- The paper introduces a contrastive context sampling protocol that dynamically balances in-context learning and in-weights learning.
- It demonstrates that adaptive mode selection based on target-context similarity minimizes brittle behaviors seen in standard fine-tuning regimes.
- Extensive experiments across translation, Text-to-SQL, and semantic parsing tasks validate the method's efficacy in maintaining performance over diverse settings.
Training In-Context and In-Weights Mixtures with Contrastive Context Sampling
Introduction and Motivation
LLMs exhibit two principal learning modalities post-pretraining: in-weights learning (IWL), where domain/task information is embedded into model parameters, and in-context learning (ICL), in which models adapt on-the-fly using provided input-output exemplars at inference. Robust continuous adaptation for real-world tasks necessitates leveraging both modalities and the capacity to switch efficiently between them, depending on the similarity between the test input and supplied context examples.
Standard fine-tuning regimes often disrupt this equilibrium, with zero-shot fine-tuning degrading ICL and traditional in-context (IC) fine-tuning exhibiting brittle, regime-dependent behaviors. "Training In-Context and In-Weights Mixtures Via Contrastive Context Sampling" (2604.01601) presents a systematic investigation into how context-target similarity governs the emergence and maintenance of ICL-IWL mixtures and proposes a contrastive context sampling protocol designed to robustly co-train both capabilities while equipping the model to select the appropriate “mode” at test time.
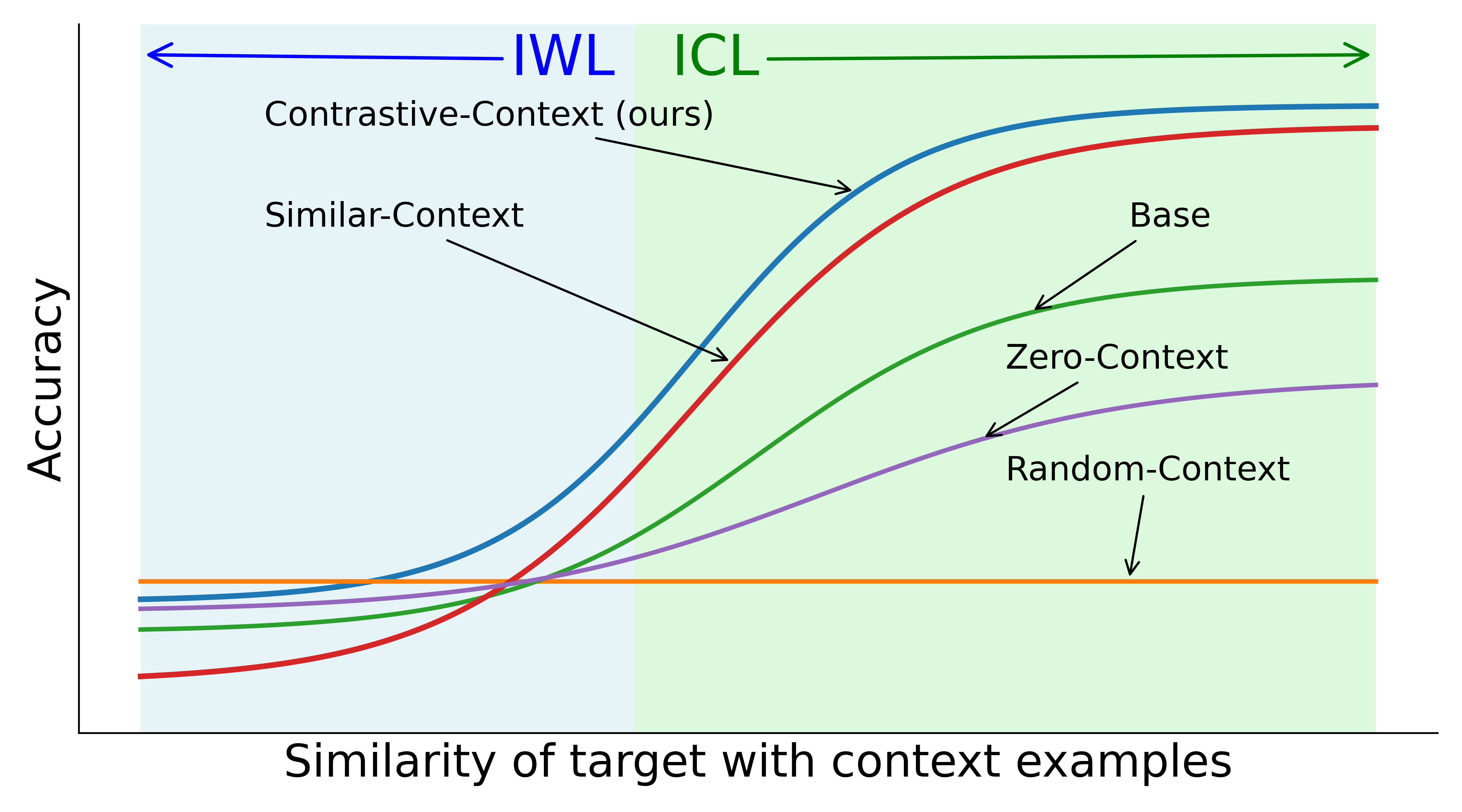
Figure 1: Visual summary of main findings—standard fine-tuning collapses ICL, random-context IC fine-tuning degrades both, similar-context fine-tuning degenerates to copying, and contrastive-context yields a robust, switchable ICL-IWL mixture.
The paradigm is formalized as fine-tuning on task data D={(xi,yi)} with the aim that, after fine-tuning, (1) the model benefits from additional labeled examples appended to D (absorbed via ICL) in high-similarity test scenarios without further updates, and (2) maintains generalization for unseen or dissimilar test points (relying on IWL).
Key baseline regimes are:
- Random-Context: Context elements for IC training are sampled randomly, irrespective of target similarity—this emphasizes IWL and erodes ICL.
- Similar-Context: Context elements are close to the target (e.g., top-k by similarity)—this suppresses IWL and induces brittle, blind-copying ICL.
- Contrastive-Context (proposed): Contexts are composed to deliberately span a spectrum of target-context similarities and ensure contrasts both within a context and across the batch, including synthetic “paraphrases” of the target when natural similar examples are lacking.
Theoretical Analysis
The paper constructs a minimal two-layer transformer model with distinct architectural components: a learned in-weights learner f^, and self-attention parameters θ1,θ2,θ3 which implement switching among pure ICL, pure IWL, and degenerate copying. Analytical investigation shows:
- Training with Random-Context yields a stationary point favoring IWL, ignoring context.
- Training with Similar-Context leads to context averaging (ICL) or even context-blind copying, suppressing in-weights learning.
- Only contrastive training (random-similar mixtures with intra-context contrasts) induces optimal parameters that allow the model to perform ICL only when context is highly similar and default to IWL otherwise—i.e., learning to select between modes adaptively.
This is achieved by shaping the attention parameters so the model can dynamically upweight the context or rely on internalized parametric representations as warranted.
Empirical Results
Extensive empirical analysis is conducted on 32 model-task-test settings (across Llama 3.2 1B, Llama 3.1 8B, Qwen 2.5 7B, and Mistral 7B), over four low-resource machine translation tasks, eleven Text-to-SQL tasks, and three multilingual semantic parsing tasks.
Performance is always plotted as a function of target-context similarity, with methods compared under both in-domain (ID) and out-of-domain (OOD) evaluation. The trends are:
- Zero-shot fine-tuning harms ICL, especially for high-similarity test cases.
- IC-Train with Random-Context is consistently worst when high target-context similarity is present—incapable of leveraging related examples.
- Similar-Context fine-tuning performs poorly for low-similarity test points due to lack of IWL retention and a tendency towards blind copying.
Contrastive-Context is among the best or competitive across the full spectrum, uniquely preserving both IWL and ICL.
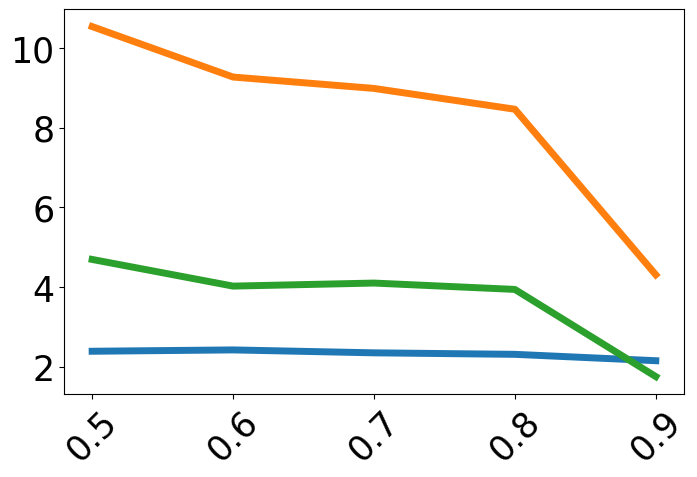
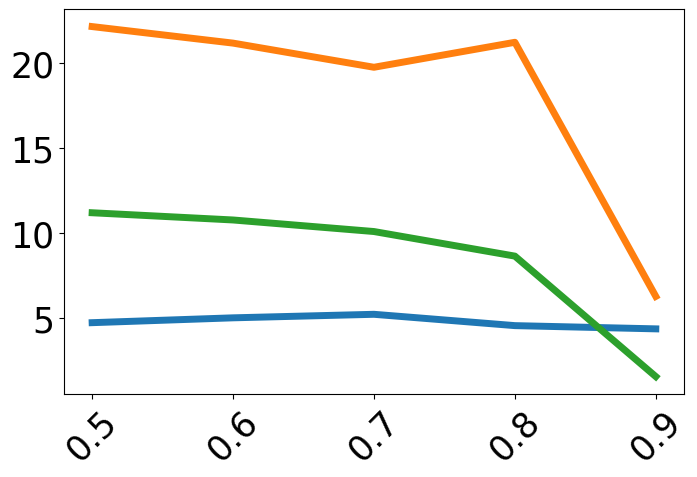
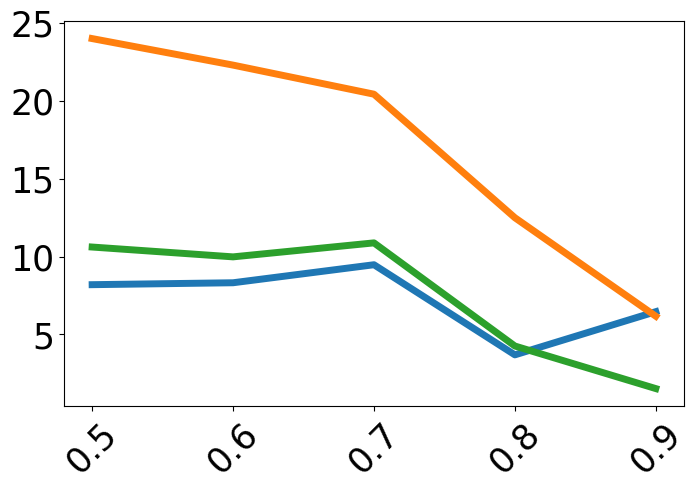

Figure 2: Task accuracy across target-context similarity, demonstrating that only the contrastive context method achieves high, stable accuracy throughout the similarity spectrum, while other regime-specific methods show severe drops in one or more regions.
Diagnostic Probes and Emergence of Failure Modes
Dedicated probing is employed to trace the emergence and relative strengths of three behaviors: IWL, ICL, and degenerate copying. These include direct measurement of prediction overlap between contexts and blind copying probes with permuted input-output pairs. During fine-tuning:
Ablation Studies
Further ablations address:
- Robustness to context sampling hyperparameters (p, ϵ) and paraphrase quality.
- Necessity of explicit intra-context and inter-context contrasts (simple mixtures are insufficient).
- Comparing contrast-aware paraphrasing to naïve data augmentation (only the former yields robust mixtures).
Implications and Future Directions
This work sharpens operational and theoretical understanding of fast adaptation in LLMs. Practically, contrastive context sampling offers a simple, effective prescription for fine-tuning LLMs so they can flexibly absorb feedback during deployment (continuous adaptation) and reliably adapt in both low and high-similarity settings—a critical capability for both production and few-shot learning uses. Theoretically, the findings reinforce that proper mixture modeling (balancing ICL and IWL dynamically) requires not only diverse batch/task sampling but deliberate intra- and inter-context contrasts to avoid mode collapse and pathological overfitting.
Future research directions suggested by this work include:
- Extension to extremely low-resource and cross-lingual tasks, where appropriate context similarity is even more crucial.
- Deeper mechanistic analysis of how contrastive sampling interacts with specific transformer architectural motifs.
- Development of metrics or diagnostics for adaptive mode selection in-the-wild and during continual learning.
Conclusion
The paper provides a rigorous dissection of fine-tuning strategies for balancing and mixing in-context and in-weights learning in LLMs. It demonstrates, both theoretically and empirically, that context-target similarity structure is the primary determinant of effective adaptive behavior post-fine-tuning. The contrastive context protocol proposed induces robust, switchable ICL-IWL mixtures and mitigates common pathologies observed in naïve fine-tuning. This establishes a strong methodological foundation for real-world adaptation tasks and prompts broader reconsideration of how context is incorporated in LLM training and deployment (2604.01601).
