A comprehensive taxonomy of hallucinations in Large Language Models
Abstract: LLMs have revolutionized natural language processing, yet their propensity for hallucination, generating plausible but factually incorrect or fabricated content, remains a critical challenge. This report provides a comprehensive taxonomy of LLM hallucinations, beginning with a formal definition and a theoretical framework that posits its inherent inevitability in computable LLMs, irrespective of architecture or training. It explores core distinctions, differentiating between intrinsic (contradicting input context) and extrinsic (inconsistent with training data or reality), as well as factuality (absolute correctness) and faithfulness (adherence to input). The report then details specific manifestations, including factual errors, contextual and logical inconsistencies, temporal disorientation, ethical violations, and task-specific hallucinations across domains like code generation and multimodal applications. It analyzes the underlying causes, categorizing them into data-related issues, model-related factors, and prompt-related influences. Furthermore, the report examines cognitive and human factors influencing hallucination perception, surveys evaluation benchmarks and metrics for detection, and outlines architectural and systemic mitigation strategies. Finally, it introduces web-based resources for monitoring LLM releases and performance. This report underscores the complex, multifaceted nature of LLM hallucinations and emphasizes that, given their theoretical inevitability, future efforts must focus on robust detection, mitigation, and continuous human oversight for responsible and reliable deployment in critical applications.
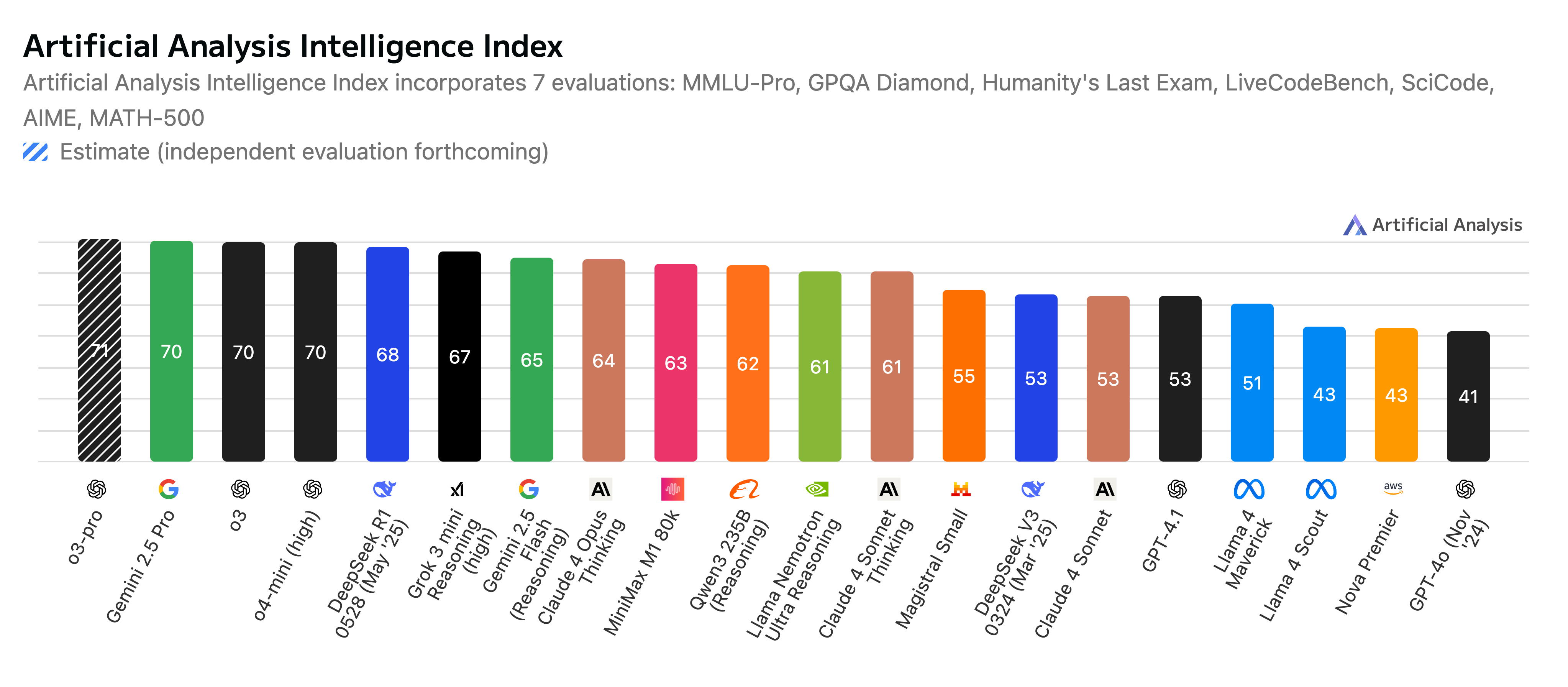
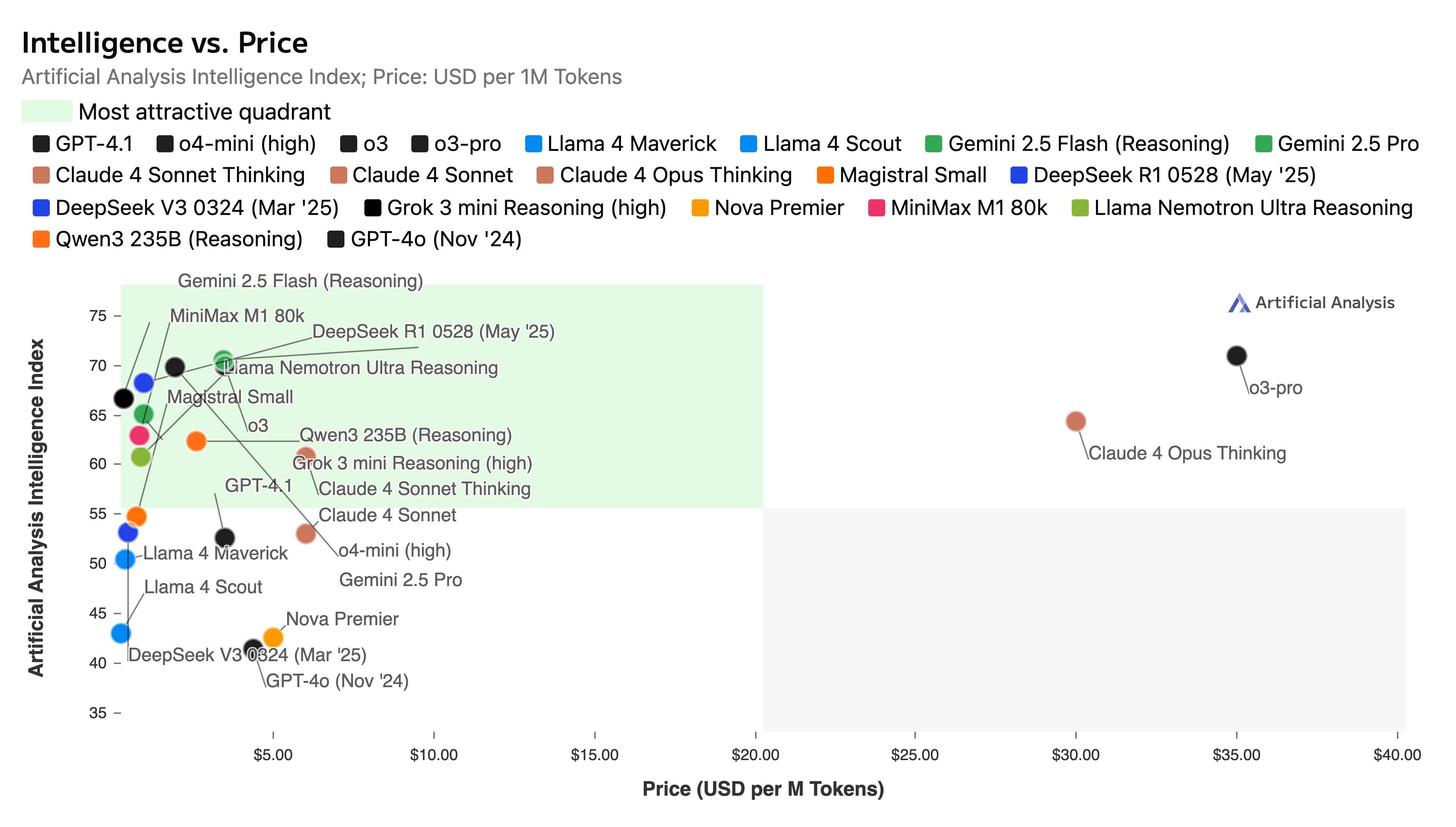
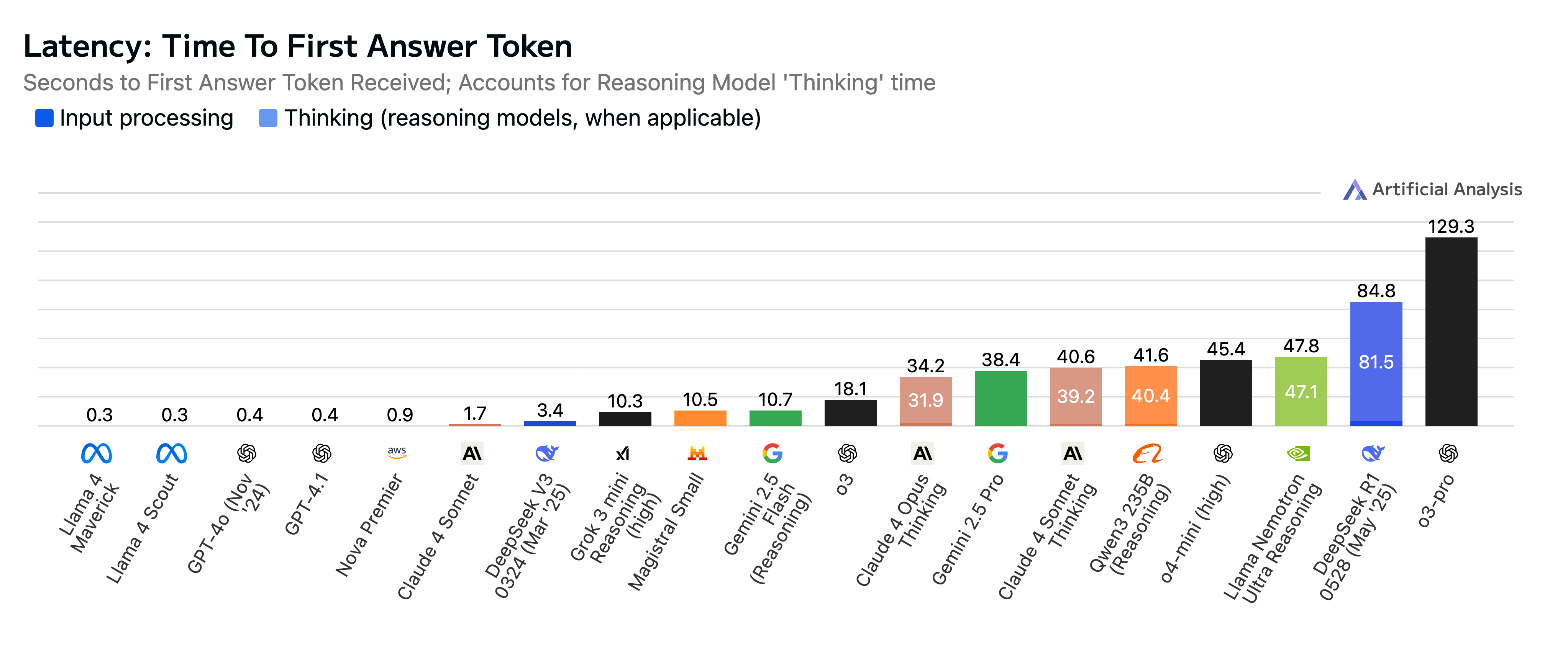
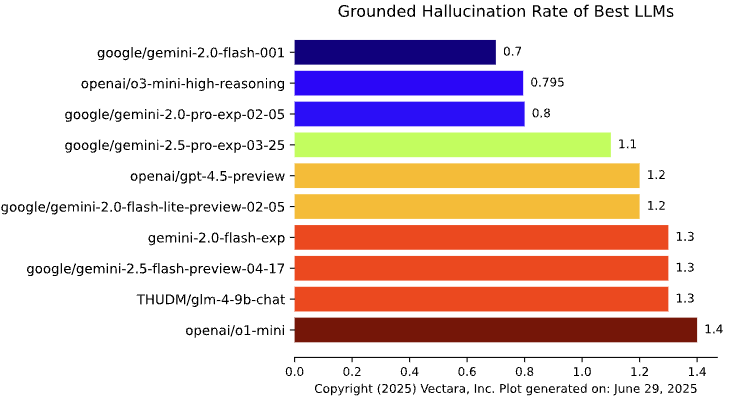
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explains why LLMs—the AI systems behind tools like chatbots—sometimes “hallucinate.” In AI, hallucination means the model confidently says things that sound right but are actually wrong or made up. The paper builds a clear map (a taxonomy) of different kinds of hallucinations, why they happen, how to check for them, and what we can do to reduce them. It also argues that some hallucinations are impossible to fully eliminate, no matter how good the model is.
What questions does the paper try to answer?
- What exactly is an AI “hallucination,” and how should we define it?
- Are hallucinations rare mistakes, or are they unavoidable?
- What kinds of hallucinations exist, and how can we tell them apart?
- What causes them—bad data, model design, the user’s prompt, or something else?
- How can we detect, measure, and reduce hallucinations in practice?
How did the author study the problem?
The paper isn’t a single experiment. It’s a comprehensive review and framework that does three things:
- It introduces a formal, math-based argument that hallucinations are unavoidable for any realistic LLM. Think of it as a proof that some errors will always slip through.
- It organizes (taxonomizes) the different kinds of hallucinations into clear categories with examples.
- It surveys causes, human factors (like trust and bias), tests and benchmarks, and practical fixes (like grounding answers in reliable sources and adding safety guardrails).
If “formal proof” sounds abstract, imagine a game where you try to write a rulebook that covers every possible tricky question. The paper argues that for any rulebook an LLM can follow, someone can still craft a question that makes it slip up. It’s like an unbeatable game of whack-a-mole: you can reduce mistakes, but you can’t remove them all.
What did the paper find?
1) Some level of hallucination is inevitable
Using ideas from computer science, the paper shows that for any computable LLM (which includes real-world models), there will always be questions that make it answer incorrectly. Not only that, but there can be infinitely many such questions. This means:
- No model can guarantee 100% truthfulness on everything.
- Models can’t “self-fix” hallucinations completely just by thinking harder.
- Safety-critical uses (like medical or legal decisions) must include external checks and human oversight.
Why this matters: It shifts the goal from “eliminate all hallucinations” to “detect, limit, and manage them reliably.”
2) There are two key ways to classify hallucinations
To talk clearly about hallucinations, the paper separates them into simple, easy-to-spot types:
- Intrinsic vs. Extrinsic
- Intrinsic: The answer contradicts the given text or context. Example: The source says “approved,” but the summary says “rejected.”
- Extrinsic: The answer invents details not supported by the context or reality. Example: Making up a fake animal or event.
- Factuality vs. Faithfulness
- Factuality: Is the answer true in the real world?
- Faithfulness: Does the answer stick to the user’s prompt or the provided source?
These pairs overlap but help different teams (engineers, evaluators, users) discuss problems precisely.
3) Common ways hallucinations show up
Here are typical patterns the paper highlights:
- Factual errors and fabrications: Wrong dates, fake citations, made-up facts.
- Contextual mistakes: Adding details not in the source or contradicting it.
- Instruction-following errors: Ignoring what the user asked (e.g., wrong language or format).
- Logical errors: Step-by-step reasoning that falls apart midway.
- Time mistakes: Outdated info or wrong timelines.
- Ethical/legal harms: Defamation, dangerous advice, or bogus legal cases.
- Task-specific issues: Code that looks right but fails; vision-LLMs naming objects that aren’t in the image; chatbots confusing people or events across a long conversation.
4) Why do hallucinations happen?
In short, LLMs are super-powered autocomplete. They predict the next word based on patterns they’ve seen, not because they truly “understand” the world. Several ingredients matter:
- Data problems: Noisy, biased, incomplete, or outdated training data.
- Model design: The auto-regressive setup (predicting one token at a time), reasoning limits, and overconfidence.
- Decoding randomness: Settings that boost creativity can also increase errors.
- Prompts: Tricky or misleading prompts (accidentally or on purpose) can push the model to make things up.
- Human factors: People may trust confident-sounding text, even when it’s wrong.
5) How do we test and reduce hallucinations?
The paper reviews benchmarks and metrics used to detect hallucinations and discusses practical ways to cut them down:
- Grounding the model: Use Retrieval-Augmented Generation (RAG) to pull in up-to-date, trustworthy sources during answering.
- Tools and external systems: Let the model call calculators, databases, code runners, or search tools.
- Guardrails and policies: Add filters, constraints, and safety checks before answers reach the user.
- Better prompts and examples: Clear instructions and in-context examples reduce confusion.
- Human oversight: Experts review answers, especially in sensitive domains.
No single fix works for everything; the best systems combine several of these.
Why does this matter, and what’s the impact?
As LLMs spread into schools, hospitals, courts, and businesses, their mistakes can have real consequences—misinformation, risky medical claims, financial losses, and reputational harm. This paper’s core message is realistic and responsible: total perfection isn’t possible, so aim for strong defenses. That means:
- Design systems that check facts against reliable sources.
- Keep humans in the loop for important decisions.
- Use clear categories to diagnose what went wrong and improve targeted fixes.
- Build better tests and shared definitions so the field can compare models fairly and improve faster.
In short: LLMs are powerful but imperfect. Treat them like skilled assistants who still need supervision, not like all-knowing authorities.
Collections
Sign up for free to add this paper to one or more collections.

