- The paper introduces a self-prompted state-tracking mechanism that significantly improves LLM agent efficiency and accuracy.
- It details a chain-of-states method augmenting in-context prompts with explicit goal, state, thought, and action annotations to reduce steps and errors.
- Experimental results on ALFWorld and WebShop validate the approach, achieving state-of-the-art performance over traditional ReAct-based agents.
StateAct: Self-prompted State Tracking for Efficient LLM-based Agents
Introduction and Motivation
The rapid deployment of LLM-based agents for embodied and interactive domains surfaces persistent deficiencies in long-horizon planning, state representation, and task efficiency. Despite impressive generalization in various RL and multimodal environments, LLMs exhibit significant performance drops as tasks extend in length and complexity, largely due to loss of situational awareness and inability to synthesize context across many steps. Existing interventions mostly rely on extensive curated data, tool execution, or engineered rules, incurring high data and computational costs and restricting agent generality. The “StateAct: Enhancing LLM Base Agents via Self-prompting and State-tracking” paper (2410.02810) introduces a minimal but highly effective self-prompted state-tracking mechanism solely within the few-shot in-context learning paradigm. The explicit representation of goals and states, formatted as an iterative “chain-of-states,” demonstrates state-of-the-art (SOTA) efficiency and generalization on challenging benchmarks, significantly outpacing prior LLM-only agents.
Methodology
StateAct rearchitects the LLM-agent decision pipeline by extending in-context prompts with explicit “goal,” “state,” “thought,” and “action” annotations at each turn. This “chain-of-states” provides the LLM with reminders for both high-level objectives and an updated, agent-centric world representation, eliminating the dependence on external tool integration, fine-tuning, or auxiliary training data. The policy at step t is defined as πcontextual(ct∣ot,ct−1,...,c0,o0), where ct aggregates goal, state, chain-of-thought (reasoning), and action for the LLM to autoregressively sample the next decision.
A critical property of StateAct is its minimal annotation cost: efficient reuse of existing ReAct-style traces, simply augmented with goal reminders and precise state/inventory tracking. Experimental pipelines systematically investigate the contributions of state, goal, and thought representations via controlled ablation, as well as the impact of prompt structure and syntactic corrections for domain-specialized action spaces.
Experimental Setup
Evaluations are performed on ALFWorld, a challenging text-based household manipulation environment designed for generalization and long-horizon planning, and WebShop, a real-world scale e-commerce interaction benchmark. Following common protocol, the primary LLM is gpt-3.5-turbo-1106, with supplementary tests on gpt-4o-mini and Mixtral-8x22B to verify model-agnosticism. Comparison baselines include ReAct, ExpeL, AdaPlanner, and tool-augmented and fine-tuned variants from the literature, enabling clear attribution of gains to the StateAct methodological core.
Textual environments offer strong visualization of state–action trajectories, confirming the interpretability and robustness of the StateAct chain-of-states interface.
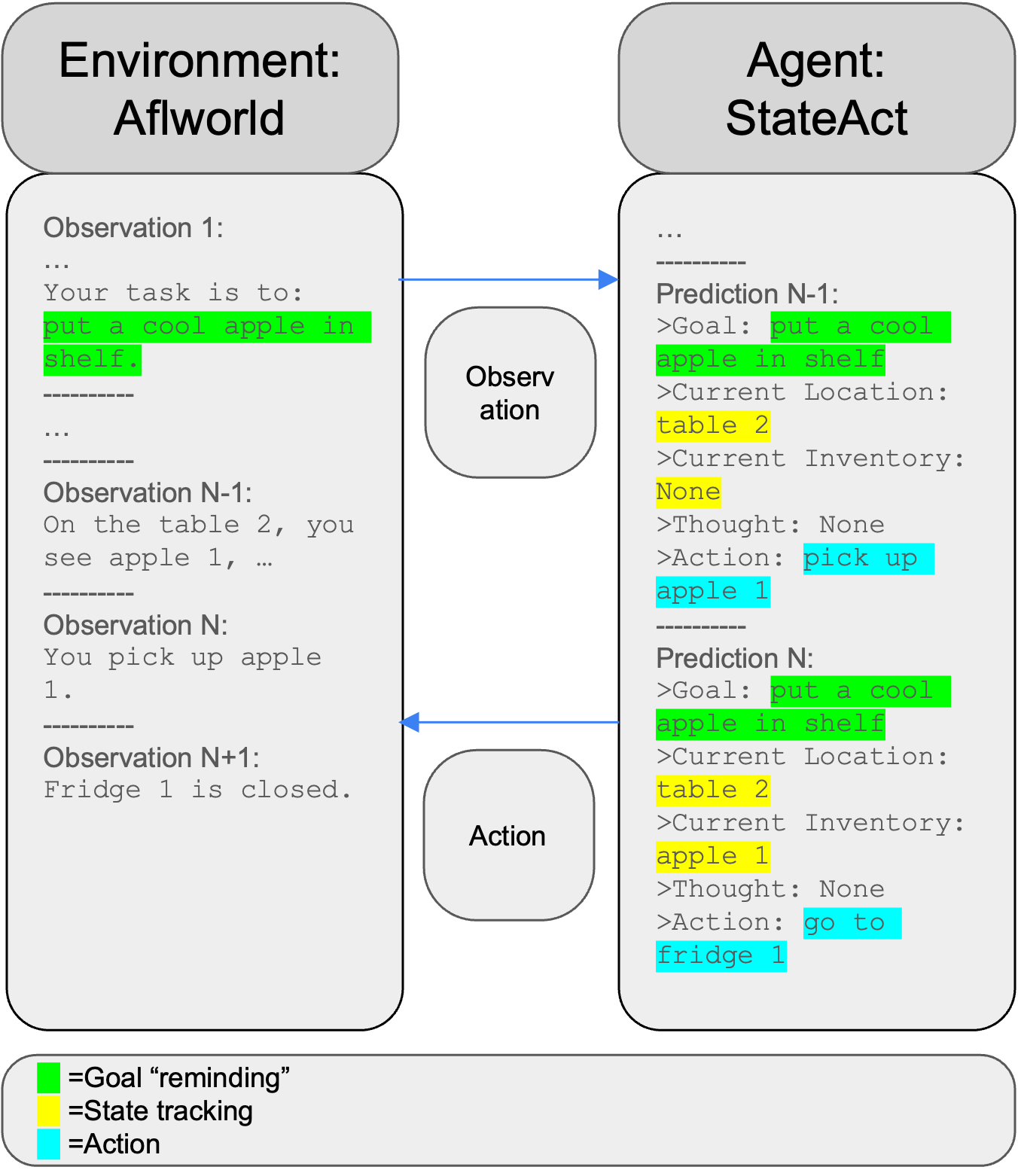
Figure 1: Illustration of StateAct’s stateful reasoning traces in ALFWorld’s partially observable household environment.
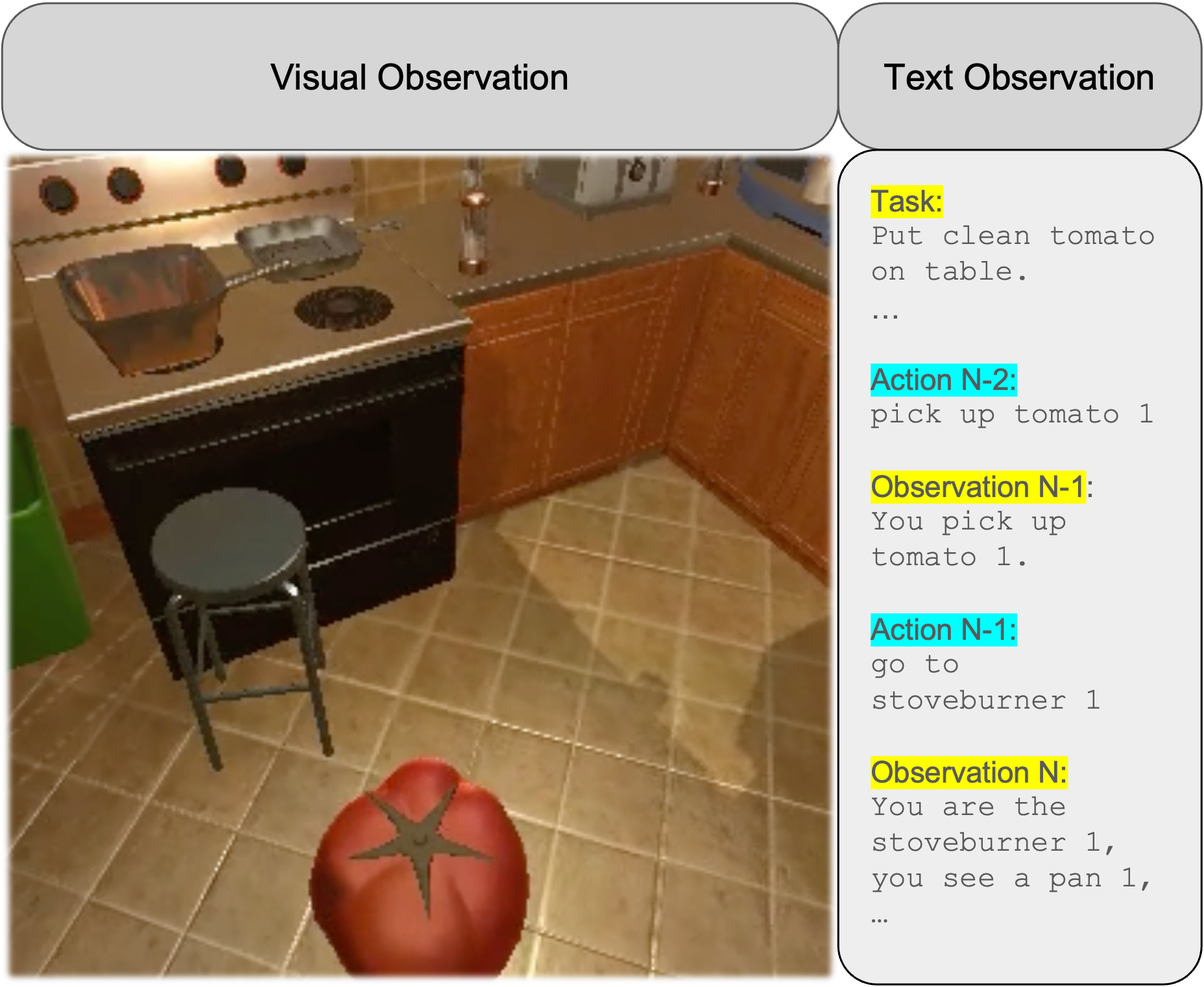
Figure 2: Example agent–environment interaction trace in ALFWorld, with synchronized 3D rendering contextualizing agent actions.
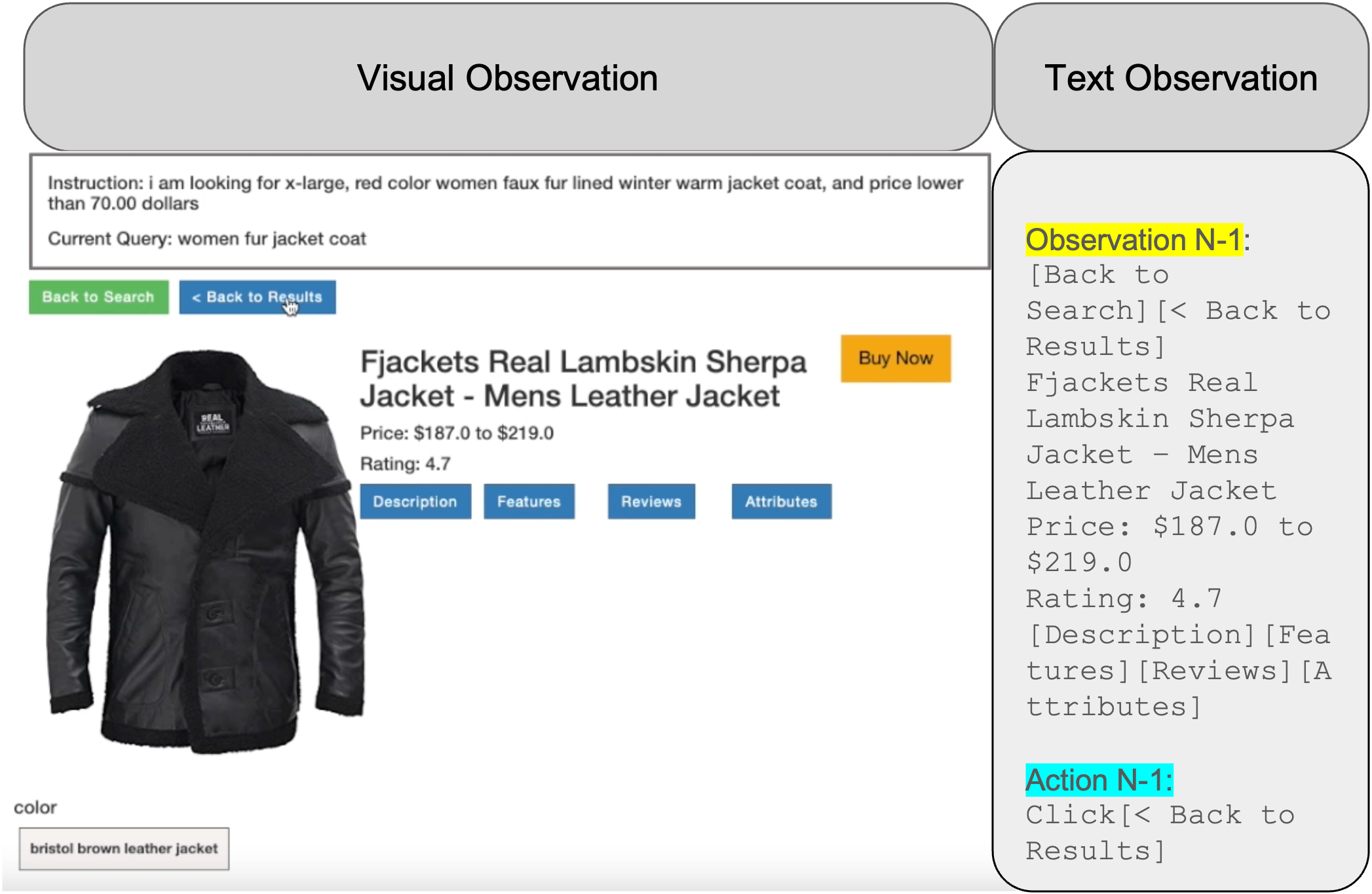
Figure 3: WebShop interaction transcript alongside the grounded web page view, highlighting decision feedback and product selection.
Results
Alfworld
StateAct sets a new SOTA among in-context LLM agents on ALFWorld, with a success rate (SR) of 77.04%, outperforming the previous best in-context approach (ReAct+correction) by +13.34 points. Notably, it surpasses AdaPlanner, which leverages code-execution and regex parsing, by +2.48 points, establishing that purely prompt-based state tracking suffices for maximal LLM utilization in complex domains. The method’s efficiency is evident, with an average step reduction from 38.84 (ReAct, no correction) to 19.11 (StateAct with correction), confirming that task completion is not achieved by lengthening trajectories.
Ablation studies reveal:
- State tracking is the dominant contributor—removing it leads to drops in both accuracy and efficiency.
- Goal reminders enhance both final SR and efficiency, especially as problem horizons lengthen.
- Inclusion of “thoughts” (chain-of-thought outputs) can sometimes degrade performance, especially in environments with rigid command syntax, such as WebShop.
- Introducing rigid JSON formatting into prompts consistently harms SR, indicating that natural, human-readable structures allow LLMs to better map from prior to action compared to artificial serialization schemes.
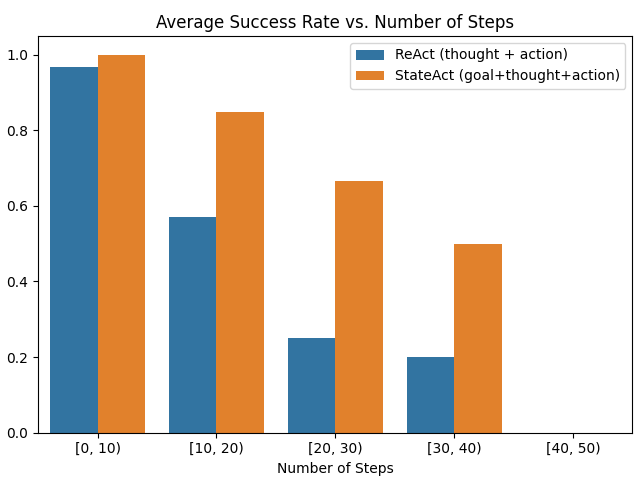
Figure 4: Performance degradation with and without explicit goal reminders as a function of trajectory length in ALFWorld.
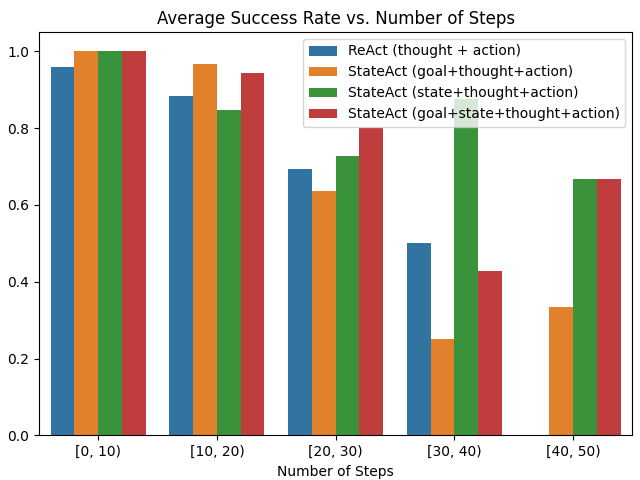
Figure 5: Impact of state tracking on success rate for long-horizon planning in ALFWorld.
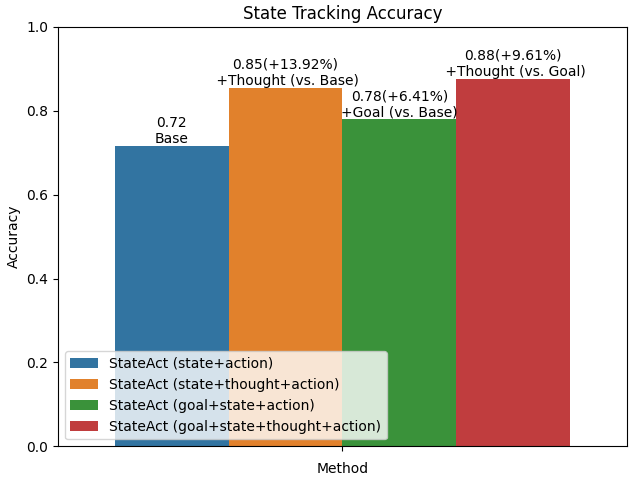
Figure 6: StateAct achieves approximately 88% correct state tracking in ALFWorld, correlating with improved planning success.
WebShop
StateAct outperforms ReAct-style agents on WebShop when “thought” is omitted, reaching 27.8% SR (vs. 17.8% for ReAct), illustrating domain specificity in structural prompt design—verbose reasoning can obstruct correct command parsing in environments with brittle syntax, whereas explicit goal and state tracking consistently confer benefits.
Model Generalization
Testing on stronger open-source (Mixtral-8x22B) and newer API-based agents (gpt-4o-mini) indicates robust transferability. For instance, StateAct achieves 83.7% SR on ALFWorld with Mixtral, outperforming the ReAct baseline by 11.1 points and confirming no algorithmic dependence on proprietary APIs or single LLM series.
Analysis
The comprehensive ablation and comparative studies signal two principle theoretical implications:
- Explicit self-prompted state tracking is sufficient for near-maximal LLM agent efficiency and accuracy in interactive reasoning, even in the absence of tool augmentation, fine-tuning, or retrieval. This finding challenges the presumed indispensability of external state or tool integration, particularly for tasks with moderate to long horizons.
- Prompt engineering must be adapted to domain syntax and reward structure. “Thought”/CoT augmentation can counterproductively increase search space or induce parse errors when environments expect terse or highly regular inputs, notably in real-world and brittle web commands.
Practically, StateAct’s framework provides a lightweight and annotation-efficient path to scaling LLM agents into new embodied or simulated domains, simply by augmenting example traces with goal and state fields.
Implications and Potential Extensions
The demonstration that single-model, in-context learning alone can rival or outperform approaches requiring code execution, data augmentation, and complicated prompt engineering fundamentally lowers the barrier for deploying capable LLM-agents across environments. This is particularly salient for robotics, digital assistance, and any setting with partial observability and noisy feedback.
Open research questions and likely future extensions include:
- Systematic identification of when “thought” annotation transitions from beneficial to detrimental.
- Automatic induction of state representations by the LLM, moving beyond hand-annotated states.
- Extension of the approach to multilingual and more diverse environment types.
- Integration with retrieval-augmented or multi-agent “debate” methods for problems with extremely high step counts or ambiguous goals.
Conclusion
StateAct offers a robust, annotation-efficient framework for LLM-based agents that requires only self-reminding (goal) and explicit in-context state-tracking, realizing substantial accuracy and efficiency advances over previous tool-dependent or data-hungry architectures. The method’s advances in efficiency, interpretability, and generalizability provide actionable direction for future LLM-powered agents in embodied, web, and other interactive settings.

