.
- Sector: Customer Support and CX Automation
- Use case: Shared “escalation and compliance” memory across diverse chatbots that captures intent-specific invariants (verify identity before action) and forbids failure modes (hallucinating refund policy).
- Product/workflow:
- “Contrastive QA Memory” that distills patterns from correct vs. incorrect resolutions across multiple bots/vendors and routes retrieval by intent category.
- Middleware that enforces retrieved constraints before final response.
- Assumptions/dependencies: Clear ground truth or verifier (policy base, CRM state); robust intent classification; privacy controls to store abstract guidance not raw PII; red-teaming for jailbreak patterns.
- Sector: RAG and Knowledge Assistants (Enterprise Search, Analytics)
- Use case: Reasoning-oriented RAG: retrieve normative constraints (how to reason) alongside factual passages (what to know) to reduce distraction and tool-misuse.
- Product/workflow:
- “Reasoning Cheatsheet Index” integrated with LlamaIndex/LangChain; task-aware filter (topic + task type) before dense similarity ranking.
- Assumptions/dependencies: Existing RAG stack; task classifier quality; cost budget for memory retrieval tokens; curator loop to remove stale constraints.
- Sector: AI Safety and Governance
- Use case: Cross-model “safety memory firewall” that encodes forbidden failure patterns (prompt injection, PII leakage, unsafe medical/legal advice) distilled by contrasting safe vs. unsafe trajectories from multiple models.
- Product/workflow:
- Interceptor service between model and user that retrieves safety constraints by scenario category and vetoes or rewrites responses violating them.
- Assumptions/dependencies: Safety taxonomy; evaluators/heuristics for correctness of safety labels; defenses against memory poisoning; audit logging.
- Sector: Education and EdTech
- Use case: Tutor agents share topic-specific solution invariants (e.g., probability requires conditional enumeration; algebra requires variable isolation) and avoid common student and model errors.
- Product/workflow:
- “Tutor Memory Pack” per curriculum unit; LMS plugin retrieves constraints by topic/skill and guides hints, step checking, and worked examples.
- Assumptions/dependencies: Alignment to curriculum standards; ground-truth checkers (symbolic math, unit tests); age-appropriate safety layers.
- Sector: MLOps and Evaluation
- Use case: Shared “reasoning playbooks” for internal agent ecosystems to cut inference turns and costs while improving accuracy on structured tasks.
- Product/workflow:
- Memory service API exposing SubmitTrajectories/BuildMemory/RetrieveConstraints; dashboards for memory coverage by task category, retrieval hit-rate, and win-rate deltas.
- Assumptions/dependencies: Multiple agents (sizes/vendors) active on same task set; acceptance of abstract memory over demos; KPIs for accuracy vs. token cost and latency.
- Sector: Business Operations and RPA
- Use case: Tool-using agents share invariant steps (e.g., validate schema before transform; reconcile ledger before close) and forbidden actions (posting without approval) per workflow category.
- Product/workflow:
- “Auto-Playbook Generator” that distills constraints from successful vs. failed runs and injects them into orchestrations (Camunda/Temporal).
- Assumptions/dependencies: Instrumented tools with feedback; verifiers (checks, reconciliation); role-based access; change management to update constraints as processes evolve.
- Sector: Research (NLP/AI)
- Use case: Benchmark augmentation with contrastive memory to study cross-model transfer of reasoning constraints; reproducible protocols for multi-agent collaboration.
- Product/workflow:
- Open memory banks per dataset/category; evaluation harness comparing vanilla vs. memory-guided inference-time efficiency (#turns, tokens).
- Assumptions/dependencies: Public datasets with verifiers; standardized prompts; careful license compliance for model outputs.
- Sector: Content Moderation and Policy Enforcement
- Use case: Shared memory of enforcement invariants (e.g., protected classes rules, contextual disambiguation) and typical misclassifications across model families.
- Product/workflow:
- “Policy Memory Router” that retrieves constraints by policy category before moderation decision.
- Assumptions/dependencies: Gold or adjudicated labels; drift monitoring; explainability requirements for audits.
- Daily Life (Personal Productivity)
- Use case: Cross-app assistants share task rules of thumb (e.g., budgeting requires after-tax cashflow; trip planning requires visa/season checks) and forbid typical mistakes (double-booking, hidden fees).
- Product/workflow:
- On-device or account-scoped memory of abstract constraints retrieved by task type (finance, travel, scheduling) when planning or summarizing.
- Assumptions/dependencies: Strong privacy—store abstractions only; lightweight classification; user override controls.
Long-Term Applications
These applications are high-impact but require additional research, domain validation, scaling, or tighter safety/compliance frameworks before deployment.
- Sector: Healthcare (Clinical Decision Support)
- Use case: Shared diagnostic/treatment reasoning invariants across clinical agents (differential diagnosis ordering, contraindication checks) and forbidden patterns (anchoring bias, ignoring comorbidities).
- Potential tools/workflows:
- “Clinical Reasoning Memory” integrated with EHR CDS systems; retrieval conditioned on specialty and complaint category.
- Assumptions/dependencies: Rigorous clinical validation; liability management; regulated data handling; high-precision task classification; human-in-the-loop oversight; certified verifiers.
- Sector: Finance (Risk, Trading, Compliance)
- Use case: Cross-agent constraints for model risk management, stress testing, and reporting (e.g., IFRS/GAAP invariants, market data sanity checks) with forbidden error modes (look-ahead bias, incomplete exposure nets).
- Potential tools/workflows:
- “Compliance Memory Layer” that gates LLM-generated analyses and narratives; audit trails tying retrieved constraints to decisions.
- Assumptions/dependencies: Regulatory acceptance; robust verifiers; adversarial resilience; governance for model updates and memory provenance.
- Sector: Law and Public Policy
- Use case: Shared legal reasoning templates and forbidden practices (unauthorized practice, citation hallucination) across drafting/review agents.
- Potential tools/workflows:
- “Precedent-Constrained Drafting” memory keyed by jurisdiction/matter type, plugged into contract automation suites.
- Assumptions/dependencies: Jurisdiction-specific task taxonomies; expert curation; explainability; risk and privilege controls.
- Sector: Robotics and Embodied AI
- Use case: Cross-planner memory encoding task-order invariants (grasp-before-transport) and forbidden failure modes (unsafe reach, occlusion) across heterogeneous policies.
- Potential tools/workflows:
- “Embodied Contrastive Memory” retrieved by task family (assembly, navigation, manipulation) to guide hybrid LLM–planner stacks.
- Assumptions/dependencies: Reliable simulators/real-world verifiers; multi-modal trajectories; safety certification; sim-to-real transfer research.
- Sector: Scientific Discovery and Data Analysis
- Use case: Agents share domain-specific analysis invariants (statistical controls, unit/scale conversions, causal identification checks) and avoid pitfalls (p-hacking, data leakage).
- Potential tools/workflows:
- “Lab Notebook Memory” keyed by study design; notebook agents retrieve constraints before running analyses.
- Assumptions/dependencies: Domain-expert verification; provenance and reproducibility standards; integration with ELN/LIMS.
- Sector: Cross-Organization/Vendor Memory Ecosystems
- Use case: Standardized, privacy-preserving interchange of abstract reasoning constraints across vendors and agencies to raise baseline safety and reliability.
- Potential tools/workflows:
- Open schema for “normative constraint + forbidden pattern” entries; attestations and cryptographic provenance; federated memory construction.
- Assumptions/dependencies: Standards bodies; legal frameworks for shared artifacts; robust defenses against poisoning; interop across taxonomies.
- Sector: Agentic Infrastructure at Scale
- Use case: Auto-curation and continual learning of memory with reinforcement learning signals; dynamic task taxonomy induction; automated memory pruning and versioning.
- Potential tools/workflows:
- “MemoryOps” platform with RL-based store/update/retrieve policies; lineage tracking; quality gates.
- Assumptions/dependencies: Reliable reward/verification signals; budget for continuous training; safeguards against over-constraining creativity.
- Sector: Privacy-Preserving and On-Device Deployment
- Use case: Local construction and retrieval of abstract constraints with secure enclaves or differential privacy for sensitive domains.
- Potential tools/workflows:
- On-device memory compilation; secure multi-party comparison of trajectories for cross-agent contrast without sharing raw data.
- Assumptions/dependencies: Efficient local models; DP/SMPC protocols; hardware support; performance–privacy trade-off studies.
Cross-cutting assumptions and dependencies (impacting feasibility)
- Access to multi-agent trajectories per task and a verifier or reliable proxy for correctness (unit tests, checkers, human adjudication).
- Accurate, stable task classification; misclassification degrades retrieval precision.
- Memory governance: prevent data leakage, ensure abstraction (no raw PII, secrets, or verbatim user content); provenance and versioning.
- Robustness to memory poisoning and distribution shift; continuous evaluation and pruning of stale or harmful constraints.
- Vendor/model heterogeneity support (APIs, formatting, token limits); handling model/version drift and router changes.
- Cost and latency budgets: retrieval adds tokens; benefits must outweigh overhead; optimal top-p often small (≈3).
- Human-in-the-loop review for high-stakes domains; regulatory compliance and auditability requirements.
Glossary
- Agent-agnostic memory: A memory representation designed to be reusable across different agents without encoding model-specific behavior. "constructs agent-agnostic memory by contrasting reasoning trajectories generated by different agents on the same task"
- Agent-specific biases: Model- or agent-dependent preferences and habits that can contaminate transferable knowledge. "such memory entangles task-relevant knowledge with agent-specific biases"
- Agentic linking: Connecting and updating memory elements through agent-driven interactions and structures. "including agentic linking and evolution of memory graphs"
- Auxiliary retriever: An external retrieval component used to fetch relevant information that conditions generation. "conditioning model outputs on passages retrieved by an auxiliary retriever"
- Backbone LLM: The base LLM that instantiates an agent and produces trajectories. "Each agent Ai is instantiated with a base backbone LLM fi"
- Branching factor: The number of alternatives expanded at each step in a search or reasoning process. "let b denote the original branching factor"
- Buffer of Thoughts (BoT): A method that distills reusable thought templates from past reasoning episodes to guide future tasks. "Buffer of Thoughts (BoT)"
- Collaborative memory framework: A system that constructs shared memory by leveraging multiple agents’ trajectories. "we propose MemCollab, a collaborative memory framework"
- Coarse-grained memory representation: A higher-level, less granular memory unit used to reduce noise and overhead in retrieval. "We adopt a coarse-grained memory representation"
- Contrast-Derived Memory Construction: The process of extracting abstract constraints from contrasted trajectory pairs. "Contrast-Derived Memory Construction"
- Contrastive learning: A paradigm that learns salient features by contrasting positive and negative examples. "This intuition aligns with principles from contrastive learning"
- Contrastive memory learning: Building memory by contrasting successful and unsuccessful trajectories to isolate transferable guidance. "benefits multiple agents through contrastive memory learning"
- Contrastive Trajectory Analysis: Comparing trajectories at a structural level to extract invariants and violations. "Contrastive Trajectory Analysis"
- Contrastive Trajectory Distillation: Distilling reusable constraints from contrasted trajectories to form shared memory. "MemCollab: Cross-Agent Memory Collaboration via Contrastive Trajectory Distillation"
- Cross-agent reuse: Applying memory or strategies derived from one agent to others. "limiting the scope of the guidance to cross-agent reuse"
- Cross-architecture contrast: Constructing memory by contrasting trajectories from models with different architectures to suppress model-specific biases. "cross-architecture contrast can potentially expose complementary reasoning patterns"
- Cross-family agent pairs: Agent pairs from different model families used to build more generalizable memory. "By using cross-family agent pairs, MemCollab continues to yield consistent improvements"
- Cross-modal-family settings: Scenarios where agents from different model (modal) families share memory. "including cross-modal-family settings"
- Discrepancy operator: A formal operator that summarizes differences between preferred and unpreferred trajectories. "defined as a discrepancy operator:"
- Dynamic Cheatsheet (DC): A test-time learning approach that maintains an evolving cheatsheet to guide reasoning. "Dynamic Cheatsheet (DC)"
- Episodic memory: Memory that records specific interaction episodes to support later recall. "episodic memory that records interactions and manage multi-tier context"
- Executable verifier: A programmatic checker that validates solutions via execution rather than only comparing text. "ground-truth solution or executable verifier"
- Error-forbidden patterns: Explicitly identified failure patterns that the agent should avoid during reasoning. "error-forbidden patterns"
- Error-type distributions: Statistical distributions over types of errors made within task categories. "error-type distributions"
- Failure modes: Systematic patterns of errors that recur across tasks or models. "cross-model failure modes"
- Fine-grained units: Small retrieval units (e.g., sentences, entities, snippets) used for more precise retrieval. "fine-grained units such as sentences, entities, or code snippets"
- Heterogeneous agents: Agents that differ in size, architecture, or capabilities operating within the same system. "with heterogeneous agents"
- Indicator model: A model or function that determines whether a trajectory is correct with respect to ground truth. "we employ an indicator model I(·)"
- Inference-time efficiency: The effectiveness of solving tasks with fewer steps or less computation during inference. "improves both accuracy and inference-time efficiency"
- Inference-Time Routing: Directing queries to appropriate memory partitions or processes during inference. "Inference-Time Routing"
- Jensen--Shannon divergence (JSD): A symmetric measure of divergence between probability distributions. "Jensen--Shannon divergence (JSD)"
- Long-term interaction memory: Memory that supports continual recall and updates across extended interactions. "long-term interaction memory that supports continual recall and update"
- LLM-based agents: Autonomous agents built around LLMs for multi-step reasoning and tool use. "multiple LLM-based agents"
- Memory bank: The collection of distilled memory entries used for retrieval and guidance. "memory bank"
- Memory graphs: Structured representations of memory where entries are nodes linked by relationships. "memory graphs"
- Memory-Guided Inference: Generating solutions while conditioning on retrieved memory constraints. "Memory-Guided Inference"
- Normative reasoning constraint: An abstract rule that enforces desired reasoning invariants while prohibiting known violations. "normative reasoning constraint"
- Orchestration: Coordinating multiple specialized models or agents within an application workflow. "specialization, orchestration, or routing among models"
- Preferred trajectory: The trajectory judged correct for a task and used as the positive example in contrast. "The preferred and unpreferred trajectories are defined as:"
- Retrieval-augmented generation (RAG): Extending LLMs with retrieved external information to improve outputs. "Retrieval-augmented generation (RAG) extends LLMs with access to external corpora"
- Reasoning invariants: Task-level principles preserved in correct reasoning that generalize across agents. "reasoning invariants"
- Reasoning trajectory: A sequence of intermediate reasoning steps produced while solving a task. "produces a multi-step reasoning trajectory"
- Reinforcement learning: A training paradigm where policies are learned via reward signals over time. "through reinforcement learning"
- Routing among models: Dispatching queries to different models based on their specialization or performance. "routing among models"
- Self-Contrast Memory: Memory built by contrasting multiple trajectories from the same agent. "w/ Self-Contrast Memory"
- Task-aware retrieval mechanism: A retrieval strategy that filters memory by task category before relevance ranking. "task-aware retrieval mechanism"
- Task categorization: Classifying a query into a task category and subcategory to guide retrieval. "Task Categorization."
- Task-level invariants: Shared, abstract constraints that hold across instances of a task category. "task-level invariants"
- Tool feedback: Execution results or signals from tools (e.g., code runners) used within trajectories. "tool feedback"
- Tool-usage errors: Mistakes in invoking or interpreting external tools during reasoning. "tool-usage errors"
- Trajectory pairing: Creating pairs of trajectories for the same task from different agents for contrast. "Trajectory Pairing and Preference Selection."
- Training-based memory management: Learning what to store, update, and retrieve in memory through training signals. "training-based memory management"
- Unpreferred trajectory: The trajectory deemed incorrect and used as the negative example in contrast. "unpreferred trajectory"
Collections
Sign up for free to add this paper to one or more collections.