EVOLVE-VLA: Test-Time Training from Environment Feedback for Vision-Language-Action Models
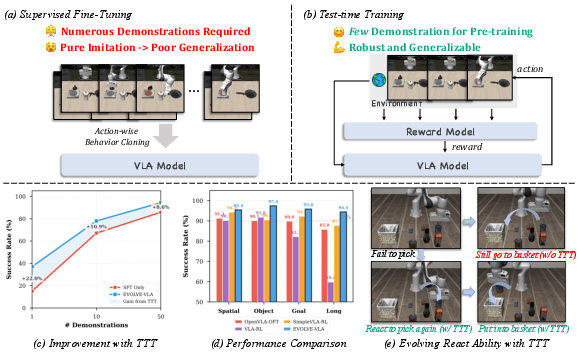
Abstract: Achieving truly adaptive embodied intelligence requires agents that learn not just by imitating static demonstrations, but by continuously improving through environmental interaction, which is akin to how humans master skills through practice. Vision-Language-Action (VLA) models have advanced robotic manipulation by leveraging LLMs, yet remain fundamentally limited by Supervised Finetuning (SFT): requiring hundreds of demonstrations per task, rigidly memorizing trajectories, and failing to adapt when deployment conditions deviate from training. We introduce EVOLVE-VLA, a test-time training framework enabling VLAs to continuously adapt through environment interaction with minimal or zero task-specific demonstrations. The key technical challenge is replacing oracle reward signals (unavailable at test time) with autonomous feedback. We address this through a learned progress estimator providing dense feedback, and critically, we design our framework to ``tame'' this inherently noisy signal via two mechanisms: (1) an accumulative progress estimation mechanism smoothing noisy point-wise estimates, and (2) a progressive horizon extension strategy enabling gradual policy evolution. EVOLVE-VLA achieves substantial gains: +8.6\% on long-horizon tasks, +22.0\% in 1-shot learning, and enables cross-task generalization -- achieving 20.8\% success on unseen tasks without task-specific demonstrations training (vs. 0\% for pure SFT). Qualitative analysis reveals emergent capabilities absent in demonstrations, including error recovery and novel strategies. This work represents a critical step toward VLAs that truly learn and adapt, moving beyond static imitation toward continuous self-improvements.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (Overview)
The paper introduces EVOLVE-VLA, a way to help robot control models learn by practicing in their environment, not just by copying examples. These models are called Vision-Language-Action (VLA) models because they see (vision), understand instructions (language), and move (action). The big idea is to make robots learn like humans do—try things, get feedback, and improve over time—especially when conditions during deployment are different from training.
What questions the researchers asked (Key Objectives)
The paper focuses on simple but important goals:
- Can we reduce the number of expert demonstrations robots need by letting them learn during deployment?
- Can robots recover from mistakes instead of just following memorized paths?
- How can a robot get useful feedback during deployment when a “perfect judge” (an oracle success signal) isn’t available?
- Can we design a safe and effective way for robots to improve step by step on long, multi-stage tasks?
How they approached it (Methods, in everyday language)
Think of teaching a robot like teaching someone to play a new video game:
- First, it watches a short tutorial (a few demonstrations).
- Then it plays and learns during the game (test-time training), improving based on feedback.
Here’s how EVOLVE-VLA works:
- Vision-Language-Action (VLA) model: The robot sees camera images, reads a task instruction (like “put the book on the shelf”), and outputs small “action tokens” that control its movements step by step.
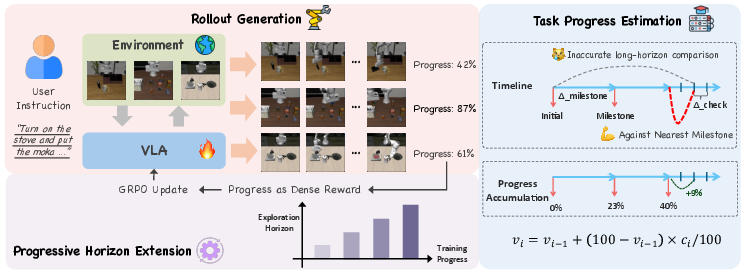
- Reinforcement Learning (RL): This is learning by trial and error. The robot tries different action sequences and gets a “reward” if it makes progress toward the goal. They use an RL method called GRPO, which compares groups of attempts and nudges the policy toward better ones.
- Progress Estimator (feedback without a perfect judge): Since we don’t have a reliable success/fail signal during deployment, the robot uses a learned “progress meter” (VLAC). It looks at two images—one from earlier, one from now—and the instruction, then estimates how much closer the robot is to finishing. This gives the robot a continuous “progress bar” instead of a simple “you won” or “you lost.”
Two big challenges and the solutions:
Accumulative Progress Estimation (taming a noisy progress bar)
Real-life progress estimates can be messy. If you only compare the very first image to the current one, small changes can mislead the robot.
Solution: The robot tracks “milestone images” over time (like saving checkpoints). It regularly compares the current state to the latest milestone and updates an overall progress bar gradually, with diminishing jumps near the end. This smoothing makes feedback more stable, like averaging scores over several rounds instead of trusting a single noisy score.
Progressive Horizon Extension (learning in stages)
Long tasks are hard to learn all at once. If the robot tries full-length tasks from the beginning, early attempts are often bad and confusing.
Solution: Start with shorter practice runs (short horizons). Once the robot gets good at early steps, extend the length. It’s like mastering Level 1 before moving to Level 2 and Level 3 of a game. This makes learning steadier and helps the robot build complex skills step by step.
What they found (Main Results and why they matter)
With EVOLVE-VLA, the robots got better across many tasks in the LIBERO benchmark (a standard set of robotic tasks):
- Overall improvement: About +6.5% average success rate over a strong baseline.
- Long, multi-step tasks: +8.6% improvement—important because these are the hardest.
- With only 1 demonstration per task (very low data): +22.0% improvement on long tasks, and +17.7% on average. This shows the robot can learn a lot by practicing instead of needing many examples.
- Cross-task generalization: When tested on unseen tasks without task-specific training, the robot moved from 0% success to 20.8% just by adapting at test time. That’s a big step toward robots that can handle new tasks on the fly.
They also saw new, smart behaviors emerge:
- Error recovery: If the robot fails to grab an object, it tries again instead of blindly following a memorized path.
- Strategy discovery: The robot found new ways to complete tasks that weren’t in the demonstrations (like grasping a pot differently).
A known limitation:
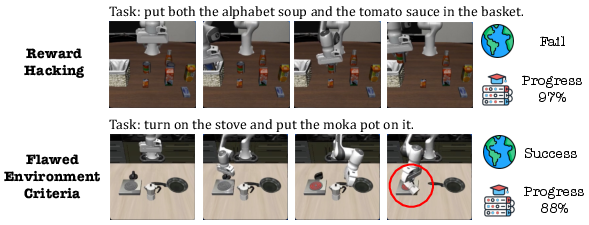
- Sometimes the learned “progress bar” doesn’t perfectly match the environment’s rule-based success check (for example, an object is “semantically” in place but slightly off by coordinates). Better alignment between progress estimates and environment rules is a future challenge.
What this means going forward (Implications)
- Less human labor: Robots won’t need hundreds of demonstrations for every new task; they can learn by practicing in the actual environment.
- More robust robots: They can adapt when something unexpected happens, fix mistakes, and discover new solutions.
- Toward general-purpose helpers: This is a step toward robots that can handle a wide variety of tasks by learning continuously.
- Future work: Improve the progress estimator so it matches environment rules better, make learning safer and faster in the real world, and push toward true zero-shot adaptation (no examples needed at all).
In short: EVOLVE-VLA helps robots learn like people—by doing, getting feedback, and improving—so they can handle tough, changing tasks with less setup and more resilience.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide future research.
- Real-world validation: The framework is only evaluated in simulation (LIBERO). No results on physical robots, sim-to-real transfer, safety constraints during exploration, or mechanisms for preventing damage in early training stages.
- Sample efficiency and training cost: The paper does not report the number of environment interactions, wall-clock time, or compute required per task to achieve the reported gains (including per-stage horizons and GRPO steps), making it hard to assess practicality for real deployments.
- True zero-demo initialization: Despite claims of “minimal or zero task-specific demonstrations,” all experiments start from SFT-pretrained policies (50 demos per task or 1-shot). Demonstrating TTT starting from no demonstrations or from an untrained policy remains open.
- Reward model dependency: The approach hinges on a single foundation critic (VLAC) trained elsewhere. There is no analysis of how reward-model pretraining data, biases, or domain coverage affect performance, nor how to bootstrap a progress estimator in novel domains with sparse supervision.
- Modalities in progress estimation: VLAC uses two images and task text only. Progress signals ignore proprioceptive and tactile information, which can be critical for tasks where visual cues are ambiguous; evaluating and integrating multimodal feedback is unexplored.
- Alignment with environment success criteria: The paper documents semantic–rule mismatch and “reward hacking,” but does not propose or evaluate principled alignment mechanisms (e.g., hybrid semantic–geometric success metrics, calibrated decision thresholds, or constraint satisfaction checks).
- Calibration and uncertainty in progress estimates: There is no uncertainty quantification, confidence-aware termination, or dynamic thresholding based on estimator reliability; false positives/negatives in termination are not measured.
- Sensitivity to hyperparameters: The accumulative mechanism introduces new hyperparameters (Δmilestone, Δcheck, diminishing-returns update, τthreshold). A systematic sensitivity analysis across tasks and environments is missing.
- Adaptive curriculum: Progressive horizon extension uses a fixed schedule. There is no method to adapt horizons based on online competence or uncertainty (e.g., automatic stage transitions or success-driven curriculum).
- Exploration strategy: Exploration is limited to temperature sampling. Comparisons to alternative strategies (e.g., entropy regularization, intrinsic motivation/curiosity, directed exploration via subgoals) are absent.
- RL algorithm choice: GRPO is used without evaluating alternatives (e.g., PPO with value networks, A2C, SAC for continuous actions, off-policy methods) or analyzing stability/convergence in token-based action spaces.
- Action space limitations: The approach disables continuous action regression and relies on discrete action tokens, potentially limiting fine-grained control. Generalization to continuous actions and other VLA architectures (e.g., flow-based, diffusion) is not assessed.
- Cross-task generalization scope: Zero-shot cross-task transfer is shown only from LIBERO-Long to LIBERO-Object with modest success (20.8%). It is unclear how broadly this generalizes across task suites, object categories, and instruction styles, or what task properties enable transfer.
- Robustness to perception shifts: The method is not stress-tested under visual distribution shifts (lighting, occlusions, camera viewpoints), clutter, or partial observability that commonly arise in real settings.
- Termination reliability: The paper notes premature/delayed termination risk but does not quantify termination error rates, their impact on learning, or propose corrective heuristics (e.g., hysteresis, multi-criteria confirmation).
- Non-monotonic tasks and reversibility: The accumulative progress update assumes monotonic advancement with diminishing returns. How it handles tasks with reversible steps, backtracking, or multi-branch subgoals is not studied.
- Subgoal discovery and hierarchy: While accumulative estimation uses milestones, it does not detect or leverage semantically meaningful subgoals. Integrating hierarchical RL or skill libraries to structure long-horizon tasks remains open.
- Co-evolution of reward model: The reward estimator remains static; no exploration of online reward model adaptation, preference learning, human-in-the-loop corrections, or self-supervised refinement to reduce misalignment.
- General evaluation metrics: Success rate is the primary metric. Effects on trajectory length, energy/smoothness, error recovery frequency, and safety violations are not reported, limiting insight into qualitative improvements.
- Variance and reproducibility: Performance variability across random seeds, tasks, and runs is not provided. The F-score validation set for progress estimation is not described in detail (composition, collection protocol), hindering reproducibility and fair comparison.
- Data and code dependencies: The framework depends on external VLAC checkpoints; licensing, availability, and procedures for retraining/replacing the critic in other domains are not documented.
- Instruction robustness: The system’s sensitivity to linguistic variations (paraphrases, ambiguity, multi-step language) in task instructions and its impact on progress estimation and policy learning is unexamined.
- Safety-aware learning: Although safety is mentioned as future work, there is no concrete mechanism (e.g., action constraints, safety critics, recovery policies) or evaluation protocol to ensure safe TTT in physical environments.
- Negative transfer risks: The potential for TTT to degrade performance on previously competent tasks (catastrophic forgetting) or induce harmful behaviors due to noisy rewards is not analyzed; mechanisms for safeguarding against regression are lacking.
Practical Applications
Summary of Practical Applications
EVOLVE-VLA introduces a deployable test-time training (TTT) framework for Vision-Language-Action (VLA) models that adapt through environment interaction without oracle rewards. Two innovations—accumulative progress estimation and progressive horizon extension—stabilize inherently noisy, learned feedback signals, enabling robust online improvement with minimal or zero task-specific demonstrations. Below, applications are grouped by immediacy and linked to sectors, tools/workflows, and feasibility assumptions.
Immediate Applications
These applications can be piloted now in simulation or controlled lab/production settings with available VLA stacks (e.g., OpenVLA-OFT) and a progress estimator (e.g., VLAC).
- Robotics R&D and prototyping (Robotics)
- Use case: Rapid adaptation to task variants and environment shifts during lab development (e.g., grasping different container types, drawer opening with novel handles).
- Tools/workflows: EVOLVE-VLA trainer with GRPO; progress-estimator API; integration with LIBERO/RLBench/MuJoCo/Isaac; automated rollout termination using progress thresholds.
- Assumptions/dependencies: Access to a competent base VLA; calibrated progress estimator per task family; enough on-device or workstation compute; safety interlocks for test-time exploration.
- Demonstration cost reduction (Robotics, Academia)
- Use case: Replace hundreds of human demonstrations per task with few-shot or 1-shot pretraining followed by autonomous TTT (+17.7% avg gain in 1-shot setting shown).
- Tools/workflows: “Few-shot commissioning kit” for integrators; pipelines that auto-collect self-rollouts and update policies on the fly.
- Assumptions/dependencies: Progress model must generalize across object/scene variations; controlled environments to minimize costly exploration errors.
- Long-horizon skill acquisition and error recovery (Robotics)
- Use case: Improve completion of multi-step tasks and develop recovery behaviors (e.g., reattempting grasp, adapting to changed object states).
- Tools/workflows: Progressive horizon curriculum schedules; accumulative reward smoothing; policy monitoring dashboards to visualize progress curves and termination events.
- Assumptions/dependencies: Good temporal calibration of milestones and thresholds; safe reset mechanisms for failed trials.
- Cross-task bootstrapping within related domains (Robotics)
- Use case: Deploy a model trained on one task suite to related tasks and use TTT to lift from 0% to non-trivial success rates (e.g., 0% → 20.8% in LIBERO cross-suite).
- Tools/workflows: “Cold-start adaptation” workflows: load pretask model → enable progress feedback → constrain horizon → extend progressively.
- Assumptions/dependencies: Overlap in motion primitives; progress estimator with task-agnostic semantics; tolerance for initial low success.
- Benchmarking and curriculum research (Academia)
- Use case: New benchmarks for TTT, reward-model “taming,” and curriculum design; ablation suites for horizon scheduling and temporal sampling.
- Tools/workflows: Reproducible EVOLVE-VLA code; standardized progress estimators; dataset splits for success-criteria alignment studies.
- Assumptions/dependencies: Open-sourced code/models; shared evaluation protocols (e.g., LIBERO).
- Reward-model utilities for robotics QA (Software, Robotics)
- Use case: Use progress estimation as a semantic quality metric for intermediate steps (beyond binary success) in simulation testing and CI for robot policies.
- Tools/workflows: “Progress Estimator as a Service” microservice; batch scoring of rollouts; regression tests against baseline progress trajectories.
- Assumptions/dependencies: Stable estimator across lighting/viewpoint changes; validation sets for recalibration to avoid reward hacking.
- Safety-aware TTT in sandboxes (Policy, Robotics)
- Use case: Lab governance for on-robot learning: run TTT in virtual fences; action clamps; human-in-the-loop approval for horizon extension.
- Tools/workflows: Safety critics; kill-switch integrations; exploration budgets and rollback checkpoints.
- Assumptions/dependencies: Institutional safety policies; real-time monitoring; safe stopping ability.
- Education and training (Education)
- Use case: Hands-on modules demonstrating TTT, reward learning, and curriculum design in robotics courses.
- Tools/workflows: Student-friendly notebooks combining OpenVLA-OFT + VLAC; controlled simulation labs; visualization of accumulative progress.
- Assumptions/dependencies: Access to GPUs/sim environments; instructor familiarity with RL/VLA stacks.
Long-Term Applications
These require further research for robustness, safety, sample efficiency, or real-world validation (e.g., sim-to-real transfer, multi-modal sensing, regulatory approval).
- Adaptive factory and warehouse automation (Robotics, Manufacturing, Logistics)
- Use case: On-the-fly adaptation to new SKUs, packaging geometries, and workcells without reprogramming; auto-recovery from disturbances.
- Tools/products: “TTT-enabled robot controller” with fleet telemetry; progressive horizon policy updates during off-shifts; shadow policies tested in digital twins before go-live.
- Assumptions/dependencies: Verified safety envelopes; high-confidence progress models tailored to SKUs; strong sim-to-real transfer; compliance with ISO/ANSI robot safety standards.
- General-purpose home assistants (Robotics, Consumer)
- Use case: Robots that learn user-specific routines (e.g., organizing, loading dishwashers, tidying in unknown homes) from natural language and few demonstrations.
- Tools/products: Edge-cloud TTT service; privacy-preserving logs; user-friendly “teach-by-trying” interfaces; tactile and vision progress estimators.
- Assumptions/dependencies: Robust perception under home variability; safety and privacy safeguards; reliable reset procedures for failed attempts.
- Hospital logistics and assistive care (Healthcare, Robotics)
- Use case: Robots that adapt to ward layouts, supply placement changes, and individualized patient interaction protocols with minimal retraining.
- Tools/products: Clinical-grade TTT platform with audited learning traces; safety critic tuned to clinical policies; semi-autonomous modes with clinician oversight.
- Assumptions/dependencies: Strict safety and compliance (FDA/CE); explainability and audit logs; infection control constraints; reliable multi-modal sensing (vision+tactile+speech).
- Infrastructure inspection and maintenance (Energy, Utilities, Construction)
- Use case: Robots that adapt to novel equipment layouts, wear, or weather-induced changes; learn improved inspection coverage or manipulation sequences onsite.
- Tools/products: Field-deployable TTT stacks with offline replay; progress models trained on multi-year inspection datasets; terrain-aware horizon schedules.
- Assumptions/dependencies: Ruggedized hardware; safety in hazardous environments; domain-tuned progress estimators; intermittent connectivity.
- Agricultural manipulation and harvesting (Agriculture, Robotics)
- Use case: Seasonal and varietal adaptation for picking, pruning, and sorting without exhaustive reprogramming.
- Tools/products: Crop-aware progress estimators; fleet learning across farms; hybrid human-in-the-loop correction interfaces for reward/model recalibration.
- Assumptions/dependencies: High variance in plant morphology; weather/lighting robustness; gentle failure handling to avoid crop damage.
- Mobile manipulation and navigation (Robotics, Autonomy)
- Use case: Integrate TTT with embodied navigation for long-horizon fetch-and-place or assembly tasks in dynamic spaces.
- Tools/products: Multi-stage progressive horizon spanning locomotion and manipulation; hierarchical progress estimators (scene-level + object-level).
- Assumptions/dependencies: Reliable state estimation; sensor fusion; hierarchical policy architectures.
- Fleet learning and continual improvement ops (Software, Robotics)
- Use case: Centralized learning from distributed robot experience with guardrails; rollout validation in sim; staged rollout to production robots.
- Tools/products: “Robot MLOps for TTT”: dataset/version control, reward-model drift detection, canary deployments, safety gates.
- Assumptions/dependencies: Telemetry infrastructure; strong privacy/security; reproducible training; legal approvals for continuous learning.
- Regulatory frameworks for adaptive robots (Policy)
- Use case: Standards for test-time learning: safety boundaries, auditability, rollback, and certification of reward models and curricula.
- Tools/products: Conformance test suites for progress estimators; standardized reporting for learning events; third-party audits.
- Assumptions/dependencies: Multi-stakeholder consensus; mapping to existing functional safety standards (e.g., IEC 61508, ISO 10218).
- Multimodal reward modeling and safety critics (Academia, Healthcare, Robotics)
- Use case: Progress estimators that align with semantic task completion and safety constraints (reducing reward hacking/mismatch with environment success).
- Tools/products: Tactile/force/vision-language critics; counterfactual evaluators; uncertainty-aware termination logic.
- Assumptions/dependencies: Large, diverse datasets; robust calibration; interpretability tools; sample-efficient RL updates.
- Edge-efficient on-robot learning (Software, Hardware)
- Use case: Real-time TTT on limited compute with energy constraints; low-latency policies for safety-critical tasks.
- Tools/products: Model compression and token-efficient action decoders; on-chip RL accelerators; asynchronous background learning.
- Assumptions/dependencies: Hardware support; careful scheduling to avoid control latency spikes; power/thermal budgets.
- Education-to-industry pipelines (Education, Industry)
- Use case: Workforce training on safe deployment of adaptive robots; capstone-to-factory transition programs using TTT curricula.
- Tools/products: Standardized TTT courseware; accredited labs; certification for “TTT-safety practitioner.”
- Assumptions/dependencies: Industry-academic partnerships; access to simulators and safe robot cells.
- Progress scoring for process optimization and QA (Manufacturing, Software)
- Use case: Use learned progress signals beyond control—for line diagnostics, early-stopping of failed cycles, or automated rework routing.
- Tools/products: Inline progress monitors; alarms when progress plateaus; analytics tying progress profiles to yield.
- Assumptions/dependencies: Calibrated estimators per station; integration with MES/SCADA; governance for automated interventions.
Notes on feasibility and key dependencies across applications:
- Reward/Progress alignment: The paper documents mismatch between semantic progress and rule-based success criteria; robust calibration and safety checks are required to avoid reward hacking and premature termination.
- Sample efficiency and runtime: Online RL is slower in the real world; parallelization, sim-to-real transfer, and curriculum design are crucial.
- Safety and governance: Early-stage exploration can be unsafe; action constraints, safety critics, human oversight, and rollback mechanisms are mandatory for physical deployments.
- Sensing and generalization: Progress estimators (e.g., VLAC) must generalize across lighting, viewpoints, objects, and tasks; multimodal inputs (vision+tactile+language) likely needed in production.
- Compute and integration: On-robot or edge-cloud compute must support frequent critic queries, policy updates, and logging without impacting control loop stability.
- Data and privacy: Deployment in homes or hospitals demands privacy-preserving telemetry, on-device processing, and clear consent and data retention policies.
Glossary
- Accumulative progress estimation: A technique that aggregates incremental progress signals over time to smooth noise and produce a stable reward estimate. "an accumulative progress estimation mechanism smoothing noisy point-wise estimates"
- Action chunking: Grouping multiple low-level actions into larger units to improve efficiency and stability in sequence generation. "OpenVLA-OFT further proposes parallel decoding, action chunking, and a continuous action representation to improve performance."
- Action tokenization: Discretizing continuous robot actions into tokens so they can be generated by sequence models. "we adopt action tokenization where continuous robot actions are discretized into tokens."
- Advantage: In policy gradient RL, a measure of how much better an action is compared to the average, used to stabilize learning. "GRPO normalizes trajectory rewards within each batch to compute advantages and applies PPO-style clipping for stable updates"
- Autoregressive (model): A model that predicts each token conditioned on previously generated tokens in a sequence. "a state-of-the-art autoregressive VLA model that achieves high performance and inference efficiency."
- Behavior cloning: Imitation learning that trains a policy to mimic expert demonstrations by supervised learning on state-action pairs. "VLAs optimized through behavior cloning merely imitate demonstrations and struggle to generalize beyond training distribution."
- Binary success signals: Sparse reward feedback that only indicates success or failure at the end of a task. "oracle reward functions (e.g., binary success signals) unavailable at test time."
- Closed-loop interaction: Executing actions while continuously receiving observations and using them to inform subsequent actions. "A trajectory is generated through closed-loop interaction: the policy outputs actions, the environment transitions based on physical dynamics, and updated observations feed back into the policy until task completion or maximum horizon ."
- Continuous action regression head: A network output branch that predicts continuous-valued actions directly rather than discrete tokens. "while disabling the continuous action regression head, i.e., use discrete action tokens instead."
- Cross-task generalization: The ability of a model to transfer learned skills to different tasks without task-specific training. "and enables cross-task generalizationâachieving 20.8\% success on unseen tasks without task-specific demonstrations"
- Dense feedback: Frequent, informative reward signals provided throughout an episode to guide learning efficiently. "progress-based rewards provide dense, continuous feedback crucial for sample-efficient learning."
- Diminishing returns principle: A rule in accumulation where incremental gains contribute less as the estimate nears completion, preventing overshoot. "This recursive formulation applies a diminishing returns principle"
- Discount factor: A scalar in RL that weights future rewards relative to immediate ones. "and is the discount factor."
- Flow-based architecture: A generative modeling approach using invertible transformations to model continuous distributions, adapted here for action generation. "a continuous flow-based architecture."
- Foundation critic model: A broadly trained evaluator that scores task progress across diverse settings without task-specific training. "We employ a foundation critic model, VLAC"
- GRPO (Group Relative Policy Optimization): An RL algorithm that uses group-normalized rewards and PPO-style clipping without a value network. "We employ Group Relative Policy Optimization (GRPO) to update the policy."
- Ground-Truth (GT): Accurate, oracle-provided labels or signals (e.g., success/failure) available in training but not at deployment. "they still assume access to Ground-Truth (GT) information during the RL training phase, such as whether a trajectory succeeds or fails."
- LLMs: Scaled LLMs that provide semantic priors and reasoning capabilities for embodied agents. "Propelled by the capabilities of LLMs, control policies are rapidly evolving beyond traditional methods"
- LIBERO benchmark: A simulation benchmark of language-guided robotic manipulation tasks used for standardized evaluation. "We evaluate our method on the LIBERO benchmark"
- Long-horizon tasks: Tasks requiring extended sequences of actions with multiple subgoals and long temporal dependencies. "EVOLVE-VLA achieves substantial gains: +8.6\% on long-horizon tasks"
- Markov Decision Process (MDP): A formalism for sequential decision-making defined by states, actions, transitions, rewards, and a discount factor. "We formulate the robotic manipulation task as a Markov Decision Process (MDP) "
- Milestone frames: Periodically sampled reference frames used to compute incremental progress during long rollouts. "we maintain milestone frames at regular intervals and compute progress incrementally."
- Online reinforcement learning: Updating a policy continually during deployment from interaction-generated data. "We achieve this through online reinforcement learning, where the policy is iteratively refined based on rewards obtained from environment interaction."
- Oracle reward functions: Perfect or simulator-provided reward signals (e.g., success flags) not available at test time. "they rely on oracle reward functions (e.g., binary success signals) unavailable at test time."
- Parallel decoding: Generating multiple action tokens concurrently to speed up inference in sequence models. "OpenVLA-OFT further proposes parallel decoding, action chunking, and a continuous action representation"
- PPO-style clipping: A constraint in policy optimization that limits updates to stay within a trust region for stability. "applies PPO-style clipping for stable updates"
- Proprioceptive state: Internal robot sensing of its own configuration (e.g., joint positions/velocities). "proprioceptive state $o_t^{\text{prop}$"
- Progressive horizon extension: A curriculum strategy that gradually increases the maximum rollout length during training. "and (2) a progressive horizon extension strategy enabling gradual policy evolution."
- Reward hacking: Optimizing the learned reward proxy in ways that do not align with true task success. "This creates a form of ``reward hacking'' where the policy optimizes for high progress scores without meeting the strict environmental criteria."
- Rollout trajectories: Sequences of states and actions generated by interacting with the environment under a policy. "a VLA model interacts with the environment and generates diverse rollout trajectories."
- Success Rate (SR): The proportion of trials in which a task is completed successfully. "We report the average Success Rate (SR) across 50 trials for each task"
- Supervised Fine-Tuning (SFT): Training a model on labeled demonstrations to imitate expert behavior. "Vision-Language-Action (VLA) models have advanced robotic manipulation by leveraging LLMs, yet remain fundamentally limited by Supervised Finetuning (SFT)"
- Temperature (sampling): A parameter that controls randomness when sampling actions from a probability distribution. "by sampling from the policy's action token distribution with temperature ."
- Test-time training (TTT): Adapting a model during deployment using feedback from its own environment interactions. "The central challenge of practical TTT is replacing the oracle with autonomous feedback."
- Transition dynamics: The environment’s probabilistic rules that map current states and actions to next states. " represents transition dynamics"
- Value network: A function approximator that estimates expected returns; some methods avoid using it. "without requiring a separate value network."
- Vision-Language-Action (VLA) models: Multimodal policies that perceive vision, parse language, and output robot actions. "Vision-Language-Action (VLA) models have advanced robotic manipulation"
- VLAC (foundation critic): A pre-trained critic that estimates task progress from image pairs and language instructions. "VLAC takes two images and a language instruction as input and outputs a critic value"
- Zero-shot cross-task generalization: Achieving non-zero performance on unseen tasks without task-specific demonstrations. "pioneering zero-shot cross-task generalization (0\% â 20.8\%) through test-time adaptation alone."
Collections
Sign up for free to add this paper to one or more collections.