- The paper demonstrates that integrating Behavior Consistency Reward (BehR) enhances decision preservation by aligning predicted states with agent actions.
- It employs Group Relative Policy Optimization (GRPO) to optimize behavior-level objectives, resulting in robust calibration and reduced false positives in weak agents.
- Empirical results show improved task-level consistency, with a notable increase in Pairwise Consistency Ratio (e.g., from 0.345 to 0.483) in key environments.
Behavior Consistency in Text-Based World Models: Moving Beyond Surface State Similarity
Introduction
Text-based world models (WMs) are increasingly central to enabling LLMs to function as surrogate environments for interactive agents operating in text-rich settings—such as web navigation and text-based games. Most established approaches optimize for state consistency: maximizing token-level or semantic similarity between next-state predictions and ground truth environment responses. However, this paradigm is shown to be insufficient: world models with high textual or semantic overlap can fail to preserve the actual agent behavior due to their inability to capture decision-critical function. This paper proposes a paradigm shift, introducing behavior consistency—a functional criterion—into both the evaluation and training of text-based world models (2604.13824).
Limitations of State Consistency and Metric Inversion
Contemporary WMs are conventionally trained to reconstruct the next environment state with high textual fidelity, leveraging metrics such as Exact Match (EM), BERTScore, or token-level F1. However, these state-level metrics can misalign with agent requirements. For example, a predicted page in a web environment may appear highly similar to the ground-truth page but omit a decision-critical element (e.g., the target product to be purchased). Such a deficiency can have catastrophic downstream effects on agent action space, even as surface metrics remain high. This failure mode—metric inversion—arises when the metric values are not sensitive to functionally crucial omissions or inclusions in next states.
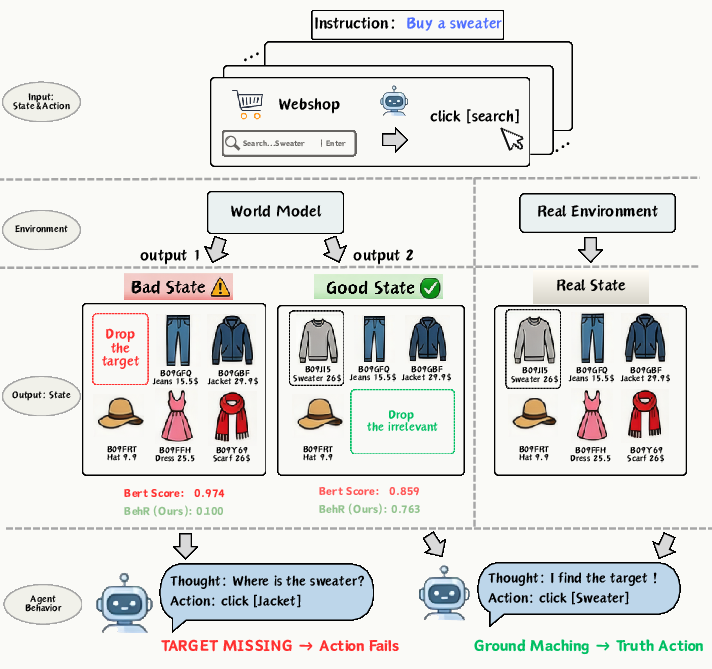
Figure 1: Metric inversion in WebShop—the omission of a decision-critical product results in a catastrophic error that typical surface or semantic metrics do not penalize adequately; only behavior consistency reflects the true impact on agent action space.
Behavior Consistency Reward (BehR) and Training Paradigm
The paper introduces Behavior Consistency Reward (BehR) as a step-level proxy for functional consistency. Rather than scoring the predicted state based on token-level similarity to the reference, BehR evaluates whether the agent is likely to take the same action in the predicted state as in the real state. This is operationalized as follows:
- Reference Agent: A frozen agent model computes, for the logged next action, its log-likelihood under (a) the real state and (b) the predicted world model state.
- BehR: BehR is defined as the negative absolute difference between these two log-likelihoods, thus rewarding predictions that preserve the propensity to execute the correct next action.
Practically, BehR is implementable in offline settings using logged trajectories. It obviates the need for notoriously inaccessible full action distributions for black-box policies. BehR-based models are optimized via Group Relative Policy Optimization (GRPO), a reinforcement learning approach that leverages behavior-level rewards instead of only surface reconstruction signals.
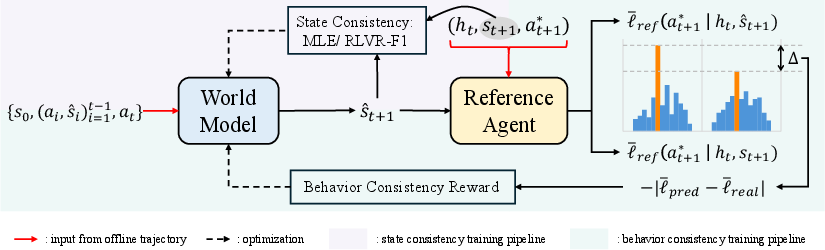
Figure 2: Behavior Consistency Training pipeline—compared to traditional state consistency, the proposed approach aligns world model outputs to agent decision preservation signals derived from a reference agent’s action likelihoods.
Single-Step Prediction
BehR-optimized world models demonstrate parity or improvement in single-step exact match (EM) accuracy in three out of four evaluated settings (WebShop and TextWorld, with both Qwen2.5-7B and LLaMA3.1-8B backbones). This suggests that optimizing for functional consistency does not inherently degrade local next-state prediction quality.
Task-Level Consistency and Functional Evaluation
Task-level evaluation centers on Pairwise Consistency Ratio (CRpw)—the fraction of real-environment successful tasks that remain successful when the same agent trajectory is replayed in the world model and then in the real environment (W2R setting). The strongest numerical gains are observed in WebShop, especially in Qwen-based settings (e.g., CRpw increases from 0.345 to 0.483 for Qwen3-8B). The gains transfer to other domains and model families, albeit with reduced margin in near-ceiling regimes or when underlying agents compensate for modeling deficiencies.
Notably, reward ablation experiments (contrasting BehR to token-level F1 and structured factual rewards) demonstrate that the choice of optimization target substantively impacts long-horizon functional preservation. While all methods improve over SFT baselines, meaningful gains in CRpw are attributable to behavior-level objectives, not merely the reinforcement learning procedure per se.
Downstream Implications: Evaluation Calibration and Planning
Surrogate Evaluation
World models are often used as offline surrogates for agent evaluation owing to the prohibitive cost of real-environment interaction. However, calibration is essential: a poorly calibrated WM can inflate the success of weak agents through false positives. BehR-based WMs reduce false positives by factors of 3–5 for weak agents in TextWorld, raising agreement rates at the task level from ~60% to over 80–90%.
Lookahead Planning
In online planning experiments (WebShop), integrating BehR-optimized WMs yields modest but consistent improvements in agent performance under lookahead planning protocols, compared to both pure SFT and F1-optimized WMs. Most gains derive from the lookahead paradigm itself, with BehR’s contribution being incremental—suggesting higher-fidelity action rollouts but not eliminating the need for strong downstream planning heuristics.
Why Optimization Target Selection is Critical
Control ablations confirm that optimizing for token-level F1 (surface) or structured factual correctness alone fails to consistently preserve decision-critical behavior. While such objectives can improve state-level similarity or factual correctness, only behavior-level alignment (as instantiated by BehR) consistently boosts task-level functional preservation—particularly in regimes where strong downstream policies cannot compensate for world model deficiencies. Optimization target selection, therefore, is not a trivial choice but a primary axis of world model efficacy.
Limitations and Theoretical Implications
BehR leverages only the log-likelihood of a single logged action under a fixed (frozen) reference agent, not the full downstream action distribution. As a practical proxy, its success depends on the relevance of the logged next action and the representativeness of the reference agent. Transferability across diverse agent architectures may be imperfect; gains are most pronounced when baseline world models are miscalibrated or insufficiently functional. Furthermore, improvements taper off near the upper bounds of agent or world model capacity (near-ceiling regimes).
Theoretically, the paradigm refocuses world model evaluation and training from the ill-posed task of linguistic similarity to a criteria focused on agent usability and decision invariance—a shift paralleling similar movements in computer vision (e.g., perceptual metrics for image generation).
Future Directions
Future theoretical and practical research should advance:
- Estimation of fuller action distributions or sampling-based behavior consistency proxies.
- Family-invariant reference judging for robust downstream generalization.
- Integration into multi-agent or open-ended tool-use domains where function preservation is not reducible to a single action’s likelihood.
- Extension to non-textual, multimodal environments and non-Markovian agent policies.
Conclusion
This paper demonstrates that behavior-level functional alignment is essential for effective text-based world modeling. Surface or semantic similarity is necessary but insufficient for preserving agent task performance. The introduction of behavior-consistent training, instantiated via the BehR reward, results in robust improvements on downstream agent-task preservation and evaluation calibration, and offers preliminary benefits for planning. These findings advocate for a reorientation of field-wide objectives in world model research, prioritizing functional consistency over text reconstruction as the principal axis of progress.