- The paper introduces a novel test-time rethinking framework integrating test-time scaling with in-context reinforcement learning to iteratively update policies.
- It leverages retrieval of semantically relevant contexts and iterative candidate solution refinements to achieve significant performance gains on benchmarks like MedQA and AIME2024.
- Empirical results reveal that TR-ICRL enables smaller models to match or exceed larger models under fixed compute budgets by efficiently aligning reward signals.
TR-ICRL: A Test-Time Rethinking Framework for In-Context Reinforcement Learning
Overview of TR-ICRL and Its Position in ICRL
TR-ICRL (Test-Time Rethinking for In-Context Reinforcement Learning) introduces a synergistic framework that integrates Test-Time Scaling (TTS) with In-Context Reinforcement Learning (ICRL), advancing the capacity of LLMs to reason and adapt through reward-driven iterative refinement entirely at inference. Unlike classical ICRL, which is heavily constrained by the lack of reward signals at test time due to unavailable ground-truth labels, TR-ICRL provides a mechanism for reward generation and policy update within the context window itself. The paper demonstrates that this approach substantially uplifts LLM performance on both mathematical reasoning and knowledge-intensive tasks, effectively closing the gap between small-scale and much larger models under fixed compute budgets.
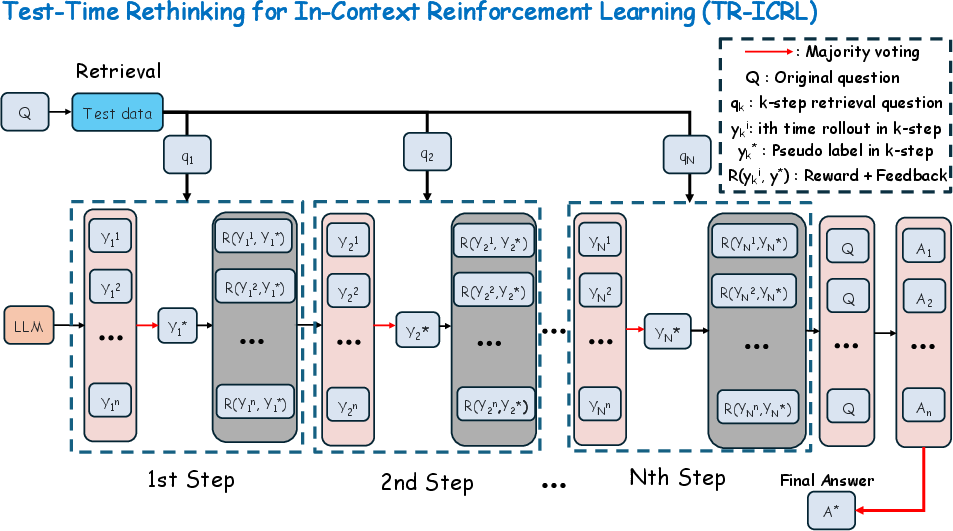
Figure 1: TR-ICRL combines both Test-Time Scaling (TTS) and In-Context Reinforcement Learning (ICRL).
Framework Design: Iterative In-Context Policy Refinement
TR-ICRL operates through a multi-phase pipeline:
- Context Retrieval: The target query is embedded and the most-analogous instances are retrieved from a large unlabeled evaluation corpus via cosine similarity in embedding space. This ensures domain and task alignment in subsequent reasoning.
- Test-Time Iterative Rethinking: For each retrieved question, multiple candidate solutions are generated via zero-shot Chain-of-Thought (CoT) prompting. Pseudo-labels are inferred by majority vote. Each candidate is rewarded or penalized (in a binary fashion) by comparing against these pseudo-labels. The agent then produces formative feedback conditioned on the reward, iteratively refining its context.
- Self-Consistent Aggregation: All rollouts and their correction histories are amalgamated to form contextual prompts for the target query. The final answer is then determined by majority voting across candidate responses.
TR-ICRL thereby achieves in-context policy adaptation and reward alignment without recourse to explicit gradient-based updates or external supervision.
Empirical Results: Robustness and Scalability
Extensive evaluation reveals that TR-ICRL provides robust, monotonic improvements across benchmarks and model architectures. Performance consistently increases with more ICRL steps, subject to context length constraints. Noteworthy numerical results include:
- Qwen2.5-7B: 21.23% average gain on MedQA and 137.59% (from 7.9 to 18.7) on AIME2024.
- Llama3.1-8B: 21.22% improvement on MedQA and 36.68% on MedXpertQA.
- Qwen2.5-7B on AMC: From 34.80 to 55.30 (+58.92%).
These improvements elevate small-parameter models (e.g., 7B) to outperform or closely match the accuracy of much larger models (e.g., 72B) under compute-matched conditions, emphasizing the framework's sample efficiency and resource economy.
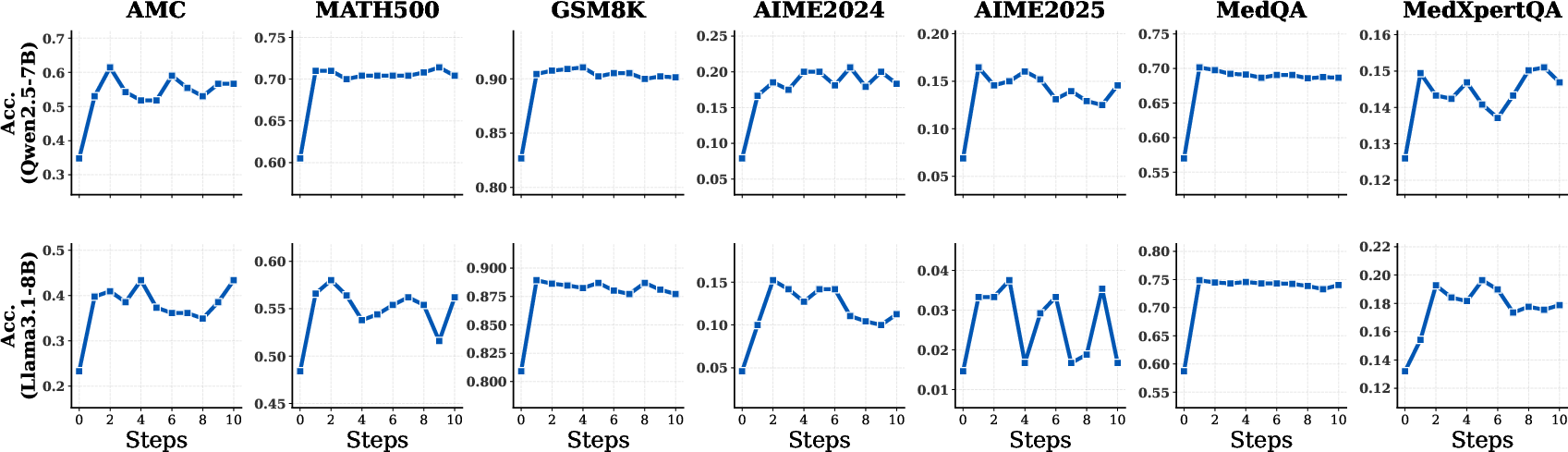
Figure 2: TR-ICRL evaluated with varying numbers of ICRL steps for both reasoning and knowledge-intensive tasks; baseline at step 0.
TR-ICRL's efficacy is especially pronounced on challenging datasets (AIME2024/2025), where the relative improvement is maximal, addressing long-standing limitations of base models on high-difficulty reasoning problems.
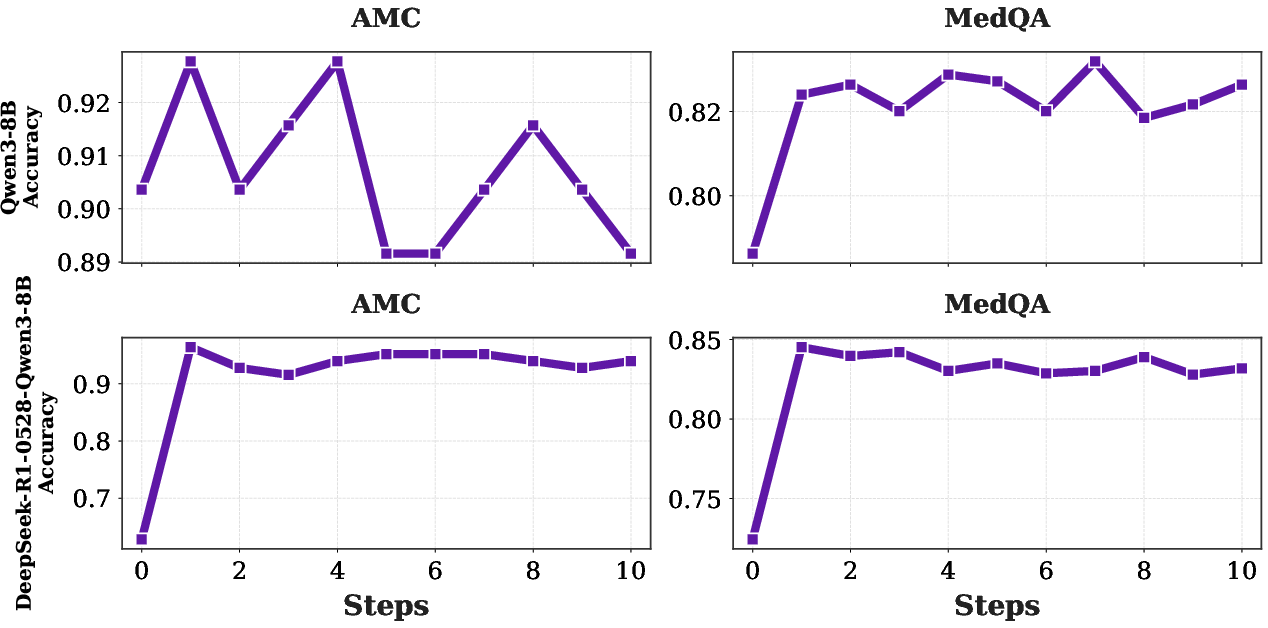
Figure 3: Performance curve of large reasoning models (LRMs) under TR-ICRL iterations.
Ablation Studies: The Role of Contextual Relevance
Ablation analyses dissect the sensitivity of TR-ICRL to the distribution and order of retrieved contexts:
- Retrieval Distribution: Using randomly sampled, minimally similar, or cross-domain contexts leads to sharp performance degradation, highlighting that in-domain semantic relevance is mandatory for effective in-context adaptation.
- Contextual Ordering: Placing highly similar (relevant) samples closer to the query in the prompt sequence yields higher performance, evidencing that proximity to relevant reasoning substantially influences inferential quality.
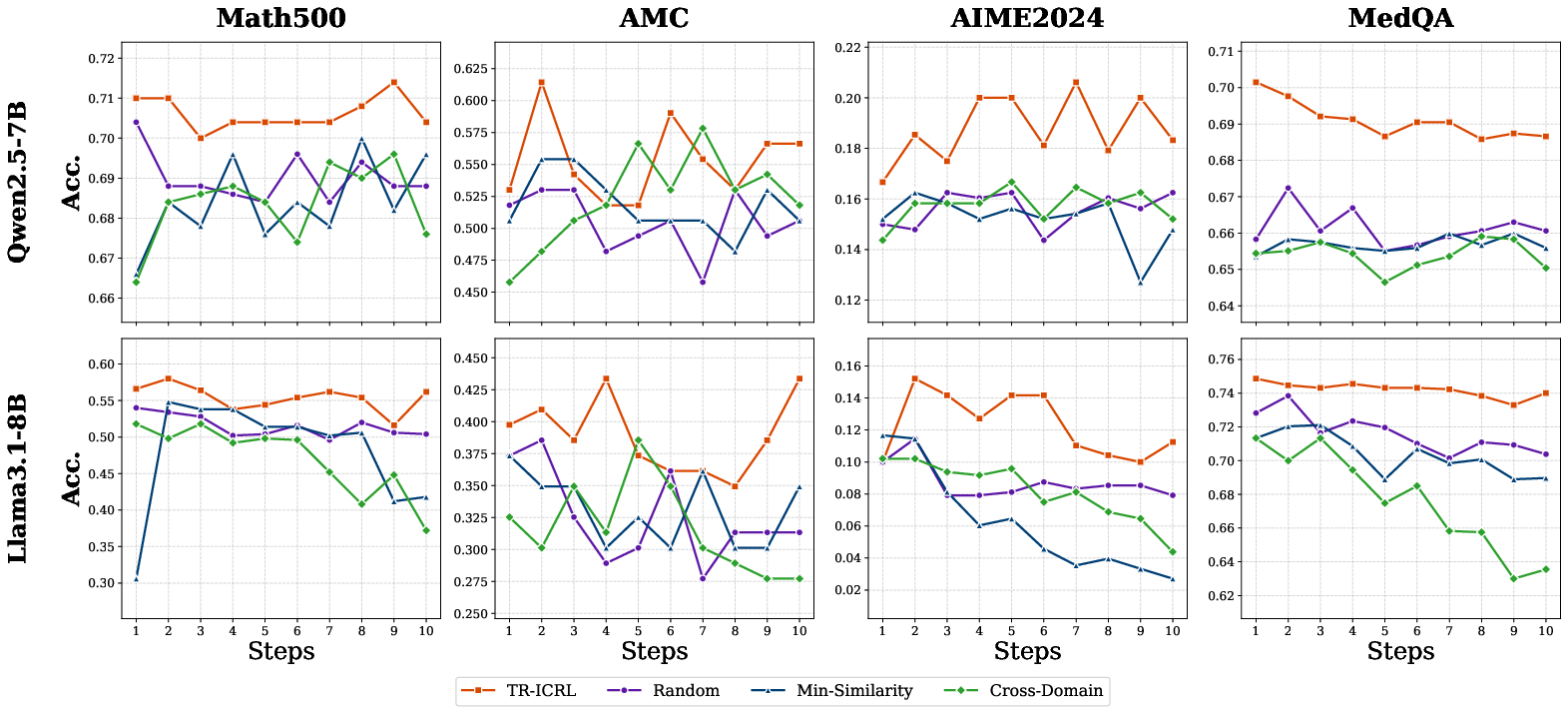
Figure 4: Performance as a function of the retrieved question selection strategy, emphasizing the necessity of semantically relevant contexts.
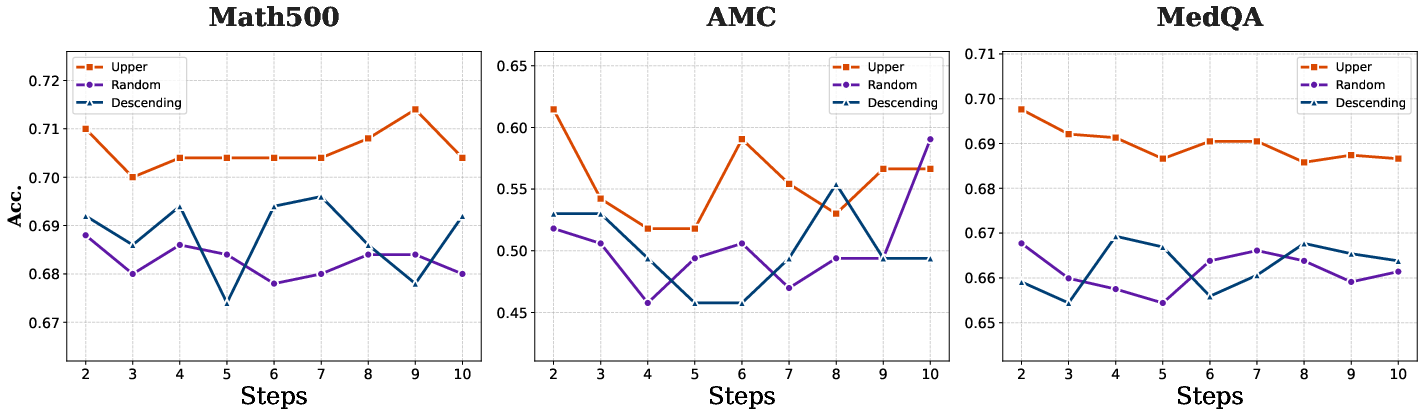
Figure 5: Impact of ordering retrieved contexts on model performance across several benchmarks.
Reward Messages and the "Lucky Reward" Phenomenon
The framework's reliance on pseudo-rewards inferred by majority vote raises the question of functional signal efficacy. Analysis explains TR-ICRL's strong performance even when pseudo-label accuracy is low—the "lucky reward" effect. Negative rewards are densely available via pseudo-label disagreement, ensuring high reward accuracy despite poor label accuracy, particularly on challenging benchmarks.
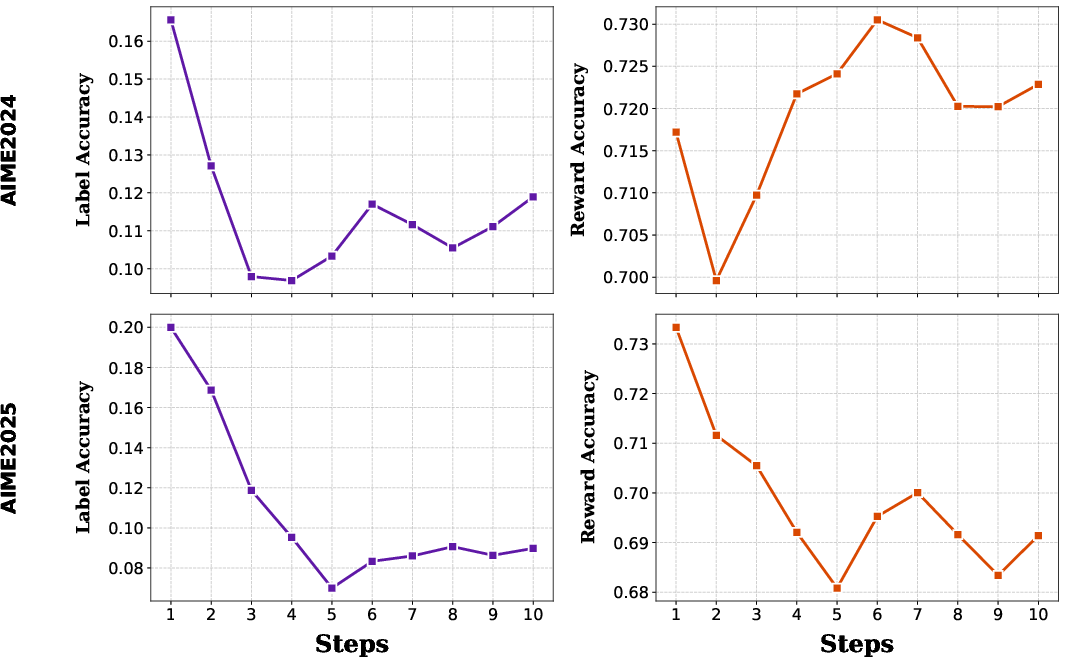
Figure 6: Empirical divergence between raw pseudo-label accuracy and actual reward signal accuracy, with “lucky reward” ensuring dense, informative feedback even for weak base models.
Further, a spurious reward experiment reveals a consistent performance gap: real rewards derived from self-consistent aggregation are superior, but even spurious signals (i.e., incorrect or noisy rewards) can facilitate some learning for simpler tasks. The criticality of reward quality becomes acute for complex reasoning.
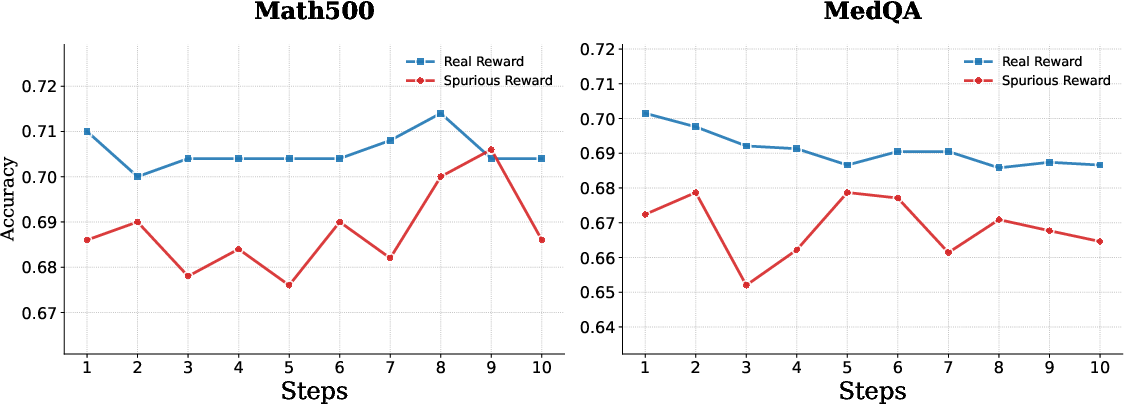
Figure 7: The influence of spurious vs. correct reward signals, confirming the necessity for reward alignment with majority consensus.
Comparative and Practical Considerations
TR-ICRL outperforms strong TTS baselines such as Best-of-N, Self-Refine, and Reflexion in most settings, due to its structured iterative feedback mechanism rather than unguided sampling diversity. It achieves superior performance without exceeding token or FLOP budgets of larger models, making it advantageous for deployment in resource-constrained or latency-sensitive environments.
The theoretical implications of TR-ICRL are manifold:
- It demonstrates that iterative in-context adaptation can emulate the effects of continual RL fine-tuning via context instead of explicit parameter updates.
- The in-context reward-driven updates endorse the duality between ICL and offline RL objectives.
- Interaction between prompt engineering, retrieval, and reasoning signal design is essential and nontrivial, as TR-ICRL's ablation results underscore.
Implications and Future Directions
TR-ICRL decouples test-time inference improvement from model scale, advocating for "thinking at inference" as a compute-efficient alternative to continual supervision and finetuning. The practical upshot is that sufficiently powerful retrieval and reward aggregation strategies can close the gap between small, inexpensive LLMs and state-of-the-art, high-parameter models on complex domains.
For future work, several directions are promising:
- Reward Granularity: The binary nature of TR-ICRL's current reward mechanism could be replaced with rubric-based or probabilistic uncertainty-weighted scores, augmenting learning signal richness.
- Context Compression and OOD Robustness: Mitigating context interference and scaling to longer sequences or more diverse data will require interventions at the memory-aggregation or selection level.
- Fine-Grained Process Supervision: Integrating stepwise process reward or meta-optimization may bridge remaining performance gaps, especially in multi-hop, compositional reasoning tasks.
Conclusion
TR-ICRL formalizes a new paradigm for reward-driven, fully unsupervised test-time optimization for LLMs under the ICRL framework. It empirically validates that robust, context-grounded, and reward-aligned iterative rethinking can yield substantial performance gains, match or exceed much larger LLMs under compute constraints, and generalize across both reasoning and knowledge-intensive tasks. As such, TR-ICRL marks a critical advance in methodological repertoire for in-context policy learning, self-improving inference, and practical deployment of LLMs in scenarios where high-quality labels are unavailable at test time.
(2604.00438)