- The paper presents a mechanism-based taxonomy for hallucinations in Vid-LLMs, distinguishing between dynamic distortion and content fabrication errors.
- It benchmarks error modes using metrics like event misordering and duration estimation, revealing strengths and weaknesses in current models.
- Mitigation strategies employing contrastive decoding and modality-disentangled tuning are evaluated, highlighting trade-offs between training and inference approaches.
Survey of Hallucination Taxonomy and Mitigation in Video LLMs
Introduction
Video LLMs (Vid-LLMs) extend multimodal reasoning to temporally coherent, audio-visual contexts, introducing unique challenges in reliability. This survey systematically categorizes hallucinations observed in Vid-LLMs, analyzes evaluation protocols, reviews mitigation techniques, and identifies open problems. The taxonomy differentiates hallucinations arising from dynamic distortions in spatiotemporal reasoning and referential consistency, versus content fabrications driven by statistical priors and modality dominance. The focus is on mechanism-driven categorization, comprehensive benchmarking, and scalable mitigation strategies targeting video-specific error modes.
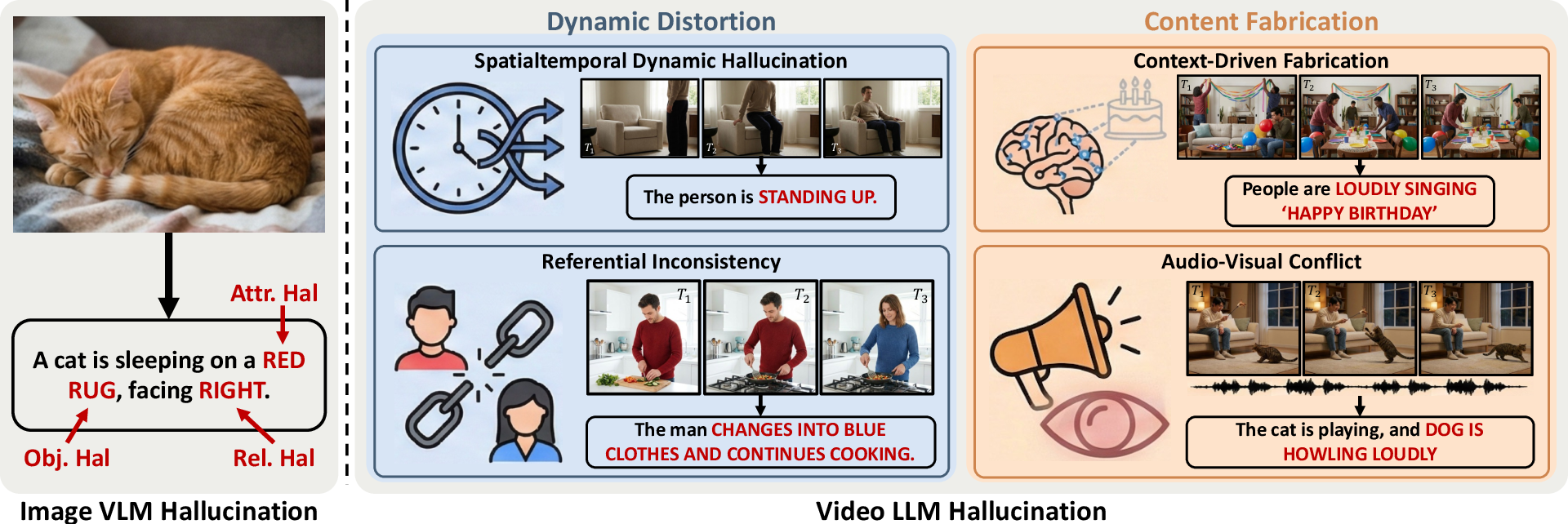
Figure 1: Taxonomy illustrating dynamic distortion and content fabrication in Vid-LLMs, with further breakdown into spatiotemporal misrepresentation, referential inconsistency, statistical priors, and audio-visual dominance.
Taxonomy of Hallucinations in Vid-LLMs
The survey introduces a layered, mechanism-based taxonomy distinguishing two principal hallucination categories:
- Dynamic Distortion: Model detects entities but misrepresents temporal relations or referential identities. Subtypes include:
- Spatiotemporal Dynamics: Event misordering, erroneous duration estimation, frequency confusion.
- Referential Inconsistency: Character/scene conflation across temporal boundaries.
- Content Fabrication: Output is ungrounded in visual evidence and is instead driven by prior knowledge or audio cues. Subtypes include:
- Context-Driven Fabrication: Object-action or scene-event completions unsupported by visual evidence.
- Audio-Visual Conflict: Auditory dominance leading to hallucinated actions/emotions contradictory to visuals.
The taxonomy is empirically separable and mutually exclusive, determined by whether the hallucinated output is visually supported (dynamic distortion) or relies on non-visual/statistical cues (content fabrication).
Evaluation: Benchmarks and Their Coverage
Comprehensive benchmarking across the taxonomy reveals disproportionate focus on certain hallucination types. Spatiotemporal dynamics are broadly covered with robust metrics (event misordering, duration, count), but referential inconsistency and audio-visual conflict are distinctly underrepresented. SOTA Vid-LLMs demonstrate high accuracy on select tasks (e.g., VidHalluc—81.2%, EventHallusion—91.9%), yet struggle with duration (VideoHallucer—37.8%) and referential consistency (ELV-Halluc—53.1%). Generative benchmarks enable deep reasoning but suffer from evaluation bias; discriminative formats support scalable metrics but may reinforce shortcut learning.
Mitigation Strategies: Mechanisms and Trade-offs
Mitigation follows the taxonomy, employing approaches tailored to error type:
- Dynamic Distortion: Addressed via contrastive decoding (e.g., SEASON, SmartSight), preference optimization, introspective sampling, feature reweighting (DINO-HEAL), temporal-aware activation injection (TAAE), and dense video-script alignment (Vriptor). Referential inconsistency is mitigated through equal distance attention (Vista-LLaMA), database-anchored symbolic execution (VideoPLR), adversarial preference optimization (ELV-Halluc-DPO), and memory bank updates (VideoChat-Online).
- Content Fabrication: Attenuated using fine-grained contrastive tuning (SANTA), logit subtraction (TCD), disentangled spatial-temporal attention (MASH-VLM), preference learning with negative samples (PaMi-VDPO), and dual-path visual-text alignment (MMA). Strategies penalizing low visual-dependency tokens (VistaDPO) achieve strong gains. For audio-visual conflict, modality-disentangled fine-tuning (AVHModel-Align-FT) and contrastive decoding (AVCD) show notable accuracy improvements.
Training-centric interventions yield higher performance gains but incur substantial computational overhead; inference-time approaches offer deployment flexibility but are less effective against entrenched parametric priors.
Theoretical and Practical Implications
Vid-LLMs within safety-critical domains (autonomous driving, embodied AI) require robust hallucination mitigation due to the elevated risks of plausible but incorrect outputs. Dynamic distortion reflects deficiencies in temporal encoding and memory mechanisms, demanding motion-aware encoders and explicit long-range context retention. Content fabrication reveals the need to disentangle learned priors from perceptual grounding, particularly under audio-visual integration. Referential consistency and modality alignment emerge as core challenges escalating with temporal scale and interactive deployment.
Future Directions
Extension of the taxonomy to emerging contexts (long-form, streaming, agentic Vid-LLMs) enables systematic error categorization independent of model architecture. Advances should focus on:
- Temporal Fidelity: Video-native encoders (VideoMAE), motion priors (optical flow), structured memory architectures (Mamba, episodic memory).
- Grounded Reasoning: Counterfactual learning, debiasing strategies, modality-verification pipelines for multimodal claims.
- Scalable Mitigation: Training-time alignment methods reducing inference latency, robust preference optimization, and visual evidence-centric reward modeling.
- Benchmark Expansion: Domain-specific benchmarks for long-range, referential, and audio-visual errors.
Conclusion
The survey consolidates the study of hallucination in Vid-LLMs via a mechanism-based taxonomy, covering evaluation and mitigation in depth. While progress is evident for spatiotemporal and context-driven hallucinations, referential inconsistency and audio-visual conflict remain challenging. Emphasis is placed on future architectures supporting temporal structure, scalable memory, and perceptual grounding—foundational for trustworthy video-language systems.