- The paper demonstrates that TTVS significantly outperforms baseline test-time RL methods, achieving up to 29.8% improvement by synthesizing semantically diverse query variants.
- It employs a dual-module approach that combines online variational synthesis and hybrid exploration to generate and optimize diverse query variants while enforcing answer consistency.
- The method shows robust performance across multiple reasoning benchmarks, efficient computational resource usage, and offers a promising solution for domains with scarce labeled data.
TTVS: Boosting Self-Exploring Reinforcement Learning via Test-Time Variational Synthesis
Motivation and Context
The paper introduces Test-Time Variational Synthesis (TTVS), a novel test-time reinforcement learning framework for Large Reasoning Models (LRMs) intended to address the limitations of Reinforcement Learning with Verifiable Rewards (RLVR) in specialized domains where obtaining high-quality supervised data is expensive or infeasible. Traditional RL methods, including RLHF and RLVR, depend on either substantial human annotation or rule-based rewards, restricting their applicability in domains with scarce labels or objective correctness criteria. Moreover, contemporary test-time adaptation approaches such as TTRL suffer from overfitting risks due to reliance on static query sets, causing models to learn superficial patterns rather than robust underlying logic.
Methodology
TTVS is designed to enable LRMs to self-improve on unlabeled test-time data by dynamically augmenting the data stream and optimizing over semantic variants. The architecture consists of two synergistic modules:
- Online Variational Synthesis: This module transforms each static test query into a cluster of semantically-equivalent, syntactically-diverse variants. A pseudo-label is generated via majority voting from sampled policy rollouts, serving as the reward anchor. The policy model is then prompted to create k new queries that are consistent with the original, sharing the same answer but differing in surface expression. An online filtering mechanism ensures only queries satisfying predefined difficulty and quality constraints are retained.
- Test-Time Hybrid Exploration: The policy is optimized through both intra-group and cross-group explorations. Intra-group exploration independently updates policy for each query instance to maximize accuracy. Cross-group exploration pools rollouts from all variants, enforcing consistency via unified majority voting rewards. This dual mechanism combines exploitation and generalization, incentivizing both mastery of individual variants and robustness across their semantic diversity.
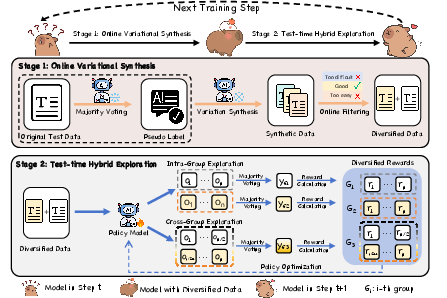
Figure 1: A schematic illustration of TTVS: Stage 1 generates diverse, high-quality variants from test queries; Stage 2 executes hybrid exploration across intra-group and cross-group rollouts, optimizing toward both accuracy and consistency.
Experimental Results
Extensive experiments demonstrate that TTVS consistently outperforms both test-time adaptation baselines and state-of-the-art RL post-training approaches that rely on large-scale labeled data. When applied to various models (Qwen3, Qwen2.5, LLaMA) over multiple reasoning benchmarks (MATH-500, AIME2024, AMC2023, GPQA), TTVS achieves absolute gains of up to 29.8% average score over the best test-time RL baseline (TTRL). Remarkably, TTVS surpasses fully supervised RL models (e.g., DeepSeek-R1-Distill-7B, OpenReasoner-Zero-7B) despite operating exclusively with unlabeled test-time data.
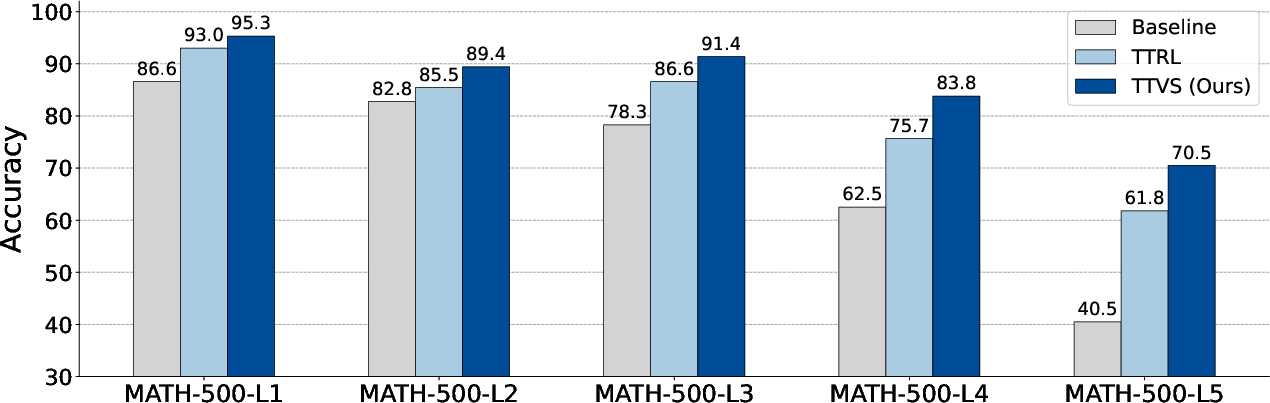
Figure 2: Comparative analysis of performance across five difficulty levels in MATH-500 reveals TTVS's superior robustness and wider performance gap as complexity increases.
Component Analysis
Ablation studies isolate the individual effects of Consistency-Guided Exploitation (CGE) and Intra-Group Exploitation (IGE). Both modules independently produce substantial gains, with IGE yielding higher entropy and more stable exploration during policy optimization.
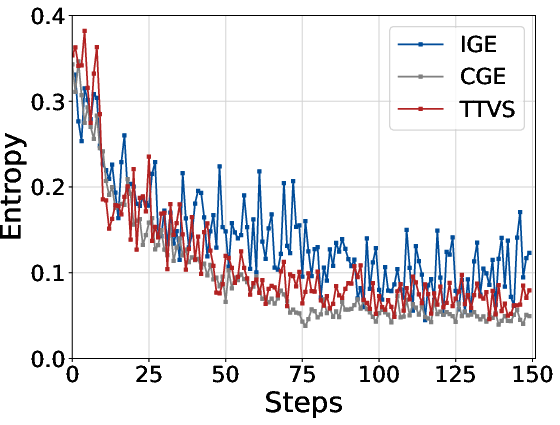
Figure 3: Entropy curves for TTVS components on AMC2023 (Qwen3-4B) illustrate maintained diversity and exploration throughout training.
Computational Efficiency
Resource analysis confirms that TTVS does not incur substantial additional computational overhead. GPU memory usage during test-time training is comparable to TTRL for the same number of rollouts. Even when TTRL's rollouts are doubled, TTVS maintains lower memory consumption while delivering superior accuracy.
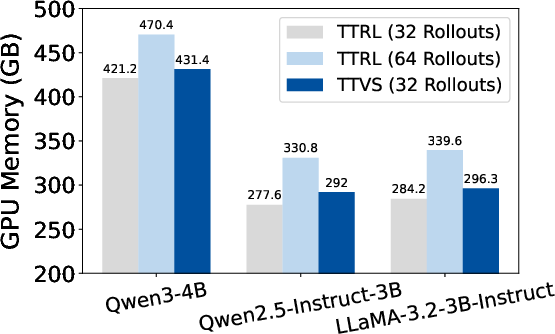
Figure 4: Computational cost during test-time training on Qwen3-4B demonstrates TTVS's efficient utilization of resources.
Hyperparameter Sensitivity
Empirical examinations reveal optimal warmup steps for intra-group (Eintra) and cross-group (Ecross) exploration, with peak performance achieved at 40 and 60 steps, respectively. Filtering thresholds and maximum token length are also shown to be robust, further validating TTVS's quality control.
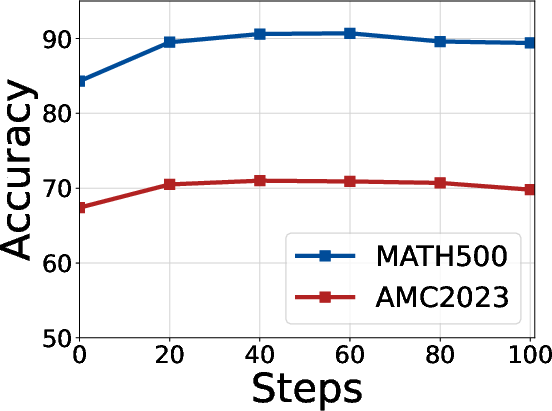
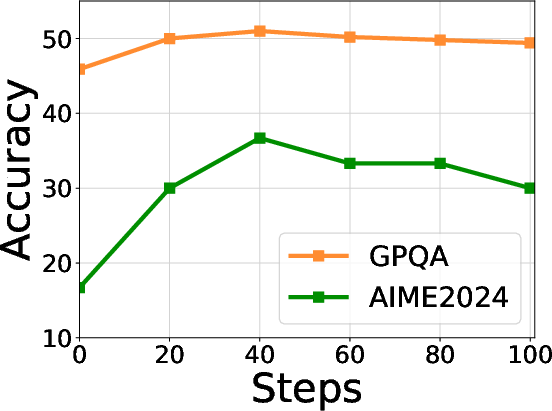
Figure 5: Hyperparameter analysis of the warmup steps for intra-group exploration (Eintra) on diverse reasoning datasets.
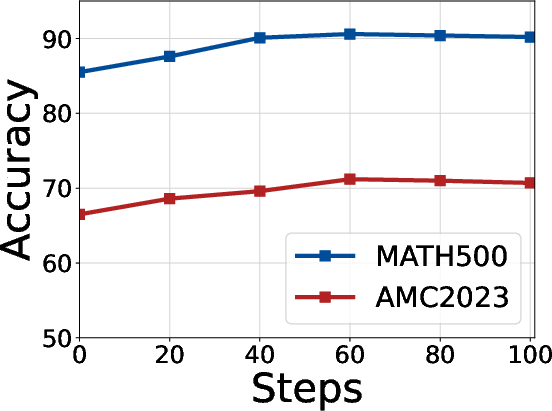
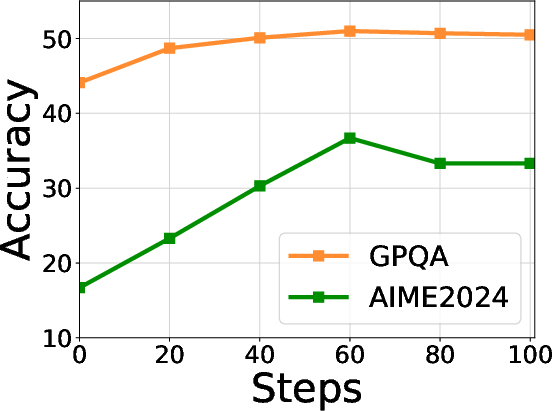
Figure 6: Hyperparameter analysis of cross-group exploration (Ecross) across multiple datasets confirms the stability of TTVS.
Implications and Future Directions
TTVS fundamentally expands the scope of RL-based LRM adaptation, decoupling performance improvements from reliance on labeled data or expert model supervision. The dynamic data augmentation and hybrid exploration provide a self-evolving mechanism, with robust empirical gains seen even on challenging or domain-specific benchmarks, including medical reasoning (MedMCQA) and unseen datasets (DeepMath-103K).
Practically, TTVS enables efficient test-time adaptation for LRMs in environments with distributional shift, scarce supervision, or costly label acquisition. Theoretically, its compositionality with policy optimization algorithms (GRPO, OPO, DAPO) and compatibility with base models (without instruction-following ability) signal potential for broader applicability. Extensions to multimodal architectures and non-verifiable reward scenarios (creative, commonsense reasoning) are plausible via LM-as-a-Judge paradigms, inviting further research in self-supervised RL on subjective or creative tasks.
Conclusion
TTVS presents a principled, highly effective approach to test-time reinforcement learning for LRMs, leveraging variational synthesis and hybrid exploration to achieve superior performance on reasoning benchmarks without reliance on labeled data. The results underscore its practical utility in real-world settings and its theoretical relevance for adaptive self-improvement in RL-driven LLMs.