- The paper introduces TF-TTCL, which distills explicit rules from its own inference trajectory to steer frozen LLMs without gradient updates.
- TF-TTCL employs a three-module system – Semantic Query Augmentation, Contrastive Experience Distillation, and Contextual Rule Retrieval – to enhance performance.
- Empirical results show significant improvements in closed- and open-ended tasks, demonstrating robust domain adaptation and effective error correction.
Training-Free Test-Time Contrastive Learning for LLMs
Motivation and Problem Statement
The static "train-once, deploy-anywhere" paradigm in LLMs is fundamentally limited when facing distributional shifts or dynamic reasoning demands in real-world deployments. Existing Test-Time Adaptation (TTA) methodologies predominantly require gradient access and substantial compute/memory overhead, limiting their applicability to black-box, API-deployed LLMs. Training-free alternatives, such as static prompting or Retrieval-Augmented Generation (RAG), are either rigid or dependent on curated external knowledge, which is not always available. The paper "Training-Free Test-Time Contrastive Learning for LLMs" (2604.13552) introduces TF-TTCL—a regime in which frozen LLMs are dynamically steered to self-improve at inference by distilling explicit textual rule-based supervision from their own inference experiences, bridging the gap between pure inference and introspective adaptation.
TF-TTCL Architecture and Algorithmic Components
TF-TTCL operationalizes a dynamic "Explore-Reflect-Steer" loop through three primary modules:
- Semantic Query Augmentation (SQA): Multi-agent role-playing (Teacher, Tutor, Student) diversifies input queries and probes varied reasoning trajectories. The Teacher generates anchor answers via stable greedy decoding, while the Tutor rewrites queries simulating distributional shift. Students sample responses in parallel, conditioned on retrieved rules.
- Contrastive Experience Distillation (CED): Responses are partitioned into positive and negative candidates via task-dependent clustering (majority vote for CRT, embedding similarity for OET). High-confidence candidates (min-PPL selection) from both positive and negative sets are used to distill explicit rules, capturing semantic reasoning gaps without any parameter update.
- Contextual Rule Retrieval (CRR): All distilled rules are stored in a dual memory repository (positive, negative). At inference, queries retrieve top-K relevant rules by cosine similarity of embeddings. Retrieved rules are injected into the model context via structured prompts, directly steering reasoning away from past errors and toward robust patterns.
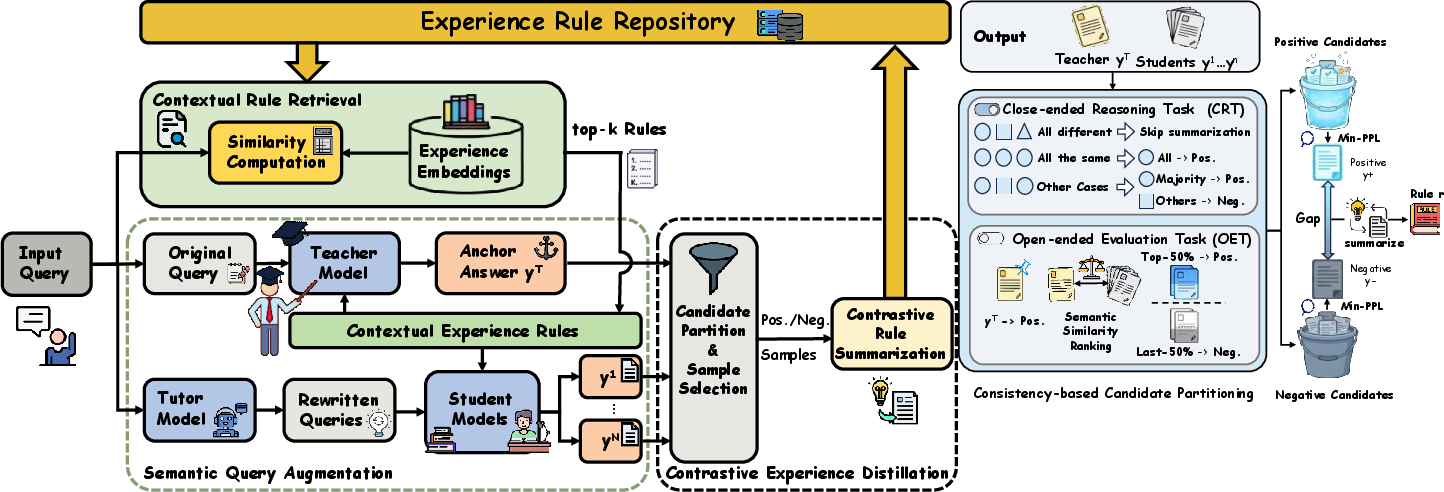
Figure 1: Overview of the TF-TTCL framework, illustrating semantic query augmentation, contrastive experience distillation, and contextual rule retrieval for test-time adaptation.
Contrastive Distillation Pipeline
CED implements unsupervised partitioning and rule extraction to mitigate reinforcement of hallucinations and enable self-correction:
- Closed-ended Reasoning Tasks: Reasoning outputs are clustered; positive clusters reflect consensus (majority) while negative candidates embody divergent, high-confidence errors.
- Open-ended Evaluation Tasks: Positive/negative partitioning is based on semantic closeness to anchor outputs, supporting evaluation in domains lacking deterministic ground truth.
- Rule Summarization: The LLM generates explicit positive (what to do) and negative (what to avoid) rules, which provide semantic gradients for future inference.
Figure 2: Contrastive Experience Distillation pipeline, detailing consistency-based partitioning, min-PPL candidate selection, and contrastive rule summarization.
Empirical Evaluation and Ablative Insights
TF-TTCL is tested on GSM8k, MATH-500, AIME24, Minerva (closed-ended), and DomainBench (open-ended: Geography, Agriculture, Medicine, Finance), using Llama-3.1-8B-Instruct and API black-box models Qwen-Plus and DeepSeek-V3.2. Notable findings include:
- Closed-ended Tasks: TF-TTCL achieves 87.49% accuracy on GSM8k, outperforming TLM (85.06%), TF-GRPO (86.49%), and zero-shot baselines. On AIME24 (competition-level), TF-TTCL reaches 13.33% (vs. 3.33% for base LLM).
- Open-ended Tasks: TF-TTCL delivers an average ROUGE-Lsum of 0.2194 (vs. 0.1731 for base LLM), outperforming both TTA and RL-based methods. RL-based approaches (TF-GRPO) underperform due to reward modeling failures in non-deterministic settings.
- Black-box Model Generality: On Qwen-Plus and DeepSeek-V3.2, TF-TTCL enhances both reasoning (AIME24) and domain adaptation (Finance) beyond CoT and TF-GRPO, indicating effective self-derivation of adaptation signals.
Ablation studies confirm CED as most critical (–1.52% accuracy drop when removed), negative rules contribute more than positive, and precise CRR is essential for open-ended tasks. Parallel execution and memory pruning yield efficient, scalable deployment with bounded latency and repository growth.
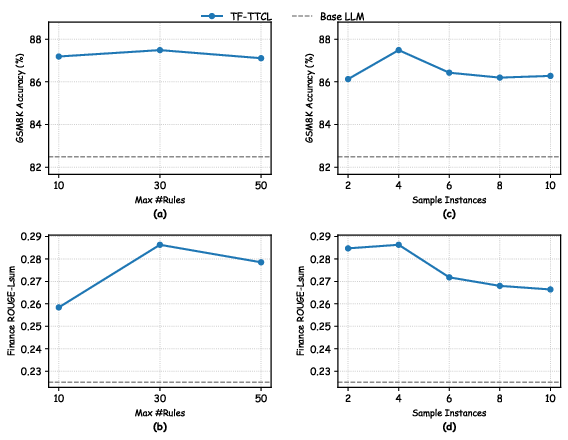
Figure 3: Hyper-parameter ablation for TF-TTCL, showing optimal results for rule and sample instance count across GSM8k and Finance.
Practical and Theoretical Implications
TF-TTCL establishes a clear paradigm for training-free adaptation: experience-driven rule distillation and retrieval dynamically steer black-box LLMs without reliance on gradient updates or external knowledge. This mechanism enables robust domain generalization, effective correction of high-confidence hallucinations, and resilience to self-reinforcing errors, even as models approach proficiency saturation. The explicit separation and injection of negative and positive rules can be interpreted as context-level semantic boundary shaping, emulating cognitive error-awareness and memory.
Theoretically, this approach aligns with reflective learning and contrastive objectives in representation learning, reconceptualizing experience memory as a source of semantic gradients and decision boundaries. Practically, TF-TTCL offers a scalable pathway for adapting proprietary, API-served LLMs in dynamic or streaming test environments, with minimal compute overhead and no requirement for external reward sources.
Future Directions
Future work may integrate progressive rule disclosure (Agent Skills, workflow memory) for even finer-grained, dynamic context injection, optimize retrieval strategies for long-horizon and compositional reasoning, and investigate adversarial robustness and safety under growing rule repositories. The paradigm could be further extended to active learning, self-correction in tool-use agents, and adaptation in multi-domain conversational settings.
Conclusion
TF-TTCL enables frozen LLMs to self-improve at test-time by distilling and retrieving explicit, contrastive rules from their own inference trajectory, outperforming both gradient-based and other training-free adaptation techniques in diverse reasoning and domain tasks. Its efficient, modular architecture and empirically robust gains indicate substantial value for the deployment of LLMs in realistic, resource- and knowledge-constrained settings. The explicit contrastive memory mechanism provides principled error correction and experience transfer at the prompt/context level, opening avenues for future research in dynamic, reflective, and training-free NLP adaptation.

